
基于数据挖掘的地震经济损失与当地经济情况相关性分析1
2013-09-09 03:21:12斌1安源源2彭亚飞2卢国明2
震灾防御技术 2013年3期
胡 斌1) 安源源2) 彭亚飞2) 卢国明2)
基于数据挖掘的地震经济损失与当地经济情况相关性分析
胡 斌安源源彭亚飞卢国明
1)四川省地震局,成都 610041 2)电子科技大学,成都 611731
本文以收集的西南地区1950年以来301个典型破坏性地震震例数据为基础,选择关联规则和决策树两种数据挖掘方法,对地震经济损失与当地经济情况进行分析,给出了相关规则,并对关联规则和决策树两种不同的挖掘方法得出的结果进行了分析比较。
经济损失 数据挖掘 关联规则 决策树
引言
西南地区是我国破坏性地震多发区,地震震级大,发震频度高,地震影响范围广;而与此同时,西南地区社会经济发展、人口分布极度不均衡,城乡间、民族间、区域间经济发展差异巨大。西南地区丰富的地震震害资料及差异性社会经济数据为本文的研究奠定了数据基础。
数据挖掘(Data Mining)是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据准备、规律寻找和规律表示3个步骤(王丽珍等,2005)。数据挖掘的方法有关联分析、聚类分析、分类分析、决策树分析、逻辑回归分析等。本文采用关联分析与决策树分析方法,对地震经济损失与当地国内生产总值的比值(以下简称地震经济损失比)(林均岐等,2007)进行研究,挖掘与其它因素之间的关联关系,可为将来地震经济损失估计提供参考。
1 数据收集
通过对地震灾害经济损失和GDP相关因素的分析,对挑选的以下主要因素进行了收集及相关性分析:震级、烈度、经济损失、GDP、国土面积、人口数。通过以上数据可以计算出:经济损失比、人均GDP、人口密度。表1是数据库表结构定义。
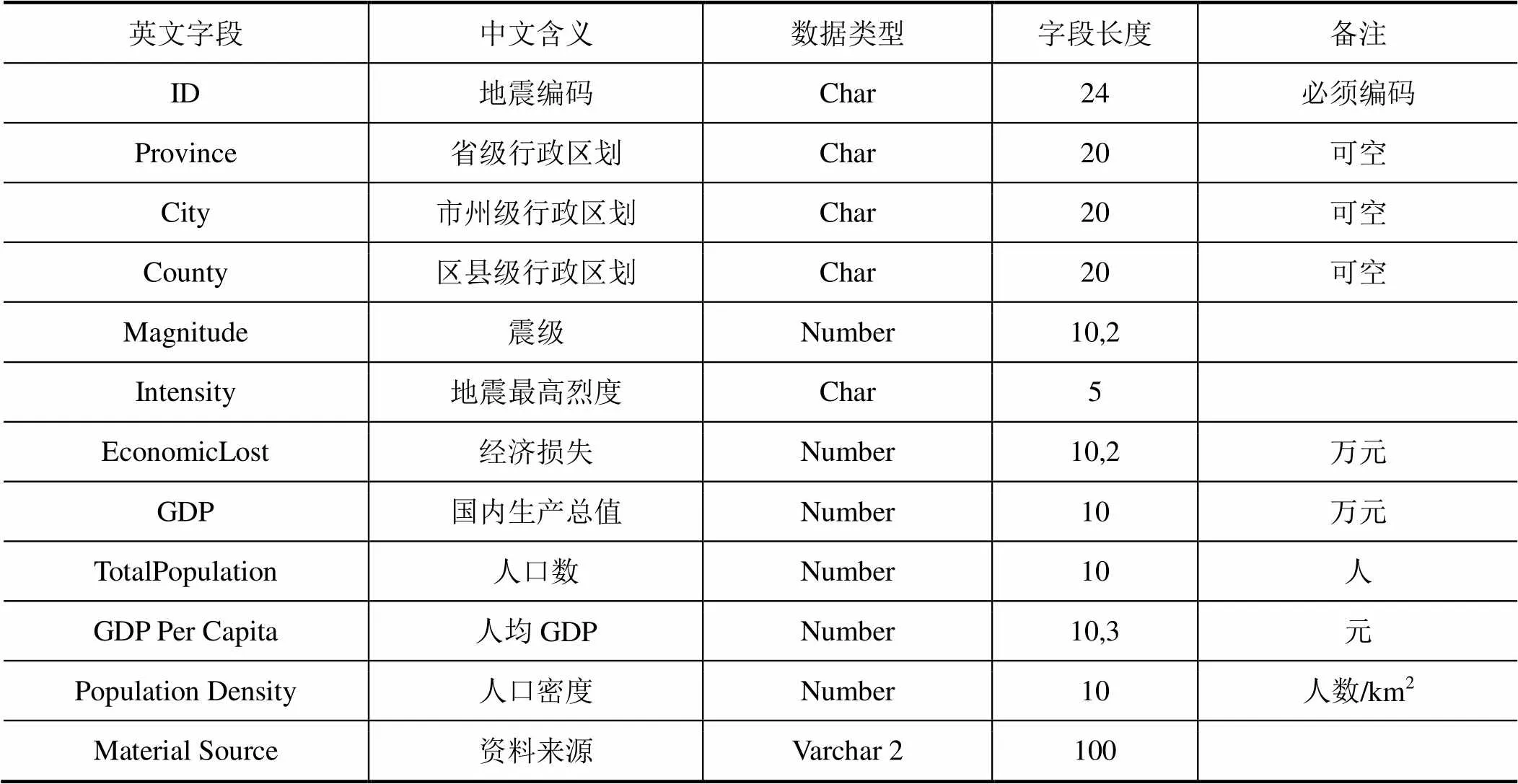
表1 数据库表结构
数据收集来源主要分为以下三部分:
(1)来源于西南地区地震应急基础数据库;
(2)来源于各省地震年鉴及地震科学考察报告;
(3)来源于各省、市、县当年的社会、经济统计年鉴等。
本文收集的地震经济损失数据,都是在地震发生时的统计结果,研究地震经济损失与当地经济情况的相关性,对应的当地经济情况、人口情况也必须是地震发生时的数据。地震发生所在地1980年以前的人口、经济数据无法直接收集,对这些数据依据国家、省统计局提供的经济增长率、人口增长率进行推算(国家统计局国民经济核算司,1997;国家统计局人口统计司等,1988)。
由于数据来源的多样化,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。因此要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗,而数据清洗的任务是过滤掉那些不符合要求的数据。
本次在西南地区共收集到有数据记录的324条地震震例数据,由于数据来源的多样化,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,为此必须按照一定的规则把这些错误的或有冲突的数据清洗掉(王曰芬等,2007)。本文采用手工方式实现数据清洗:
(1)对于部分经济损失收集数据单位为元,没有转换为万元,进行手工修改。
(2)对于严重缺失项的地震震例数据,直接删除。
清洗完成后,总共收集到的有效案例记录条数为301条。
2 数据挖掘
2.1 关联规则分析
关联规则挖掘采用Apriori算法。Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,其核心是基于两阶段频集思想的递推算法。
算法关联规则中的Apriori挖掘算法在在执行过程中要多次扫描数据库,并且产生大量的候选项集(韩家炜等,2007)。由于本次研究数据量比较小,对于上述问题在本研究中不会出现。具体分析步骤如下:
第一步:扫描地震震例数据库,对各个项集的次数进行计算,得到候选项集1-(表2)。
第二步:从候选项中选出大于最小支持度的项集,即选出支持>2的项集,从而得到频繁1-项集(表3)。
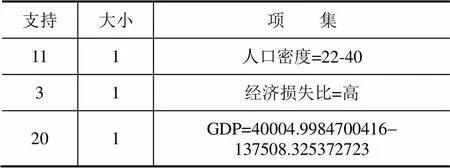
表2 部分候选项C1集合
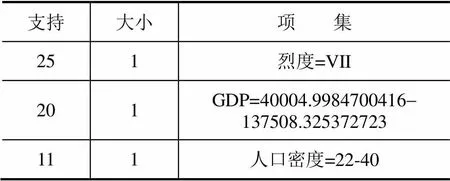
表3 部分频繁集L1集合
第三步:重复上述整个过程,直到产生的候选项级C的支持<2,即小于规定的最小支持项,不能产生频繁项集,算法停止。本研究结果最终产生的最大频繁项集为(表4)。

表4 频繁项集L3
根据以上产生的频繁项集,可生成不同形式的关联规则,对于一个-项的频繁项集,其最多产生(2-2)种不同形式的规则,当较大的时候,产生的规则成几何数量级的增长。在这里不可能一一列举,所以需要定义一个置信度阀值MINMUM_SUPPORT。通过分类统计,-项集能产生的关联规则形式主要有-1类:
第一类:规则左部有-1项,规则右部有1项:
规则如:,,…→
第二类:规则左部有-2项,规则右部有2项:
规则如:,,…→,
…………
第-1类:规则左部有1项,规则右部有-1项。
通过定义置信度阀值MINMUM_SUPPORT,可过滤掉一些无用的规则。
2.2 决策树分析
决策树是同时提供分类与预测的常用方法。通过一连串的问题和规则将数据分类,可以通过相似的形态来推测相同的结果。决策树的数据分析方法是一种用树来展现数据受变量的影响情形的预测模型。
在运行决策树算法之前,首先把输入的各项连续数据进行清洗,使其离散化。决策树开始时,是作为一个单个节点(根节点)包含所有的训练样本集,为“全部”节点;决策树模型的预测项为经济损失比,其属性可以取个不同的值,本文对经济损失比进行离散化,对应于个不同类别为C;设一个属性取个不同的值 {,,……,a},若取GDP,则取2个不同的值 {GDP<40004.998,GDP≥40004.998}。利用属性可以将划分为个子集 {,,……,s},其中s包含了集合中属性取a值的数据样本。若属性被选为测试属性,设s为子集s中属于C类别的样本数。那么,利用属性划分当前样本集合所需要的信息(熵)可以进行如下计算:
这样,利用属性对当前分支节点进行相应样本集合划分所获得的信息增益就是:
Gain()=(,,……,s)-() (3)
也就是说,Gain()被认为是根据属性取值进行样本集合划分所获得的(信息)熵的减少。在本文中的Gain(Intensity)、Gain(Population Density)、Gain(Magnitude)、Gain(GDPPer Capita)、Gain(GDP)、Gain(Total Population)等信息增长中,Gain(GDP)值最大,因此被作为测试属性用于产生当前分支节点,test_attribute=GDP。同时根据“GDP”取不同的值,把全部的输入分为两部分:GDP<40004.998和GDP≥40004.998。若设符合此条件的集合:GDP<40004.998为,返回值为Generate_decision_tree(,GDP);GDP≥40004.998,设此集合为,返回值为Generate_decision_tree(,GDP)。以此类推,继续递归调用决策树算法。
按照上述步骤构造决策树,最终可产生一个如图2所示的决策树。
3 挖掘结果分析
3.1 关联规则挖掘结果分析
通过关联规则挖掘能够发现很多有趣的和有价值的规则,但是其本身也存在着一些不可避免的缺陷,比如在挖掘中能满足最小支持度和最小置信度阀值的规则很多,但并不是所有的规则用户都有兴趣。对于挖掘结果而言,哪些是用户感兴趣的关系是数据挖掘技术要解决的一个重要基本问题(蔡红等,2011)。因此,挖掘结果的进一步处理,需要相关领域的专家与计算机领域的专家共同配合,协同提取有用的挖掘结果。图1给出了部分挖掘结果。表5列出了几个典型的规则。

表5 部分挖掘结果
从表5给出的规则中可以看出:对于规则1,人口密度极小,人均GDP较低时,其经济损失比也会比较低;对于规则2、3,地区经济较不发达或者人员分布较稀疏时,地震造成的经济损失比也会比较低;对于规则4,在人口密度较大的中小城市发生5级以上地震,地震造成的经济损失比也会比较高;对于规则5,高烈度的不发达地区,一般地震造成的经济损失比也会比较高。综合挖掘规则的若干结果,在一般情况下人口密度大、GDP总量高、震级大、烈度高地区,地震造成的经济损失比会比较高。
3.2 决策树模型挖掘结果分析
如图2所示,每个矩形方框中不同颜色的直方图分别表示经济损失比的不同等级。当GDP<40004.998时,蓝色直方图面积大,一般其经济损失比低;当GDP≥40004.998时,依据人均GDP取值范围分为下面两类,人均GDP处于1651.608到2913.555之间时,红色直方图较大,其经济损失比一般较低;人均GDP<1651.608或者人均GDP>2913.555时,依据人口密度又分为两类,人口密度在68到122之间的,红色直方图的比例较大,其经济损失比一般较低;人口密度小于68,大于122的,其中蓝色直方图的比例最大,一般其经济损失比低。
其中一个具体的叶子节点的挖掘图例如表6所示。
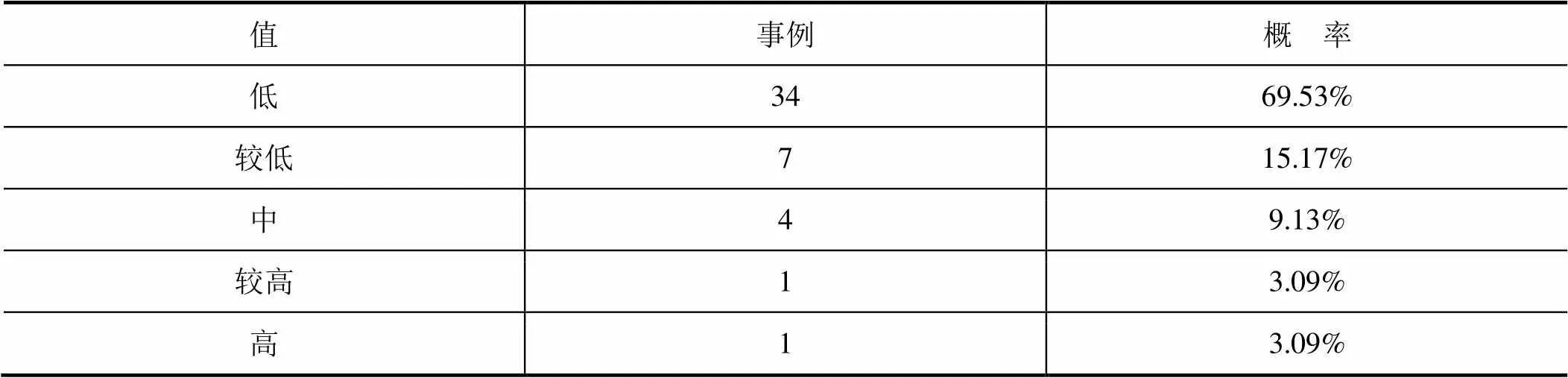
表6 GDP<40004.998
依据决策树结果,生成依赖关系网络,由依赖关系网络图中(图3)箭头线越粗表示其变量对经济损失比影响越大。从图3可以看出,在地震发生时影响经济损失比的因素从强到弱依次为:Intensity、Magnitude、Population Density、Per Capita GDP、Earthquake GDP、Total Population。在西南地区的地震中,烈度对经济损失的影响最大,其次是震级、人口密度、人均GDP、GDP、人口数。
4 结论
在本文研究中,挖掘结果的评价采用了微软的Microsoft SQL Server 2005模型评估模块,将挖掘结果导入到模型评估系统中,以随机抽取的样本作为模型评估测试数据,并对研究结果做了准确性评估测试。
如图4所示,蓝色线代表理想模型的提升结果(评估结果),红色线代表决策树实际的提升结果(评估结果),绿色线代表关联规则的提升结果(评估结果)。从图5中可以看出,关联规则的分数为0.78,决策树的分数为0.86,二者整体趋势跟理想模型的趋势比较相同。在预测评估地震经济损失方面,决策树模型的预测效果比关联规则预测效果更好一些。
西南地区大跨度的社会经济发展水平、多样性的人文地理环境和多种类型的地震活动特点,使得西南地区的地震经济损失在具备特殊性的同时,更具备典型性。因此本文在这方面的深入研究,对全面提升我国地震经济损失研究具有较强的示范作用。尽管文中还存在一些不足,若地震历史数据能收集的更加全面,就能得到更加丰富的挖掘结果。
致谢:感谢西南地区地震局相关工作人员以及地震专家的支持,不辞辛苦收集并整理数据,对本文展开的研究提供了宝贵意见及建议,发挥了重要的导向作用。同时感谢电子科技大学卢国明教授的数据挖掘团队,尤其感谢李谊瑞研究员的细心指导,技术上提供了很大的支持,在此深表感谢。
蔡红,陈荣耀,陈波,2011.关联规则挖掘最小支持度阀值设定的优化算法研究.微型电脑应用,27(6):33—36.
国家统计局国民经济核算司,1997.中国国内生产总值核算历史资料(1952—2004).北京:中国统计出版社.
国家统计局人口统计司,公安部三局,1988.中华人民共和国人口统计资料汇编.北京:中国财政经济出版社.
韩家炜,(加)坎伯(Kamber, M.),2007.数据挖掘概念与技术. 北京:北京工业出版社,1—3.
林均岐,钟江荣,2007. 区域地震间接经济损失评估. 自然灾害学报,16(4):139—142.
王丽珍,周丽华,陈红梅等,2005.数据仓库与数据挖掘原理及应用.北京:科学出版社,10—13.
王曰芬,章成志,张蓓蓓,吴婷婷,2007.数据清洗研究综述.现代图书情报技术,12:50—56.
Correlation Analysis of Seismic Economic Losses and Local Economic Conditions Based on Data Mining
Hu Bin, An Yuanyuan, Peng Yafeiand Lu Guoming
1) Earthquake administration of Sichuan Province, Chengdu 610041, China 2) University of Electronic Science and Technology of China, Chengdu 611731, China
This work is based on 301 destructive earthquake cases in the five southwestern provinces in China since 1950. By using association rules and decision tree, we analyze seismic economic losses and local economic conditions, works out the correlation rules, and compare the results of the above two different mining methods.
Economic losses; Data mining; Association rules; Decision tree
2011年度地震行业科研专项西南地震应急对策新模式与关键技术研究(201108013)
2012-12-28
胡斌,男,生于1977年。硕士。现在四川省地震局从事地震灾害研究与应急救援工作。 E-mail:kennyferly@yahoo.com.cn
胡斌,安源源,彭亚飞,卢国明,2013.基于数据挖掘的地震经济损失与当地经济情况相关性分析.震灾防御技术,8(3):275—282.
猜你喜欢
交通财会(2023年9期)2023-10-29 00:10:38
水利水电快报(2022年8期)2022-11-23 10:18:48
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
中华老年多器官疾病杂志(2016年9期)2016-04-28 08:52:15
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
网络安全与数据管理(2010年1期)2010-05-18 07:28:54
