
基于频繁闭模式的故障状态简洁关联规则挖掘
2013-08-29 09:32徐华结钱叶旺许亚男
华中师范大学学报(自然科学版) 2013年3期
陈 艳,徐华结,钱叶旺,许亚男
(池州学院 机械与电子工程系,安徽 池州 247100)
系统故障的发生往往会引起外部可观测特征的变化,在对一个系统的故障机理和其对外界影响效应未完全了解之前,建立故障与故障表象之间的关系,为故障进行分析和诊断提供决策是一种重要的故障检测手段.在智能数据分析处理中,已经有人工智能、模式识别[1-2]等手段被应用到此领域中.作为数据挖掘领域中的一种重要知识,关联规则[3-5]表达了离散事物间的关联关系,具有分类和预测的特性.在特定离散事件分析中,基于关联规则分析的处理方法CBA[6]、CMAR[7]相比C4.5等传统分类方法,具有直接、有效、正确率高等特点.在故障分析过程中,根据以往的故障观测特征,挖掘基于关联信息的故障表象与实际故障之间的关联关系,并建立分类与预测信息,当新的故障表象表现时,根据预测信息诊断出相应具体故障发生的概率.此过程包括故障样本数据的获取、故障状态关联知识获取、基于关联知识的诊断3个步骤.
在一个系统中,与故障相关的表象因素可能会很多,在对故障因素进行关联知识的挖掘表述中,每个故障因素对应到具体的数据项.基于频繁模式的关联规则会随着数据项的增长成指数增加,难于进行处理.闭模式[8-9]表示方法是一种有趣的选择,其能计算出所有频繁项集信息,而模式的个数要比后者呈数量级缩小.挖掘基于闭模式的关联规则和基于频繁模式的关联规则具有相同的功效.由于闭模式表示方法的简洁性,基于闭模式的关联规则数量较少,维护规则的时空开销也将大大降低.相关的挖掘任务效率也将有较大提高.
本文采用频繁闭模式进行简洁故障状态关联规则挖掘的方法.首先根据以往的观测样本,挖掘故障特征间的关联关系.然后建立故障特征触发转换图,表征故障表象的因果关系.新的故障表象发生时,选择路径进行会诊,得到结果.由于闭模式挖掘剔除冗余复杂,计算量大,采用对搜索空间提前剪枝的方法,直接生成闭模式,不需较大候选的产生.避免了采用通过保存频繁模式并不断扫描原始数据和过滤候选闭模式的方法.同时整个挖掘结构在挖掘过程中由于不断被删除回收,占用内存会越来越少.最终在枚举出的基于闭模式简洁规则的基础上,建立故障事件转换图,进行故障诊断.实验结果表明,提出的方法准确、有效,具有一定的实用性和推广价值.
1 问题描述
设e={e1,e2,…,em}是系统出现的m个故障征兆集,f={f1,f2,…,fn}是系统的故障集,在某一时刻,系统的故障征兆和故障状态同时出现.T={T1,T2,…,Tl}是系统故障状态观测样本,其中Ti为系统在一个故障时刻i观测到的系统出现故障的状态集,其中Ti(1≤i≤l)⊆e∪f.则使用简洁关联知识进行故障诊断的方法,是根据系统状态观测样本,挖掘出故障征兆和故障集之间的关联关系,并进行诊断的过程.
故障诊断主要包括两个步骤:(1)挖掘系统中故障状态间的简洁关联知识;(2)使用简洁关联知识进行诊断.关联规则的挖掘是从大量事务中,挖掘出包含的项之间的关联关系.在这里我们将系统出现故障的状态集的集合T作为事务数据集,其中的某个状态特征c⊆e∪f称为项.
2 基于闭模式的先验简洁故障关联知识表示方法
设故障和状态的集合I={x1,…,xM},给定故障状态事务数据库TDB={T1,T2,…,TN},其中Ti⊆I是一个故障状态集.在数据库TDB中,项集X的支持度表示为support(X).给定最小支持度阈值min_sup.
定义1 项集X是频繁闭模式当且仅当以下条件成立:
(1)support(X)≥min_sup;
(2)∀Y⊃X,support(Y)<support(X).
由以上定义可以看出,频繁闭模式首先是频繁的,其次剪除了具有相同支持度的子集,故闭模式个数要比频繁模式个数小得多.
性质1 对于项集X、Y(Y⊃X),support(Y)=support(X),则对任意项集Z(Z⊃X,Y⊄Z),项集Z不为闭模式.
性质2 任何频繁的非闭模式必存在具有相同支持度,且为其超集的频繁闭模式.
给出以下计算任何频繁模式支持度的方法.对于任何项集X⊂I:
(1)若存在项集Y⊇X,Y为频繁闭模式,则项集是频繁的.且其支持度可计算为:
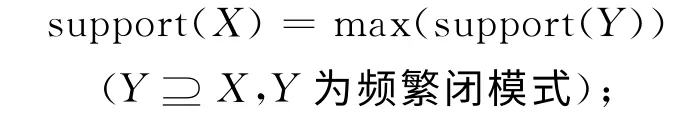
(2)否则,项集X为非频繁项集.
定义2 基于闭模式的简洁故障状态关联规则表示为A⇒B,其中A⊂B,A,B为频繁闭模式,且有支持度support(A⇒B)=support(B),置信度confidence(A⇒B)=support(B)/support(A).
例如有项集A⊂B,A,B为频繁闭模式,分别表示为:

支 持 度support(A⇒B)=support(B)=30%,置信度confidence(A⇒B)=support(B)/support(A)=80%,则表示在机器发生(噪声大于90dB)(温度大于200 ℃)的情况下,会出现(发动机缺少机油)的故障的概率为80%,以上两个事件同时发生的概率为30%.
性质3 任何基于频繁故障状态模式的规则可由基于闭模式的简洁故障状态关联规则正确计算出其支持度和置信度.
由性质2可得结论,证明从略.
3 挖掘简洁故障状态关联知识
不失一般性,假定故障状态集I=e∪f上存在一个偏序,记作≺.有许多方法定义≺,在这里定义≺为I中每个项的支持度降序,以取得较好的处理效率.
设Ti={i1,i2,…,im}(i1≺i2≺… ≺im)(1≤m)是一个事务.称项集{j1,j2,…,jn}⊆T(1≤n≤m,j1≺j2≺…≺jn)为事务Ti的约束.项集{i1,i2,…,ik}⊆T(1≤k≤m-n,ik≺j1≺ik+1)称为{j1,j2,…,jn}约束下的约束项集.
3.1 支持度降序后缀树
在事务数据库TDB中,把项集{j1,j2,…,jn}(n≥1)约束下的所有约束项集{i1,i2,…,ik}利用类似于创建FP-树的方法创建并插入树中,设置新后缀,形成项集{j1,j2,…,jn}(j1≺j2≺…≺jn)约束下的支持度降序后缀树DSST(jn,…,j2,j1).在树中出现的项成为树的候选项.
定义空集∅约束下的支持度降序后缀树为DSST(),其类似于由初始原始数据创建的FP-树,但其叶节点后缀指针已被设置为空链.
3.2 枚举简洁故障状态关联规则
由关联规则的定义,挖掘关联规则有两个步骤:首先枚举出闭模式,其次枚举出基于闭模式的规则.在基于支持度降序后缀树的挖掘中,采用按照项的排序优先依次进行处理,使用后向关联对频繁模式的冗余搜索空间进行提前剪枝,得到闭模式.
例1 设定支持度为30%,置信度为50%,枚举简洁故障状态关联规则.某一动力系统在故障发生时可能会出现以下征兆:
e1:冷却系统液体温度超过300 ℃;
e2:冷却系统液体压力大于半个大气压;
e3:动力系统表面温度超过200 ℃;
e4:动力系统噪声超过80dB;
e5:动力系统排放废气颜色较深;
动力系统可能会发生的故障可能为.
f1:活塞发生重大磨损;
f2:燃油压力过低.
系统故障状态观测样本有:

表1 系统故障状态观测数据Tab.1 System fault state observation data
在以上观测数据中,项e1,e2,e3,e4,e5,f1和f2 的支持度计数分别为1,1,2,3,2,2和1.按照支持度降序得到项的排列e4≺f1≺e3≺e5≺e1 ≺e2 ≺f2.创建的支持度降序后缀树DSST()见图1,具体创建过程从略.

图1 基于状态观测数据创建的DSST()Fig.1 Proposed DSST()based on state observation data
性质4 设数据库中的项i1≺i2≺i3≺… ≺in(n>1),若在DSST(in,in-1,…,im)中项i1,i2,…,ik的计数等于{in,in-1,…,im}的计数,则任何项集X⊇{in,in-1,…,im}且存在ij(k≥j≥1)∉X,X不是闭模式.
由支持度降序后缀树定义和性质1可得结论.
性质5 设数据库中的项i1≺i2≺i3≺… ≺in(n>1),若在DSST(in,in-1,…,i3)中项i1的计数等于项i2下的项i1的计数,则任何项集X⊇{i2,…,in}且i2∉X,X不是闭模式.
由以上性质给出枚举频繁闭模式的过程如图2所示.

图2 枚举故障状态闭模式伪代码Fig.2 Pseudocode of enumeration fault state closed mode
基于图1中创建的DSST()进行挖掘,当项e1处理结束后,挖掘以项e5 开头的闭模式,创建DSST(e5),进一步挖掘得到以项e5开头的闭模式{e5,e4}:2.下图3为处理完项e1后的DSST()和DSST(e5).

图3 处理完项e1后的DSST()和DSST(e5)Fig.3 DSST()and DSST(e5)based on item processed e1
最终得到例1的闭模式为:

根据基于闭模式的简洁故障状态关联规则的定义,进一步枚举出规则形式如下:

从以上简洁故障状态关联规则能够计算得到例1中所有基于频繁模式的关联规则.
4 基于简洁故障状态关联规则进行故障诊断
基于闭模式的简洁故障状态关联规则数量很多,包括了所有与系统相关的状态关系,而那些仅与系统故障征兆相关的规则或右部没有比左部多余故障的规则,是不具有故障预测性的,需要剔除掉.然后建立故障状态跳转图,选择优先的规则进行诊断.
4.1 面向规则前件的故障诊断规则剔除方法
定义3 一个基于简洁知识的故障状态规则A⇒B为冗余的,满足以下条件.
存 在 规 则C⇒B使 得,A⊃C且confidence(C⇒B)≥confidence(A⇒B).
包含单个项后件的规则的剔除方法如下:
(1)对于规则A⇒B,∀I∈B,替换为单项后件规则的集合IS={A⇒{I}|I∈B};
(2)对于所有的单项后件的规则集使用定义3进行剔除冗余的规则;
(3)把具有相同前件的规则的后件合并.
在进行单个故障进行诊断时,可使用以上方法.但在一些系统中,需要进行故障同时发生的诊断,则不可进行上面的诊断规则剔除方法.
4.2 建立故障状态转换图
从例1的简洁故障状态关联规则中剔除仅与系统故障征兆相关的规则,剩余的有:

把以上规则左部和右部项集表示为图的顶点,若存在对应规则,在两点之间连接又向边,形成如下故障状态关联转换图.
在以上图4中的故障状态关联关系转换图中按照项的深度优先顺序对项集进行组织,以提高查找匹配效率.
4.3 基于简洁规则进行故障诊断

图4 故障状态关联关系转换图Fig.4 Transition graph of fault state relationship
在实际的故障诊断中,当一个故障征兆出现时,由图4中可以看到,可触发的规则左部节点可能有多个.例如当状态集{e4,e5}被触发时,状态子集{e4}也同时被出发.在选择触发路径时进行以下算法CRBD(Concise Rule Based Diagnosis)的步骤:
(1)对于给定的故障状态集E:
若仅存在1个包含所有的节点项集包含当前触发的状态集,则输出其包含的故障和概率;否则执行步骤(2).
否则对于当前故障征兆集合E做如下操作:∀A⊆E,若图中节点存在前件项集B⊇A,则选择 其 中 的 项 集C,使 得 support(C) =min(support(B))(B⊇A).输出其转移路径达到的故障和概率.
(2)对任何前件节点项集B⊇E,遍历所有可能的转换路径,当仅有1个转移故障时,则输出其包含的故障和概率;否则:
a)根据用户需要给出可能发生的故障选择集,和相应参数,供用户最后决策;
b)使用多匹配选择机制.采用类似于CMAR算法选择类标号的方法进行决策.
在例1中假设发生故障征兆:(动力系统表面温度超过200摄氏度)(动力系统噪声超过80dB),其对应的项为e3、e4,所有子项集有{e3}、{e4}、{e3,e4};在图4中查找得到对应的项集C为{e3,e4}、{e4};由转换图可得到{e4}触发{f1,e4}、{e1,f1,e3,e4}、{f2,e3,e4,e5}的 置 信 度 为0.6667、0.5000、0.5000.即故障f1、f2触发的可能性分别为0.6667、0.5000.符合现实规律,完成诊断.
5 正确性与性能分析
定理1 基于简洁故障状态关联知识的诊断方法无损表达了原始观测数据的规律.
证明 根据基于简洁故障状态关联规则的定义可知,基于闭模式的性质,能够完全正确计算出所有原始数据中的项集及其支持度.简洁规则是对原始数据规律的无损反映.
由算法RBD 的步骤可知,其诊断的正确性取决于以下两个方面:a)由数据挖掘出的单条关联转移路径的正确性,体现在步骤(1)中;b)多条转移路径的选择方法,体现在步骤(2)中.其中基于闭模式的性质,定理1可以确定算法CMAR 中仅有一条基于频繁项集的规则匹配时,与步骤(1)的定价性.又步骤(2)采用类似于CMAR 的决策方法,故算法整体具有的分类正确率,在设置相同的支持度和置信度时与CMAR 大体一致.
在从观测的数据到故障诊断的过程中,包括了挖掘简洁故障状态关联规则、选择规则建立关联关系转换图、使用最佳规则进行诊断等步骤.其中主要的耗时操作是提取简洁规则的过程并建立预测模型的过程,相比基于频繁项集的关联分类与预测方法,提出的方法需要挖掘的项集要少得多,建立预测方法需要的操作规模也大大降低.同时挖掘简洁项集的提前剪枝方法,提高了挖掘效率.相比基于频繁项集的分类方法,算法能在不损失诊断正确率的前提下,相对提升诊断效率.
6 仿真和实验
实验环境:CPU Intel 2.6GHz,内存512MB,Windows 2000操作系统.本文诊断方法CRBD 由Microsoft Visual C++6.0 编写,算法CBA 和CMAR 由相关文献提供.选取UCI Machine Learning Database Repository 中的数据集Mushroom 来模拟测试数据,此数据集记录了各种蘑菇信息和是否有毒或可食用等特征,有毒和可食用特征用于表示两种故障,而其它属性可表示为状态特征.此数据属于稠密数据,相对于较稀疏的数据,规则的类别区分度较弱,更具有代表性.
算法CBA 和CMAR 基于传统关联规则建立分类模型并进行预测.前者采用多次扫描数据库的方法建立模型且分类器构造也有所不同,总体有效性要劣于后者.本文的方法在有效挖掘简洁项集的基础上产生简洁规则,并在此基础上建立故障诊断方法.
图5显示了在数据集Mushroom 上建立诊断模型时,本文算法需要处理的简洁项集数量要比对采用一般频繁项集的算法需要处理的项集个数成指数级减少.进而在挖掘项集与规则和后续的分类与诊断模型建立过程中,需要花费更多的时间和空间进行处理.
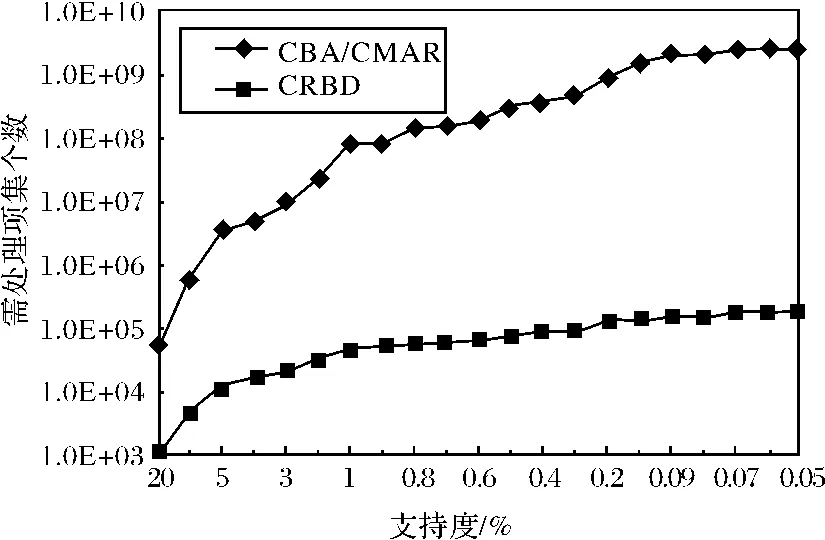
图5 需处理的项集个数比较Fig.5 Comparison results on the number of needed itemsets

图6 运行时间和伸缩性Fig.6 Comparison results on operation time and scalability
本文方法CRBD 在建立诊断模型中决策时部分采用了CMAR 的选择规则建立模型的方法,由于简洁规则本身相对较少,没有选择其数据覆盖的过滤规则方法,故在后续处理方面CRBD 要少于CMAR.设置置信度20%,算法CMAR的数据覆盖阈值为4,置信度差阈值0.2,图6显示了随不同的支持度变化,算法具有的时间效率和可规模性比较.

图7 覆盖正确率比较Fig.7 Comparison results on covering accuracy
图7显示了随不同的支持度变化,算法具有的覆盖正确率比较.诊断算法的正确性一方面是得到的诊断模型对覆盖原始训练数据的分类正确性,这可由算法验证.另一方面是对新数据诊断的正确性,此时当诊断数据包含在训练数据中时,属于第一种情况;而当诊断数据为新的数据时,则算法对数据的预测性主要体现在算法是否对训练数据过度拟合上.在这里比较对训练数据的覆盖正确率.由于CRBD没有使用数据覆盖的过滤方法,多保存了部分规则,相比较CMAR 对训练数据的覆盖正确率上相当,但随着支持度的减小对正确率有一定增加,易产生过度拟合.在实际使用中,可根据需要对参数进行调整.
7 结论
本文采用频繁闭模式进行简洁故障状态关联规则挖掘,利用关联规则具有的分类和预测特性,实现诊断过程.实验结果表明,方法能够根据先验故障状态关联性,在不损失原始先验知识的基础上,为用户提供相对准确的诊断决策.基于压缩的关联知识表达和有效的规则挖掘方法,不仅使得最终得到的模型简洁,且生成效率较高,方法适用性广泛.
[1]刘晓平,郑海起,祝天宇.基于进化蒙特卡洛方法的特征选择在机械故障诊断中的应用[J].震动与冲击,2011,30(10):98-101.
[2]李 兵,张培林,刘东升,等.基于自适应多尺度形态梯度变换的滚动轴承故障特征提取[J].震动与冲击,2011,30(10):104-108.
[3]Agrawal R,Imielinski T,Swami A.Mining association rules between sets of items in large databases[C]∥Raghu Ramakrishnan:International Conference on ACM SIGMOD,Washington D C,USA:ACM,1993:207-216.
[4]Han J,Kamber M.数据挖掘:概念与技术[M].北京:机械工业出版社,2001.
[5]Han J,Pei I,Yin Y.Mining frequent paterns without candidate generation[C]∥Raghu Ramakrishnan:International Conference on ACM SIGMO,Washington D C,USA :ACM,2000:1-12.
[6]Bing Liu,Wynne Hsu and Yiming Ma.Integrating classification and association rule mining[C]∥Raghu Ramakrishnan:International Conference on ACM SIGMOD,Washington D C,USA:ACM,1998:80-86.
[7]Wenmin Li,Jiawei Han and Jian Pei.CMAR:Accurate and Efficient Classification Based on Multiple Class-Association Rules[C]∥Ben Ching Ooi:International Conference on Data Mining,California,USA:IEEE,2011:369-376.
[8]Pasquier N,Bastide Y,Taouil R,et al.Discovering frequent closed itemsets for association rules[C]∥Karl Aberer:International Conference on Database Theory,Jerusalem,Israel:Springer,1999:398-416.
[9]Feng H,Lesot M-J,Detyniecki M.Using Association Rules to Discover Color-Emotion Relationships Based on Social Tagging[C]∥Tamer Ozsu:International conference on Knowledge-based and Intelligent Information and Engineering Systems,Cardiff,UK:Springer,2010∶544-553.
[10]李振兴,尹项根,张 哲,等.分区域广域继电保护的系统结构与故障识别[J].中国电机工程学报,2011,31(28):95-103.
猜你喜欢
一重技术(2021年5期)2022-01-18
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
天津科技大学学报(2018年4期)2018-08-22
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
振动、测试与诊断(2014年5期)2014-03-01
河南科技(2014年3期)2014-02-27
网络安全与数据管理(2010年1期)2010-05-18
