
一种有效的属性约简算法
2013-08-23 10:46:10陆光,李想,王彪
计算机与现代化 2013年8期
陆 光,李 想,王 彪
(东北林业大学信息与计算机工程学院,黑龙江 哈尔滨 150040)
0 引言
一般将机器学习和特征规则学习定义为从给定的特征数据中提取重要的、潜在的、有用的结构模式[9]。众所周知,传统的机器学习方法,如决策树方法(ID3,C4.5)等主要研究的是数据约简的主要过程,也就是说,在保留原始数据分类一致性不变的前提下通过属性约简可以得到原始数据的一个更短的属性值描述。如在约简前,如果对象x确定属于类y,那么在约简后x仍然属于类y。粗糙集理论的观点可以表示为“知识就是一种对对象进行分类的能力”[1],其目的是对原始数据的最大约简,也就是说寻找一种尽可能小的模式以适应训练样本。相对约简(后面用约简代替)是一个最小的属性子集,保留了原始数据的分类一致性,从而能够得到整个属性集的分类[2]。在粗糙集理论[3,10-11]中,属性约简是一个基本的、古典的数学问题,这样可以找到一个更好的或近似的约简,用其去更好地分类未知的对象。本文提出一种算法,可以有效地找到约简,其不只是探索好的约简方法,而且更专注Pawlak提出的数学问题中的核问题,这意味着本文把问题看做是一个总结原数据的问题,而不是一个泛化的问题。因此,本文专注对算法的完整性和计算复杂度进行分析,并完成其他相关工作。
表格知识体系被广泛研究并常用于数据挖掘领域,决策表DT(Decision Table)是表格知识体系中的一种,因此决策表是一类特殊而重要的知识表达系统。一个数据集表示为一个表,表中每一行代表一个对象或者一个事件;每一列代表一个可以描述每个对象或事件的属性。在决策表中,有一个独特的属性,它的值决定了一个对象属于哪个类,称这个属性为决策属性,定义为“d”;称其他的属性为条件属性,条件属性的集合被定义为“C”。假设tc∈C,把表中的第i列表示成 Ci(Ci∈C,1≤i≤tc)并且用(tc+1)列表示决策属性d。在决策表中,如果i<j,则说明表中Ci在Cj的左侧。形式上,一个决策表可以被看做DT=(U,C∪D,V,f),其中 U 是非空有限的对象集,称作全集,即论域;C是非空有限条件属性集;D为决策属性集;C∩D=Φ,C≠Φ,D≠Φ。对于任意一个a∈C∪D,a:U→Va,这里Va叫做a的一个值集[2];最右边的列定义成“d”,决策表根据d的值被分为rD组,称这些组为“D域“,rD为由决策属性d导出的等价类的数目。
一个决策表描述了条件属性知识范畴与决策属性知识范畴之间存在的蕴含关系[1]。如果在一个决策表中,两个对象根据条件属性或者是决策属性被视为是不同的,那么就说这两对象之间有一个分界;如果根据条件属性和决策属性这两者是不同的,那么说它们之间有一个相对的划分。更进一步说,如果两个对象之一同所有其他对象是一致的,那么就说相对划分是有效的。证明约简,包括属性约简和值约简,是保留原有决策表的相对界限的一个过程。
对于保持一致性来说,所有有效相对界限集是充分也是必要的,其证明很简单。本文的任务就是找到一个约简,保留原系统的所有有效的相对界限,形成决策表的一个约简组合,再由Pawlak提出的属性重要度计算出其中的核值,逐次求出除核值以外的属性的重要度,把重要度大于预先设定的最小重要度值的属性加入其中,最终得到一个约简,就像按压海绵,挤压出其两边的水,得到最终的约简。
1 属性约简
1.1SEGMENT-SIG算法基本思想
假设,条件属性是许多工作在一个生产线上的特殊的机器人,他们的任务是划定一些对象,属性约简方案是尽可能少地分配这些机器人,以完成预定的任务。对于许多工作在生产线上的机器人,它的任务是整合划分决定下一个机器的任务。不能直接对一个机器人划分,因为空间复杂度将成为大型应用程序的一个问题。幸运的是,有一个简单的方法,节省了空间和时间复杂度。
假设有一个属性列表s_reduct,要使s_reduct作为最佳约简,它可以包含至少一个约简。算法通过连接一项任务到它的子任务,再由Pawlak提出的属性重要度算法求得的约简属性,产生了一个决策树,一旦找到约简,IF-THEN规则通过最终决策表和读值很容易被构造出来。一个对象的条件属性值会在规则先行词(IF)处形成连接词,决策属性形成规则集(THEN)[2]。
假设有一个小的决策表DT,它包含N个对象,每个对象有一个序列号,有k个条件属性和一个决策属性 d。让{[a,b]i,[c,d]i,[e,f]k}CR作为集合{(x,y)|x∈[a,b]or[c,d],y∈[e,f]}的表示方法。在[a,b]i中小角标 i代表[a,b]分为 D 区域 i,即对任何 x∈[a,b],d(x)=i。因为它不会引起混乱,所以省略上标“CR”。在本文中,[a,b]、[c,d]、[e,f]被称为段。首先,按决策属性d进行排序,由决策属性d可以导出界限集,称 TD 区域,如{[a,b]0,[c,d]1},其中0和1代表由d划分的一类中的值。很明显,所有的相对划分就是TD的一个子集,TD的任何一个子集称为一项任务。值得注意是,一项任务可以表示成段的一个集合。首先考虑最右边的条件属性,看它能诱导出哪一个相对划分,如果这个属性能够明显地诱导出一些相对划分,划分出来的部分称为CTk,那么将属性放在s_reduct中。当CTk不为空时,分裂CTk形成 CTk-1,即下一个任务形成;当 CTk-1=CTk时,则去除当前属性,否则把当前任务中的属性加入到s_reduct中,直至所有任务结束。任务结束后,s_reduct中包含了一些属性,然后运用Pawlak的属性重要度方法对s_reduct中的属性进一步约简,避免冗余的属性出现。首先找到属性集中的核值,把每一个属性的重要度求出来,留下重要度最大的属性,其中属性重要度的度量值可以由专家给出,也可以直接去除重要度为0的属性。
1.2SEGMENT-SIG算法基本步骤
在图1中,CTi中的子任务被连接成一个列表,在子任务1中出现的“k”是子任务片段的编号。这个编号大于1。对于任何属于这些片段的一个对象,“a”是Ci中的它的测量值。级联任务CTi如图1所示。

图1 级联任务的数据结构
在算法的最开始,对象会被决策属性d分类,假设结果是:{Seg1,Seg2,…,SegrD},这样 TD 就形成了,这些rD片段对应rDD-区域,rD的值大于1。这些片段将会根据最右边的条件属性分类。换句话说,它们会分裂形成一些子片段。有相同值的所有子片段会被放在一起形成一个新的任务。级联任务分裂一些属性会产生新的任务,就是它的子任务。这些子任务形成一个新的级联任务。
下面对本文提出的属性约简的一个有效算法进行介绍。
一个正式的ADL描述SEGMENT-SIG算法步骤为:
SEGMENT这个子程序找到一个基本约简s_reduct。
(1)k←tc, /*假设|C|=tc*/;
(2)CTk←TD,s_reduct←{}/*决策属性分裂形成的段TD,设初始约简为空*/;
(3)WHILE CTk≠Ф DO
(IF k=1 THEN标记不一致对象并RETURN返回
分裂 CTk,形成 CTk-1
IF CTk-1≠CTkTHEN s_reduct←s_reduct∪{k -1}
k←k-1.);
(4)return s_reduct /*形成一个由原属性中的部分属性组成的新的决策表s_reduct。*/。
然后运用Pawlak的属性重要度方法[1]:
(1)B=Φ /*设s_reduct的核为B*/;
(2)计算条件属性C相对于决策属性D的核,令B←COREC(D);
(3)如果 PosB(D)=PosC(D),那么 B=COREC(D)∈REDC(D),否则转到第(4)步;
(4)计算对任意的ci∈CB,计算属性重要度sig(ci,B)=|posB∪{ci}(D)|-|posB(D)|,求得 cm=arg maxsig(ci,B)(若同时出现多个属性满足最大值,则从中选取一个与B的属性值组合数最少的属性作为cm),令B=B∪{cm};
(5)输出B∈REDc(D),即得到reduct最终的约简,算法结束。
在决策表中找到约简的主要步骤为:
(1)给条件属性一个order/*最重要的或者是花费代价少的属性应该设置在表的右侧,通过测量的重要性,order次序可以是任意的*/;
(2)由决策属性d分类的对象,形成一个D-区域。假设结果是:{Seg1,Seg2,…,SegrD},TD 形成;
(3)s_reduct←SEGMENT;
(4)reduct←SEGMENT-SIG。
根据选择所要处理属性的次序找到一个约简,一个好的次序意味着好的约简[4]。一般来说,好的先验算法可以形成高质量的近似约简。算法SEGMENT-SIG可以确保近似约简是一个真正的约简。此外,算法可以用一些额外的时间找到更多的约简。
2 算法实例分析及实验结果报告
2.1 实例分析——决策表中的一个例子
举个小例子,一个小的决策表DT=(U,C∪D,V,f),其中 C={C1,C2,C3,C4,C5}。全集中有 11 个对象,首先按决策属性d进行排序,表格及排序结果如表1所示。由决策属性d诱导出的界限集可以表示成{[1,5]0,[6,11]1},称之为 TD。
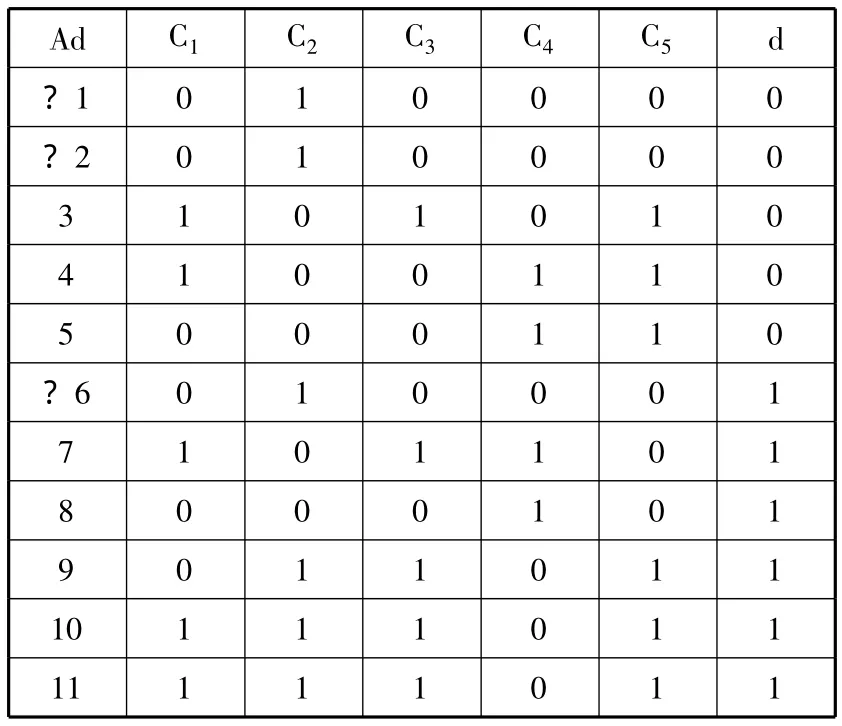
表1 决策表TD排序后的表格
首先观察C5,它可以诱导出哪一个相对分段。属性 C5的值在 TD 中(即[1,5]和[6,11])分组或者分割段,结果可以在表1中看到。很显然,对象x和y可以被属性C5和d划定,对任意x∈[1,2]和y∈[9,11],也就是说,{[1,2]0,[9,11]1}是相对划分的一个集,所以{[3,5]0,[6,8]1}也是。
假设有一个属性列表s_reduct,想要使s_reduct作为最佳约简,初始值为空,它可以包含至少一个约简。首先,把C5放在s_reduct中,因为C5可以诱导出一些相对划分。但是属于[1,2]的对象却不能被属于[6,8]的对象划分,同样适用于[3,5],[9,11],这些对象需要被其他的属性划分。因此,一项新的任务形式是:第一项子任务是{[1,2]0,[6,8]1},第二项子任务是{[3,5]0,[9,11]1}。用 CT5来表示这个新的任务,是两个子任务的合集。本文称CTi为一个级联任务,因为它连通属性 Ci-1决定了 CTi-1。CTi即是之前的比喻,“机器”Ci-1面临的任务。
当CT5≠Φ时,必须考虑属性C4。C5中的段根据C4的值被划分,这意味着C4≠C5。换句话说,C4可以诱导一些相对分割,而不能被C5诱导,因此把C4放在 s_reduct中。显然,{[1,2]0,[6,6]1}和{[3,3]0,[9,11]1}形成一个新的级联任务,可以表示成CT4。值得注意是,CT3=CT4。这样,C3对于{C4,C5}是可有可无的,并且可以跳过。一旦CT2={[1,2]0,[6,6]1}≠CT3,则把 C2放在属性列表 s_reduct中。
因为 CT1=CT2,对于{C2,C4,C5}而言,C1是可有可无的。同时发现{[1,2]0,[6,6]1}是界限,不能被条件属性诱导,但是可以被决策属性诱导。这就意味着,对象1、2、6不能被确定地指定到同一个类里,则用一个特殊的符号“?”来简单地标记它们。对于一个段[x,y]来说,如果任何一个对象 z∈[x,y]被标记成“?”,则称其为段标记。
s_reduct中有 3 个属性:C2、C4、C5(可以简单表示成{2,4,5})。由属性 C2、C4和 C5组成了新的决策表,如表2所示。表2中的属性相比原始表的属性已经约简了不少,然而这并不一定是最终的最简约简(尽管最简不一定意味着最好),所以有必要进行进一步验证。根据属性重要度的方法可以求出新决策表的核值:由于 IND(C)={{1,2},{3},{4},{5,6},{7},{8},{10},{11}},IND(D)={{1,2,3,10,11},{4,5,6,7,8,9,}},POSc(D)={3,4,5,6,7,8,10,11},求得 POS(C -C2)(D)={4,7,8,10,11}≠POSc(D),POS(C - C4)(D)={3,4,5,6,7,8,10,11}=POSc(D),POS(C - C5)={3,4,5,6,7,10}≠POSc(D),故决策表的核值为{2,5},约简属性中除了核值外剩余属性为C4,求得其属性重要度sig(4,C;D)=(8-8)/11=0,故C4对于属性C2和C5而言是可有可无的,故删除C4,所以最终约简为{2,5}。
该算法中,可以采取一个辅助数组“Ad”,如表2所示。
最后,用这种方式得到一个约简{C2,C5}。注意,算法通过连接一项任务到它的子任务,再由Pawlak提出的属性重要度算法求得约简属性,产生一个决策树,如图2所示。

图2 决策树
2.2 实验结果
由上述例子找到约简,IF-THEN规则通过最终决策表和读值很容易被构造出来。一个对象的条件属性值会在规则先行词(IF)处形成连接词,决策属性值对形成规则集(THEN)[2]。如从表2可以写出规则“IF C2=1 and C5=0 THEN d=0”。这里,d的值由多数判决决定。
用本文算法和ID3算法做对比,得到如图3所示的两个决策树:图3(b)是在这个例子当中形成的决策树,图3(a)为ID3算法求得的决策树。显然,本文例子中创造的决策树比ID3算法的决策树要短。这并不奇怪,因为该算法使用属性重要度方法进行第二次扫描,删除所有非必要的属性,根据奥坎氏简化论,这是很有用的,尽管“短”并不总是意味着好。

图3 两个决策树
从图3(a)中所示的树可知,任何一个树的深度都能得出结论,因为在每一节点处有条件值和决策值元素。对于不一致规则,可以得到像“IF C2=1 and C5=0,THEN d=0(2)or d=1(1)”的规则,而不是简单地把最普通的值分配给它们的决策属性值,其中括号中的数字是匹配规则对象的编号。分离的概念形式在现实生活中是非常有用的。如果有一个相应高级的层次概念[5],则可以通过属性定向诱导得到更多的一般规则[6]。
因此,属性约简之后得到两个不同的分类器:一个是规则系统,另一个是决策树。目前分类的有效性是本文关心的问题,决策树的形式是比较常见的,而规则对人们来说更难理解。
该算法时间需求主要是排序。假设SEGMENT实际描述属性的编号是r,表中对象的编号是N,排序需要O(rNlnN)步,这里1≤r≤tc。值得注意是,在SEGMENT中,可以用第二次排序来减轻排序的不规则。算法中另一部分时间是计算两个级联任务的交集,仅需要O(NlnN)步。因此,SEGMENT-SIG算法的最坏的时间复杂度是:O(rNlnN)。
在SEGMENT中,内存中保存的所有级联任务CTi(Ci∈s_reduct)常驻内存,仅用一个级联任务CTi,所有这些级联任务占用O(rN)单元,这些是额外的或者是附加的空间。同时,仅需要总表的一小部分,表的一个或者几个进入到内存,这样仅仅需要O(N)个单元,因此总的空间是O(rN)。然而,也可以在内存中不保存所有的级联任务CTi,而是把这些任务写入磁盘中,可以通过磁碟常驻视图,写入和读出操作,这样算法仅需要O(N)内存空间。
让length(CTi)作为CTi片段大小的编号,对于在SEGMENT中任意的 i∈[2,tc+1],并假设 length(CTi-1)/length(CTi)≤μ(0≤μ≤1),算法最坏的时间复杂度是:O(Min(tc,logμ(2/N))×NlnN),因为有Min(tc,logμ(2/N))个属性要被浏览到。之前最快的算法,称它为 NERS(Nguyen Sinh Hoa and Nguyen Hung Son的算法粗糙集的效率),它得到一个约简需要浏 览 表 Tc次[7],最坏 的时间复杂 度 是 O(Tc2NlnN)。
一般来说,SEGMENT-SIG算法在面临大量的属性时,可以显示出它的优点。但是,众所周知,数据挖掘中更加严格的限制是内存。也许,是由于在面对大量数据集[2](当矩阵中不同元素的数量适中时,它们仍然是不可用的)时,基于算法的差别矩阵是不可行的,而且一些嵌入式RSES文库中的算法并不适用于比预订的规模大的决策表,一般只限于500个对象、20个属性。影响NERS有效性的一个因素是排序中对象的移动。给NERS增加一个辅助数组来避免此类运动,称这种改进为NERSA。NERS和NERSA需要把整个表放在内存中,还规定了对内存的需求。由于已经做出解释,SEGMENT-SIG算法通过把一列或者是几个一步一步放入内存可以避免这个问题,使得它更适合数据挖掘的需求。
当需要挖掘的原始数据数量比较大时,一些其他的算法并不适合,并且用单纯的属性重要度方法进行属性约简显得太繁琐,本算法通过子算法SEGMENT遍历一次后便可以把多余属性去掉,相比单纯属性重要度方法而言,它首先是遵循逐步向前选择的原则,一步步选择属性加入到s_reduct中,之后用逐步向后删除法将不重要的属性删除,该方法得到了至少包含核在内的一个组合,而不需要如单纯属性约简算法那样对属性进行组合,大大节省了计算时间。
3 结束语
本文提出一种简单有效的算法SEGMENT-SIG,可以找到一个约简。该算法约简有两个原因:其一,在大的数据库中找到所有的约简,在文献[8]中已经证明是一个NP-Hard问题;其二,对于一个专家来说,逐次约简几乎是处理不了的。
算法的输出是两种类型的分类器:一个是IFTHEN规则,另一个是决策树。这是SEGMENT-SIG算法的一个优点,其他算法是做不到的。该算法的其他优点就是通过读取部分数据集到内存可以解除内存使用限制,因为它每次只是处理表的一列。
[1]苗夺谦,李道国.粗糙集理论、算法与应用[M].北京:清华大学出版社,2008:132-232.
[2]Komorowski J,Pawlak Z,Polkowski L,et al.Rough Sets:A Tutorial[M].Springer,1998:3-98.
[3]Pawlak Z.Rough Sets:Theoretical Aspects of Reasoning about Data[M].Kluwer Academic Publishers,1992.
[4]Hu Q,Pao W,Yu D.Improved reduction algorithm based on A-Priori[J].Computer Science,2002,29:115-117.
[5]Best J B.Cognitive Psychology[M].Heinle and Heinle Publishers,Boston,MA,1998.
[6]Han J,Kamber M.Data Mining:Concepts and Techniques[M].Morgan Kaufmann,San Francisco,CA,2000.
[7]Hoa N S,Son N H.Some efficient algorithms for rough set methods[C]//Proceedings of the Conference of Information Processing and Management of Uncertainty in Knowledge-Based Systems.1996:1451-1456.
[8]Skowron A,Rauszer C.The discernibility matrices and functions in information system[M]//Intelligent Decision Support-Handbook of Applications and Adbvances of the Rough Set Theory.Kluwer Academic Publishers,1992:331-362.
[9]He Yuguo.An efficient attribute reduction algorithm[C]//Proceedings of the 7th International Conference on Intelligent Data Engineering and Automated Learning.2006:859-868.
[10]王国胤.Rough集理论与知识获取[M].西安:西安交通大学出版社,2001:117-152.
[11]Ivo Düntsch,Günther Gediga.Rough set data analysis[C]//Encyclopedia of Computer Science and Technology.2000:281-301.
[12]Pawlak Z.Rough set approach to knowledge-based decision support[J].European Journal of Operational Research,1995,99(1):48-57.
[13]王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759-766.
[14]张腾飞,肖健梅,王锡淮.粗糙集理论中属性相对约简算法[J].电子学报,2005,33(11):2080-2083.
猜你喜欢
舰船电子工程(2022年4期)2022-05-11 09:34:32
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
电测与仪表(2015年13期)2015-04-09 11:57:36
电测与仪表(2014年1期)2014-04-04 12:00:34
电测与仪表(2014年1期)2014-04-04 12:00:28
河南科技(2014年7期)2014-02-27 14:11:29
