
基于行为的机器人自学习方法研究
2013-08-22 07:34杜宽森
制造业自动化 2013年4期
宁 祎,闫 铭,杜宽森
(河南工业大学 机器人研究所,郑州 450007)
0 引言
自从20世纪80年代中后期,Brooks等人把行为学引入机器人研究领域以来,基于行为的控制方法以其简单、实用、易于实现等优点迅速成为机器人研究的热点。时至今日,已有不少可喜的研究成果[1,2]。但许多对基于行为的机器人研究都是在已知环境参数的情况下对行为选择算法进行各种智能控制方面的设计与优化研究[3~5],不能实现机器人实时的在线学习。
本文提出一种在线学习方法,不给机器人初始化行为信息,而由机器人在行动过程中不断总结经验,自我学习,并能修正错误,以使自身更加适应各种不可预知的环境。
1 机器人模型
要让机器人能自主学习行为,并对行为做出评价,这不仅要求机器人有基本的测距装置,也要有简单的碰撞检测装置。所以,本文以广茂达能力风暴个人机器人为基础,稍做改装,只保留该机器人的驱动机构和碰撞检测装置(即微动开关)。机器人驱动机构(底盘结构)如图1所示。该机器人有2组减速电机组,2个万向轮,4个微动开关组成的碰撞检测传感器,1组锂电电池[6]。

图1 机器人驱动机构

图2 微动开关
微动开关用于对机器人的碰撞检测,以对机器人所做出的行为动作进行评价。微动开关分别位于机器人的左前、右前、左后、右后四个位置,微动开关如图2所示。它们和机器人外周的悬挂式活动圆环共同组成了碰撞检测装置。
给机器人加装超声波传感器,用于探测机器人与障碍物的距离,即感知周围环境信息。传感器分布示意图如图3所示。机器人一共有7个超声波传感器,编号S1~S7,相邻两个传感器之间的夹角为30度。
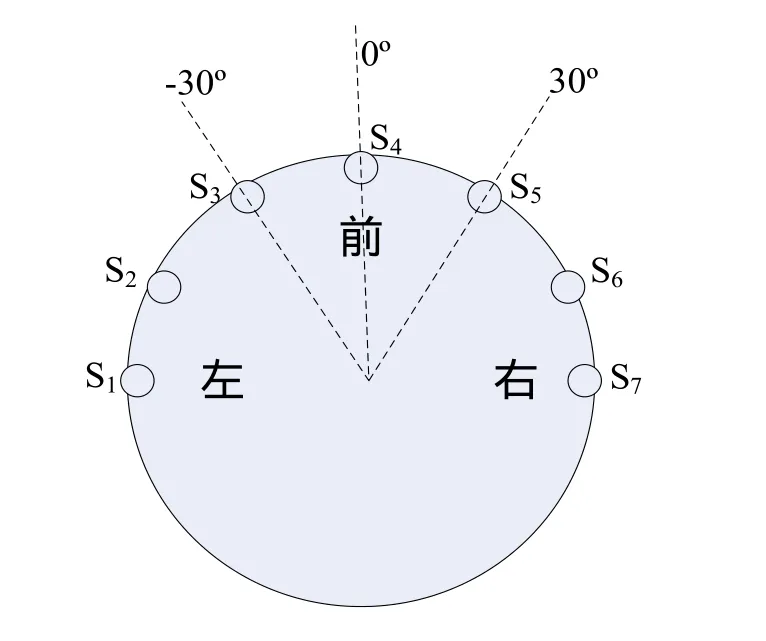
图3 传感器分布示意图

图4 机器人坐标系
机器人由单片机控制。运行时,把机器人看作是一个圆,其半径为r=10cm,机器人所在的位置坐标以圆心坐标来表示。构建机器人坐标系,如图4所示。简单起见,把机器人设置成始终以一个固定的速度v=10cm/s前进。
2 机器人行为设计
在基于行为的机器人学中,机器人的控制系统由一系列的行为构成。行为是为了完成特定任务的控制单元。每个行为根据所要完成的任务进行特定的感知,并输出行为的控制命令。就目前大多数对行为机器人的研究来看,主要把机器人的行为分为目标趋向行为、避障行为、沿墙走行为和漫步行为等。
本文为了研究在线学习方法的效果,把机器人的行为只设计为避障、漫步和沿墙走这三种。不要目标趋向行为是因为本文主要是为了验证机器人的自学习路径规划问题,暂时不考虑目标寻找问题。其结构如图5所示。
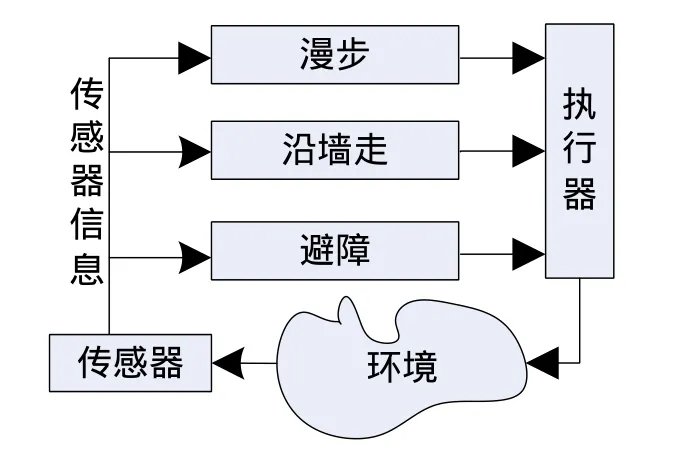
图5 本文设计采用的行为选择机制
3 自学习方法
3.1 方法设计
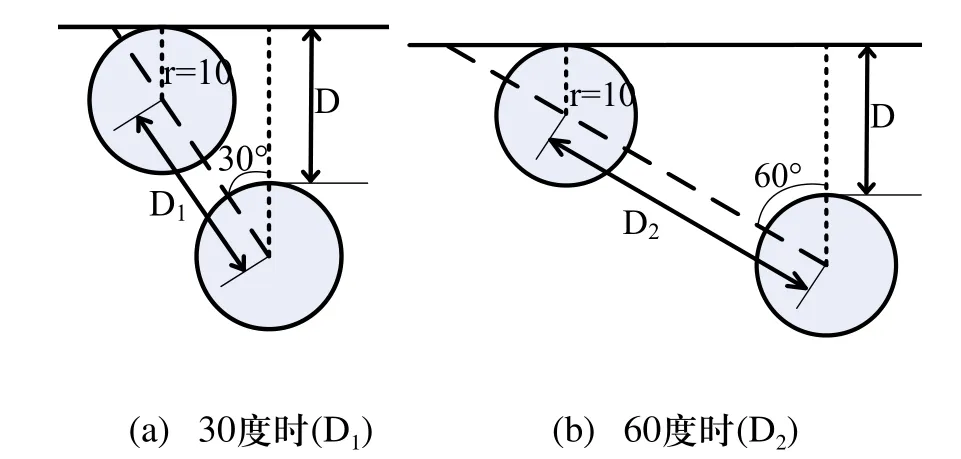
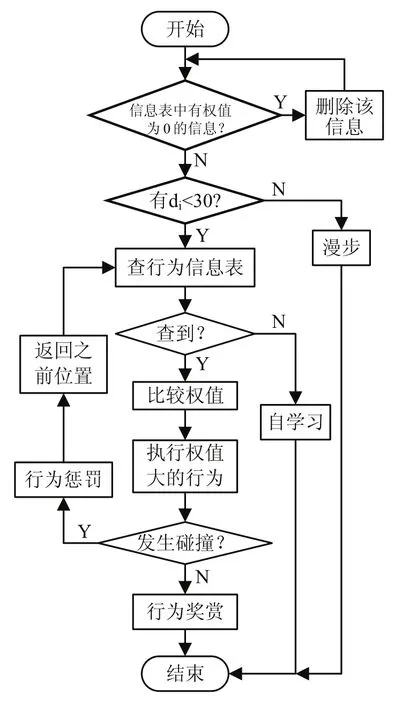
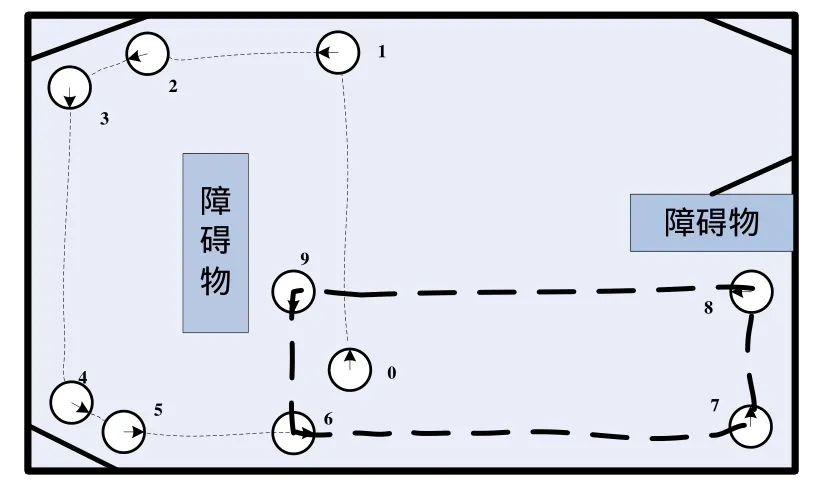
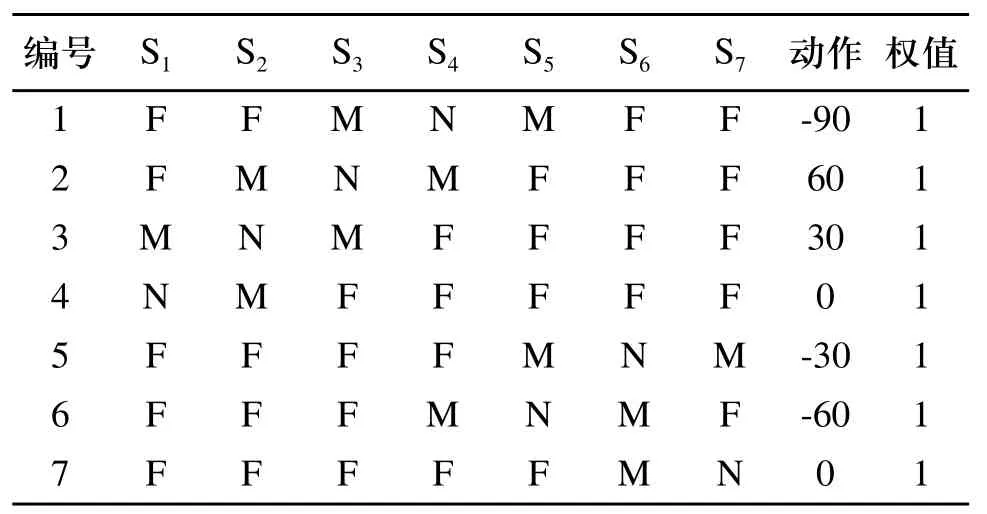
机器人所采用的超声波传感器的有效范围为10cm~4m之间。我们把机器人周围的环境信息,即机器人与障碍物的距离分为三个等级:近(距离D≤15cm,用N表示)、中(15cm 机器人在行进过程中不断的探测自己与周围障碍物的距离。当有传感器探测到离障碍物距离为中或近时,则根据探测到距离最近的传感器所对应的角度值θi,让机器人旋转相应的角度θ(或-θ),然后沿着这一方向运行,行进一段距离后没有发生碰撞,则认为这种判断是正确的,把这种判断与所对应的环境信息记录下来,初始权值为0.1,最大权值为1;若行进一段距离后发生了碰撞,则认为这种判断不正确,回到做出判断前的位置,然后旋转30°+θ(或-(30°+θ)),再行进一段距离,做出判断;若还不能避免碰撞,则旋转角度再增大30°(或-30°),直到不再碰撞,记录信息与行为。行为学习流程图如图6所示。 图6 行为自学习流程图 其中,θi是传感器i所测得的与障碍物的距离最近的传感器对应的角度值,并且θi是θ的函数,即θi与θ满足以下关系: n初始化为0,如果第一次作出的行为决策不正确,则n会自加1,以使机器人旋转更大的θ角。直到机器人判定此行为决策正确为止。 在机器人做出行为判断后,到底行进多远的一段距离才算合适呢?根据传感器探测到的机器人与障碍物的最小距离D,如果机器人转角30度行进,则机器人会在转角后移动的最小碰撞检测距离D1。如图7(a)所示。由图可计算得出D1的最小值为。如果机器人转角60度行进,则机器人会在转角后移动的最小碰撞检测距离为D2。如图7(b) 所示。由图可计算得出D2的最小值为D2=2D。如果机器人正前方有障碍物,则机器人会左转或右转90度,我们设定此时机器人的最小碰撞检测距离为D3=D。因为碰撞传感器是物理装置,在其实现功能时会有一个检测反应距离存在,所以我们给每一个最小碰撞检测距离都加上微动开关的反应距离d=3cm。由上,我们得出最小碰撞检测距离Dis与旋转角θ间的关系为: 在最小碰撞检测距离Dis内,若没有发生碰撞,则认为该行为与环境相符合,即适应该环境,记录信息,以便后来查询。若在最小碰撞检测距离Dis内发生了碰撞,则认为该行为不符合该环境,不记录或做出惩罚。 图7 最小碰撞检测距离 机器人有一个行为处理信息表,这个表初始化是空的,第一次查找是找不到任何信息的,直到有一条学习成功的信息被记录下来为止。当表中有信息时,则先查表中的信息。如果只查到一条符合当前环境的信息表,则按查到的处理情况做出行为决策,若选择该行为后无碰撞发生,给该行为权值加0.1(最高为1),即给该行为一个行为奖赏;若有碰撞发生,给该行为权值减0.1(最小为0,在确定行为权值为0后会删除该记录),即给该行为一个行为惩罚。如果查表得到不止一个符合条件的信息,则比较权值,谁的权值大就以谁的行为来输出,并根据运行结果做出相应的奖赏与惩罚。 本文所提出的机器人自学习方法的总流程如图8所示。首次运行环境示意图如图9所示。经过一段时间测试后,获取机器人第一次运行信息表中的信息,如表1所示。 结合运行环境示意图分析表中信息,当机器人正前方有障碍物时(位置1),机器人随机选择了向左转向90度,并记录下来。当机器人走到位置2时,机器人探测到障碍物离60度方向角最近,所以选择了向左转向30度行进。行进到位置3时,探测到障碍物离30度方向角最近,所以选择了向左转向60度行进。当行进到位置7时,探测到正前方有障碍物,并选择了已有的向左转向90度信息执行。自此点后,机器人一直在一个小区域内运行(图9中的机器人位置6,7,8,9所围成的区域),所以可见表1中第一条信息的权值为1,第二、三条信息的权值只是0.2。与此同时,由第四条信息权值为1可见机器人很好的实现了沿墙走的行为选择。 图8 总流程图 图9 机器人首次运行轨迹示意图 表1 第一次运行机器人信息表 在分析第一次运行结果以后,我们可以发现机器人对运行规则有较好的认识与执行。为进一步验证规则,得到更多的信息,我们在原有信息的基础上对其运行环境稍做改变,再进行实验,如图10所示。运行一段时间后得出信息表如表2所示。 图10 改变运行环境后的运行轨迹示意图 表2 第二次运行机器人信息表 分析第二次运行示意图和得到的信息表,我们发现在第一次运行表的基础上增加了三条信息,且各条信息的权值都为最高。这是因为机器人一直在沿着位置1一直到位置11所示的线路运行,且各个行为均选择正确,没有受过惩罚。至此,机器人信息表已基本建立完成,能够适应示意图中运行环境。 本文提出机器人行为选择自学习方法,在机器人对环境的感知过程中让机器人不断累积经验,并把经验总结成规则记录下来,以便碰到相同环境信息时查找并执行。经实验测试,在简单环境中能够得到比较理想的结果。虽然如此,但仔细分析,发现还是少了一些信息:如当机器人正前方有障碍物时没有向右转的信息。这就需要我们结合实际情况并通过认真分析表中得到的结果,对机器人信息表做个补充与完善,以使机器人更适应运行环境。 这种方法以简单环境为前提,实现起来比较容易,以后可逐渐增加环境障碍,为研究复杂环境下机器人自学习方法提供一个新的思路。 [1] 恽为民.基于行为的机器人学[J].华中科技大学学报(自然科学版),2004,10(32):15-19. [2] 王义萍,陈庆伟,胡维礼.机器人行为选择机制综述[J].机器人.2009,9:472-480. [3] 张惠娣,刘士荣,俞金寿.基于动力学系统方法的自主移动机器人行为设计[J].华东理工大学学报.2008,12:843-849. [4] 谢敬,傅卫平,李德信,等.动态环境下基于行为动力学的移动机器人路径规划[J].西安理工大学报.2008,4(24):411-414. [5] 郝冬,刘斌.基于模糊逻辑行为融合路径规划方法[J].计算机工程与设计.2009,30(3):660-663. [6] 上海广茂达机器人公司.能力风暴智能机器人操作手册[Z].2005.

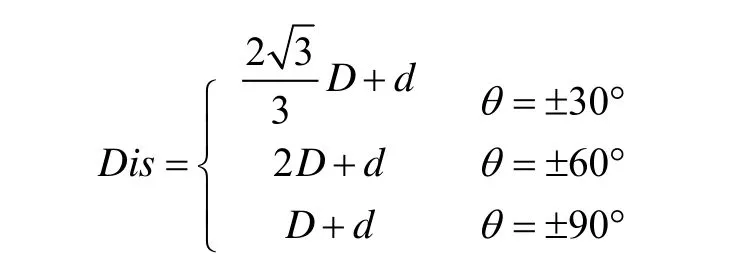
3.2 学习巩固
4 实验测试


5 结束语
猜你喜欢
汽车实用技术(2022年11期)2022-06-20
汽车工程师(2021年12期)2022-01-17
数学小灵通(1-2年级)(2020年9期)2020-10-27
铁道通信信号(2020年10期)2020-02-07
当代贵州(2019年41期)2019-12-13
雷达学报(2018年5期)2018-12-05
雷达学报(2018年5期)2018-12-05
宇航计测技术(2018年3期)2018-09-08
电脑知识与技术(2017年14期)2017-07-10
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
