
M5’模型树在热电厂负荷优化中的应用
2013-08-20 12:57顾雅云胡林献哈尔滨工业大学电气工程系黑龙江哈尔滨150001
节能技术 2013年5期
顾雅云,胡林献(哈尔滨工业大学 电气工程系,黑龙江 哈尔滨 150001)
厂级负荷优化无需对现有设备进行硬件改造即可达到节能减排的目的,有效且简便,是目前发电企业提高经济效益的重要手段。热电厂除提供电负荷外,还提供不同品质的热负荷,负荷种类多,机组的热力特性不单一、约束条件多,因此热电厂的负荷优化较凝汽式发电厂复杂很多,相关的文献研究也相对较少。
汽轮机组的汽耗特性准确与否直接影响到负荷优化的合理性。传统上主要采用基于传统热动力学分析的方法,如热平衡法、等效热降法等[1-2],该类方法计算繁琐,需大量机组参数。对此文献[3]提出了改进方案:将复杂的供热机组根据供热循环和凝汽循环等效为一台背压机组和一台凝汽机组,然后利用考虑辅助汽水因素的单元进水系数法得到等效机组的特性方程。文献[4]使用循环函数法来建立汽耗特性模型,极大简化了计算,提高了精度。近年来则一般采用线性拟合方法,根据拟合数据来源分为工况图法[5]、热力实验法[6]、变工况计算法[7]和运行数据法[8]。汽耗特性随机组老化而变化,因此工况图法误差大;热力试验需定期现场实测,要停机和采用专门的设备与系统,费时、费用高;变工况计算复杂,且不能包括机组运行的全部工况;运行数据未加入任何假设和简化,利用这些数据建立的模型更能贴近机组实际运行特性,且成本低,易于实现。
文献[9]指出供热机组汽耗特性同时存在非凸、非连续性特点,采用多元线性回归方程并不能很好地逼近原非线性的汽耗曲线。M5’模型树[10]算法是一种多输入单输出系统的分段线性化数据挖掘算法,在处理非凸形和非连续性的特性方程方面具有优势。文献[10]基于M5’模型树算法建立热电机组的汽耗特性,但其数据预处理粗糙简单,且最终生成的模型分段数太多,不利于实际应用。
本文首先详细分析采集数据特点,提出一种数据预处理方案,以提高数据挖掘效果,并通过设置结点的最小样本数来控制分段数目,使建模过程可控。然后在此基础上建立实时厂级负荷优化模型,给出应用差分进化算法的求解方法。实例表明:M5’模型树算法建立的分段线性模型不仅精度高且具有实用价值,可方便应用于厂级负荷优化。
1 M5’模型树算法
M5’模型树算法将样本空间分为边缘相互平行的长方形区域,对每个分区确定一个相应的回归模型,包括树的生长、树的剪枝、树的平滑、树的实现等步骤。
1.1 模型树的生长
M5’模型树算法劈分标准是样本属性差异化原则

式中 T——要劈分的样本空间;
T1、T2——劈分后的两子空间;
||——样本数函数;
sd()——目标属性标准差的函数。
按照该原则将样本空间分割成一定数目的子空间,分割的子空间就是树的结点。其中树停止生长的条件有:
(1)结点的样本数少于一定数量;
(2)结点的样本目标属性标准差与总体样本目标属性标准差的比例小于某个限定值。具体的分割实例请看文献[10]。
1.2 模型树的剪枝
M5’模型树算法的剪枝原则
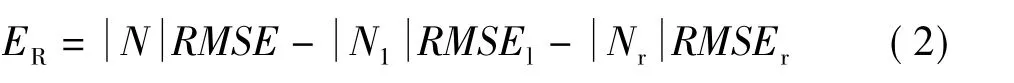
式中 RMSE、RMSEl、RMSEr——分别是根结点,左,右叶子结点拟合方程的均方根误差;
当ER小于0时剪枝,该根结点成为叶子结点,以提高整个模型的简洁性和效率。
1.3 模型树的平滑
使用平滑过程来补偿树相邻叶子节点处的不连续性。平滑方法是将子结点与父结点的拟合方程合并为一个新的线性方程
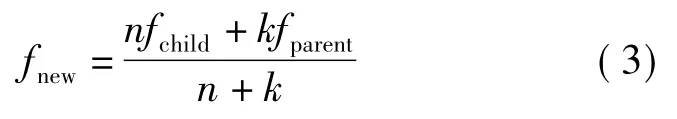
式中 fparent、fchild、fnew——分别是父、子、新结点的拟合方程;
n——到达该子结点的样本数;
k——一个常数。
只有当fnew与fchild的RMSE值相差小于一定的阈值,才进行平滑处理。
1.4 模型树的实现
Weka是基于java的一种数据挖掘工具,简单、使用门槛低。导入预处理后的数据后,选择classify中M5’的classifier,选择目标属性,点击start就可以对导入数据进行训练最后得出模型树,有图形和文字两种表示方法。Weka还可以设置结点的最小样本数来控制分段数目,使建模过程可控。
2 汽耗特性建模
2.1 数据特点
(1)样本/记录:运行数据在计算机中是以样本/记录的形式存储,一个采样时间点形成一个采样样本,一个样本包括该时间点的汽耗流量、蒸汽负荷、热负荷、电负荷、温度、压力等相关数据。
(2)坏数据:数据采集过程可能被干扰,采集回路软件和硬件可能会出现问题,所以采集的数据不可避免地会出现坏数据。
(3)量纲不同:与汽耗流量相关的有蒸汽负荷、热负荷和电负荷等,这些参数的量纲不同,数量级不同,会影响数据挖掘的效果。
(4)不稳定工况:热电机组运行时可能会受到内扰或外扰,扰动后,热力系统处于动态调整中,此时采集的数据就是不稳定工况数据,不能真实反映机组的汽耗特性,不能用做数据挖掘的训练样本。
(5)数据不均匀:机组大部分运行在满负荷附近,中高负荷较少,所以采集的运行数据非常不均匀。若采用不均匀的样本训练会导致训练模型在中高负荷下精度不够,而在满负荷下泛化能力不足,且满负荷附近大量冗余数据会影响数据挖掘速度和性能。
(6)数据连续:自动化系统采集的数据都是关于时间连续的,即相邻样本相隔一个采样周期。
2.2 数据预处理
(1)简化样本:运行数据样本有很多属性,有汽耗流量、蒸汽负荷、热负荷等我们建模需要的,也有汽轮机型等我们不需要的,删去我们不需要的属性,简化样本。
(2)坏数据:识别超过正常数值范围或不满足相关性检测的数据为坏数据,含坏数据的样本称为坏样本。定义样本邻域为与该样本相差不超过3个采样周期的样本。若坏样本的邻域有坏数据,则判断该坏样本已经无法通过插值法来精确补正,应直接删除,并标记一个时间断层。反之则通过插值法进行补正。
(3)不稳定工况:在连续时间内,若两个相邻样本的蒸汽温度和蒸汽压力的变化值超过一定范围就可以判断为不稳定工况样本,做删除处理。
(4)数据不均匀:对于剩余样本,首先按照机组的电负荷,将样本简要划分成不同的区间,然后在每个区间抽取一定比例或一定数目的样本,如中高负荷处可以全部抽取或大比例抽取,满负荷处小比例抽取。这样就可以有效提高数据的均匀度,利于建立精确、泛化能力强的汽耗特性模型。
(5)量纲不同:用标准差化,也就是 Z-score法,消除量纲。标准差化法如下式。
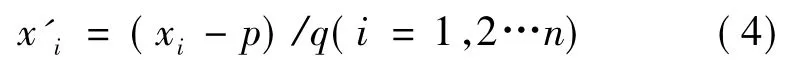
式中 xi、x′i——分别是标准差化前,后的数组;
p、q——分别是数组 xi的平均数,标准差。
2.3 汽耗特性的建模流程
(1)设置数据窗口长度 t,从机组自动化系统[11]历史数据库中收集与抽取最新的时间长度为t的历史数据,形成建模样本库。
(2)对建模样本库,按照第2节介绍的方法进行数据预处理,形成数据挖掘的训练样本库。
(3)将训练样本库导入Weka,选择其中的M5’分类器进行训练,就能得到供热机组汽耗特性的无量纲形式分段线性模型。根据实际需要,设置结点的最小样本数来控制分段数目。
(4)模型还原,通过消除量纲的逆过程,还原量纲,得到还原量纲的汽耗特性模型。
(5)对模型进行评估并和单一线性拟合模型进行对比,评估指标是关联度R、绝对差值率MAE、均方根误差率RMSE。
3 热电厂负荷优化
3.1 热电负荷优化模型
热电厂负荷优化就是在满足总的发电功率、供热(汽)量以及各汽轮机组出力限制的条件下,使全厂的总汽耗量最少。

式中 Q、N、P∑、D1Σ、D2Σ——分别是热电厂总耗汽量,热电机组总台数,总电负荷,总蒸汽负荷,总热负荷;
Hi、Pi、D1i、D2i、Pimin、Pimax、D1imin、D1imax、D2imin、D2imax——分别是第 i台机组的汽耗特性方程,电负荷,蒸汽负荷,热负荷及它们的最小最大值。
3.2 优化算法
热电负荷优化模型是高维、分段线性化模型,传统的优化算法如优先顺序法、线性规划法、动态规划法等无法适用或者效果不好。只能寻求对模型无要求的智能算法来求解,如遗传算法、粒子群算法、蚁群算法、模拟退火算法、差分进化算法等。本文就选择原理简单、受控参数少、鲁棒性强的差分进化算法[12]求解热电负荷优化模型。差分进化算法应用于负荷优化的流程如图1。
图中 NP、Tmax、F、CR——分别是种群规模、最大迭代次数、缩放因子、交叉概率因子;
Uj、Lj——分别是第 j维变量的上下限;
r1、r2、r3——都是[1,NP]的随机整数;
rand(0,1)、r4——都是(0,1)的随机小数;
r5——1到总维数的随机整数。
设置适应度函数如下式
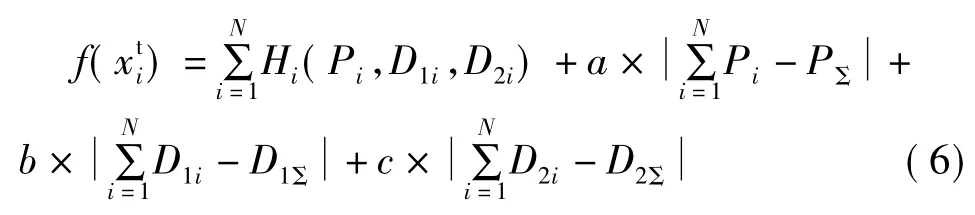
式中 a、b、c——等式约束项的惩罚系数。

图1 差分进化算法应用于负荷优化的流程图
4 算例分析
某热电厂装有3台高温高压单抽机组,数据窗口长度设为一个月、采样周期为1 min。设置结点的最小样本数,生成6个叶结点时机组一的汽耗特性模型如下:

采用传统二元线性拟合,建立的模型如下


表1 二种方法建立汽耗特性模型的R,RMSE,MAE值
表1是对两种方法建立的汽耗特性模型进行对比,评估指标是关联度R、绝对差值率MAE、均方根误差率RMSE。
由表1的关联度R值可以看出:两种方法建立的汽耗特性模型关联度都很高,模型均有意义。由绝对差值率MAE、均方根误差率RMSE可以看出:M5’模型树算法建立的模型更精确,逼近实际特性的能力更强。
在热电厂全部机组最新汽耗特性模型的基础上建立全厂热电负荷优化模型,当总电负荷为65 MW,总汽负荷是70 t/h时,应用差分算法求解得到的最优解为机组一承担17 MW电负荷、7 t/h汽负荷,机组二承担23 MW电负荷、36 t/h汽负荷,机组三承担25 MW电负荷、27 t/h汽负荷,总耗汽411 t/h。由此可以看出,分段汽耗特性模型可应用于厂级负荷优化分配,具有实用价值。
5 结论
(1)汽耗特性模型是热电厂负荷优化的基础。本文基于M5’模型树算法、滚动利用机组最新历史数据建立的分段线性化模型具有实时性强、预测能力高、建模过程可控等优点。
(2)在分段线性化模型基础上建立的实时厂级负荷优化模型可应用差分算法求解其全局最优解,实例计算表明:多段线性化模型可应用于实时厂级负荷优化,具有实用价值。
[1]钟文琪,顾利锋,贾俊颖,等.供热机组热化发电率算法研究[J].热力发电,2002(4):11-13.
[2]吉柱明.汽轮机汽耗量的确定[J].热能动力工程.2012,27(5):565.
[3]李俊涛,冯霄.供热机组的热电负荷分配[J].西安交通大学学报,2006,40(3):311 -322.
[4]王培红,江浩,朱玉娜,等.供热机组特性分析的循环函数法及其应用[J].热能动力工程,1999,14(83):397 -411.
[5]张炜.供热发电机组耗量特性模型研究[J].电力学报,2002,17(2):83 -86.
[6]温志刚,王勇,骆贵兵,等.模拟退火算法在供热机组负荷分配中的应用研究[J].热力发电,2003(7):18-20.
[7]黄锦涛,武学素.应用多元线性回归原理建立300 MW抽汽凝汽式汽轮机组的特性方程[J].动力工程,1993,13(4):16-20.
[8]韩果,汪寿基,汪济龙,等.供热抽汽式汽轮发电机组之间在线最优分配负荷的研究[J].四川联合大学学报,1999,3(2):102 -107.
[9]徐帆,姚建国,耿建,等.机组耗量特性的混合整数模型建立与分析[J].电力系统自动化,2010,34(10):45 -50.
[10]章坚民,刘登涛,吴光中,等.采用 M5’模型树和测量数据识别抽汽式机组汽耗量特性[J].中国电机工程学报,2011,31(23):21 -26.
[11]于达仁,李晓栋,胡清华,等.基于智能信息处理的电厂优化运行技术[J].节能技术,2006,24(4):348 -653.
[12]禹超.母管制热电机组负荷优化分配方法研究[D].哈尔滨:哈尔滨工业大学,2011.
猜你喜欢
大电机技术(2022年3期)2022-08-06
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
河北电力技术(2021年2期)2021-07-29
现代畜牧科技(2021年4期)2021-07-21
水泵技术(2021年6期)2021-02-16
流行色(2020年9期)2020-07-16
家庭影院技术(2018年9期)2018-11-02
CHIP新电脑(2017年6期)2017-06-19
自动化博览(2014年9期)2014-02-28
