
利用深度信息增强的自由视点DIBR技术研究
2013-08-10 12:46:32霍智勇武明虎刘天亮朱秀昌
湖北工业大学学报 2013年1期
霍智勇,武明虎,刘天亮,朱秀昌
(1南京邮电大学传媒与艺术学院,江苏 南京210003;2湖北工业大学电气与电子工程学院,湖北 武汉430068;3南京邮电大学通信与信息工程学院,江苏 南京210003)
1 研究现状
自由视点视频(FVV)的一项关键技术是新视点内容的生成,即虚拟视点渲染合成技术.许多研究机构均在这方面开展相关研究[1].DIBR虚拟视点渲染技术核心思想在于利用深度信息和摄像机参数将已知视点的图像像素投影到未知的虚拟视点.1996年,Seitz提出了一种视点变换方法(View Morphing)[2],这种方法和 DIBR技术的基本原理比较接近.他将参考图像信息还原到三维空间,然后重新投影到虚拟视点的图像平面.1997年,McMillan提出了一种一般场合的视点间的变换公式[3].Oliveira等人使用了单参考图像投影虚拟视点[4],这类方法的缺点在于,当虚拟摄像机距离过远时,虚拟画面中出现的人量遮挡导致的空洞由于缺少信息而难以得到有效的填补,极大的影响了视觉质量.2004年,C.Fehn则提出了在针孔相机模型下,世界坐标系和参考视点的摄像机坐标系重合的条件下,利用DIBR技术绘制虚拟视点的3D渲染方程[5].Zitnick等人[6]提出了基于分层深度图表示的自由视点渲染算法.实验结果由Smolic等人[7]进行了扩展,根据其可靠性识别并分类为三个深度层,然后获得的每一层的图像变形结果合并在一起,采用了三个后处理算法来解决渲染中人工伪影的问题.算法的质量无法测量,但算法需要有相当多的预处理和后处理计算.Merkle[8]进行DIBR计算之前会首先为视点建立深度图.深度图中没有得到定义的像素利用结合了腐蚀和膨胀计算的经验花定义进行填补.基于建立的深度图,通过逆映射得到纹理.利用对应的深度值合并变形后的纹理,前景像素具有优先权.算法结果表明得到的映射结果优于几个其他的算法.Mori[9]的自由视点DIBR的算法采用了一种边界膨胀的方法,能够消除部分遮挡边界上的伪影,并使用了相邻像素填充非遮挡空洞,达到了较好的效果,成为 DIBR的标准参考方法(ISO/IEC JTC1/SC29/WG11,M15377).
2 存在的问题及解决方案
对DIBR的标准参考方法Mori算法存在的问题进行了分析,研究现有算法存在的主要问题,并尝试用新的方法解决.
假设3D点所在的齐次坐标系为Pw=(Xw,Yw,Zw,1)T,由两个摄像机分别拍摄并投影到参考图像平面和合成图像平面的点的位置分别为P1= (X1,Y1,1)T和P2= (X2,Y2,1)T,如图1所示.

图1 参考图像3D变形过程
摄像机i(这里i∈ {1,2})的方向和位置由旋转矩阵Ri和变换矩阵ti=-RiCi描述,Ci为摄像机的中心的坐标,则两个图像平面的像素位置P1和P2为:

这里K1和K2为3×3的摄像机内部参数矩阵,λ1和λ2为尺度因子,假设摄像机1位于坐标原点,C1=03,方向为Z方向(R1=I3×3),尺度因子λ1可以指定为λ1=Zw.
由式(1),原点Pw的3D坐标可以写为
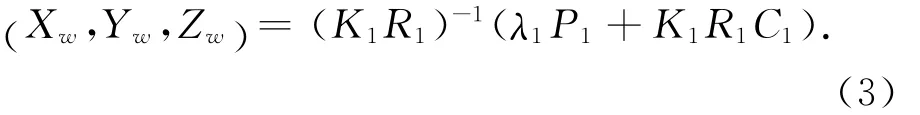
则式(2)代入式(3)得到合成的像素点P2为
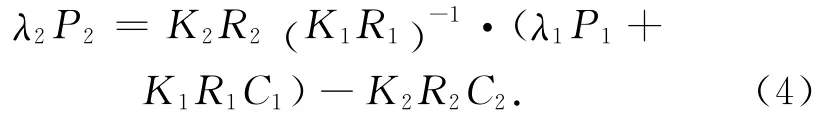
假设摄像机1方向为Z方向,则可以简化为
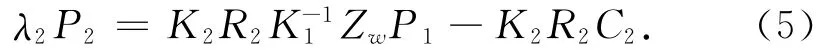
同样,深度图的变形可以写为

这里的D1,D2分别为参考深度图和变形投影后的深度图.
1)反向变形消除裂缝 要面对的第一个问题是变形后图像中的裂缝和空洞,这主要是由于在参考图像的x和y方向上采样而产生.如图1所示,大的空白区出现在每个人物右侧的阴影部分,细小的裂缝出现在人物的左右两侧,都是不遮蔽的.标准参考方法中对付裂缝的方法是图像空间过采样.当在参考图像中沿着x和y方向采样时,采样率是分辨率的2倍,则大部分裂缝会消失,同时执行变形的计算量也增大了4倍,加重了计算的代价.在最初的实验中,结论是仅仅为了消除裂缝就执行过采样,计算代价太大.另一个可能的问题是由于周边选择的像素太多,一些相邻的弯曲像素可能会有错误的值.
这种方法是标记裂缝像素并反向变形,查找对应纹理.该方法分三步:第一步,对变形的深度图进行中值滤波处理.由于深度图包含边缘清晰的平滑区域,中值滤波并不会降低质量;第二步比较中值滤波的输入和输出,标记所有数值发生改变的像素(红色的像素);第三步对改变像素执行一个逆向变形,查找对应的纹理像素(图2).这个方法能很好地消除裂缝,计算量也要小于前一种方法.
根据公式(6),深度图反向映射可以表示为
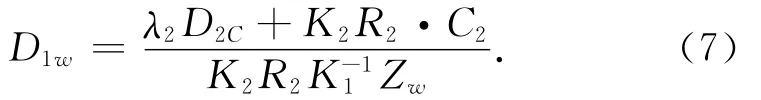
这里D1w为反向变换后的深度图,D2C为改变了的深度像素.

图2 中值滤波后逆向变形消除裂缝
2)背景中伪影的消除 不可靠的深度图会使虚拟视点图像中纹理被扭曲到错误的地方,而这种现象在纹理对象的边缘最为明显,原因是那里深度变化最为剧烈.在深度图中,这些边是清晰的并只有一个像素的宽度.而在纹理图中,它们通常支配着2到3个像素.当进行前向变形时,边缘像素本来在前景纹理的,结果被扭曲到背景中.
DIBR的标准参考方法的解决方案是扩大这个不遮挡区来消除重影的轮廓线.但这个方法存在严重缺点,它不只是去掉了重影轮廓线,而且也修改了纹理像素.这种方法只去掉深度变化剧烈区域边沿的变形像素,由于这个边可能覆盖2至3个像素,因此邻近像素也被抹去.这个方法的优势在于只去掉重影轮廓,但前提是需要找到非常不连续的部分.这里简要说明一下如何实现.作为前景,目标对象周围都存在相邻前景像素.一般的做法是,首先比较每个像素和它周围的8个像素,以便确认是不是最不连续的区域.只要它的相邻像素有一个是前景像素,就已经认为该像素是重影轮廓.因此检查每个像素是否满足条件:
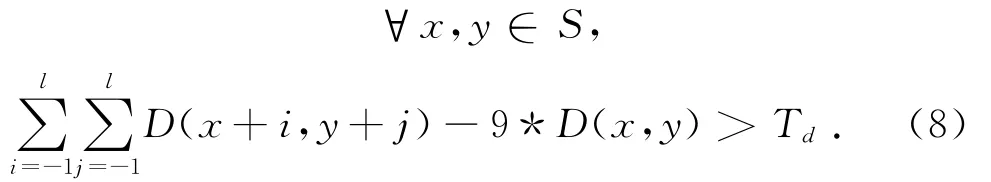
这里S是图像空间,D标示参考图像的深度图,Td是预先定义的阈值.
如图3所示,如果放大这个不连续区域的边缘,就可以看到这些边缘的纹理存在前景和背景的混合.因此我们发现:如果直接忽略掉这些边缘的变形像素效果更为明显.去变形唯一没有被当作重影轮廓的那个像素.将每个像素带入公式(8)中,判断像素是否需要变形.这个方法的好处是不需要抹去重影轮廓这一步.但由于边缘通常有两个像素宽度,不得不给当作重影轮廓的边增加一个像素.
图3 非常不连续的边缘部分
3)剩余空洞的填充 在混合两个投影图像时,遮挡区域可能仍然存在.这个区域在参考摄像机中是看不到的.目前的inpaint填充技术都是用于小块图像区域的.这些区域可以用遮挡区域的边缘像素来填充,以便保持那里纹理的结构.虽然这些技术有很好的效果,但是往往填充区域还是会留有某些模糊的情况.
在填补遮挡区的应用中,遮挡不仅仅是随机出现的区域,而且作为新的背景的一部分,没有任何纹理信息,完全与前景无关.当遮挡区是背景时,可以利用遮挡区边缘的深度信息来填充更精准的纹理.
填充过程如下:首先对于最靠近边缘的像素,在8个方向搜索遮挡区的每个像素;这里仅考虑具有最低深度值的边缘像素.这些像素根据公式(9)计算加权平均值.这个方法的好处是前景与背景之间不存在模糊的问题.缺点是当遮挡区面积比较大时,填充区域就成为低频小块.填充算法是基于不含纹理值的邻域像素加权内插,表达式为
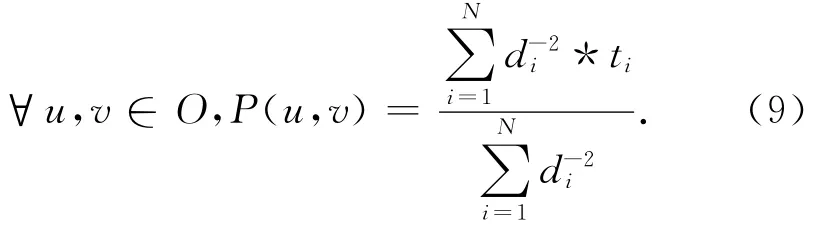
这里的O是遮挡区,N是在背景中边缘像素的数量,d是P到遮挡区边缘的距离,t是边缘像素的纹理值.计算时逐一处理遮挡区中的每个像素,以便在保证算法复杂度的前提下,实现尽可能高质量的输出效果.
3 算法结构
完整的基于深度信息增强的DIBR虚拟视点渲染算法分4步进行.首先对参考摄像机图像进行3D变形,并同时将深度和纹理图3D变形到虚拟视点.投影图像的裂缝利用中值滤波来处理,滤波器的窗口宽度为3×3像素.改变的像素再逆向变形回参考摄像机图像,找出其中的纹理.为了去掉重影轮廓,检查用于变形的所选像素,深度变化剧烈的前景边缘区域的边不去做变形处理.剩下的空洞利用inpaint的方法进行填充,最后对两路生成的渲染图像进行混合.下面介绍一下具体的算法步骤.
第一步:同时对参考视点的纹理图和深度图进行3D变形,该位置由深度图变形所定义.变形过程由下面的表达式定义:
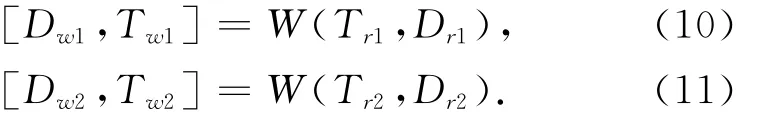
这里Tr1和Tr2分别是两个参考摄像机的纹理图,Dr1和Dr2分别是两个参考摄像机的深度图,W是3D变形函数,如式(10)、(11)所示,Dw1和Dw2分别是Dr1和Dr2变形后的深度图,Tw1和Tw2分别是新视点中的纹理图.
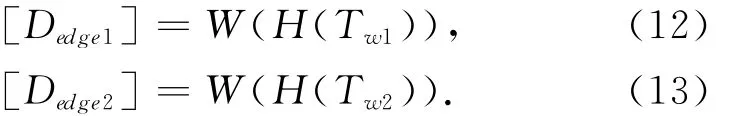
比较每个像素和它周围的8个像素,以便确认是不是最不连续的区域.函数H标记深度变化剧烈区域的像素,变形这个像素,然后从前景中抹去.根据公式(8),取阈值Td=80,阈值的取值一般在最大深度值的1/4左右.Dedge为变形后的轮廓像素.
第二步:中值滤波和定义修改的像素.
首先对Dw1和Dw2进行中值滤波,找出并标记改变了值的像素位置Iw1和Iw2.这个计算表达式为:

这里的M表示窗口大小为3×3的中值滤波,C函数检测像素是否在中值滤波中发生改变.
第三步:通过反向变形填补纹理裂缝.
变形后的纹理图像中的裂缝利用方向变形进行填补,变形时从虚拟视点反向变形到参考摄像机视点.W-1的表达式见式(7),这种反向修复的表达式:
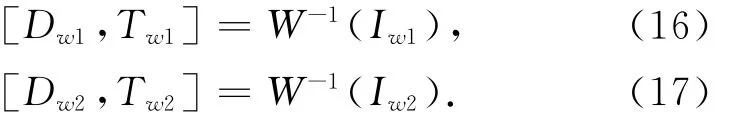
第四步:创建新视点的纹理.
这一步包括填充和混合两项任务.分别填充两个变形纹理图,然后混合函数实现结果图像的混合,表达式为
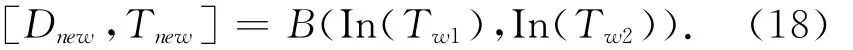
这里的In为填充函数,B为混合函数.
由于选用的参考视点处于虚拟视点的两侧,一个视点的遮挡区域在另一个视点中未必被遮挡,因此,绝大多数由遮挡引起的空洞可由不同视点的像素互补填充,从各个参考视点得到的虚拟视点公共部分则根据虚拟视点与参考视点的距离,由α混合加权得到最终像素颜色,如公式(20)所示,对于同一位置的像素颜色,距离越近的参考视点得到的权值越大,α混合后剩余的空洞则交由后续步骤处理.

这里
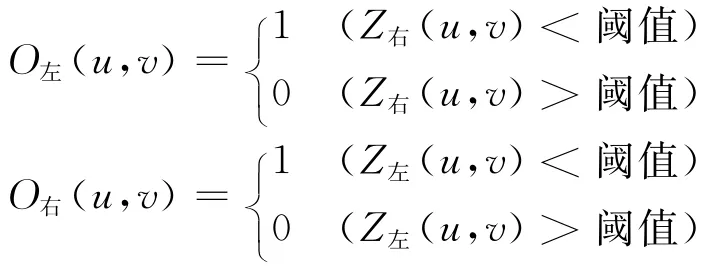
公式(19)中,I左表示由左参考视点变换得到的虚拟视点(u,v)处的像素值,I右表示由右参考视点得到的虚拟视点.I则表示最终的虚拟视点,O表示相应的虚拟视点位置 (u,v)是否处于空洞区域,Z是虚拟视点位置(u,v)的深度值,α的值与虚拟视点和已知的参考视点之间的距离有关,如式(20)所示,t,tl,tr表示相对应摄像机外部参数中的平移向量.
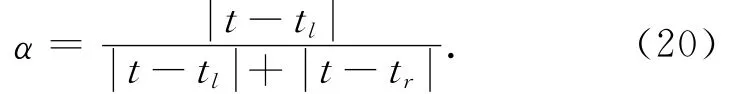
4 实验仿真结果
本文选择了微软研究院交互视频组的多视点数据集“Ballet”和“Breakdancers”视频序列作为测试场景,如图6和图7所示.算法生成的视点图像与Mori的算法结果进行了比较.这两个测试视频序列分别包含100帧纹理和对应的深度图,分辨率为1024×768像素.场景由8个摄像机沿着圆弧的视点同时拍摄,装置图见图4.每帧图像都有对应的深度图.




其中第5个摄像机光学中心坐标为世界坐标系原点.深度图中的像素值P与真实的深度值Z之间的关系为
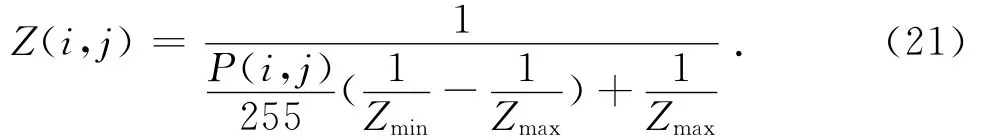
这里的P是深度图的亮度值,“Ballet”视频测试序列的Zmin=42.0,Zmax=130.0,Breakdancers视频测试序列的Zmin=44.0,Zmax=120.0.
下面从测试序列中任意选取图像进行DIBR新的视点图像生成实验.
图8为纹理图进行3D变形后得到的新视点的纹理图的裂缝填充实验结果,从图中可以看到包含有明显的裂缝和大的空洞.图8b为算法对裂缝进行了消除后的结果,图8a中原有的裂缝已经被去除,画面纹理结构完整,可以观察到前面人左边还有明显的黑色的大块区域,这是画面中包含的空洞.这些空洞通过后面的inpaint流程加以消除.

图8 变形后的纹理图进行裂缝填充
图9为深度图进行变形后得到的新视点的深度图的填充结果,从图中可以看到包含有明显的细线状的裂缝和大片的黑色区域.图8b为算法对裂缝进行了消除后的结果,图8a中原有的裂缝已经被去除,画面纹理结构完整,可以观察到前面人左边和裤子上还有明显的黑色的大块空洞.

图9 变形后的纹理图进行裂缝填充
图10为提取出来的裂缝和空洞进行填充的实验结果,从图中可以看到变形后存在于纹理和深度图中的细线状的裂缝和大片的白色区域,这些区域由于变形后没有数据,以零值填充.图10b为算法对裂缝进行了消除后的结果,图10a中原有的裂缝已经被去除,但可以观察到前面人和后面人的左侧和裤子上还有明显的白色的大块空洞,观察效果比纹理图中明显.
图11是消除变形后纹理图中伪影实验结果,图11a中可以看到人物头部左侧有明显的伪影,通过本文的消除算法,可以观察到重影被有效的消除了,如图11b所示.
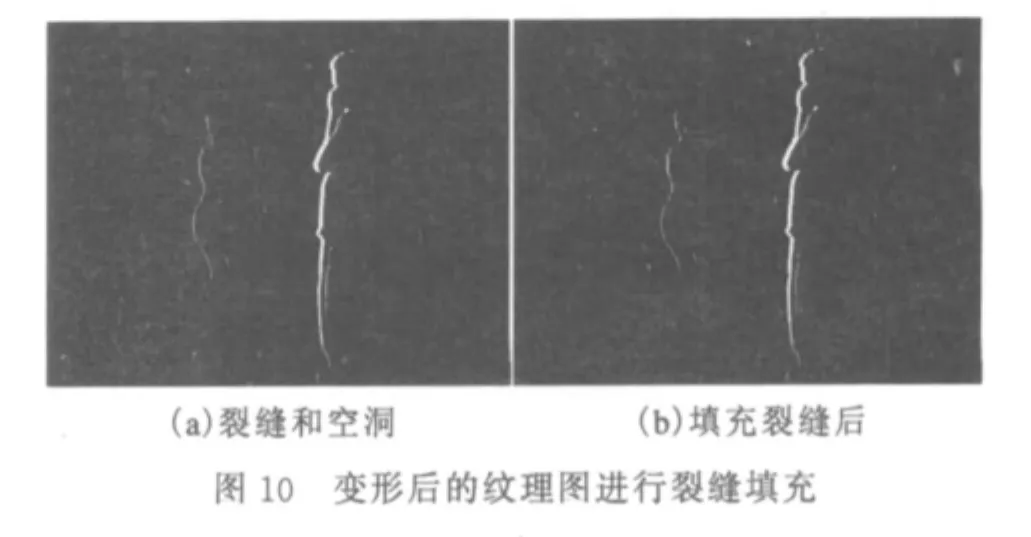

图12为算法对空洞进行了inpaint后的实验结果,画面中还包含有大块的黑色空洞区域,未填充前为零值.图12a中原有的空洞已经被去除,可以明显观察到右侧画面中前面人和后面人的左侧和裤子上的大块空洞,已经被有效以新的纹理数据填充,达到预期目标.

图12 纹理图中剩余空洞的填充
图13a图为Mori算法生成的新的纹理图的结果,图13b图与图12b相同,为合成的新视点的纹理图.

图13 Mori的算法和本文算法的结果对比
通过对比可以观察到,图13a中前面人和后面人的左侧仍然有明显的重影存在,画面左侧墙上还有一条明显的黑色细线,裤子上的大块空洞也察觉不到,已经被新的纹理数据有效填充.通过对比,从主观观察来看,可以明显看出本文算法的效果要比Mori算法结果好.
在两个视点图像(图14、图15)之间进行了虚拟视点内插的实验,在“Ballet”和“Breakdancers”数据集中任取相邻两视点,摄像机间距为20cm,三个内插视点的α分别取1/4、1/2、3/4.每行左右两端的图像帧(a)和(e)为原始参考图像,中间的3个图像为视点生成的图像,如图(b)、(c)和(d)所示,从结果可以观察到,生成视点质量较好,没有非常明显的伪影和空洞.


下面将进行两项质量评价:PSNR评价包括了与视频压缩有关的渲染视点的摄像机配置和扭曲.由于摄像机的数量有限,摄像机配置的首要目的就是为了获得高质量的自由视点渲染.
第一项测量是通过改变相邻摄像机之间的角度,研究对最终渲染的质量.RGB图像被首先转换到YUV色彩空间,然后计算Y的峰值信噪比(PSNR).
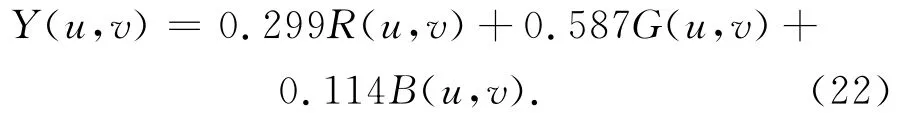
PSNR的计算表达式为

均方误差(Mean Squared Error,MSE)的计算表达式为
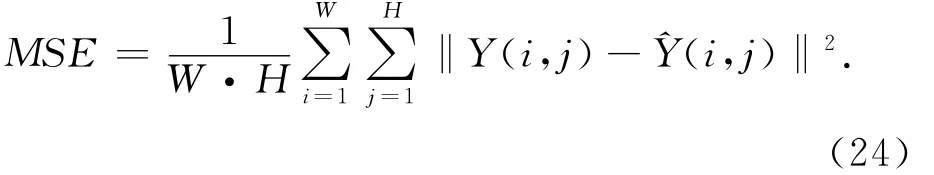
结果如图16所示.测量是随机选择20个图像帧进行的.从图中可观察到,对于测试场景(a)图“Ballet”和(b)图“Breakdancers”,与 Mori提出的算法相比,PSNR平均提高了4dB左右.这么明显的提升主要原因在于两个方面,一是利用中值滤波取代双向滤波,二是inpaint填充算法中利用了深度信息.主观品质也能感觉到有小幅的改善,主要是一些前景对象的边缘更加平滑.
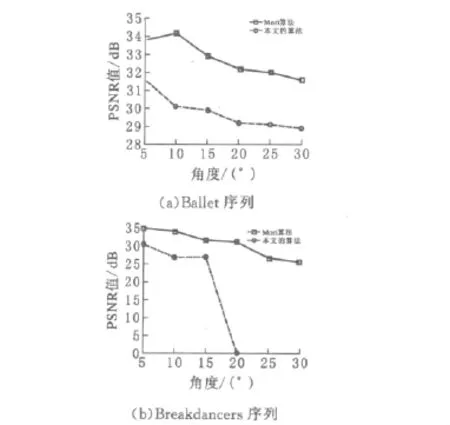
图16 摄像机之间角度改变对合成图像PSNR的影响
第二项测量分析了编码对渲染质量的影响.我们使用常规配置的H.264对周围的摄像机流进行编码,目的是找到联合优化的量化参数,编码器的质量参数,qmin=22,qmax=52.为此首先创建出联合深度和纹理率失真表面曲面,通过搜索以便找到最小的失真,尤其是优化参数.
渲染的质量对于每个联合比特率都可以表示为PSNR最大化.H.264的率失真曲面如图17所示.率失真曲面的计算参考了 Morvan的方法[10],为了最小化这些曲面上离群点的数量,从测试序列中随机选择10帧进行测量并取平均值,每一帧的纹理和深度图的分辨率为1024×768.图18为联合纹理深度比特率的渲染质量曲线,这里的比特率为纹理和深度图的编码比特率和.

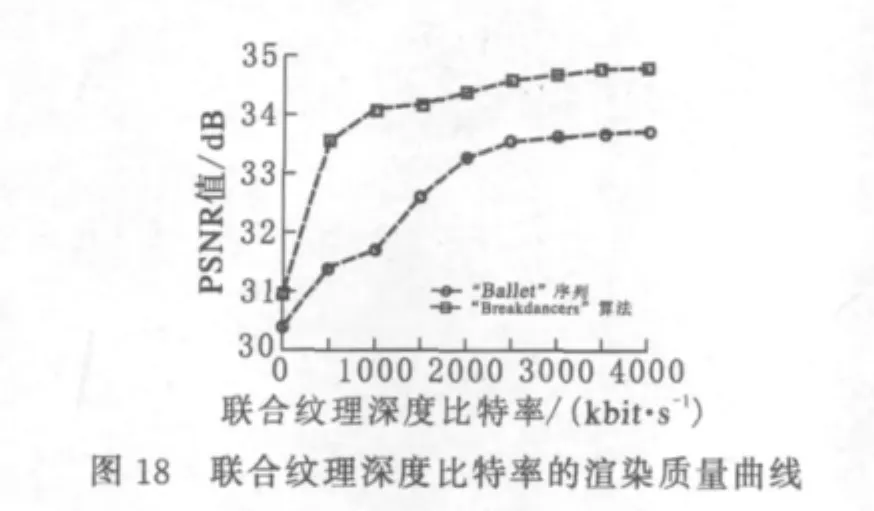
由图17、18可以看出,深度和纹理的比特率达到1 500kbit/s后,渲染的质量就没有太多的改善.这意味着取更高的比特率对于渲染质量的影响不大,影响最大的还是渲染算法,而不是来自相邻摄像机的视频流的压缩.
5 结论
本文研究的渲染算法可以实现两个参考视点之间的自由视点生成计算.在每个参考视点都有好的深度图的情况下,算法可以获得比较满意的虚拟视点生成结果.对于DIBR渲染过程,分析了面临的主要问题,重点放在人工伪影的消除方法上.首先,渲染产生的裂缝利用反向变形进行消除,这个方法的优点在于填充裂缝时计算量不大,不要为新视点生成深度图.其次,给出一种遮挡区的处理方法,对于深度剧烈变化的区域可略去边缘的变形.虽然方法简单,但是实际效果很好.最后,给出了利用了深度图信息解决遮挡区的重绘(inpaint)方法,可以避免由于内插所造成的纹理图质量下降.
总的来说,本文提出的算法比现有的Mori算法性能要好,特别是当参考摄像机角度变化时,其效果更加明显.而且,在保证渲染质量的同时,所需的算法复杂度较低.此外,还证明了在H.264编码时,提高编码比特率对于渲染质量的改善贡献有限.
[1]Koch R,Evers-Senne J.3DVideo communication algorithms,concepts and real-time systems in human centered communication[M].Wiley,2005.
[2]Seitz S M,Dyer C R.Toward image-based scene representation using view morphing[C].In Pattern Recognition,1996,Proceedings of the 13th International Conference on,1996:84-89.
[3]McMillan Jr L.An image-based approach to three dimensional computer graphics[D].Citeseer 1997.
[4]Oliveira M,Bishop G.Relief textures[C].University of North Carolina at Chapel Hill,Chapel Hill,NC,1999.
[5]Fehn C.Depth-image-based rendering (DIBR),compression,and transmission for a new approach on 3DTV[C].In Electronic Imaging 2004,2004:93-104.
[6]Zitnick C L,Kang S B,Uyttendaele M,etal.Highquality video view interpolation using a layered representation[C].In 2004:600-608.
[7]Smolic A,Muller K,Dix K,etal.Intermediate view interpolation based on multiview video plus depth for advanced 3Dvideo systems[C].In 2008:2 448-2 451.
[8]Merkle P,Morvan Y,Smolic A,etal.The effects of multiview depth video compression on multiview rendering[J].Signal Processing:Image Communication,2009,24(1):73-88.
[9]Mori Y,Fukushima N,Yendo T,etal.View generation with 3Dwarping using depth information for FTV[J].Signal processing:image communication,2009,24(1):65-72.
[10]Morvan Y,Farin D,de With,P H N.Joint Depth texture bit-allocation for multi-view video compression[C].In 2007.
猜你喜欢
计算机应用(2019年3期)2019-07-31 12:14:01
故事作文·高年级(2017年2期)2017-03-01 13:03:27
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
河南电力(2016年5期)2016-02-06 02:11:24
新闻传播(2015年20期)2015-07-18 11:06:46
新闻前哨(2015年2期)2015-03-11 19:29:22
中国水利(2015年5期)2015-02-28 15:12:40
世界科学(2013年11期)2013-03-11 18:09:47
上海大学学报(自然科学版)(2012年5期)2012-10-16 07:23:36
