
云南失业率影响因素分析和回归诊断
2013-08-10 06:23朱琳陈飞
当代经济 2013年4期
朱琳 陈飞
(云南财经大学统计与数学学院 云南 昆明 650221)
一、引言
失业率是指失业人口(一定时期有工作意愿而仍未有工作的劳动力人口)占劳动人口的比率。失业是市场经济不可避免的一种经济社会现象。但失业人员数量过多,失业率过高,不仅会给失业者本人及家庭带来极大冲击,也会对经济发展和社会稳定构成重大威胁。因此,把失业率控制在社会可承受的范围内,是市场经济环境下国家政府的重要目标之一。
目前国内关于失业率的研究已取得一定的成果。田力(2003)研究了影响失业率的主要因素及降低失业率的对策,利用数学的穷举法,就影响供给的因素、影响需求的因素以及同时影响供求双方的因素三个方面,分析了与失业密切相关的七大因素,但其研究缺乏一个量化的统计模型。程红莉和刘强(2003)以全国30个省市的相关数据为样本研究了区域失业率差异影响因素。陈幼芳和张天会(2006)对云南的失业率进行了预测和研究,其贡献在于给出了比较全面的预测模型,但是缺乏对模型的检验。本文使用线性回归模型对云南省失业率的影响因素进行实证研究,通过变量选择方法,筛选得到了对失业率具有显著影响的因素,并建立了拟合模型,该模型通过了异方差性、序列相关性和异常值检验。
二、数据与变量选择
1、数据来源
本数据来源于云南统计局网站(http://www.stats.yn.gov.cn/TJJMH_Model/default.aspx)上统计公报公布的2001—2011的相关数据。
2、变量选择
本文的失业率的影响因素的研究主要考察在众多因素中哪些因素对失业率具有显著的影响。我们首先给出自变量的待选变量集。奥肯定律认为经济增长与失业率是负相关的,故首先考虑把GDP引入待选变量集中。此外,由于失业保险是解决失业所产生的不利因素的社会机制,故考虑把享受失业保险人数、失业保险参保人数、失业保险金收入额也引入待选变量集中。云南劳动力资源供给的潜力相当大,这将给云南的就业形势造成不容忽视的压力,故而把人口总数也引入变量集。固定资产投资是生产规模的重要表征,对就业情况产生着重要影响,故此,应将其也引入变量集中。综上,我们选取失业保险参保人数(十万人)、享受失业保险人数(万人)、GDP(千亿元)、人口总数(千万人)、失业保险金收入额(亿元)、生产性固定投资总额(百亿元)为自变量,以城镇登记失业率(%)为响应变量。
三、模型的建立
1、用普通最小二乘法(OLS)估计模型
综上分析,我们建立云南省失业率影响因素分析的六元回归预测模型:
y=a0+a1x1+a2x2+a3x3+a4x4+a5x5+a6x6
其中,x1系参保人数(十万人)、x2系享受失业保险人数(万人)、x3系 GDP(千亿元)、x4系人口总数(千万人)、x5系失业保险金收入额(亿元)、x6系生产性固定投资总额(百亿元)、y系城镇登记失业率(%)。
回归方程的F检验的p值为0.016<0.05,这意味着,在5%的显著性水平下,解释变量对被解释变量的联合线性影响是显著的。而系数的t检验中,p值最小的为0.208,故在5%显著性水平下所有系数均不显著,即每个解释变量对被解释变量的线性影响均是不显著的。这说明模型自变量间很可能存在多重共线性。事实上,t-检验中解释变量都不显著,可能是由于某些自变量对因变量的影响被其他自变量掩盖了。为了检验多重共线性的存在,先求出自变量的样本协方差矩阵,并求得该协方差矩阵的条件数(最大特征值与最小特征值之比)为1.7914*104,这说明六个变量之间存在很严重的多重共线性。故此,分别通过逐步回归法和AIC准则进行自变量的选择。
2、使用逐步回归法进行变量选择
对六个自变量采用逐步回归方法进行变量筛选,用SPSS软件逐步回归的结果如表1所示。

表1 逐步回归法选择的变量回归系数表
逐步回归结果显示选择的自变量应当为失业保险参保人数(x1)和人口总数(x4)。在5%的显著性水平下,他们的p值分别为.000和.000,表明这两个解释变量对方程的影响是显著的。为了进一步确证上述变量选择结果,我们使用AIC准则对一些重点待选模型进行比较。比较结果如下:仅包含x1、仅包含x4和包含x1和x4两个自变量和其他任意自变量搭配的模型,其AIC值均大于只包含x1和x4两个自变量的模型的AIC值。可见,AIC准则提供的变量选择的结果与逐步回归法一致,均选择x1和x4。
以y为因变量,以x1和x4为自变量的回归模型拟合结果如下:

在5%的显著性水平下,所有解释变量系数的t统计量的P值均小于0.05,故所有系数均不显著为0,即每个解释变量对被解释变量的线性影响均是显著的。F检验(p=0.000<0.05)的结果显示方程显著,即在5%的显著性水平下解释变量对被解释变量的联合线性影响是显著的。
四、异方差性的White检验
由异方差性的White检验来看,F统计量的p值为0.3869,在5%的显著性水平下,落在接受域内。所有的交叉项和独立项的p值也都落在接受域内,说明无法拒绝原假设,所以模型中不存在明显的异方差性。
五、序列相关的检验
六、异常点检验
异常点即为在预设统计模型下明显与大多数数据点的统计规律不一致的数据点。在线性模型下,异常点可采用下述的均值漂移模型来检验,该模型的向量形式可表示为Y=Xβ+hiγ+ε,hi=(0,…,1,…,0)T。其中 hi中第 i个元素为 1,其余元素为 0,X为自变量矩阵,Y为因变量向量。若γ显著,说明第i个点的均值有漂移,则该点不符合既定的线性回归方程,从而说明第i个点为异常点。为了检验γ是否显著,我们采用参数显著性检验方法。
对异常点的检验过程如下:新增加一个自变量z,可疑点所对应的取值为1,其他元素取值为0,在模型(1)加入变量z再进行线性回归,若z的系数显著,则判定相应的样本点为异常值点。经过计算,在5%的显著性水平下,2000年和2002年的数据中变量z通过了系数的显著性检验(其p值分别是0.014和0.006),故判定其为异常值点。
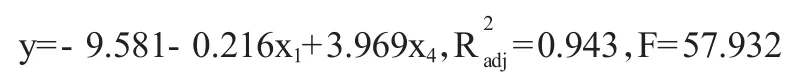
将2000年和2002年的数据点剔除,利用剩余十个年度的数据重新进行逐步回归得到由x1和x4组成的模型,并得到以下的拟合方程:可见,剔除2000年和2002年的异常点后变大了,表明模型的拟合优度得到了改善。F检验(p=0.000<0.05)的结果显示方程显著,即在5%的显著性水平下解释变量对被解释变量的联合线性影响是显著的。该模型也通过了异方差和序列相关检验。上述拟合模型即为我们最终所得的失业率对失业保险参保人数和总人数的线性回归模型。
七、模型的解释与几点启示
从上述模型看,在失业保险参保人数、享受失业保险人数、GDP、人口总数、失业保险金收入额和生产性固定投资总额这些自变量中,对失业率影响最显著的是参保人数和人口总数。失业保险参保人数和失业率呈负相关,这说明失业保险对保障失业人员的基本生活、降低失业者的再就业成本具有显著意义,对就业起到积极的促进作用。人口总数和失业率呈正相关,说明人口增长给就业带来了不可忽视的压力。虽然,本文中使用的失业率是城镇登记人口的失业率,而云南省是一个农业大省,农村人口占大多数,然而,近几年进城务工的农村劳动者人口数的不断攀升,仍给城镇劳动者的就业带来一定压力。某一地区流动人口的大量增长会在短期内造成该地区劳动力市场的失衡,对本地区居民就业产生压力,但流动人口也对本地区经济增长提供了劳动力的支撑。面对由于这种原因造成的失业,各地区应采取的措施是有效完善劳动力市场、加快劳动力市场的信息化建设、促进经济增长带动就业以降低失业率。模型表明GDP对失业率的影响不显著,这表明云南省经济增长对降低失业率的贡献不大,这似乎与奥肯定律相违背,奥肯定律认为针对整个国家而言,经济增长会引起失业率的下降。GDP对失业率的影响不显著的原因除了经济增长地区吸引劳动力而造成就业压力以外,还可能与云南省GDP质量有关。此外,2000年和2002年的样本点对于模型而言是异常值点,其异常的原因值得进一步研究。
[1]程红莉、刘强:区域失业率差异影响因素的实证分析[J].统计与信息论坛,2003(3).
[2]田力:影响失业率的主要因素及降低失业率的对策[J].哈尔滨金融高等专科学校学报,2003(1).
[3]陈幼芳、张天会:云南失业率预测和研究[J].经济问题探索,2006(6).
[4]高惠漩:应用多元统计分析[M].北京大学出版社,2005.
猜你喜欢
数学物理学报(2022年4期)2022-08-22
中学生数理化·高一版(2021年2期)2021-03-19
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
当代工人(2018年9期)2018-07-21
百科探秘·航空航天(2017年6期)2017-07-10
电子制作(2017年24期)2017-02-02
遥测遥控(2015年2期)2015-04-23
探索(2013年4期)2013-07-24
环球时报(2009-11-23)2009-11-23
环球时报(2009-02-05)2009-02-05
