
基于GPU的多帧信号FIR滤波的并行实现
2013-08-10 05:22张道成
舰船电子对抗 2013年4期
张道成
(解放军92785部队,秦皇岛066200)
0 引 言
随着信息技术的不断发展,有限冲激响应(FIR)滤波得到了越来越多的应用,而图形处理单元(GPU)的不断发展使自身具备了强大的并行处理能力,利用其特性可以使信号在进行并行滤波时得到很高的加速比。
1 GPU的发展概况
GPU是指一个单芯片的处理器,近年来,随着GPU可编程性的不断提高,利用GPU来完成图形渲染以外的通用计算得到了越来越多的应用[1-3],众多运算密集型的应用程序执行速度已经可以通过NVIDIA的GPU产品获得令人瞩目的提升。
2 FIR数字滤波器原理
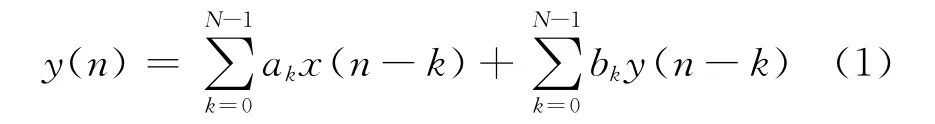
式中:x(n)为输入序列;y(n)为输出序列;ak和bk为滤波器系数;n为滤波器阶数。
对式(1)进行z变换,整理后可得FIR滤波器的传递函数:
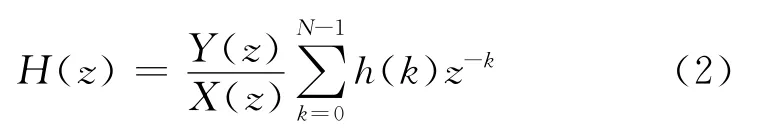
FIR数字滤波器一般具有如下差分方程:
FIR滤波器实现的方法很多,基于傅里叶变换的卷积定理,可利用快速傅里叶变换(FFT)实现输入信号与FIR滤波器单位冲击响应序列的快速卷积运算。每次从输入信号样点序列中截取一段进行离散傅里叶变换(DFT)到频域,然后将各个频谱值乘以滤波器频率响应系数,最后再进行逆DFT变换到时域。
3 在GPU上实现多帧信号的FIR
3.1 在GPU的实现过程
目前,统一计算设备架构(CUDA)已实现了单帧信号的滤波,本文在此基础上实现多帧信号并行FIR滤波。程序实现时利用了CUDA中的CUDA快速傅里叶变换(CUFFT),在GPU上实现多帧信号FIR并行滤波过程如下:
(1)CPU初始化,即在CPU上为多帧信号分配空间,并为其赋值,同时需要为GPU所得计算结果分配空间,用于存储最后的滤波结果。
(2)在GPU上为所要滤波的所有数据参量分配空间,并将CPU已经赋值完毕的参数拷贝到GPU中,用于FIR滤波处理。
(3)在GPU中进行线程划分,然后调用核来进行GPU上的FIR滤波[4]。
3.2 系统测试环境及主要参数
系统测试环境如表1所示。

表1 系统测试环境
3.3 实验结果与分析比较
根据以上所述,随机产生了不同长度、多个批次的多帧信号,并对多帧信号进行了滤波。表2是当帧长度取512、滤波器阶数为11、帧批次取500时所给的数据。为了节省篇幅,取前5个数据的分别采取C、MATLAB2010b、GPU不同方式滤波的计算结果(其中输入的数据为1~512 500的整数),同时给出了CPU、MATLAB2010b和GPU的运算精度并进行了对比。

表2 GPU、CPU和MATLAB的计算精度
从表2中的6组数据显示可以看出,数据分别在GPU、CPU和 MATLAB2010b的计算结果中。GPU与另外2个的计算结果相比较,均存在着一定的误差,但是误差完全符合精度的要求,满足原算法的基本需求。
表3分别给出了不同帧信号的滤波时间结果,其中表格的数据均是采取了连续10次运算后的平均结果,为了更清晰地看出GPU运算时间结果的优越性,将表3中的数据绘成图1和图2。
由表3和图1、2可看出,基于MATLAB进行FIR处理时,随着帧长度和帧数的增加,处理所需的时间增长很快,而基于GPU的FIR处理所用时间增长却不是很明显。在数据长度较短、处理帧数不多的时候,GPU进行并行滤波的运算时间的优势并不很明显,因为数据在内存与显存之间拷贝需要占据一定的时间,时延没有得到很好的隐藏[5]。随着数据长度和并行处理批次的不断增加,其运算时间的优势也越来越明显。但是最终加速比并不是很高,这是因为算法在程序实现中的优化过程没有得到最佳。但是随着输入信号数据长度和帧数达到一定的时候,将不再适合应用GPU运算,因为已超过了其显存大小,这是由GPU硬件资源决定的。
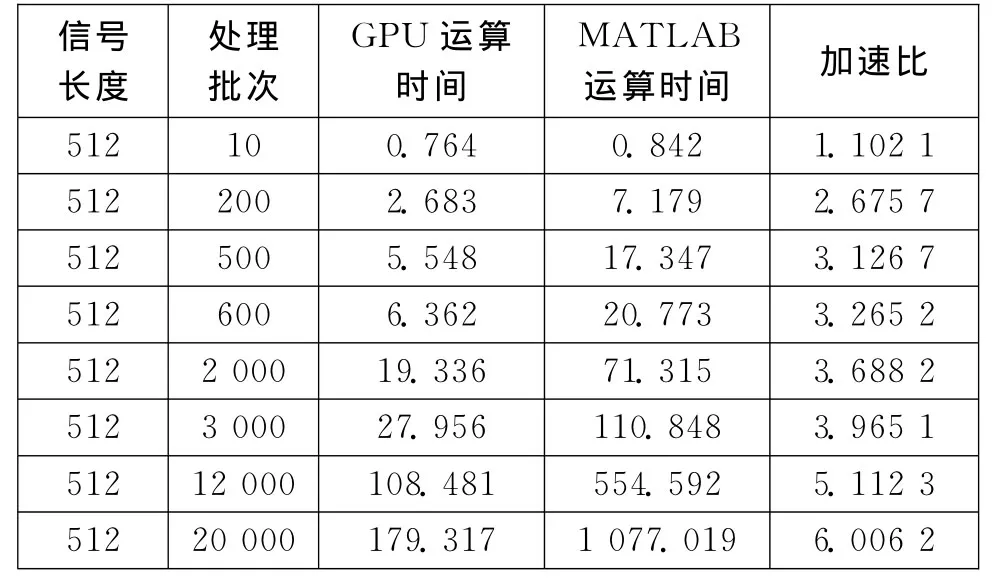
表3 不同帧信号的滤波时间(单位:ms)
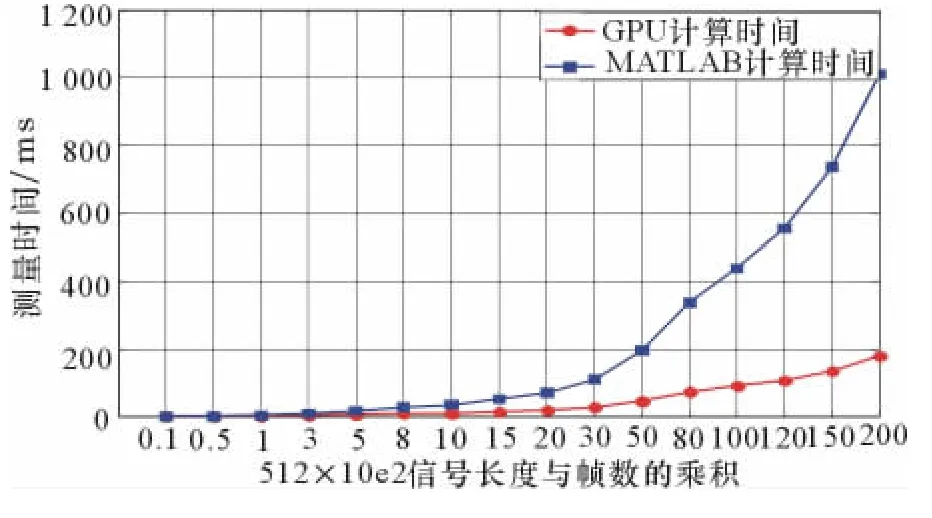
图1 GPU与CPU滤波处理时间图
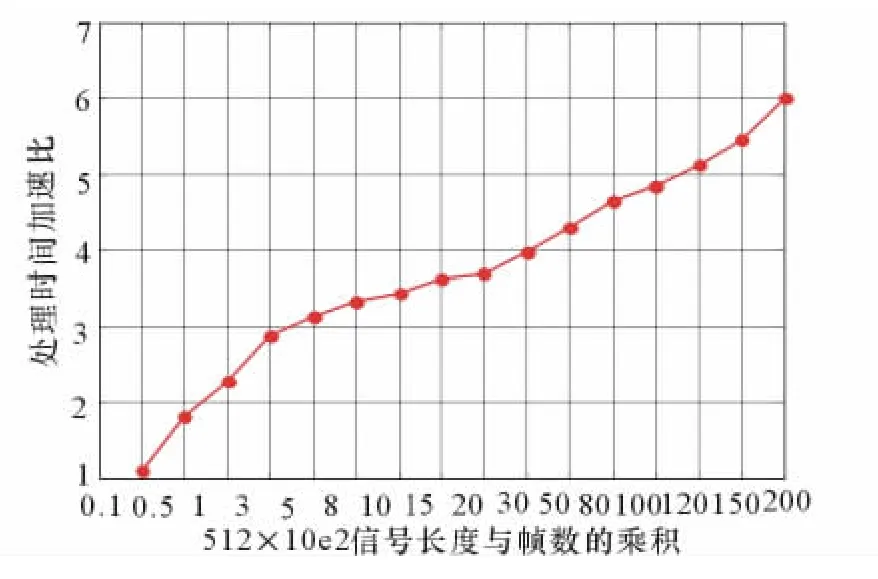
图2 GPU与MATLAB2010b滤波处理时间加速比图
4 结束语
本文基于CUDA实现了多帧信号的并行FIR滤波,试验结果表明,在采用CUDA并行实现后,数据处理速度得到了进一步提升,也证明了GPU良好的并行处理能力和浮点计算能力,进一步验证了采用GPU实现通用计算的可行性。
[1]杨晓玲.基于GPU的LBM方法计算研究[D].上海:上海大学,2008.
[2]王海华.基于GPU的合成孔径雷达回波仿真技术研究[D].成都:电子科技大学,2009.
[3]韩博,周秉锋.GPGPU性能模型及应用实例分析[J].计算机辅助设计与图形学学报,2009(9):23-36.
[4]张舒,褚艳丽,赵开勇,张钰勃.GPU高性能运算之CUDA[M].北京:中国水利水电出版社,2009.
[5]Dmitri Yudanov,Muhammad Shaaban,Roy Melton.Leon Reznik.GPU-based simulation of spiking neural networks with real-time performance & high accuracy[A].IEEE International Joint Conference on Digital Object[C],Barcelona,2010:1-8.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
少儿科技(2021年12期)2021-01-20
科技创新导报(2021年23期)2021-01-15
科技视界(2019年10期)2019-09-02
数字技术与应用(2018年5期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
小天使·三年级语数英综合(2017年6期)2017-06-07
小天使·三年级语数英综合(2017年6期)2017-06-07
舰船科学技术(2016年1期)2016-02-27
中国纤检(2015年4期)2015-03-13
