
支持向量机在换道行为识别中的应用研究
2013-07-25 02:28张亚岐
计算机工程与设计 2013年2期
袁 伟,张亚岐,王 畅
(长安大学汽车学院,陕西西安710064)
0 引言
换道行为是驾驶员常见的操作行为之一,也是影响到车辆运行安全性的重要因素[1]。安全驾驶辅助系统成为改善道路交通环境的重要手段,研究人员已经研制出许多安全辅助驾驶及预警系统,比较典型的有ACC自适应巡航控制系统、SWA换道辅助系统以及LKAS车道保持辅助系统,而行为识别技术就成为影响这些系统可靠工作的决定性因素。目前,驾驶意图识别技术主要包括:隐马尔科夫模型[2],贝叶斯网络,神经网络以及图像检测[3]等等,这些技术需将连续数据离散化,易造成信号失真,且需对短时间内的驾驶行为进行归类,这样会影响到识别的连续性,而贝叶斯网络和神经网络需大量样本,泛化能力较差,图像检测技术受环境因素干扰大,可靠性较低。所以,寻求一种识别精度高、识别耗时短的识别技术成为科研人员关注的焦点。
支持向量机是目前公认的具有较强泛化能力的识别方法。能够在较短时间内准确识别出驾驶行为。本文以真实道路试验数据为基础,建立支持向量机的换道行为识别模型。从能够表征换道行为的众多指标中筛选出车道线距离和方向盘转角作为最终换道指标。对采集到的样本数据进行Kalman滤波[4]、归一化处理以及主成分分析,利用遗传算法[5]优化SVM的核参数,选择最佳的参数组合,最后,对优化后的模型进行训练与测试,测试结果能够满足现有车载换道预警系统的实时性和可靠性要求。
1 换道识别模型建立
1.1 线性支持向量机理论
支持向量机 (support vector machine)是Cortes和Vap-nik于1995年首先提出,主要用于解决平面上的二分类问题,如图1 所示[6]。
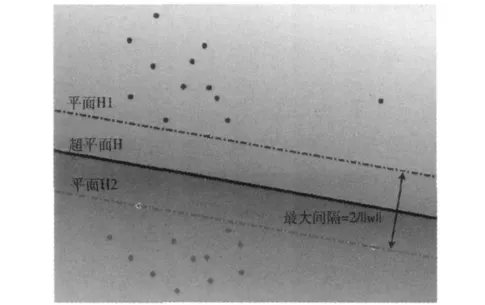
图1 线性可分情况下最优分类面
由图1可知,平面H、H1和H2的都能实现二分类的功能,即分类面H并不是唯一的,但最佳的分类面是唯一的,即最大间隔超平面,该平面使得使H1和H2之间的间隔最大。图中H为一个超平面,H1、H2与H互相平行。最优分界面的求解问题通常表述为二次优化的问题,对于给定的样本 {xi,yi}(i=1,2,3………l),求使下列二次泛函取极小值的w

其约束条件为

对于此类二次规划问题,通常转换成与其对应的拉格朗日对偶问题来求解,该问题的拉格朗日函数为[7-9]
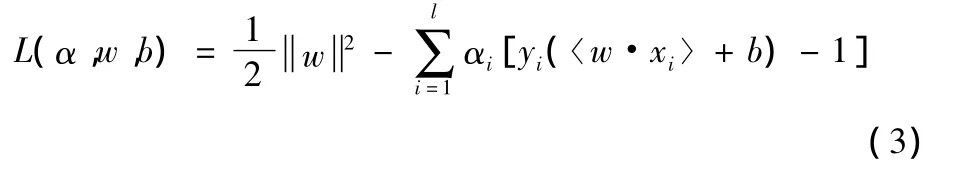
式中αi0,其为拉格朗日乘子。根据库恩-塔克条件可得
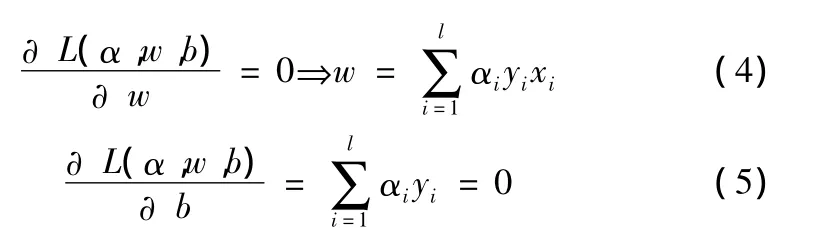
将以上两式代入式 (3)可得原规划问题的对偶优化问题,即
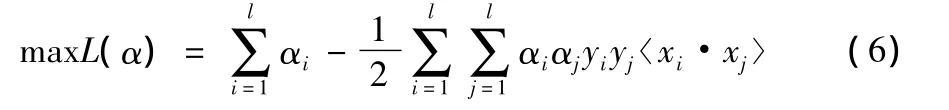
相应的约束条件变为
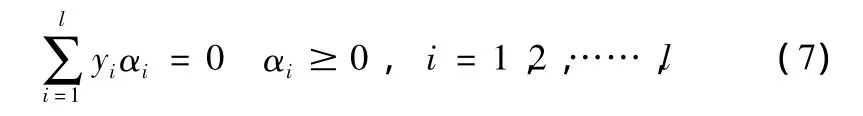
通过求解以上对偶优化问题,获取最优超平面的特征参数,实现最佳二分类功能。
1.2 换道行为表征参数
与换道行为识别关联性较强的参数包括:车辆与车道线距离、方向盘转角、横向加速度、纵向加速度、航向等。参考其他研究人员的结论,根据参数特点,本文中所使用的特征集包含两个参数:
(1)车辆与车道线距离d。车辆与车道线距离是表征车道变换行为最直接的参数,该参数须在车辆发生横向位移后才能体现出换道特征。
(2)方向盘转角θ。方向盘转角也在一定程度上能够表征车道变换行为,大部分换道过程中方向盘转角均会呈现一定程度的变化规律,但其他非换道情况下方向盘转角也会出现一定程度的波动,且在仅靠方向盘转角很难区分车辆曲线行驶和车道变换,从而使得无法单独使用方向盘转角来对换道行为进行识别。
1.3 表征参数滤波
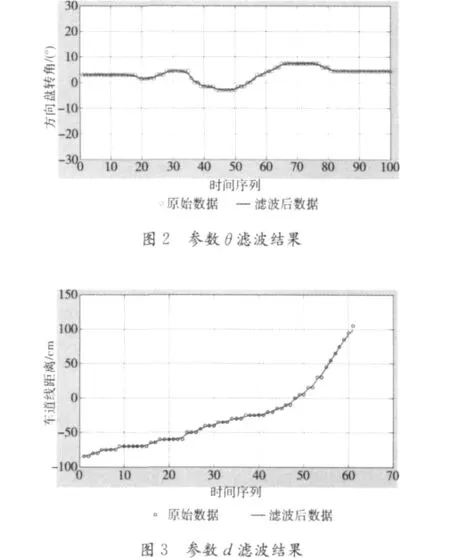
受限于传感器的采集精度,特征参数d和θ均存在一定程度的阶跃性,弱化了数据之间的关联性。支持向量机识别模型最重要的思想是从换道数据内部挖掘数据的相关特性,为削弱原始数据的阶跃性,本文采用卡尔曼滤波器对d和θ进行滤波处理。滤波过程采用标准离散型卡尔曼滤波器,基于MATLAB卡尔曼滤波工具箱完成,滤波结果如图2图3所示。
1.4 训练集和测试集
选择实际道路正常驾驶过程中的部分换道数据,此外选择部分车道保持数据,共挑选出945组数据,其中车道变换次数为503次,占总次数的53.23%;车道保持次数为442次,占总次数的46.77%。所挑选的数据中,一部分用于SVM模型训练,训练样本集为645组;另一部分数据用于对训练后模型进行测试,测试集样本为300组,用于训练模型和检验模型的数据比例约为2:1,具体的数据分布如图4图5所示。

1.5 SVM模型训练
时间窗口的长短对于换道行为识别的有效率存在较大影响,一方面,时间窗口太短,则该时间窗口内所包含的换道信息不足,很难对该时窗所对应的驾驶行为进行准确分类,从而使得识别率偏低。另一方面,过长的时间窗口会使得特征集所包含的换道特征被淹没或者特征不明显,也容易造成识别率偏低。
最优时间窗口由两点体现,第一为较高的识别率,第二为实时性要好,只有这两点均得到满足的情况下,所选时间窗口才有意义。最优时间窗口随应用环境的不同而存在较大差异,因此无法根据经验来确定,所以,只能对不同时间窗口下的换道行为分别进行分析,根据测试结果来挑选最佳的时间窗口。以0.8秒为最短时间窗口,以5.0秒为最长时间窗口,分别对 0.8、0.9、1.0、1.1、1.2、1.3、1.4、1.5、1.6、1.7、1.8、1.9、2.0、2.5、3.0、3.5、4.0、4.5和5.0秒间窗口下的换道行为进行识别。
在MATLAB环境中,利用libsvm支持向量机工具建立SVM训练模型。将645组训练样本导入到SVC环境中,使用系统默认参数进行训练,训练过程结束之后输出测试集的分类准确率。该参数的大小体现了训练模型对训练样本的学习接受程度,分类准确率越高则表示训练模型能将更多的数据准确划分为车道保持或车道变换,同时分类准确率对于后续测试识别过程也具有重要影响。利用libsvm工具箱,对不同的时窗长度分别进行训练,得到相对应的分类准确率,如表1所示。
表1表明,不同时间窗口长度的SVM模型分类准确率存在较大差异,时间窗口低于1.1秒时分类准确率均低于80%,1.2秒时窗的分类准确率开始上升,达到了92.8%,随着时窗的增加,分类准确率进一步上升,在2.0秒的时候达到了最大值98.7%。
1.6 SVM模型识别结果
将300组待测试数据导入到SVC环境中进行测试,使用不同时间窗口值和该时间窗口值所对应的识别模型进行测试识别。以5%的错误接受率 (误报率)为基准,分析不同时窗长度对应的识别率,结果如表2所示。

表1 训练集分类准确率

表2 测试集识别率 (5%FP)
表2表明,测试集识别率在时窗小于1.2秒过程中呈 现增加趋势,其中从1.1秒到1.2秒区间内测试集识别率增加了24.1%,相应的训练集分类准确率增加了19.3%,此区间内训练集和测试集均表现出相同的增加趋势。从1.2秒到2.0秒区间内,测试集识别率从90.6%增加到了97.8%,相应的,训练集侧类准确率也呈现上升趋势。时窗大于2.5秒的数据表明,测试集识别率出现下降趋势,从92.2%下降到83.1%。
换道行为识别对于实时性有较高要求,而识别实时性由时窗长度直接决定。对换道预警系统需求而言,实时性越好则时窗长度越短,实时性很好时则留给驾驶员更多的反应时间,因此换道识别所使用的时窗长度需要控制在一定范围内,此范围通常设定为1.2秒以内。表2中,1.2秒以内时窗的识别率最高为90.6%,处于较低的范围,无法满足换道预警系统的需求,因此需要进一步对SVM模型进行优化,提高时窗长度小于或等于1.2秒情况下的识别率。
2 换道识别模型优化
2.1 数据归一化[10]
换道过程中,车辆与车道线的距离一般在-300~ +120cm之间变化,而方向盘转角值的变换范围通常小于10°,从而使得两类参数之间的数据差异性较大,容易引起部分数据被淹没。此外,数据变化范围大会使计算过程较为复杂,训练SVM的时间较长,对SVM识别精度造成负面影响。为降低数据计算量,通常采用数据归一化方法降低数据复杂程度。进行数据归一化的公式如下
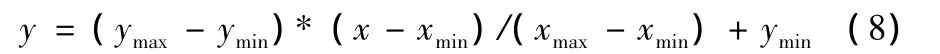
式中:ymax、ymin——归一化之后y的最大值和最小值,可以根据需要自行设定,通常取为+1、-1,xmax和xmin分别为采集原始数据中最大值和最小值。利用式8对方向盘转角θ和车辆与车道线距离d进行归一化,结果如下:
原始数据: (2.975,1.487,0,-1.487,-2.975,4.463,7.438)T
归一化结果:(0.1428,-0.1429,-0.4285,-0.7142,-1,0.4285,1)T
原始数据:(-200,-195,-190,-185,-180,-175,-160)T
归一化结果: (-1,-0.6667,-0.3333,0,0.3333,0.6667,1)T
未进行数据归一化处理和进行归一化处理之后的训练集分类准确率如表3所示。

表3 训练集分类准确率 (1.2秒时窗)
2.2 主成分分析 (数据降维)[11-12]
考虑到SVM对二分类问题具有良好的处理能力,通常将多分类问题转化为二分类问题处理,即通过采用数据降维方式将高维数据降低到低维空间。主成分分析 (PCA)是应用范围最广的一种数据降维方法,该方法通过提取包含特征信息的主元,舍弃其他非主要元,在保证所选择主元能够表征原始数据特征信息的情况下降低数据维数,从而简化计算过程,节约SVM运行过程中对计算机资源的消耗,提高训练速度和测试速度。实际应用过程中,通常根据累计方差来对主成分的个数进行选择,在保证精度的前提下主元数越少对SVM模型的训练和测试越有利。
利用SPSS软件,对实际道路所采集到的车道保持和车道变换数据进行主成分分析,总的样本数量为945组。本文中采用2个参数对换道行为进行识别,以1.2秒时窗为例,数据中共包含24个参数,因此主成分分析方法中相应的存在24个变量。求解结果见表4。
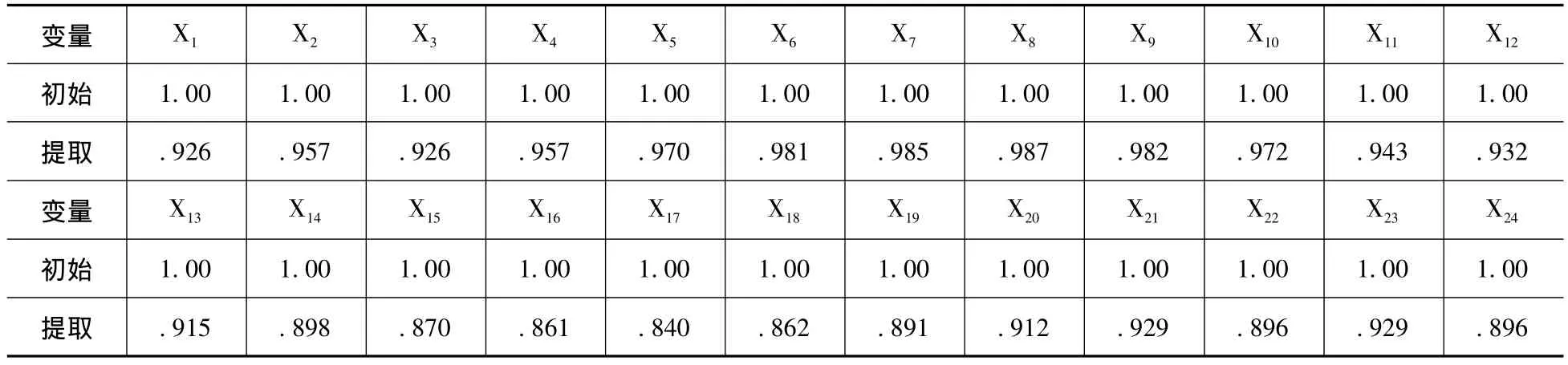
表4 公因子方差
表4中的公因子方差表示变量对原始参数的解释程度,公因子为1表示变量能完全表征原始参数,共因子为0则表示变量对原始参数无任何表征意义。表4中,最大公因子方差为0.987,最小公因子方差为0.840,共因子的平均值为0.926,标准偏差为0.043,这表明,共因子中包含了绝大部分的变量信息,从而保证了新变量的有效性。
绘制计算得到的累计贡献率图,结果如图6所示。
图6表明,从单个成分比例而言,第一主成分和第二主成分所占比例较大,这两个成分所占比例之和达到了92.57%。第三主成分所占比例为3.71%,除此之外的21个成分比例之和为3.72%,由此可知,第一主成分和第二主成分的贡献率占到了主要部分,因此本文中选取第一主成分和第二主成分。根据第一、第二主成分的系数矩阵即可得到第一主成分F1和第二主成分F2,结果如下


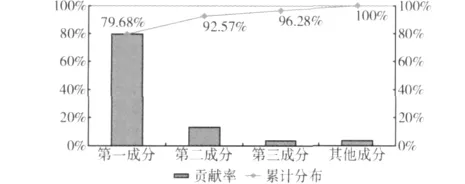
图6 累计贡献率分布
通过将数据进行降维处理后,时窗选择1.2秒,未进行数据降维和利用主成分分析法进行降维之后的训练集分类准确率如表5所示。

表5 训练集分类准确率 (1.2秒时窗)
2.3 优化模型识别结果
通过采用数据归一化、主成分析数据降维方法,同时采用遗传算法对SVM模型进行优化,限于篇幅,本文不详细介绍利用遗传算法对SVM模型的优化过程。利用优化模型对测试样本重新进行识别,在5%的错误接受率情况下,不同时窗长度的换道行为识别结果见表6。

表6 优化模型识别结果 (5%FP)
对比表6和表2中的识别率,结果表明,对于不同长度的时窗,经过优化后的SVM模型识别有效率均有大幅度的提高,对于小于或等于1.2秒时窗长度,识别率分别增加了36.8%、37.1%、35.8%、30.4%、6.6%,同时所有时窗长度的识别率均超出了90%。这表明,通过使用数据归一化、数据降维处理和利用遗传算法对SVM模型进行优化后,换道行为识别模型的有效率得到了大幅提高,从而在保证实时性的基础上提高了换道预警系统的有效率。1.2秒时窗下的识别结果的图形表示如图7所示。
图7中,在曲线 (超平面)内部的‘+’表示模型将车道变换错误识别成车道保持,同样,曲线外侧的‘*’表示将车道保持错误的判定为车道变换。从图7中可以看出,图中的超平面能够将大部分的驾驶行为准确的区分开来。
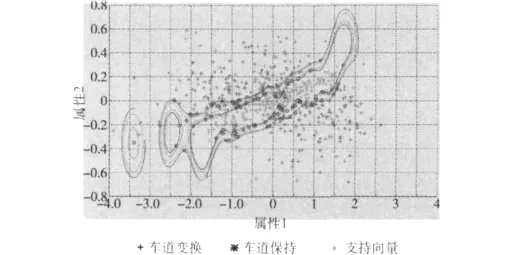
图7 经优化后的1.2秒时窗识别结果
3 结束语
换道行为的识别是影响到换道预警系统有效性的重要因素之一,本文通过采用实际试验所采集得到的数据,建立了基于SVM的换道行为识别模型。通过采取数据归一化、数据降维处理等方法对SVM模型进行优化,大幅度提高了识别时窗小于或等于1.2秒情况下的换道样本识别成功率,从而提高了换道预警系统的实时性,当换道过程存在危险时能留给驾驶员更充裕的时间来进行避险操作,避免换道事故的发生。
[1]Dario D,Salvucci Hiren M,Mandalia,et al.Lane-change detection using a computational driver model[J].Journal of the Human Factors and Ergonomics Society,2007,49(3):532-542.
[2]WANG Chang.Research on driving intention identification based on hidden markov model[D].Changchun:Jilin University,2011(in Chinese).[王畅.基于隐马尔科夫模型的驾驶员意图辨识方法研究 [D].长春:吉林大学硕士学位论文,2011.]
[3]WU Bingfei,CHEN Weihsin,CHANG Chaiwei,et al.A new vehicle detection with distance estimation for lane change warning systems[C]//Proceedings of the IEEE Intelligent Vehicles Symposium Istanbul,Turkey,2007:698-703.
[4]PENG Dingcong.Basic principle and application of kalman filter[J].Software Herald,2009,8(11):32-35(in Chinese).[彭丁聪.卡尔曼滤波的基本原理及应用 [J].软件导报,2009.8(11):32-35.]
[5]ZHAO Luhua,PENG Tao.A kind of effective selection method of SVM optimized parameter[J].Manufacturing Automation,2010,32(9):146-149(in Chinese).[赵璐华,彭涛.一种有效的SVM参数优化选择方法[J].制造业自动化,2010,32(9):146-149.]
[6]CHEN Qimai,CHEN Sengping.Sample selection method of the support vector machine based on kernel function [J].Computer Engineering and Design,2010,31(10):2266-2269(in Chinese).[陈启买,陈森平.基于核函数的支持向量机样本选取算法 [J].计 算 机 工 程 与 设 计,2010,31(10):2266-2269.]
[7]YANG Xun,ZHANG Yue.The recognition method of arrhythmia based on support vector machine[J].Computer Engineering and Design,2007,28(18):4442-4445(in Chinese).[杨煦,张跃.基于支持向量机的心律失常识别方法[J].计算机工程与设计,2007,28(18):4442-4445.]
[8]LIU Hui,YANG Junan,XV Xuezhong.Identification method of target fly low voice based on series model of HMM and SVM [J].Data Acquistion and Processsing,2011,25(6):751-755(in Chinese).[刘辉,杨俊安,许学忠.基于HMM和SVM串联模型的低空飞行目标声识别方法 [J].数据采集与处理,2011,25(6):751-755.]
[9]WANG Xvhui,SHU Ping,CAO Li.Performance study on support vector machine based on the ROC curves [J].Computer Science,2010,37(8):240-242(in Chinese).[王旭辉,舒平,曹立.基于ROC曲线寻优的支持向量机性能研究[J].计算机科学,2010,37(8):240-242.
[10]DU Jianhui,SHI Yonghua,WANG Guorong,et al.Underwater weld deviation recognition based on the PCA Nu-SVR [J].British Welding Journal,2011,32(3):21-24(in Chinese).[杜健辉,石永华,王国荣,等.基于PCA_Nu-SVR的水下焊缝偏差识别方法 [J].焊接学报,2011,32(3):21-24.]
[11]WANG Huiting.Discriminant analysis method study based on the combination of principal component analysis and support vector machine[D].Lanzhou:Lanzhou University,2009(in Chinese).[王惠婷.基于主成分分析和支持向量机的组合判别分析方法研究[D].兰州:兰州大学,2009.]
[12]SUN Shenshen,REN Huizhi,KANG Yan.Pulmonary nodules detection based on genetic algorithm and support vector machine[J].Journal of System Simulation,2011,23(3):497-501(in Chinese).[孙申申,任会之,康雁.基于遗传算法和支持向量机的肺结节检测 [J].系统仿真学报,2011,23(3):497-501.]
猜你喜欢
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2020年11期)2021-01-14
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年5期)2018-08-21
中国交通信息化(2018年3期)2018-06-13
