
基于属性约简的物联网不完全数据填充算法
2013-07-25 02:27陈志奎杨英达张清辰
计算机工程与设计 2013年2期
陈志奎,杨英达,张清辰,刘 旸
(1.大连理工大学软件学院,辽宁大连116621;2.西南大学计算机与信息科学学院,重庆400715)
0 引言
物联网数据的不完全性问题日益突出。所谓数据不完全性是指终端工作异常而引起的采集数据全部或部分属性值缺失。数据不完全性给物联网的数据融合、数据挖掘等带来极大困难,严重阻碍物联网数据的应用。因此对物联网不完全数据进行填充是一个重要课题。
常用的不完全数据填充算法主要有基于决策树的填充方法、基于马氏距离的填充方法及基于EM和贝叶斯网络的数据填充方法[1]等。传统的数据填充算法对不完全数据的所有属性采用相同的填充方法,没有考虑到与用户的交互性。在对物联网的数据进行融合与挖掘等应用中,未必需要数据的全部属性。因此传统的数据填充算法在对物联网不完全数据进行填充时效率低下,不适合填充物联网的不完全数据。
针对以上问题,本文提出一种基于属性约简的不完全数据填充方法。利用属性约简区分数据的重要属性与非重要属性,分别采用不同的填充技术对两类属性数据进行填充,其中重要属性个数根据用户需要设定。
常用的属性约简方法包括基于启发式算法的属性约简算法[2-3]、基于决策表的属性约简算法[4-6]以及基于相容矩阵[7-8]等属性约简算法。其中,基于幂图的属性约简搜索算法[9]通过幂图的方式求约简,把属性约简的计算问题转化为图搜索式问题,以直观形象的方式展现了属性约简的过程,为属性约简问题的求解提供了一条新的途径。但是基于幂图的方法只能求完全信息系统的属性约简,因此本文给出了不完全信息系统划分的定义,经过转换之后,可以把不完全信息系统看作是完全信息系统,进而用基于幂图的思想进行属性约简。
基于相似度的方法用来定义相容关系,然后进行分类。但该方法将导致对象相似度值存在大量的零值,因此本文在其求概率乘积的基础加以改进,定义相似度为概率之和。这样做的优点是既能保证相似度乘积大的求和相似度也大,同时去掉了很多相似度值是零的非正常值的干扰。
1 相关理论和技术
1.1 粗糙集与粒计算
定义1 IS=(U,A,V,f)是一个信息系统,其中U是论域,也就是研究对象的集合,A是属性集合同时A≠Φ,属性集A包含两种属性,分别是条件属性和决策属性,条件属性集合用C表示,决策属性集合用D表示,集合A、C、D之间满足如下关系:A=C∪D且C∩D=Φ。V是U中的对象在属性A下的取值集合,f是信息函数,用来把论域中的对象和属性与取值做映射,即当x∈U,a∈C时,用f(x,a)=* 表示f(x,a)的函数值是未知的。这种带有未知函数值的信息系统叫做不完全信息系统,用IIS表示。
定义2 对于一个不完信息系统IIS=(U,A,V,f), B C,DIV(B)定义了一个二元不可区分关系:a)=*)and(f(x,a)=*)≠(f(y,a)=Vya)},×代表笛卡尔乘积。在DIV(B)中,对象在属性a下的取值中,任何未知的值与已知的值不同,任意两个未知的值也不同。那么U/DIV(B)构成了论域U的一个划分,也称为U的一个知识粒。
定义3 设 IIS=(U,A,V,f)是不完全信息系统,U/DIV(C)={U1,U2,…,Un},C是条件属性集,属性集C的知识粒度定义是
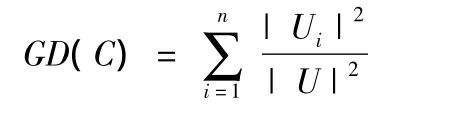
1.2 幂图
定义4 设Power(C)是条件属性集合C幂集,给定有向图G,Power(C)中的元素是图G的顶点,图G中的边满足下面条件: X,Y,Z∈Power(C),如果|X|-1=|Y|=|Z|+1且(X∩Z) Y (X∪Z),那么存在X到Y,Y到Z的有向边,称此有向图G是C的幂图。
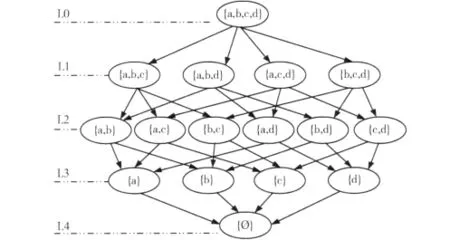
图1 幂图
1.3 基于相似度的数据填充方法
定义5 给定IIS=(U,A,V,f),x∈ U,且y∈ U;A=C∪D,a∈C;C是条件属性,D是决策属性。Va是属性a的值域,那么实体x,y在属性a下取值相同的概率定义如下:
Pa(x,y):
(1)1/|Va|,f(x,a)和 f(y,a)不同时为 *;
(2)1/|Va|2,f(x,a)和 f(y,a)同时为 *;
(3)1,f(x,a)=f(y,a);
(4)0,f(x,a)和f(y,a)都不为* 且不等;
由上面定义可得对象相似度计算公式如下
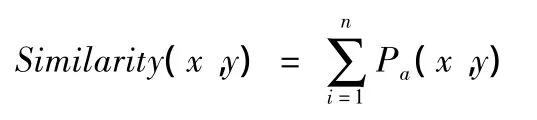
n代表对象的属性个数,即对象相似度等于每个属性相同的概率之和。
2 基于属性约简的物联网不完全数据填充算法
结合物联网数据特点,本文提出一种基于属性约简的物联网不完全数据填充算法,算法首先利用改进的基于幂图的重要属性搜索算法抽取数据的重要属性,然后利用改进的基于相似度的方法填充重要属性中的缺失值,最后,算法利用基于概率的方法填充非重要属性的缺失值。算法整体框架如图2所示。
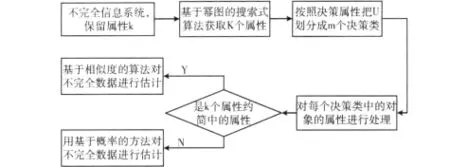
图2 算法总体框架
2.1 改进的基于幂图的重要属性搜索算法
输入:给定不完全信息系统和需要的属性个数K
输出:K个属性的属性集RED(K)
步骤:
(1)建立一个的搜索图 G,把 C放在扩展节点表Search中,计算起始节点的知识粒度 g=GD(C),令minGD=g。
(2)建立一个Searched的已扩展的节点表,初始值为空。
(3)令P=C。
(4)Loop:如果Search为空,则退出循环。
(5)选择Search表的第一个节点,把它从该表移除并放到Searched表中,称此节点为n。
(6)按照幂图扩展节点n,同时生成后继结点的临时集合TEMP,把这些成员作为后继结点添加入幂图G中。
(7)令P∈TEMP,如果|P|<K,break。
(8)对没有在G中出现过的TEMP成员,设置一个指向n的指针,计算TEMP中属性集合的粒度,如果存在P∈TEMP,GD(P)=minGD(TEMP), 把 大 于 minGD(TEMP)的加入到Searched表,其他的加入Search表。
(9)按某个启发式或者任意方式重排Search表。
(10)goto Loop。
(11)比较Search表中获取的包含K个属性的属性集粒度的大小,选择小粒度的属性集使其等于RED(K)。算法流程见图3。
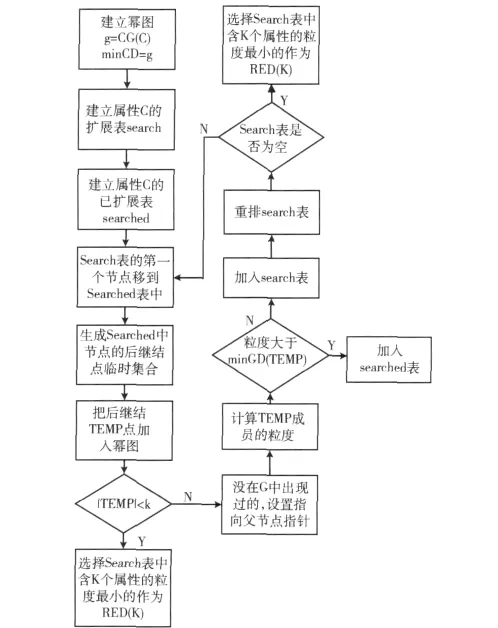
图3 基于幂图的属性约简算法流程
2.2 基于相似度的重要属性填充
(1)对U用决策属性D进行划分,得到U/D={X1,X2,…,Xn}。
(2)把U/D放到Open表中。
(3)loop:如果Open表为空,则退出循环。
(4)选择Open表的第一个节点,即Xi,然后对集合的实体进行处理。
(5)如果Xi中的实体x的属性a属于RED(K),则采用基于相似度的方法对不完全属性值进行填充。
(6)如果Xi中的实体x的属性a不属于RED(K),则采用在Xi中实体的a属性值中出现概率最大的进行不完全属性值的填充。
(7)处理完Xi中的所有实体后,把处理后的Xi从Open表移除,移到Closed表中。
(8)goto Loop。
算法流程图见图4。
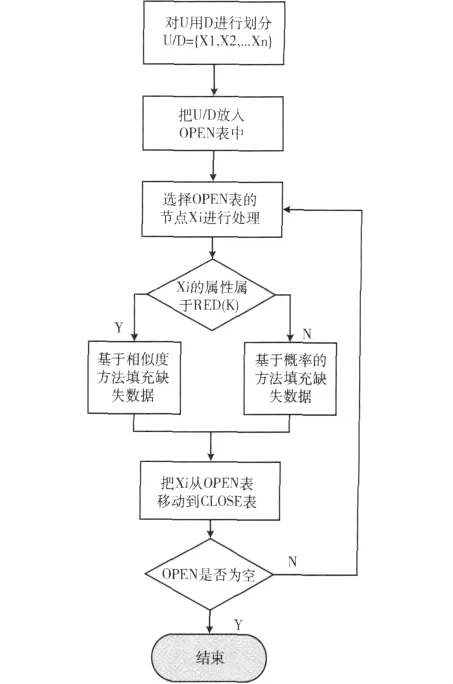
图4 数据填充流程
3 实验
采用智能家庭中的数据样本[10],应用本文提出的算法进行实例分析如下。
设IIS=(U,A,V,f),A=C∪ D,U={Rm1,Rm2,…, Rm10}, C= {temp, humi, lumi, power,location},C中的条件属性可简写为
C={t,h,l,p,L};D={sensitivity}。详细数据见表1。
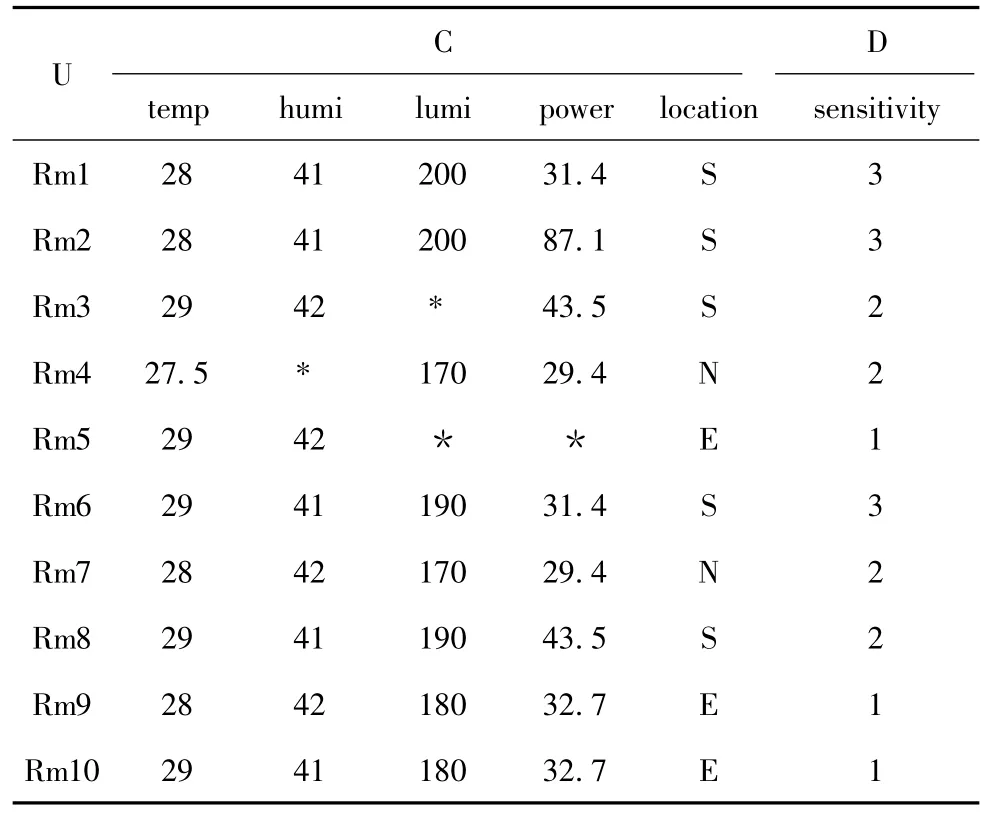
表1 数字家庭数据
设要获取的重要属性个数是3个,那么算法的执行首先采用基于幂图的搜索式算法,图3展示的是搜索的过程,其采用的是广度优先搜索。大括号中包含的是属性,小括号中的值是该节点属性集合的粒度值。红色框标注的是每一层不在进行搜索的节点,通过2.1算法的第八步去掉了幂图中重复的边,即虚线连接的上层与下层的边在处理时不需要重复计算。因此搜索完全部包含3个元素的节点即找到了所有符合要求的保留三个属性同时粒度最小的3个属性。在图5中可以看出,{t,h,p}、{t,l,p}、{h,l,p}三个节点都是符合要求的属性组合,可以任取其中一个或者基于某种启发式算法选择一个做为重要属性,在本例中选择第一个做为重要属性,即RED(3)={t,h,p}。然后基于决策属性对U进行划分即:U/D={{Rm1,Rm2,Rm6}, {Rm3,Rm4,Rm7,Rm8}, {Rm5,Rm9,Rm10}}。然后对每一个划分中的元素进行处理。因为集合{Rm1,Rm2,Rm6}中不包含未知属性值,所以不用做任何处理。继续处理集合 {Rm3,Rm4,Rm7,Rm8},此时Rm3和Rm4含有未知属性。首先处理重要属性的缺失值,即属性humi的值,此时由对象相似度公式计算相似度
Similarity(Rm3,Rm4)=0+1/2+0=1/2
Similarity(Rm7,Rm4)=0+1/2+1=3/2
Similarity(Rm8,Rm4)=0+1/2+0=1/2
因为Similarity(Rm7,Rm4)的相似度最高,所以取Rm7的humi的值作为Rm4的填充值即缺失值是42。然后处理Rm3的属性lumi的缺失值,此时计算 {Rm3,Rm4,Rm7,Rm8}中lumi的属性值出现概率,选择概率值最大的作为Rm3的缺失值。即Pmax=Plumi=170=2/3,所以对Rm3的lumi值填充为170。
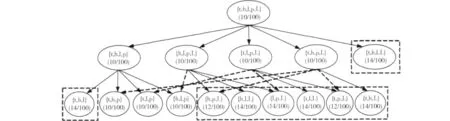
图5 重要属性搜索
处理完后处理集合 {Rm5,Rm9,Rm10}。首先处理重要属性power的缺失值。由相似度计算公式计算Rm5和Rm9、Rm10的相似度
Similarity(Rm5,Rm9)=0+1+1=2
Similarity(Rm5,Rm10)=1+0+1=2
因为Rm5和Rm9、Rm10的相似度值相同,所以任取其中一个的power值来填充 Rm5的Power值,此处选择Rm9,即缺失的power值填充值是32.7。
再对Rm5的属性lumi的缺失值进行填充,此时出现的值只有一个,因此该值出现的概率Pmax=Plumi=180=1,所以该缺失值填180。
实验分析表明,本算法可以快速的获取重要属性,通过实例中对缺失值的填充,体现了重要属性和非重要属性的区别,基于相似度的模式比单纯的基于概率的方式对缺失值的填充更加合理,这是因为基于相似度的方法综合考虑了其他属性对缺失属性的影响。同时,基于决策属性划分的方法把基于概率的填充方法的概率分布重新进行了划分,使其更有意义 (同一决策类中的属性相似的概率最大)。
4 结束语
大量终端设备在无人工监控状态下工作,经常发生损坏,导致其采集的数据中含有大量不完全数据。数据的不完全性给物联网的数据融合、数据挖掘等带来极大困难,严重阻碍物联网数据的应用。为此,本文提出一种基于属性约简的不完全数据填充方法,对缺失数据进行了填充。方法的核心由两部分组成:第一是选择重要属性,第二是填充缺失值。在重要属性选择时采用了基于幂图的搜索式算法,把重要属性选择问题转化为图搜索式问题,以直观形象的方式展现了选择K个重要属性的过程。在数据填充时,首先利用决策属性对U进行划分,这样能够去掉不相关数据的干扰。基于相似度的重要属性填充方法同时考虑了其他属性对该属性的影响,因此填充的值更加科学合理,对非重要属性缺失值的处理采用的是简单的概率方式填充,这种方法相对于其他方法将节省计算开销。
[1]LI Hong,EMMMANUEL Amani,LIPing,et al.Imputation algorithm of missing values bas-ed on EM and Bayesian network [J].Computer Engineering and Application,2012,46(5):123-125(in Chinese).[李宏,阿玛尼,李平,等.基于EM和贝叶斯网络的丢失数据填充算法[J].计算机工程与应用,2010,46(5):123-125.]
[2]HU Lihua,DING Shifei,DING Hao.Research on heuristic attributes reduction algorithm of rough sets[J].Computer Engineering and Design,2011,32(4):1438-1440(in Chinese).[胡立花,丁世飞,丁浩.基于启发式的粗糙集属性约简算法 [J].计算机工程与设计,2011,32(4):1438-1440.]
[3]HUANG Zhiguo,WANG Duan.Study on data reduction algorithm based on rough set[J].Computer Engneering and Design,2009,30(18),4284-4287(in Chinese).[黄治国,王端.基于粗糙集的数据约简方法研究[J].计算机工程与设计,2009,30(18):4284-4287.]
[4]CHEN fengjuan.Methods for calculating core attributes of inconsistence decision table [J].Computer Engineering and Design,2012,33(3):1187-1191(in Chinese).[陈凤娟.不相容决策表求核方法 [J].计算机工程与设计,2012,33(3):1187-1191.]
[5]GE Hao,YANG Chuanjian,LI Longshu.Ef-ficient algorithm for computing core attri-butes[J].Computer Engineering and Application,2012,46(26):138-141(in Chinese).[葛浩,杨传健,李龙澍.一种高效的核属性求解方法[J].计算机工程与应用,2010,46(26):138-141.]
[6]WANG Ling,WU Jie,HUANG Dan.Attribute reduction algorithm for decision table based on relative discernibility matrix [J].Computer Engineering and Design,2012,31(11):2536-2538(in Chinese).[汪凌,吴杰,黄丹.基于相对可辨识矩阵的决策表属性约简算法 [J].计算机工程与设计,2010,31(11):2536-2538.]
[7]RUAN Shen,XU Zhangyan,WANG Wei,et al.Improved tolerance matrix attribute reduction algorithm [J].Computer Engineering and Application,2011,47(32):49-51(in Chinese).[阮慎,徐章艳,王炜,等.改进的相容矩阵属性约简算法[J].计算机工程与应用,2011,47(32):49-51.]
[8]HAN Zhidong,WANG Zhiliang,GAO Jing,et al.Improved attribute reduction algorithm based on tolerance matrix[J].Computer Engineering,2010,36(20):25-27(in Chinese).[韩志东,王志良,高静,等.基于相容矩阵的改进属性约简算法[J].计算机工程,2010,36(20):25-27.]
[9]CHEN Yuming,MIAO Duoqian.Searching algorithm for attributes reduction based on power gragh[J].Chinese Journal of Computers,2009,32(8):1486-1492(in Chinese).[陈玉明,苗夺谦.基于幂图的属性约简搜索式算法 [J].计算机学报,2009,32(8):1486-1492.]
[10]LIU Yang,CHEN Zhikui,WANG Haozhe,et al.An architecture of data pro-cessing using deluge computing in internet of things[C]//Dalian,China:IEEE Internatio-nal Conferences on Internet of Things,and Cyber,Physical and Social Computing.2011:692-697.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
哈尔滨轴承(2022年1期)2022-05-23
中学生数理化·中考版(2021年6期)2021-11-22
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
电子制作(2018年11期)2018-08-04
自动化学报(2018年2期)2018-04-12
消费导刊(2017年20期)2018-01-03
智能系统学报(2017年3期)2017-08-01
