
PowerGrep在语料标注中的应用
2013-07-24 18:45:14王朝晖
赤峰学院学报·自然科学版 2013年22期
余 军,王朝晖
(厦门理工学院 外国语学院,福建 厦门 361024)
PowerGrep在语料标注中的应用
余 军,王朝晖
(厦门理工学院 外国语学院,福建 厦门 361024)
语料库标注是语料库构建的一个重要环节,除词性标注外的各类标注一般都较难实现批量操作或自动化.本文介绍了文本处理软件PowerGrep的查找、替换等主要功能及其功能赖以实现的正则表达式,并以自建的电子商务翻译语料库的标注处理为例,说明如何利用PowerGrep在替换标注赋码、添加标注以及校对标注等方面实现批量操作.
PowerGrep;正则表达式;语料标注;语料加工
1 引言
除生语料库之外,语料库的构建一般都需要对语料进行标注,包括常见的文本头标注和词性标注,以及错误标注、句法标注、语义标注、语用标注等其他各类标注,还包括语料库构建者根据研究需要制定的标注类型,如笔者所构建的多模态双语学习者语料库中的技巧标注和评价标注[1].对语料库进行标注可以为语料库带来增值(added value)[2].语料标注有人工、半自动化及自动化等三种方式,视乎标注类型而定.词性标注一般都是使用软件自动生成,而其他类型的标注一般都较难实现自动化[3].标注的流程包括文本预处理,自动标注或者人工标注,以及标注校对,在这三个步骤中,运用功能强大的文本处理软件PowerGrep,可极大地提高语料标注的效率,但目前此类探讨较少.本文以笔者自建的电子商务翻译语料库为例,介绍如何运用PowerGrep对语料进行标注加工和处理,以期广大语料库语言学研究者了解这一语料加工利器的使用,加深对语言库语言学研究工具的发掘利用.
2 PowerGrep与正则表达式
PowerGREP是一款基于正则表达式的文本检索和处理软件,可在不同的文件夹内,对不同的文件进行批量的文本搜索、替换,支持txt、htm l、xls、xm l、doc、pdf等多种文件格式,可以完成复杂的文本和二进制替换操作,是应用正则表达式在文本文件中搜索替换的强大工具.正则表达式(Regular Expression)是用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串,起源于科学家对人类神经系统工作原理的早期研究.计算机发展以后,美国数学家Stephen Kleene把它引进到计算机领域[4].正则表达式由普通字符和元字符(metacharacters)组成.普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,例如“d”(不含引号,后同)可以匹配任意一个数字字符.有关元字符的详细描述,可参考《PowerGREP与语料库加工》一文[3].
PowerGrep的主要功能包括查找(search)、查找和替换(search and replace)、数据采集(collect)等.其主界面如图1所示:
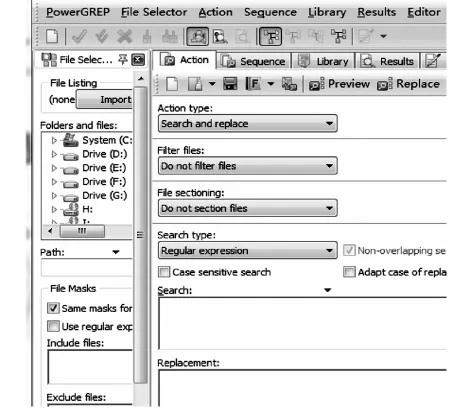
图1
PowerGrep的操作,一般分为以下几个步骤∶
(1)在左侧的文件浏览界面中选择需要处理的文件.用鼠标左键选中单个或者多个文件后,点击软件左上角的“√”即可,文件选中后,会在文件名左侧出现绿色的“√”;也可以用鼠标选中单个或者多个文件夹,之后点击软件左上角的“√√”,即可选中所选文件夹内的全部文件;
(2)在右侧的Action type中选择“Search”(查找)或“Search and replace”(查找并替换)等操作模式;
(3)以查找并替换模式为例,选择该模式后,在Search框输入需检索的字符串,在替换框输入需替换的字符串,点击软件上方的“Replace”,即可实现替换操作.
3 PowerGrep在语料标注中的应用
由于其强大的文本搜索及替换功能,PowerGrep可以高效地实现对标注的各种加工目的,节省大量人力.下面以笔者构建的电子商务翻译语料库为例,介绍PowerGrep在批量替换标注赋码、批量添加标注以及批量校对标注等方面的应用.
3.1 批量替换标注赋码
笔者构建的电子商务翻译语料库,对英文文本和中文文本分别使用CLAWS4和中科院ICTCLAS 2008软件进行了词性标注.CLAWS4的赋码标记是“_”,而ICTCLAS则是“/”.为了便于检索起见,有必要统一为一种赋码标记.虽然一般的办公软件如记事本、Word等都能通过查找替换操作实现这一目的,但由于不支持批量操作,会耗费大量的人力.用PowerGrep处理起来则极其简单、快捷,步骤如下:
(1)在使用CLAWS及ICTCLAS进行词性标注之前,在PowerGrep中选择全部文本,Action type选择“Search and replace”,在Search栏输入“/”,在Replacement栏输入“##”,点击“Replace”,将“/”替换为“##”.这一操作的目的是将文本中可能存在的与词性赋码标记相同的“/”先替换为其他符号,以免在词性标注之后被混为词性赋码标记而替换掉.
(2)使用CLAWS和ICTCLAS对全部文本进行词性标注;
(3)在PowerGrep中选择词性标注后的全部文本,参照步骤1的方法将“/”批量替换为“_”;
(4)再将“##”批量替换还原为“/”.
3.2 批量添加标注
电子商务翻译语料库除词性标注外,还对部分语料做了错误标注,赋码标记为<>.例如,“Precautions 常见问题处理<Term>”,Precautions在产品说明书中是一个常见术语,意思是“注意事项”,译为“常见问题处理”是错误的,笔者用<Term>这一标注码对这一术语翻译错误做出标注.国内对语料进行错误标注的语料库不多,其中较为著名的是CLEC,其言语失误标注码多达61种,每个标注码包含3个字符,如fm1指Spelling错误[5].标注者需要较为熟悉标注系统,判断错误类型后手工输入对应的标注码,设计为3个标注码可以减轻手工输入的负担.但错误标注码即便是3个字符,在数量较大的情况下,手工输入的工作量仍然非常大,对此笔者深有体会,由此产生了利用PowerGrep批量添加标注的尝试.操作方式如下:
(1)复制<>符号,在需要输入标注码的地方,按ctrl+v,即可将<>粘贴至该处.这一方法比手工依次输入<>或者在某些文本处理软件中通过鼠标点击预制好的字符集都要高效省力;
(2)在<>中输入标注码对应的数字及字母,标注者需要较为熟悉这些标注码及其对应的数字及字母,例如,1代表“Spelling”,2代表“Term”.这样只需输入1个字符即可完成标注.
(3)标注全部完成之后,利用PowerGrep将数字或者字母代表的标注码还原为完整的标注码.例如,在PowerGrep中选中全部文件,在Search栏输入“(<)(1)(>)”,在Replacement栏输入“1Spelling3”,点击“Replace”,即可完成全部Spelling错误的标注码还原.
“Spelling”和“Term”这种标注码相比3个字符的标注码而言,虽然较长,却更为直观,在省却了长串字符输入的情况下,值得推广.
3.3 批量校对标注
上述人工输入的标注可能存在错误.例如,有时会遗漏数字或者字母的输入,导致只有<>赋码标记,在PowerGrep中搜索“<>”即可查出此类错误.另一种可能是输入了非数字或者非字母的字符,如“#”,可在PowerGrep中搜索“<[^0-9a-zA-Z]>”,即可查出此类问题.
PowerGrep的文本检索功能非常强大,可通过正则表达式查找各种存在问题的标注,达到批量检查校对的目的.
4 结语
数十年来语料库语言学的迅猛发展得益于一大批高质量语料库的构建,如BNC,ICE和ICLE等,目前语料库的构建已愈来愈专门化,语料库构建的技术门槛阻碍了一些有志于语料库研究的人士加入语料库构建的行列,而利用各种正则表达式,PowerGrep在语料加工方面可以实现各种批量操作,其在语料库构建及检索中有着广阔的应用前景和发展潜力.对PowerGrep这类功能强大的文本处理软件的应用探索,有利于更多的语料库研究者掌握相关技术,共同促进语料库建设的繁荣发展.
〔1〕余军.CAT平台下多模态学习者双语语料库构建[J].厦门理工学院学报,2012(03).
〔2〕Leech,G.Introducing corpus annotation [A].In R. Garside,G.Leech&A.M cEnery(eds.)Corpus Annotation:Linguistic Information from Computer Text Corpora[C].London:Longman,1997.
〔3〕严华,王立非.PowerGREP与语料库加工[J].外语电化教学,2010(03).
〔4〕薛学彦,李文中.PowerGREP与语料库信息检索[A].卫乃兴,李文中,濮建忠.语料库应用研究[C].上海:上海外语教育出版社,2005.
〔5〕桂诗春.中国学习者英语言语失误分析[A].杨慧中,桂诗春,杨达复.基于CLEC语料库的中国学习者英语分析[C].上海:上海外语教育出版社,2005.
H31
A
1673-260X(2013)11-0249-02
福建省社会科学规划项目资助(2010B153)
猜你喜欢
吉林电力(2022年2期)2022-11-10 09:24:38
科学家(2021年24期)2021-04-25 12:55:27
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
阜阳职业技术学院学报(2015年4期)2015-05-17 03:58:58
印刷技术·包装装潢(2015年11期)2015-02-16 08:25:49
民族古籍研究(2014年0期)2014-10-27 08:24:34
印刷技术·包装装潢(2014年5期)2014-08-27 16:56:19
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
温州职业技术学院学报(2014年3期)2014-03-11 19:03:39
