
智能知识地图挖掘数据的金融危机早期预警
2013-07-20 02:34吴小菁
计算机工程与应用 2013年24期
吴小菁
福建江夏学院电子信息科学学院,福州 350108
智能知识地图挖掘数据的金融危机早期预警
吴小菁
福建江夏学院电子信息科学学院,福州 350108
模糊认知图(Fuzzy Cognitive Map,FCM)是知识表示和管理的有效方法[1],由一系列节点和连接这些节点的加权弧组成,节点代表概念或变量,加权弧[2]代表概念或变量间的因果关系。目前模糊认知图已广泛应用于建模、分类及预测[3]。
最初,模糊认知图主要根据专家的认识构建,由于忽略了主要的原始数据资源,构建的地图带有主观性和局限性,效果并不理想。目前已提出许多建立模糊认知图的学习算法,例如,文献[4]提出一种简单的差分赫布学习算法(Differential Hebbian Learning,DHL),通过迭代更新权值直到权重汇聚到某个预先定义的状态。文献[5]描述了一种自动构建模糊认知图的方法,其中由数据矢量表示的两个概念间的关联强度由它们的相似性决定。文献[6]描述了运用粒子群优化(Particle Swarm Optimization,PSO)学习的方法。然而随着节点数和弧数增多,使用优化算法构建模糊认知图,迭代至权重矩阵达到最佳状态需要花费大量时间,同时产生的模糊认知图也十分复杂,可读性差。为解决这一问题,文献[7]引入由模糊认知图(Fuzzy Cognitive Map,FCM)衍生知识地图(Knowledge Map,KM),文献[8]描述了一种基于历史数据产生知识地图的方法,并开发了商用软件OntoSpaceTM,该方法的核心思想是从数据源自动提取特定知识,以改善地图的性能,使用户可以迅速了解信息在变量间的流动情况。尽管上述方法都取得了一定的预测效果,但是实际应用中的预测准确性仍然不够高。
针对上述问题,提出了基于智能知识地图的数据挖掘方法,与上述各方法不同的是,它采用无模型的方式,根据历史数据生成智能知识地图,对KM进行静态分析和时域分析,从而实现对系统内部结构和关系的深入剖析,准确预测系统的发展趋势。所提方法的可靠性通过对上证50指公司的金融数据分析得到了验证,分析结果表明,基于智能知识地图挖掘数据的方法能够在早期准确预警金融危机。
1 知识地图
作为FCM的延伸,知识地图是一种在复杂系统中描述知识并将知识模型化的技术,也称做过程图。
KM可以用一个三元组U来表示,U=(V,L,C)。V= {v1,v2,…,vn}是代表变量或概念的节点集合,L代表参加组对节点的连接,例如vi和vj(vi,vj∈V)。连接包括所有用来描述变量间的因果关系的模糊规则,C代表一组连接器,它们将集合(vi,vj)映射到(λij,Eij)。λij是vi和vj间的广义交叉相关系数,Eij是相应散布图上的图像熵,连接符可以看做知识地图和模糊认知图的关键性区别,相关系数和相关熵定量描述了系统中规则模糊和混乱的程度。
如图1所示为一幅典型的知识地图,所有的节点沿对角线排成一条直线,它们的连接显示为两个垂直段或者水平段,不同集合的节点,如输入节点和输出节点,用不同的颜色标出。与其他节点有密切关系的中枢节点以圆形显示,不活动节点以白色正方形显示。在设计结构矩阵理论(Design Structure Matrix,DSM)[9]中,段布局避免了冗余,也使得知识地图可读性更强。

图1 典型的知识地图
知识地图为用户提供了大量信息,可概括为:(1)识别变量间的因果关系;(2)可视化给定系统中的信息流动;(3)将变量分级排列,变量的重要性由中枢节点和不活动节点显示。
发挥知识地图优势的主要任务是得到一张客观、精确的知识地图,正如引言中提到的,比起根据专家的看法建立的知识地图,从历史数据挖掘的地图更有效,丢失的信息更少。挖掘过程应无模型[10],不使用统计学方法或回归方法,以保留数据中隐藏的所有信息。不同于之前的FCM的学习算法,Marczyk提出的KM挖掘方法省略了耗时的迭代步骤,通过分析数据资源直接构建知识地图,后面将会详细介绍。
2 方法提出
给出一组庞大的数值数据:

上式中,xkj表示第j个变量vj的第k个样本,目的是通过挖掘数据矩阵X生成知识地图,所提方法可划分为四个步骤:构建散布图、生成模糊规则、构建知识地图、识别中枢节点及不活动节点。
2.1 构建散布图
利用成对变量vi和vj(1≤i≤j≤n)用来画出整体为n(n-1)/2的散布图,每张散布图的两个关键属性之一是在0至1区间内的广义相关系数[11],计算如下:

上式中,I(vi,vj)代表共同信息,用来衡量vi与vj间总体线性和非线性相关度:
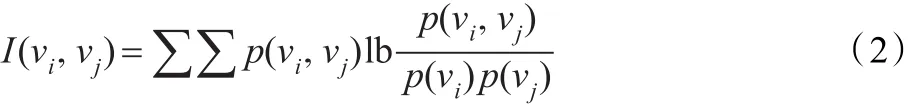
上式中,每个变量经过离散、映射到时距上,这样,相关性被量化以清楚显示这两个变量如何相互影响。如果λij达到0,那么vi不包含vj信息,相反,λij=1则表示,vi与vj间相关性很高,从而其中一个可以完全由另外一个确定。

它可以衡量散布图中的信息,杂乱无序的散布图包含大量不确定性,通常有大的熵值,因此如果一张散布图的图像熵相对很高,而广义相关系数很小,那么变量间关系也就不密切,散布图没有显著的模糊规则,最终生成的知识地图上两个变量间将不会创建连接。
2.2 生成模糊规则
所提方法采用的从数据生成模糊规则的方法与文献[13]提出的关联规则聚类系统(Association Rule Clustering System,ARCS)在本质上是一致的,但它们生成规则的形式大不相同。这里的目的是找出一个变量在另外一个变量发生变化时做出何种反应。因而,定义了如下四种规则:IF+DeltaX,THEN DeltaY;IF-DeltaX,THEN DeltaY;IF+DeltaY,THEN DeltaX;IF-DeltaY,THEN DeltaX,可表达为四元组,例如,(+1,-1,+1,-1)意味着如果变量X增加或减少一个单位,Y变量同时也相应增加或减少一个单位,反之亦然。
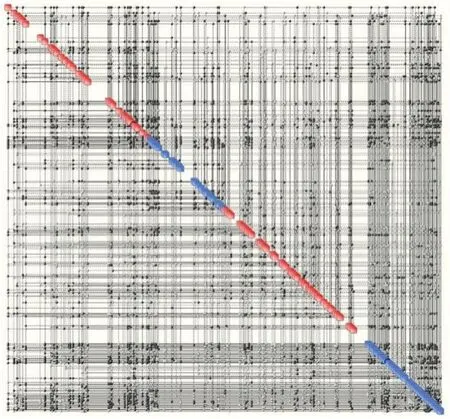
图2 CMB知识地图
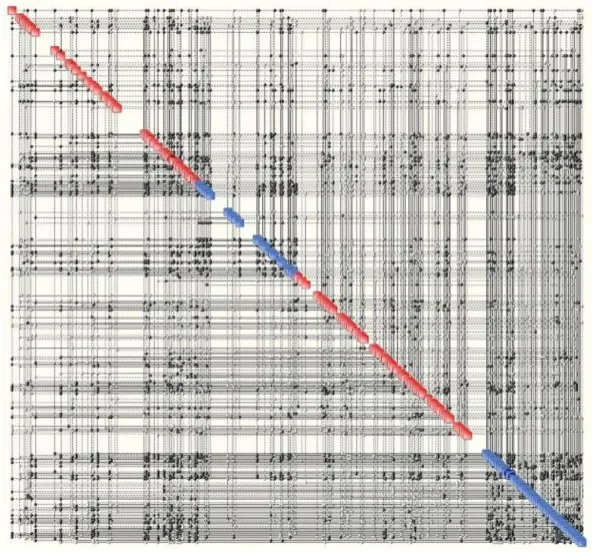
图3 CMBC知识地图

图4 SPDB知识地图
首先假定一个模糊水平(通常是3、5或7),并将整个变量空间划分区域,以3为例,根据抽样值,变量划分成低、中、高三种类型来将数据矩阵中的数值矢量转化成模糊矢量,原始数据中的每个抽样属于特定的模糊格。然后,分析所有有效的散布图。由于散布图是二维的,投射到平面上的格数是预先定义的模糊水平的平方,每个模糊格应包含构成该图的足够的样本。最后,将每个格设为坐标原点,在该散布图中,向右移动为(+DeltaX),向左移动为(-DeltaX),向上移动为(+DeltaX),向下移动为(-DeltaX)来确定最可能达到的格,以表明另外一个变量的变化程度。如果没有主导趋势或者到达几个格的可能性相同,那么将不会产生规则,记录趋势并把结果转换成模糊规则,最终标记为四元组。
2.3 构建知识地图
知识地图由节点、连接和连接器组成。首先,所有的n变量由沿对角线排列的n节点来表示,输入变量和输出变量由节点颜色加以区别。
然后,在第二步产生模糊规则的基础上确定连接。如果一张散布图中至少存在一个四元组,那么通过交换信息可以在变量间创建一个连接,反之,节点间将不产生连接。每个连接显示为两个垂直段或水平段。这些段在连接器内交叉使地图更加简洁明了,称为DSM理论[14],在没有连接器时,它将段的重叠数量最小化。衡量连接器的两个关键属性,即广义相关系数和图像熵用来说明两个变量相互影响的程度和该关系中的不确定性的量。
最后,计算这些包含四元组的散布图中所有图像熵的总和,并将其作为地图的总熵[15]记录下来:

2.4 识别中枢节点和不活动节点
在调出的3109份病历中,以《中国老年人潜在不适当用药目录》[3]为依据,对老年患者的用药潜在风险情况进行评价,共有2545份病历存在潜在不适当用药的风险,占81.9%。按药品类别和名称分类,涉及12类36种药物共计5516例次存在潜在不适当用药的风险(1份病历可能同时存在多种药物的潜在不适当用药的风险),其中占前四位的是呼吸系统用药、血液系统用药、内分泌系统用药和神经系统用药,见表2、表3。
第三步中构建的知识地图用来推断出哪一变量对系统产生的影响最大,哪些相对独立。一个节点的重要性通过计算从该节点产生多少连接来确定。关联最多的节点叫做中枢节点,而没有连接的节点是不活动节点。这两种节点都清晰地表示在地图中,连接的总数l用来计算地图的密度。

上式中,q代表活动节点的数量,这就完成了知识地图的挖掘过程。
3 实验
所有实验均在4 GB内存Intel®CoreTM2.93 GHz Windows XP机器上完成,使用商业软件OntoSpaceTM分析上证50指数的成员状况。
3.1 数据集
上证50指数是包括上海证券交易所中最具代表性、最有影响力50只股票,具有很强的流动性。在试图描述这些公司的复杂情况时,实验使用资产负债表、收入报表、现金流报表及股市数据四种类型的数据表。金融行业的公司共294个参数,其中资产负债表中有96个,收入报表中有51个,现金流报表中有97个,股市数据中有50个。金融行业外的公司有238个参数,分布在以上四种数据表的参数数量分别为75、33、80、50。这些历史样本跨越了2002年至2010年九年时间,它们均公布在网站上。基于这些完整的数据,数据矩阵将有36条线,294列或238列,从这些数据中挖掘出KM,并作静态分析和时域分析。
3.2 静态分析
静态分析利用所有2002年至2010年间的历史数据构建一幅知识地图,呈现这些公司的完整面貌,模糊水平都设定为5。为简洁起见,图中只呈现了三家金融行业公司的分析结果:中国商业银行(CMB)、中国民生银行股份有限公司(CMBC)及上海浦东发展银行(SPDB),选定这三家公司是因为它们在这九年间的财务报表比其他金融机构的更加完整,而数据的完整性会极大地影响结果的准确性。
如图2~图4所示为CMB、CMBC和SPDB根据财务数据生成的KM,资产负债表和现金流报表中的参数以红色正方形表示,另外两张报表中的参数以蓝色正方形表示,地图的四个关键特征:活动节点数、连接数、密度和总熵如表1所示,三张图中活动节点的数量差别不大。
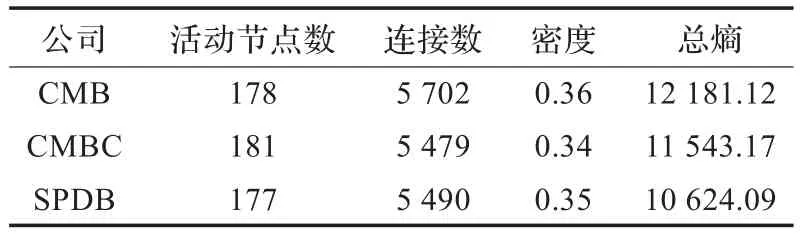
表1 CMB,CMBC和SPDB知识地图的关键特征
从图2至图4、表1可以看出,在CMB知识图中,连接数和密度均辨明变量间的关系最紧密,意味着控制该公司相对困难,因为一个节点的轻微干扰将迅速传送到其他节点,而CMB的KM中的总熵也最高,说明它的内部结构更容易崩溃,规则和模式更容易消失在混乱的环境中。
总体来说,CMB的结构最复杂,而在如此复杂的系统中它的不确定性也最多,因而CMB能够执行更多的功能的同时,该公司良好的运营状况也更容易被瓦解。如果环境发生变化,不确定性增多,公司将变得不可控制。其他两家银行的复杂性与之类似,但比CMB相对简单,CMBC的关系更疏远些,SPDB的不确定性相对来说最少。此外,根据图2至图4及表1可作出如下推断:资产负债表和股市数据对地图的贡献最大,这两个参数与其他参数联系紧密,因而产生了大量的连接。实验发现,CMB知识地图中,资产负债表中的“资产总额”、“负债总额”和值为0.91的广义相关系数的关系最为紧密,0.91十分接近1。这两个变量组成的散布图的图像熵是1.63,变量之间相互协调,与所提规定为(+1,-1,+1,-1)的模糊关联规则相一致,将这些模糊规则储存为知识可以帮助决策者更好地了解公司的运营状况。
实验中,这三家公司最重要的10个参数通过节点产生的连接数衡量出来,如表2~表4所示。例如,S4-v14,即第4个数据集合中的第14个变量,是CMB知识图中最重要的参数。
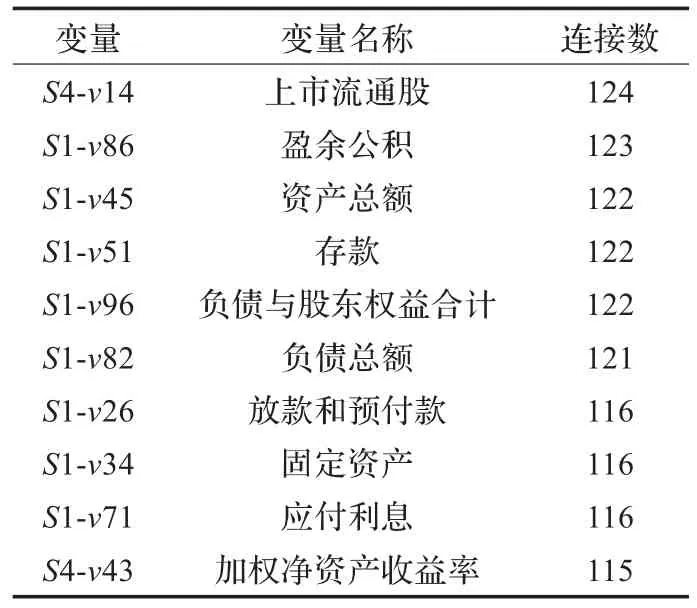
表2 中国商业银行CMB的10个最重要参数
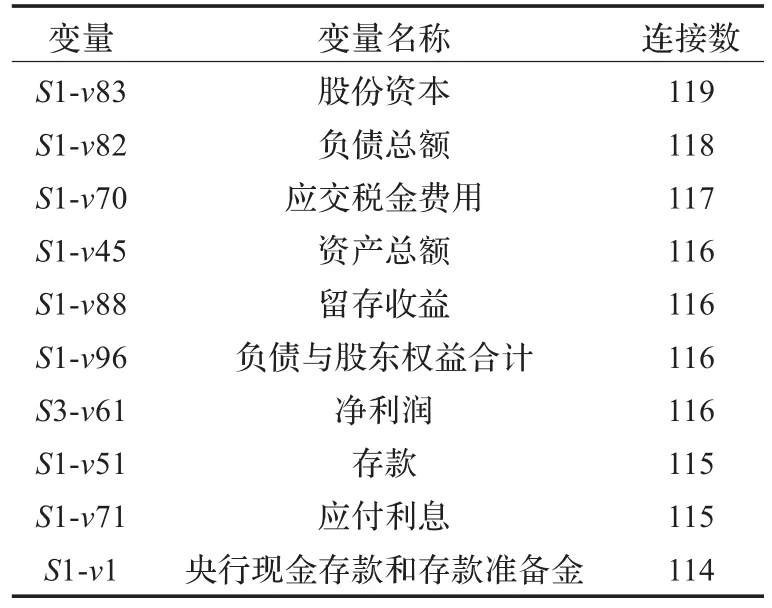
表3 中国民生银行股份CMBC 10个最重要参数
从表2~表4可以看出,尽管中枢节点不尽相同,三家公司都与许多重要节点有联系,包括“资产总额”、“负债总额”及“存款”。因而这些参数颇有影响力,并且值得决策者密切关注。8/10的重要变量来自资产负债表,因而可以得出结论:资产负债表在系统中发挥主导作用。知识图中的中枢节点明确标识最脆弱的位置,公司应该密切关注这些变化,因为它们可能导致整个系统的崩溃。
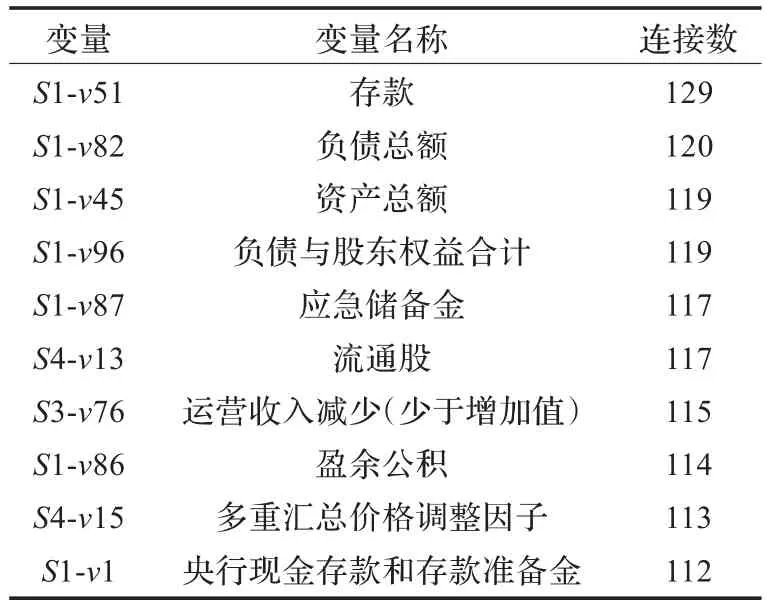
表4 上海浦东开发银行SPDB 10个最重要的参数
3.3 时域分析
在时域分析中,样本分成几个连续的周期或者窗口,每一步仅有一个窗口接受检验,窗口相互重叠以使得每一步的结果不会有太大差异。窗口宽度设为12,重叠的一步是11。12个四元组的金融报表和股市数据被用来挖掘知识地图,共生成25张地图,以跟踪各公司的效益,并在结构和不确定性方面监控系统运营情况。
下面分析了来自制造业、原油开采和房地产三个非金融行业的三家典型的公司,国家工商管理总局(SAIC)、中国石化(Sinopec)和金地集团(Gemdale)。所用的2002—2010年间的金融数据完整,这使分析结果更为可信。
图5显示对应7年里7步构建知识地图的4个关键特征的演变过程。前三张图从不同的角度描述了这些公司结构上的变化,最后一张图则展现了其不确定性的变化趋势。
如图5(a)所示,SAIC和Sinopec在2006年至2007年间的活动节点数量急速增长,而Gemdale的增长则没有如此剧烈。图5(b)显示在2007年,三家公司连接的数量都迅速上升至较高水平。图5(c)中,同一年Sinopec和Gemdale的地图密度达到各自的最高点,而SAIC的地图密度保持相对稳定。连接数量的增长表明三家公司的结构都在2007年变得更加复杂。图5(d)的总熵趋势图进一步表明三家公司的不确定性在2007年前一直保持增长,尤其是SAIC。
复杂的结构加上不明朗的形势可能造成控制和管理公司方面的困难,连接数量和总熵的突变应作为危机的征兆谨慎对待。为确定2007年的剧增是否是特殊的案例,对2002年至2010年间所有上证50指股份公司进行全面的金融和股票数据分析,共有12家公司满足这种情况,包括静态分析中涉及的三家银行。将2006年和2007年各家公司知识地图中连接数和总熵及其增长率列在表5中,其中,75%的公司在2007年连接数量猛增,平均增长率为13%,此外,总熵平均增长了9%,12家公司中有9家出现增长。
从表5可以看出,知识地图的关键属性在2007年总体上呈现增长势头。众多因素可能导致这一状况,其中全球经济大环境扮演着一个关键角色。随着全球经济日趋恶化,这些公司的不确定性势必大增,功能性趋于复杂,这与公司结构变化有直接关系。知识地图的主要特征不仅反映了金融系统的运营情况,也在某种程度上映射整个经济大环境。与公司结构和不确定性保持一致的连接数量和总熵的猛增是2008年金融危机的预警信号。

图5 SAIC,Sinopec和Gemdale三家公司知识地图的4个关键特征的演变过程
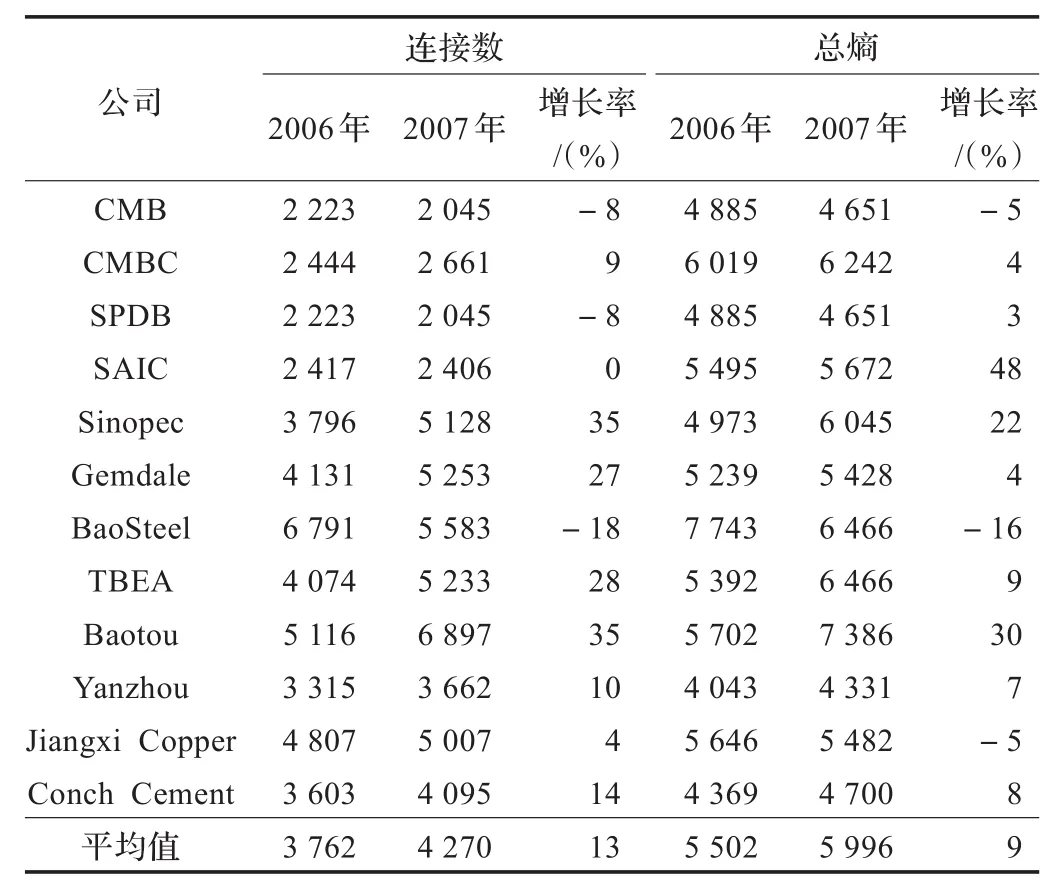
表5 2006年、2007年12家公司知识地图中的连接数和总熵
假如2006年至2007年的异常变化能及时报告给各公司管理者,他们将能为经济危机作更好的准备,并在危机发生之前采取适当的措施以减少和避免亏损,因此智能知识地图挖掘是一个十分有效的危机预警工具。
综上所述,时域分析使管理者可以从结构和不确定性方面监控公司的运营情况,公司知识地图复杂性的陡增预示着该公司将遭遇动荡,并可能由于系统内部趋于复杂和脆弱的联系而崩溃。
3.4 比较及分析
为了更好地体现所提方法的优越性,将所提方法的时域分析结果与其他几种较为先进的模糊认知图和知识地图进行了对比,包括基于信任知识库的概率模糊认知图(TKL-PFCM)[1]、基于神经网络的知识地图(NN-KM)[4]、复杂系统模糊认知图(CS-FCM)[5]、基于属性的知识地图渐进式增量模型(AKM-GIM)[10]、XTM知识地图(XTM-KM)[11],实验对2006年、2007年上述12家公司知识地图的连接数、总熵及增长率进行了计算分析,如表6所示为记录的平均结果。

表6 各方法的知识地图平均连接数和平均总熵比较
从表6可以看出,在所有的方法中,本文所提方法的平均连接数、总熵的增长率均为最高,甚至有的方法取得的增长率是负的,如TKL-PFCM、CS-FCM。在所有的比较方法中,XTM-KM表现最为出色,平均连接数增长率仅比所提方法低2个百分点,但是,它的总熵增长率却比所提方法低5个百分点。由此可见,考虑知识地图连接数及总熵的增长率作为预警金融危机的两个重要因素,所提方法明显优于其他几种较为先进的模糊认知图和知识地图。
4 结束语
针对传统模糊认知图和知识地图数据挖掘效率偏低且预测准确性偏差的问题,提出了一种在没有相关领域专家介入的情况下通过挖掘金融数据构建智能知识地图的方法。通过OntoSpaceTM软件运用这种方法分析上证50指公司运营状况。静态分析结果显示KM能够通过给定的模糊规则、相互依赖性、中枢节点和不活动节点找到接受监测系统的结构,并由总熵来衡量识别不确定性。时域分析揭示了知识地图主要特征的演变,决策者可以利用这一点来监控公司的运营状况。实验结果表明,从金融数据挖掘构建智能知识地图有其重要价值,跟踪知识地图的主要特征演变可以准确地预警金融危机,而运用惯常的模糊认知图和知识地图难以做到这一点。
未来会将所提数据挖掘方法运用到其他金融数据集上,进一步增加预测的准确度,从而更好地应用到实际的危机预警系统中。
[1]骆祥峰,高隽,张旭东.基于信任知识库的概率模糊认知图[J].计算机研究与发展,2003,40(7):925-933.
[2]彭珍,杨炳儒,刘春梅,等.一种模糊认知图分类器的研究[J].计算机应用研究,2009,26(5):4205-4208.
[3]马楠,杨炳儒,鲍泓,等.模糊认知图研究进展[J].计算机科学,2011,38(10):23-28.
[4]Hong T,Han I.Knowledge-based data mining of news information on the Internet using cognitive maps and neural networks[J].Expert Systems with Applications,2002,23(1):1-8.
[5]张桂芸,马希荣,杨炳儒.复杂系统模糊认知图的分解研究[J].计算机科学,2007,34(4):129-132.
[6]李岱.模糊认知图优化算法与几何图形识别应用研究[D].兰州:兰州理工大学,2012.
[7]翟东升,张娟.模糊认知图在上市公司信用风险评价中的应用[J].统计与决策,2008(2):161-163.
[8]Wu W W,Lee Y T,Tseng M L,et al.Data mining for exploring hidden patterns between KM and its performance[J].Knowledge-Based Systems,2010,23(5):397-401.
[9]徐兰,方志耕,刘思峰.基于设计结构矩阵的复杂产品供应链管理优化[J].运筹与管理,2013(1):106-111.
[10]潘星,王君.一种基于属性的知识地图渐进式增量模型[J].系统工程学报,2012,27(2):169-176.
[11]夏立新,王忠义,张进.图书馆专家知识地图的XTM构建方法研究[J].中国图书馆学报,2009,35(2):47-52.
[12]陈宇飞,吴启迪,赵卫东,等.基于图像熵的快速Chan-Vese模型分割算法[J].同济大学学报:自然科学版,2011,39(5):22-32.
[13]沈斌,姚敏,刘艳彬.基于带语义差别的模糊Taxonomy的交易数据库关联规则聚类[J].情报学报,2010(2):246-253.
[14]文杏梓,罗新星.基于设计结构矩阵的可信软件非功能需求评估模型[J].计算机应用研究,2012,29(10):3787-3790.
[15]Lu H,Zhang H,Yang S,et al.A novel camera parameters auto-adjusting method based on image entropy[M]//RoboCup 2009:Robot Soccer World Cup XIII.Berlin,Heidelberg:Springer,2010:192-203.
WU Xiaojing
College of Electronics and Information Science,Fujian Jiangxia University,Fuzhou 350108,China
For the issue that the traditional fuzzy cognitive map and knowledge map have inefficient data mining and low predictability,data mining based on intelligent Knowledge Map(KM)is proposed.Paired variables are used to construct scatter diagram by discrete and mapping from original data.Quad fuzzy association rules are defined based on which knowledge map is constructed.Numbers of linked nodes are used to recognize central node and inactive nodes.Uncertainty of the system structure is estimated by static analysis,and evaluation process of major KM attributes is uncovered by time-domain analysis.Then efficiency of proposed method has been verified by analysis on financial data of 50 index companies in Shanghai Stock.Experiments results show that the proposed method has perfect predicting effect on financial crisis warning,which provides a powerful crisis warning tool for deciders controlling operating condition of company.
intelligent knowledge map;data mining;financial crisis warning;static analysis;time-domain analysis
针对传统模糊认知图和知识地图数据挖掘效率偏低且预测准确性不高的问题,提出了基于智能知识地图的数据挖掘方法。利用成对变量的离散、映射从原始数据构建散布图;定义四元组模糊关联规则,在此基础上构建智能知识地图;根据关联节点数目识别中枢节点和不活动节点。实验利用静态分析评估了系统结构的不确定性,通过时域分析揭示了知识地图主要属性的演变过程,对上证50指数公司的金融数据分析验证了所提方法的有效性,实验结果表明,所提方法在金融危机预警方面取得非常准确的预测效果,为决策者掌控公司运营状况提供了强有力的危机预警工具。
智能知识地图;数据挖掘;金融危机预警;静态分析;时域分析
A
TP399
10.3778/j.issn.1002-8331.1308-0005
WU Xiaojing.Data mining based on intelligent knowledge map for financial crisis early warning.Computer Engineering and Applications,2013,49(24):116-121.
福建省科技支撑计划项目(No.102102210419)。
吴小菁(1977—),女,讲师,主要研究领域为数据挖掘、机器学习、智能计算及应用。
2013-08-02
2013-09-16
1002-8331(2013)24-0116-06
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
国际眼科杂志(2021年9期)2021-09-15
小学生学习指导(高年级)(2021年4期)2021-04-29
民用飞机设计与研究(2020年4期)2021-01-21
装备制造技术(2020年2期)2020-12-14
河北理科教学研究(2020年2期)2020-09-11
电子制作(2018年18期)2018-11-14
山东工业技术(2016年15期)2016-12-01
中国卫生(2015年12期)2015-11-10
数学年刊A辑(中文版)(2015年2期)2015-10-30
