
用延迟的异常路径检测防御非控制流数据攻击
2013-07-20 02:34王瑛张蓝图
计算机工程与应用 2013年24期
王瑛,张蓝图
中船重工(武汉)凌久高科有限公司,武汉 430074
用延迟的异常路径检测防御非控制流数据攻击
王瑛,张蓝图
中船重工(武汉)凌久高科有限公司,武汉 430074
1 引言
攻击是攻击者利用程序中的内存漏洞(如缓冲区溢出漏洞、格式化字符串漏洞、堆溢出漏洞或整数溢出等)篡改程序地址空间中关键数据,改变程序正常的执行流程,以达到其目的,如提升用户权限或者发动拒绝服务攻击等。多数攻击倾向于修改控制流相关数据(control data),如返回地址值、调用函数的EBP、函数指针和GOT表项等,以此改变进程的控制流使其指向攻击者指定恶意代码处,从而使系统执行攻击者所提供的恶意代码,造成严重的安全危机。然而攻击者也可以通过非控制流数据(Non-control-data)攻击[1],篡改其他关键性的数据,在不篡改控制流数据(如函数返回地址值,函数指针等)的情况下改变进程的控制流,以达到攻击目的。
针对篡改控制流相关数据的攻击已有多种防御方法,可利用传统的针对内存漏洞的防御方法,如StackGuard[2]、Propolice[3]及RAD[4]等,以增加攻击的难度。然而随着新型漏洞的层出不穷,单一的漏洞防御不能做到防御全部类型的漏洞。而针对控制流相关数据的防御方法和控制流一致性检测方法却不能抵御非控制流数据的攻击。作为主要的非控制流数据的攻击类型,决策性数据攻击仅仅是通过篡改某些局部变量值,从而改变关键性的条件跳转分支语句的执行,以此改变进程的控制流。比如攻击者可以通过修改SSH中的某些关键局部变量值,如判断用户是否拥有root权限函数的局部变量authenticated的值,使其为非零,就能获得root权限[1]。此类攻击所执行的是进程中正常的代码而非恶意代码,并且所有的程序控制流转移都是合法有效,因此传统的防御方法并不适用于防御此类攻击。
由于程序正常执行时相邻的条件跳转语句之间存在着相关性,决策性数据攻击势必会改变这种相关性,造成程序执行的路径发生异常。因此为防御这类非控制流数据的攻击,研究者提出了基于程序路径一致性的检测方法。这类防御方法以一系列条件转移时标志位的值来描述程序行为,并以此作为检测对象,实时检测程序是否发生异常。然而这类方法由于检测对象覆盖不够高,比如只检测连续执行的6到8个条件跳转的标志位值[5],因此容易产生二义性,造成漏检。另一缺陷则是由于检测频率过高,容易造成较大的性能开销。
本文在分析现有防御方法优缺点的基础上,提出一种延迟检测异常执行路径(Anomalous Path Lazily Detection,APLD)的方法,用以防御决策性数据的攻击。考虑到攻击者需要利用系统调用实现其最终功能,因此将检测时刻尽可能延迟到系统调用前,而相对应的检测对象则包含了相邻两个系统调用之间所有的条件跳转指令。为有效描述程序的执行行为特征,用层连的哈希运算提取出到达系统调用所经历的路径的特征值,以此作为检测对象。APLD方法尽可能地包含足够多的条件跳转,因此能最大限度减少二义性问题,降低漏检率。同时延迟的检测降低了检测频率,有利于降低检测方法的性能开销。
2 相关工作
控制流数据攻击和非控制流数据攻击虽然最终篡改的对象不同,但是两类攻击均需要利用程序中的漏洞(如缓冲区溢出漏洞、格式化字符串漏洞等),对程序中的假定不变量(如地址)进行攻击,修改程序中可写内存段的值。为防止攻击发生,可采用传统的漏洞防御方法及地址随机化方法。
针对特定漏洞类型的防御方法可在一定程度上加大攻击的成本,提高攻击的难度。然而单一的漏洞防御方法并不能完全防御控制流的非法转移,攻击者仍然可以利用其他漏洞(堆缓冲区溢出漏洞、虚指针等)篡改目标数据。地址随机化方法包含了不同粒度空间的随机化,如代码段随机化[6-7]、函数块随机化[8]以及字节级随机化方法[9-10]。然而在具体实现时,受到随机量大小的限制,地址空间分布随机化的方法容易被暴力破解[11]。同时由于各种操作系统和编译器实现的方法不一样,地址随机化在进程中应用范围不够,部分内存段中的数据未被随机化,易被攻击者可以利用此类信息绕过防御方法[12]。
当攻击最终发生时程序将会出现异常的行为,程序的一致性被破坏,因此可以通过对程序完整性进行检测以防御非控制流数据的攻击。程序的一致性检测是指分析并实时监测程序的控制流、数据流及执行路径,对程序中的关键对象(如代码、数据等)进行保护,防止这些对象被非法篡改。根据检测对象的不同,可以分为控制流一致性检测、数据流一致性检测和执行路径一致性检测。控制流一致性检测通过控制流图保护关键的控制流对象或者代码不被篡改,然而非控制流数据的攻击并不会使得程序中的控制流出现错误的转移,因此这种检测方法不能有效防御非控制流数据攻击。
数据流一致性检测通过数据流图保护关键的数据流对象不被篡改,可以有效防御各种数据被篡改,因此可以防御非控制流数据的攻击。典型的工具有:Data Flow Integrity[13]通过数据流分析检测违反数据流图的恶意写内存对象操作;Typechecking[14]检测静态敏感的数据对象中是否含有恶意的内容;WIT[15]对程序间的指针进行分析,同时结合了染色机制计算出某个内存对应的写指令,从而对超出内存对象的写指令进行严格限制。然而数据流一致性检测方法属于一种白盒技术,部分检测方法需要静态分析源代码,从而获得完整的数据流图。部分采用了染色分析技术的检测方法严格限制了输入数据的使用,带来了误检率过高的问题。
尽管在非控制流数据攻击中,控制流的转移都是有效的合法的,但是相邻条件跳转语句之间的相关性被破坏,程序原有的执行路径却发生了变化。因此可以利用执行路径一致性,实时检测当前程序的执行路径是否异常,以此来检测攻击。Shi Y et al[5]采用滑动窗口n检测程序执行时的相邻n个条件跳转标志位的值是否正常,其中n取6到8。这种检测方法能有效检测非控制路数据攻击所造成的异常的程序执行路径,但由于受限于n的取值,不能完整覆盖正常路径,容易出现二义性问题,造成漏检。Santos J C M et al[16]则是检测相邻的间接跳转语句之间所有的条件跳转标志位,为防止二义性,将紧邻间接跳转指令的条件跳转指令的地址加入到检测对象中。然而这种方法与Shi Y et al方法一样,需要在每条间接跳转指令处检测程序的执行路径,检测频率仍然较高,性能开销较大。
3 异常执行路径的延迟检测
本文假设攻击者具备修改进程中可写内存的能力,可以通过各种漏洞(如缓冲区溢出、格式化字符串等)实施决策性数据攻击。
3.1 执行路径的表征
由于需要在系统调用指令执行前验证程序已经执行的路径是否有效,并且考虑到只有当条件满足时,条件转移指令才会执行。因此可以在程序执行时,提取相邻的系统调用指令syscalli-1和syscalli之间的所有被执行的条件跳转指令,将其地址序列用于表征程序的执行路径。假设数组EP中存储正确的程序执行路径信息,则此时的EP[i]由syscalli-1和syscalli之间的条件跳转地址序列组成。
由于工作负载不同,程序的执行路径可能不同,由此会产生多条到达同一系统调用的不同的执行路径。而系统调用指令为终点的地址序列由于包含的地址个数不一,会造成极大的存储开销,由此带来较高的性能开销,因此有必要拟合程序的执行路径信息。一种拟合程序的执行路径信息的方法是将相邻系统调用之间所有的条件跳转指令的地址进行异或运算,将运算得到的32比特位的结果作为表征执行路径的特征值。然而这种单一的异或运算有可能造成执行路径上的某个条件跳转指令地址丢失,如存在下列条件跳转序列:…cjmp1||cjmp 2||cjmp 3||cjmp 4|| cjmp 1…,cjmp1的地址值经过异或后会被消除,其信息将被隐藏。条件跳转指令信息被隐藏将会造成所获取的路径信息不完整,从而影响防御效果。
为获取完整的程序执行路径信息,本文采用一种有效的方法来拟合程序执行路径上的所有条件跳转信息。本文采用了一种简单的哈希运算,即将32位的地址值等分为n份后(其中n=2i,且0<n≤32),进行移位异或运算,如图1所示。在图1所述的哈希运算方法中,n均取4,这里有四类哈希运算分别是h1、h2、h3和h4,均是通过对地址移位后异或运算,将地址拟合为一个32位的值。其中哈希运算h1,将32位地址空间等分为4份,并以此作为移位的粒度,将等分的地址值移位后异或运算。h2也是采用与h1相同粒度的划分,同样将32位地址空间划分为4份,与h1不同的是,其移位的方向相反。h3则是仅对其前24比特位地址值(即前3份)进行移位后异或运算,而低8比特位的值则直接异或,无需移位。h4是对低16位的值无需移位,直接异或运算,但其高16位的值被划分为2份,进行移位后异或运算。
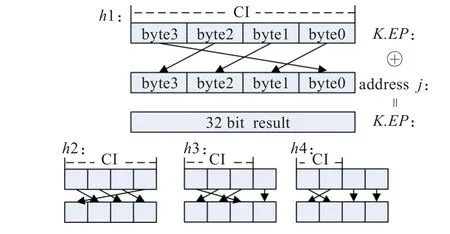
图1 用于拟合路径信息的哈希运算
这种移位后异或运算的实质是将相同的地址值在异或运算前混淆,避免同一地址值在异或运算后被隐藏。在h1运算中,混淆区间(Confusion Interval,CI)为整个32位地址空间,移位粒度被划分为4份后,可混淆的次数N为3次。这里定义混淆区间CI是指参与移位异或运算的地址的位数,混淆次数N是指可连续采用该哈希运算(如h1)的同一地址值的个数,即连续的条件跳转cjmp 1的地址值a1在经历三次哈希运算h1后,所获得的值h1(h1(h1(a1,a1),a1),a1)并没有隐藏其中任意一个a1的地址值信息。而在第4次采用h1运算中,若此时地址值与首地址相同,则有可能会造成异或运算后,该地址与头地址都将被隐藏。综上分析,单个哈希运算的可混淆次数N与当前的哈希运算的混淆区间CI有关,即N=CI-1。
假设前三次哈希运算采用h1,若在第4次运算中采用h2,由于h2和h1的混淆区间范围相同,仅移位方向不同,会造成首地址提前被隐藏,因此不适宜采用h2。若采用h3,尽管混淆区间CI缩小至前3份(即地址值的前24比特位),但由于低8比特位不参与移位,并将直接进行异或运算,此时的a1值至少将保留低8位的值,首地址和末地址a1的值将不会被彻底隐藏。随着混淆区间CI的逐级递减,h3和h4的可混淆次数也在逐级变少,但可以采用层连的多个哈希运算,在路径信息拟合过程中连续采用h1、h3和h4等哈希运算,如计算路径…cjmp1||cjmp 2||cjmp 3||cjmp 4|| cjmp 1||cjmp 2||cjmp 3…的层连哈希运算为h4(h3(h3(h1(h1(h1(a1,a2),a3),a4),a1),a2),a3)。层连的哈希运算将可以有效提高可混淆次数,有效地减少地址被隐藏的概率,降低漏检率,其有效性将在第4章中详细分析。
3.2 延迟检测异常执行路径方法
延迟检测异常执行路径方法是在程序运行时,实时搜集相邻系统调用之间的所有条件跳转指令信息,通过前述的层连哈希运算,拟合程序的执行路径,并在系统调用指令执行前,验证该路径信息是否有效。相应的APLD检测方法的伪代码如下所示:

上述伪代码中K值的格式如图2所示,其中EP表示程序的执行路径,syscall表示当前的系统调用地址值。首先在每条条件跳转指令执行前搜集当前跳转指令地址值,并利用前述的层连哈希运算方法将其拟合成表达程序执行路径的特征值。然后在系统调用指令j执行前,判断该条程序执行路径是否有效,如果当前执行路径无效,则退出;若有效,则将K中值清零,为处理下一条执行路径做准备。
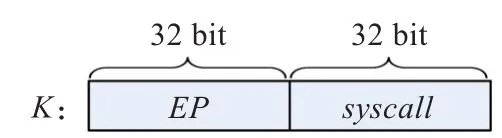
图2 K值的格式
为了创建正常的程序执行路径,以用于实时验证程序中的执行路径是否异常,这里采用类似于入侵检测中基于模型的训练方法获得完备的<EP||syscall>以填充数据EP[],即在安全环境下,以不同的工作负载连续运行目标程序直至所搜集的正常的执行路径数量满足一定的覆盖率,从而获得足够多的实际执行路径信息以填充EP。本文利用这种训练方法在SPEC2000基准程序中运行ref工作负载,采用了不同参数下的层连哈希运算,所得到的程序执行路径的数量如表1所示。
在表1中,n为32位地址值被划分的份数。从表中可以看出,随着n的增加,同一程序中的EP数量也明显增加,如crafty、gap等。分析其原因,是因为随着n的增加,可被层连的哈希运算的个数也在增加,可混淆的次数也在增加,地址被隐藏的概率就会相应减少。因而针对不同的路径,采用不同的层连哈希运算,可以计算得到不同的特征值,而非相同的特征值。随着n的增加,层连的哈希运算更能真实反映不同的程序执行路径。
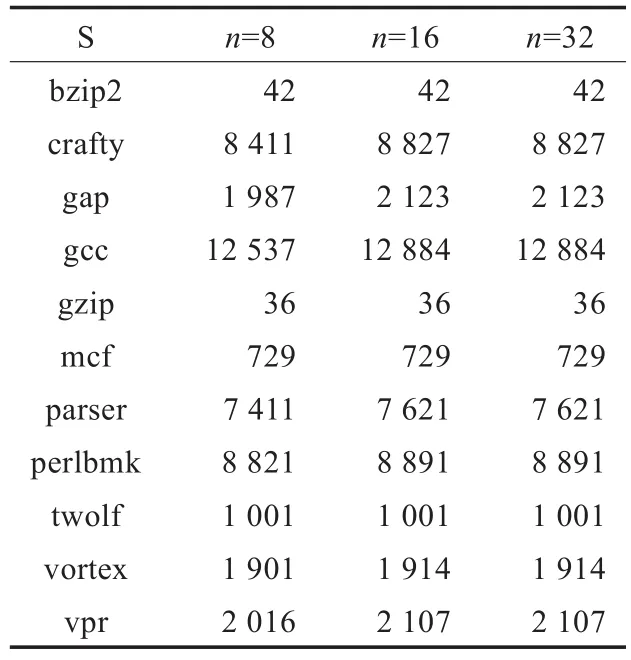
表1 基准程序的EP数量
同时在表1中,部分程序中EP元素的数量明显高于其他程序,如gcc、perlbmk和parser等。分析其原因,EP数量相对较少的程序中所要实现的功能较为简单,如bzip2和gzip均是实现压缩算法。而EP数量较多的程序则其功能较为复杂,如gcc是编译器。因此当采用相同的层连哈希运算时,EP的数量与具体的程序相关。
4 有效性分析及性能评估
4.1 地址被隐藏的概率

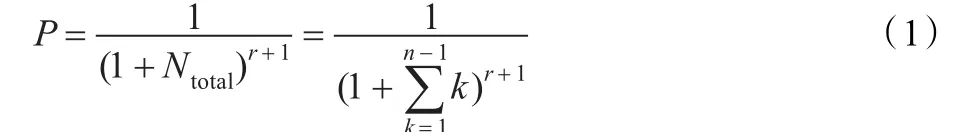
其中n代表32位地址值被等分的个数,n=2i,且0<n≤32。r代表跳转指令的复用距离。复用距离原本是用于度量程序的局部性[17],是指程序运行中连续两次访问同一数据元素之间所访问的不同数据元素的数目。而本文借用其概念,将r用于表示连续两次执行同一条件跳转指令之间所执行的其他条件跳转指令的个数。如在执行路径…cjmp1||cjmp 2||cjmp 3||cjmp 4||cjmp 1…中,条件跳转指令cjmp1的复用距离r为3。若此时假设n=4,可采用的层连的哈希运算个数为3个,如图1中所示的h1、h3和h4,混淆区间CI范围分别从4减到2,各个哈希运算可混淆的次数N分别为3、2和1,因此Ntotal为6次。采用了层连的哈希运算计算上述执行路径时,cjmp1的地址被隐藏的概率为P=1/(1+6)3+1≈4.16E-4。
若执行路径中某一条件跳转仅被执行一次,则其复用距离r为∞,则此时P为∞,即该条件跳转地址不会被隐藏。若在极端情况下,即在一系列连续的相同的条件跳转指令执行时,首条件跳转指令的复用距离r为0,在经过如图1中所述的层连哈希运算后(即采用h1、h3和h4),第7个条件跳转指令的地址值将与第一个地址值被隐藏,因此首条件跳转指令地址被隐藏的概率P为1/7。然而在实际情况下,相同的条件跳转指令连续运行意味着满足该条件跳转的条件一致,使得指令重复执行。由于异常路径检测方法是检测相邻的不同的条件跳转指令之间的相关性,若相邻的跳转指令相同(如在含有一个条件跳转指令的同一循环体内),则决策性数据的攻击并不会造成相邻指令之间的相关性受到影响。因此,即使采用层连哈希方法计算一系列连续的相同条件跳转指令的路径时,出现部分指令地址被隐藏情况,也不会影响最终的检测。
表2为不同参数下通过式(1)所求得的值,其代表程序执行的路径中重复出现的条件跳转指令信息被隐藏的概率。在表2中,n为32位地址值被划分的份数,r为指令的复用距离。如n=8,r=1表示32位地址被划分为8份,且复用距离为1时,指令信息被隐藏的概率为P=0.001 189。从表中可以看出,随着n的增加,条件跳转指令信息被隐藏的概率也随之减少。

表2 不同参数下指令信息被隐藏的概率
4.2 漏检率
由于已经通过训练方法确定程序的正常行为,因此在实现时采用布隆过滤器(Bloom Filter)存储数组EP中的各项元素以降低性能开销和存储开销。
在APLD方法中,检测就是有效识别当前的K值是否存在于EP数组中。在假设EP数组中的元素由全部的执行路径所组成,则APLD的漏检率是采用布隆过滤器Bloom filter存储EP数组中元素时所带来不可避免的后果。如本不属于EP中的元素,在经过Bloom filter中hash查找时却在相关位判定为1,也就意味着APLD方法在实现时对于不属于EP中的异常执行路径判定为有效。因此Bloom filter中的误检率FPR等同于APLD方法中的漏检率FNR。FNR= (1-(1-1/m)kt)k≈(1-e-kt/m)k,其中k为相互独立hash函数个数,t为组成EP数组中所有元素个数,m为位数组的大小。根据表1中的数据,可以得到APLD方法的漏检率如表3所示。
在表3中,n为32位地址值被划分的份数,其EP数组中元素个数对应表1。分析APLD的漏检率,随着EP数量的增多,其漏检率也随之增加。部分程序的EP数量较多,如crafty、perlbmk、parser和gcc等,因此其漏检率较高。而bzip2、gzip和vortex的EP数量较少,因此漏检率较低。
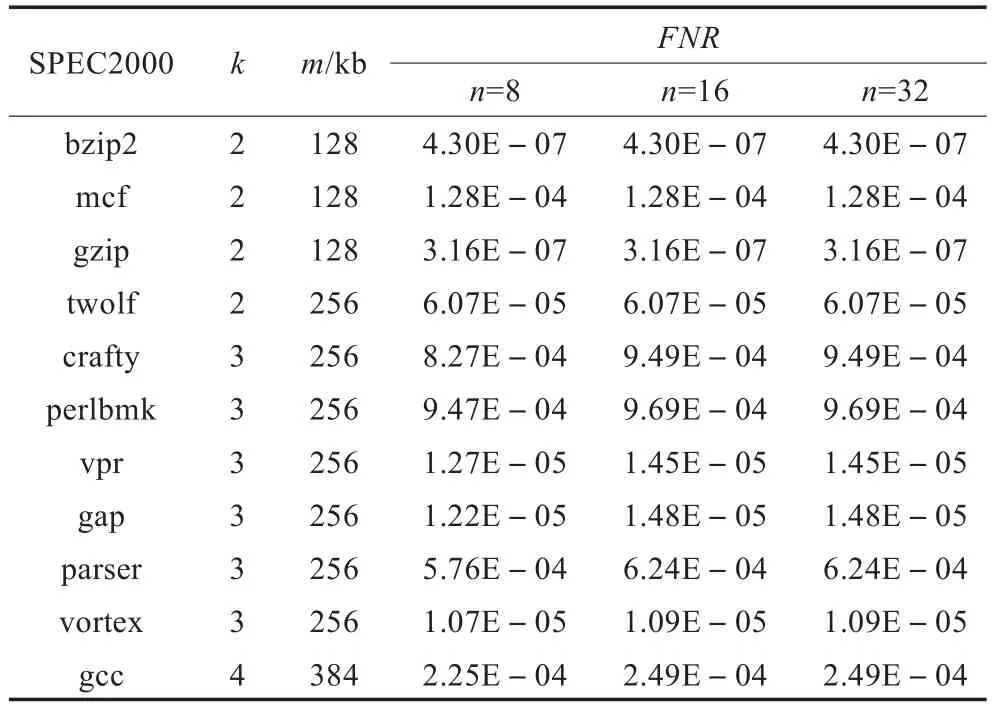
表3 APLD方法的漏检率
4.3 性能评估
由于部分条件跳转属于间接跳转,只有在程序运行时才能动态地获取这部分条件跳转的指令信息。因此为评估APLD方法的性能,本文采用插桩技术,在二进制代码动态翻译工具Pin[18]平台上实现该方法。实验环境建立在Dell微机(3 GHz core2 CPU、2 GB内存)上的,运行Red Hat 7.0企业版的操作系统,编译器选用GCC 4.2.1,并且采用Pin 2.12-53271。
由于基准程序gzip和bzip2中EP数量较少,因此在实现时不采用布隆过滤器存储EP,其他基准程序采用布隆所述,实验所获得的APLD性能开销如图3所示。

图3 APLD性能开销示意图
在图3中,在Pin上直接运行基准程序时的性能开销范围为mcf的1.1倍到gcc的3.3倍。当APLD方法采用的划分份数n为8时,可被用于层连的哈希运算个数为7,而此时的性能开销范围为gzip的2.03倍到gcc的5.76倍。采用的划分份数n为16时,可被用于层连的哈希运算个数为15,此时的性能开销范围为gzip的2.11倍到gcc的5.97倍。采用的划分份数n为32时,可被用于层连的哈希运算个数为31,此时的性能开销范围为gzip的2.29倍到gcc的6.01倍。
从APLD的性能开销可知,随着划分份数n的增加,APLD的性能开销并没有发生明显变化。分析其原因,是因为份数n的增加,只是带来了更多的细粒度的哈希运算。而细粒度的哈希运算均为移位后异或运算,只是可混淆的区间发生变化,并没有增加指令的数量,对性能开销并没有明显的影响。因此在不同的n下APLD的性能开销并没有显著的变化。
5 总结
作为一种主要的非控制流数据攻击的类型,决策性数据攻击能绕开以控制流相关数据作为保护对象的防御方法。现有的针对这类攻击的防御方法在前提假设上有过多限制,如需要源码,同时在有效性及性能上存在缺陷。由于决策性数据攻击破坏了相邻条件跳转语句之间的相关性,改变了程序原有的执行路径,因此本文提出了一种延迟检测异常执行路径的方法,用以防御决策性数据的攻击。该检测方法以相邻两个系统调用之间的所有条件跳转作为执行路径,同时本文提出了一种层连的哈希运算以获取正确的执行路径信息,并在系统调用执行前检测执行路径信息是否有效,以此来检测异常的执行路径,防御决策性数据的攻击。有效性分析和性能评估表明,层连的哈希运算可在极高的概率下,获得正确的且易于保存的程序执行路径信息。并且在此基础上实现的延迟检测异常路径方法能有效防御决策性数据攻击,且其漏检率低,性能开销适中。
[1]Chen S,Xu J,Sezer E C,et al.Non-control-data attacks are realistic threats[C]//Proceedings of the 14th USENIX Security Symposium,Baltimore,MD,2005:177-192.
[2]Cowan C,Pu C,Maier D,et al.StackGuard:automatic adaptive detection and prevention of buffer-overflow attacks[C]// Proceedings of the 7th conference on USENIX Security Symposium,San Antonio,1998:63-78.
[3]Etoh H.ProPolice:GCC extension for protecting applications fromstack-smashingattacks[EB/OL].[2013-06-15].http://www. trl.ibm.com/projects/security/ssp/.
[4]Chiueh Tzi-cker,Hsu Fu-Hau.RAD:a compile-time solution to buffer overflow attacks[C]//Proceedings of the 21st International Conference on Distributed Computing Systems,Phoenix,2001:409-420.
[5]Shi Y,Lee G.Augmenting branch predictor to secure program execution[C]//Proceedings of 37th Annual IEEE/IFIP International Conference on Dependable Systems and Networks,2007:10-19.
[6]The PaX Team.PaX Address Space Layout Randomization(ASLR)[EB/OL].[2013-06-15].http://pax.grsecurity.net/docs/ aslr.txt.
[7]Xu J,Kalbarczyk Z,Iyer R.Transparent runtime randomization for security[C]//Proceedings of 22nd International Symposium on Reliable Distributed Systems,Florence,2003:260-269.
[8]Bhatkar S,Sekar R,DuVarney D C.Efficient techniques for comprehensive protection from memory error exploits[C]//Proceedings of the 14th USENIX Security Symposium,Baltimore,MD,2005:105-120.
[9]Shioji E,Kawakoya Y,Iwamura M,et al.Code shredding:byte-granular randomization of program layout for detecting code-reuse attacks[C]//Proceedings of the 28th Annual Computer Security Applications Conference,2012:309-318.
[10]Wartell R,Mohan V,Hamlen K W,et al.Binary stirring:selfrandomizing instruction addresses of legacy x86 binary code[C]//Proceedings of the ACM Conference on Computer and Communications Security.New York:ACM Press,2012:157-168.
[11]Shacham H,Page M,Pfaff B,et al.On the effectiveness of address-space randomization[C]//Proceedings of ACM Conference on Computer and Communications Security(CCS),2004:298-307.
[12]Roglia G,Martignoni L,Paleari R,et al.Surgically returning to randomized lib(c)[C]//Proceedings of Annual Computer Security Applications Conference,2009:60-69.
[13]Castro M,Costa M,Harris T.Securing software by enforcing data-flow integrity[C]//Proceedings of the 7th Symposium on Operating Systems Design and Implementation(OSDI’06),2006:147-160.
[14]Chaudihuri A,Naldurg P,Rajamani S.A type system for dataflow integrity on windows vista[J].ACM SIGPLAN Notices,2008,43(12):9-20.
[15]Akritidis P,Cadar C,Raiciu C,et al.Preventing memory error exploits with wit[C]//Proceedings of IEEE Symposium on Security and Privacy,2008:263-277.
[16]Santos J C M,Fei Y.Leveraging apeculative architectures for run-time program validation[C]//Proceedings of IEEE International Conference on Computer Design,2008:498-505.
[17]Beyls K,D’Hollander E.Reuse distance as a metric for cache behavior[C]//Proceedings of the Conference on Parallel and Distributed Computing and Systems,2001:350-360.
[18]Chi-Keung Luk,Cohn R,Muth R,et al.Pin:building customized program analysis tools with dynamic instrumentation[C]//Proceedings of Programming Language Design and Implementation,Chicago,IL,2005:190-200.
WANG Ying,ZHANG Lantu
Lingjiu Hi-Tech Co.,LTD,China Shipbuilding Industry Corporation(Wuhan),Wuhan 430074,China
As a major type of non-control data attacks,decision-making data attacks can easily bypass any prevention method targeting control data attacks.A novel method named as Anomalous Path Lazily Detection(APLD)is proposed due to the weakness of the existing prevention methods targeting decision-making data attacks.To effectively prevent the same conditional branch information belonging to the same path from being hidden,a cascading hash is introduced to compute correct program execution path information.Since the execution path information is only validated before executing the system call instruction, the performance overhead is reduced benefited from the reduction of frequency of validation.Theoretical analysis and experimental results show that APLD can effectively defend decision-making data attacks and has achieved significant safety with a modest performance penalty.
decision-making data attacks;execution path integrity;cascading hash;Anomalous Path Lazily Detection(APLD); false negative rate
作为一种主要的非控制流数据攻击的类型,决策性数据攻击能绕开以控制流相关数据作为保护对象的防御方法。在分析现有的防御决策性数据攻击方法的优缺点基础上,提出了一种延迟的异常路径检测方法。为有效避免相同的条件跳转信息被隐藏,引入了层连的哈希运算以获取正确的程序执行路径信息。在系统调用执行前检测该路径信息的有效性,能有效降低检测频率,从而降低性能开销。理论分析和实验结果表明,该防御方法能有效防御决策性数据攻击,且其漏检率低,性能开销适中。
决策性数据攻击;执行路径一致性;层连的哈希运算;异常路径延迟检测;漏检率
A
TP393.08
10.3778/j.issn.1002-8331.1309-0132
WANG Ying,ZHANG Lantu.Non-control data attacks prevention through Anomalous Path Lazily Detection.Computer Engineering and Applications,2013,49(24):100-104.
王瑛(1960—),女,工程师,主要研究领域:信息安全,入侵检测;张蓝图,男,工程师,主要研究领域:信息安全,漏洞检测与防御,网络可靠性。E-mail:lantuzhang@163.com
2013-09-10
2013-10-23
1002-8331(2013)24-0100-05
◎数据库、数据挖掘、机器学习◎
猜你喜欢
数字技术与应用(2021年5期)2021-06-29
电子科技(2021年2期)2021-01-08
计算机工程与设计(2020年11期)2020-11-17
测控技术(2018年5期)2018-12-09
电子测试(2018年18期)2018-11-14
电信科学(2016年10期)2016-11-23
工业设计(2016年8期)2016-04-16
计算机工程(2015年8期)2015-07-03
电子设计工程(2015年6期)2015-02-27
计算机工程(2014年6期)2014-02-28
