
特征选择的和声模糊聚类研究与应用
2013-07-19 08:43:58王华秋罗江MichaelGERNDTVentsislavPETKOV
计算机工程与应用 2013年19期
王华秋,罗江,Michael GERNDT,Ventsislav PETKOV
1.重庆理工大学计算机学院,重庆 400054
2.慕尼黑工业大学信息系I10研究所,德国慕尼黑D- 85748
特征选择的和声模糊聚类研究与应用
王华秋1,罗江1,Michael GERNDT2,Ventsislav PETKOV2
1.重庆理工大学计算机学院,重庆 400054
2.慕尼黑工业大学信息系I10研究所,德国慕尼黑D- 85748
1 引言
用于高性能计算机的性能分析工具可以帮助使用者写出高效的代码。这些工具能够提供程序性能评测值,并能发现一些瓶颈。瓶颈是指在程序执行时,运行时间由于无效资源的占用而浪费掉了。只要识别出瓶颈,开发者就可以修改程序以提高运行效率。正如现如今有许多并行计算硬件和并行编程语言一样,性能分析工具也是层出不穷,其中有代表性的是如下几种:Paradyn、TAU、Periscope、Vampir、KOJAK、SCALASCA、mpiP。
聚类机制为这些工具提供了一种基本的多变量统计分析的方法,所有处理器的Performance和Region这两个属性对应的Severity值被提取出来,组成一个由处理器个数为行,Severity为列的高维矩阵。使用聚类算法对这些处理器进行分类,以检测每一类处理器在不同代码区域出现性能瓶颈的概率分布,以便对每一类处理器进行合理的资源调度。用于GENE代码分析的处理器有1 024个,这些处理器产生的性能瓶颈维度有39列之多,这样会产生1 024×39的矩阵。为了评价这些处理器的性能,对这样的性能矩阵进行划分,使其产生少数具有相似性能的处理器集合将是非常有意义的,聚类后的处理器将有利于发现隐藏在巨大数据集后的并行系统整体运行趋势。
在诸多划分、层次、密度、网格等聚类算法中,FCM聚类是最常用划分聚类算法,它采用梯度下降的方法寻找最优解,本质上是一种局部搜索技术。对初值敏感及容易陷入局部极小的缺陷,使得该方法只适用于对均匀分布的团状数据集聚类,对分布复杂的故障数据无法正确处理,而且FCM对所有特征采用相同权重,这样处理并不合理,由于未对特征加权,就无法突出某些属性特征对聚类的主导影响,使聚类效果受到了次要属性特征的干扰,而这种缺陷在高维数据中尤为明显。因此,这也成为了许多启发式搜索算法首选的优化目标,这些启发式搜索算法已广泛地用于聚类中心的发现中,并能在问题域内找到所有可能解,如果算法运用得当就能避免陷入局部最优解。例如,克隆选择[1]、蚁群优化[2]和粒子群优化[3]。和声算法是Geem提出的一种由音乐灵感激发的优化算法[4],受到广泛关注。和声搜索算法已经用于许多工程和科学领域,比如:图像分割[5]、Web文本聚类[6]、水处理[7]。本文使用和声搜索算法实现了快速准确的聚类,无论数据分布、形状、大小如何,性能好的搜索划分算法都可以对其聚类。
通过对和声搜索算法的研究,发现调音概率par和调音量bw都是凭经验或随机设定的,而且在算法收敛过程中没有变化。事实上,这两个参数对算法收敛性能的影响比较大,特别是在运行的后期,原始的和声搜索算法没有对其加以关注,不利于算法快速收敛到全局最优。因此,本文对和声搜索算法进行改进之处就在于动态调整调音概率par和调音量bw,保证和声算法快速收敛到全局最优,有效地避免陷入局部极小。
众所周知,每个都数据包含一定数量的维度(或者称为属性),聚类算法就是将这些多维数据进行划分,在划分之前并不知道需要划分成为几部分,只是将每一类内部变量尽量聚集在一起,而类与类之间的距离尽量远离,两点之间的差异用相似度或者距离计算。聚类的这种不确定性正是在于聚类学习是无监督的过程。
基本的划分算法认为所有的维对于聚类同等重要,但事实上,一些维存在冗余、无关,甚至容易产生误导的异常点。因此特征选择技术出现了,这是一种用于高维数据聚类的最佳特征子集选择技术[8]。
特征选择不仅提高了聚类的性能,而且简化了聚类模型。特征选择一般是在聚类之前完成的过程,但是也有一些算法将其集成于聚类算法中,即在聚类的同时进行特征选择。文献[8]和[9]就是将特征选择和EM聚类结合在一起,在其影响下,文献[10]提出了一种利用和声搜索算法的聚类和特征选择同步进行的方法。该方法将特征选择作为和声搜索聚类过程的一部分,每次搜索的目标不仅包括聚类中心,还包括被选择出来的属性(维),而且为了获得最佳的聚类中心数量,每次搜索需要不断改变聚类的中心数量。这种集成模式的搜索采用的评价函数则是聚类误差和属性(维)相对中心的偏差两部分之和。这些改进的确提高了划分聚类的性能,但是同时带来了一些问题:
(1)算法复杂度较高,随机的聚类中心和随机的特征属性的组合将是非常庞大的,这对于高维度大数据而言,其算法复杂度是可想而知的。
(2)性能评价函数不太合理,将聚类误差和属性偏差结合在一起不利于评价总误差究竟是由于聚类中心数量不适当而带来的误差,还是由于属性特征选择不合理而带来的偏差,从而造成每次迭代无法正确调整三个目标值:聚类中心数、聚类中心、属性维度。这将对算法的准确度产生不可忽视的影响。
以上的做法是对高维数据的属性(特征)进行选择,没有被选上的属性将被忽略或删除,进一步,有研究人员提出属性加权的思想对特征选择进行泛化,即为每一维设置一个0到1之间的权值,而不是直接保留或删除某些属性(维)。换句话说,如果某一属性的特征比较明显,那么它的权值就较高,从而对聚类结果的影响就较大;反之,特征不显著,则权值较小,而影响较小。这样看来,特征选择就是为每一维设置合理的权值。近年来,许多研究人员致力于研究这种特征加权的方法以提高聚类质量。Huang[11]提出了一种用于K-means的特征属性自动加权的机制,其利用迭代公式不断修正权值,而K-means算法的有效性并没有被影响。然而,该方法需要使用者主观指定一些参数值,而且其获得的权值无法显著区分属性是否具有代表性和不相关性。文献[12]提出了用优化的方法对属性进行加权,首先测量不同特征属性的分散度,然后构造了凸K-means算法以决定最优权值,同时保证簇内部平均分散度最小以及簇之间的平均分散度最大。而在实践中,对于所有属性进行加权并不适合高维数据聚类。Friedman[13]提出了COSA方法用于对子属性进行层次聚类,对于不同的簇类,COSA聚类方法构造了一个非凸优化目标函数为D×N个属性分配各自的权值,但是求解这个优化函数需要面临巨大的算法复杂度。Mohamed[14]在MRI图像分割的应用中,在传统的FCM算法的基础上改进了聚类目标函数,以弥补图像像素强度的不均匀性。
根据以往研究的经验,结合需要解决的问题,提出了一种采用改进的和声搜索模糊聚类的MHS-FCM算法。本文算法克服了文献[10]算法的那两点问题,而且采用一种基于统计学的特征属性加权的方法区别各个维在聚类中的不同作用,而不是忽略某些属性维,采用评价函数对不同的聚类中心个数进行评价,从而保证算法收敛时能够得到最佳聚类中心。
2 算法思路
按照前文的论述,要解决的问题有三点:(1)特征属性的加权,即数据维加权;(2)采用改进的和声搜索算法进行数据聚类;(3)选择最优的聚类中心数。因此把算法分为三步完成:
步骤1在聚类之前先进行特征属性的加权。任何一维的数据如果过于集中,数据之间失去了区别,就不利于聚类了,这样的维所代表的属性就应该具有较小的权值;反之,如果这一维数据比较散乱,数据之间便于区分,那么这一维对聚类结果影响较大,应该分配较大的权值。本文就是按照这样的思路对每一维属性进行加权。
步骤2利用和声搜索算法计算聚类中心。聚类评价函数值作为和声算法的适应度,并采用一种新的调音概率公式改进和声算法,不断调整和声库直到算法收敛,直至聚类评价函数值的改变量小于要求或者达到迭代次数。
步骤3选择最优的聚类中心数。不断改变聚类中心数,利用步骤2计算其聚类中心和评价函数值,选择评价函数值最小对应的聚类中心作为最后的输出。
3 基于维度加权的特征选择
现已知样本:

λki代表了一个是否和其他数据没有显著性区别的分界值。
规则1如果Rki>λki,那么该维的第j个数据就和其他数据没有显著区别,因此第i维数据的Samenessi就增加一个计数。
这样就是可以对每一维进行特征选择了,根据算法思路,本文采用如下方式对每一维属性进行加权。

其中,i=1,2,…,d,这样wi就代表了第i维对于聚类的权值;Samenessi是第i维数据的趋于一致的数据的数量,TotalNumber是第i维数据的总数量;Deferencei代表了每一维的具有显著差异的数据点个数,用Deferencei除以每一维数据的总数量则可以将每一维的数据差异性归一化,使得所有维之间的权值具有可比性。
4 和声搜索模糊聚类算法
和K-means、K-mediods、FCM等算法一样,和声搜索聚类算法同样离不开聚类中心反复“迭代”,只不过这时的“迭代”演变成了“演奏”。
4.1 初始化和设置参数

(2)和声搜索算法也有一些参数需要确定:和声存储库的行数(HMS=20),和声存储库的列数(COL=k×d),和声存储库的选择概率(HMCR=0.9),调音概率(par=0.25),随机带宽(bw=0.2),音演奏次数(即迭代次数ITERATION=100)或者停止条件(适应度变化量小于一个小数DELTA<0.01)。
(1)数据归一化:由于各维数据代表的意义不同,造成量纲不统一,这样不利于计算彼此的距离。由于在属性加权时已经对每一维的数据计算了标准差和平均值了,这里就采用Z-Score归一化方法,由下式计算:
4.2 初始化和声存储库
在这一步中,和声存储库HM矩阵最初由有上界Uxj∈d和下界Lxj∈d限制的随机数组成:
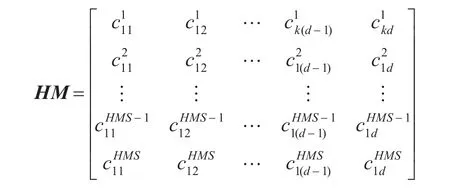
调用聚类质量评价函数计算各行和音的适应度,得到适应度列向量F=[f1,f2,…,fHMS]T,记录其中最佳和最差的适应度及其对应的和声变量。
和声存储库的作用就是在每次迭代时,由此库产生出新的和声变量,并根据这新变量不断更新和声存储库,使之收敛到全局最优解。
4.3 演奏新的和音
在第一种方法中,第一个类中心的第一维变量c′11将从和音存储库的第一列向量中随机选择,以此类推可以得到其他中心的各维变量c′ij。
HMCR的变化范围是0到1,一般为0.6~0.9之间。本文为0.9,这是决定是否从和音存储库HM中选择性的变量的概率,换句话说,(1-HMCR)就是决定是否从上下限范围内随机产生新的变量的概率。选择操作如下:

对于每一个从和声存储库中得到的变量还要决定是否调音,par就是初始调音的概率,一般为0.1~0.4之间。本文为0.25,概率(1-par)就是不需要调音的概率。调音操作如下:

所谓调音,就是在原来的变量的基础上增加或减少一个随机带宽量bw。

上述三种方法产生的新的和音将被返回,并用于更新和音存储库。
4.4 改进的调音策略
调音是避免和声算法出现“早熟”的重要措施,在最初的和声算法中,并没有对调音概率par和随机带宽bw做调整,因此需要很多次迭代才能调出一个不同于其他的和声。当库中的和声趋同时,以一个远大于通常的调音概率par′执行一次操作,同时增加随机带宽量bw,这样就能够随机产生新的音符,从而使整个和音库摆脱“早熟”。
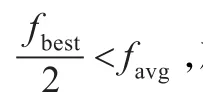
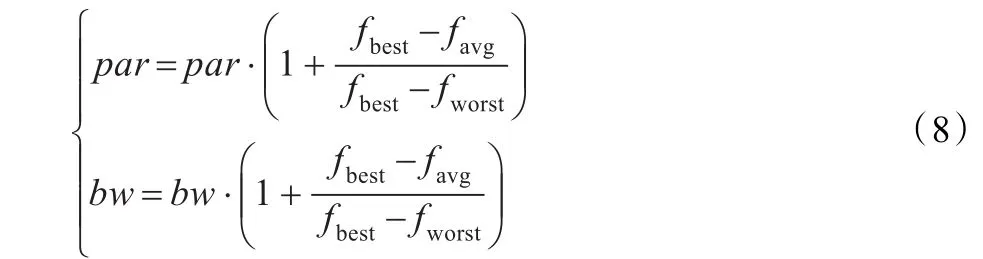
这样的改进可以增加算法的随机搜索的几率,提高算法的全局收敛性,但是考虑到收敛时间会延长,因此par和bw的增加系数均不太大。
4.5 更新和音存储库

其中,参数m∈[1,+∞)是每一个模糊中心的加权指数,它决定着样本在模糊类之间的隶属程度。
再由隶属矩阵产生新的聚类中心:
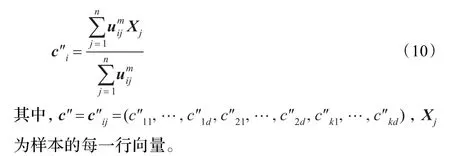
4.6 聚类性能评价
需要定义聚类质量评价函数,这个评价应该体现聚类的原则:簇内样本尽量靠近该簇中心,簇和另一个簇尽量远离。因此,把尽量小的簇内距离除以尽量大的簇间距离作为评价函数(也称为适应度):
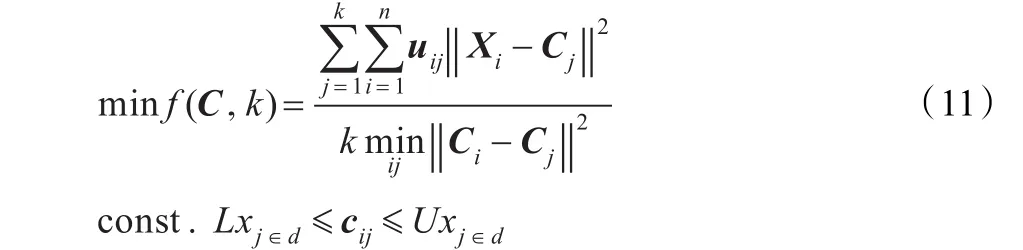
其中,C是聚类中心的集合,k是聚类中心的个数,Ci和Cj分是第i个和第j个聚类中心,Xi为样本的每一行向量,n是样本数量,样本以模糊隶属度uij归属于某些类。这样聚类的目标就是通过和声搜索到使得f(C,k)达到最小的C和k,C用向量的方式存储,C=(C1,C2,…,Ck)=(c11,…,c1d,…,ck1,…,ckd),例如:第一个聚类中心就是c11,c12,…,c1d,第k个聚类中心就是ck1,ck2,…,ckd。
用新的聚类中心调用聚类质量评价函数计算其f′,如果新的和音向量在适应度上优于和音存储库中的最差的向量,那么和音存储库就需要更新了,新的和音向量将取代那个最差的向量。如果这个新的向量同时也是和音存储库中最优的,那么保存这个新向量的适应度为和音存储库的最佳适应度,这时的最佳适应度对应的变量就是最终聚集成为k个中心时的聚类结果。
4.7 检查终止条件
如果满足终止条件,结束聚类中心的搜索;否则,转到4.3节。终止条件是:(1)迭代次数达到最大值;(2)评价函数值(适应度)的变化量小于限定值。
5 算法复杂度
为了分析整个算法的复杂性,给出算法的流程,如图1。
把整个算法分为了若干段,每一段完成一定的功能,也消耗一定的时间,外部循环让这些程序段反复迭代直至收敛。从内部开始分析,和声搜索聚类中心需要的时间为:R(初始化)+k(中心数)×d(维度)×S(式(4)的演奏+式(5)和(6)的调音)+F(式(3)的适应度计算n×k)+U(更新和声库)+P(式(7)和(8)的大概率调音),由于有了寻找最佳聚类中心数的过程,该算法重复了n/2-1次和声搜索聚类,另外还有公式(1)的维度加权和公式(2)数据归一化,因此对于整个聚类而言,整个算法复杂度为O(W+(n/2-1)× (R+k×d×S+n×k+U+P))。除了适应度公式之外,和声搜索的这些公式都不太复杂,计算速度可以得到保证。
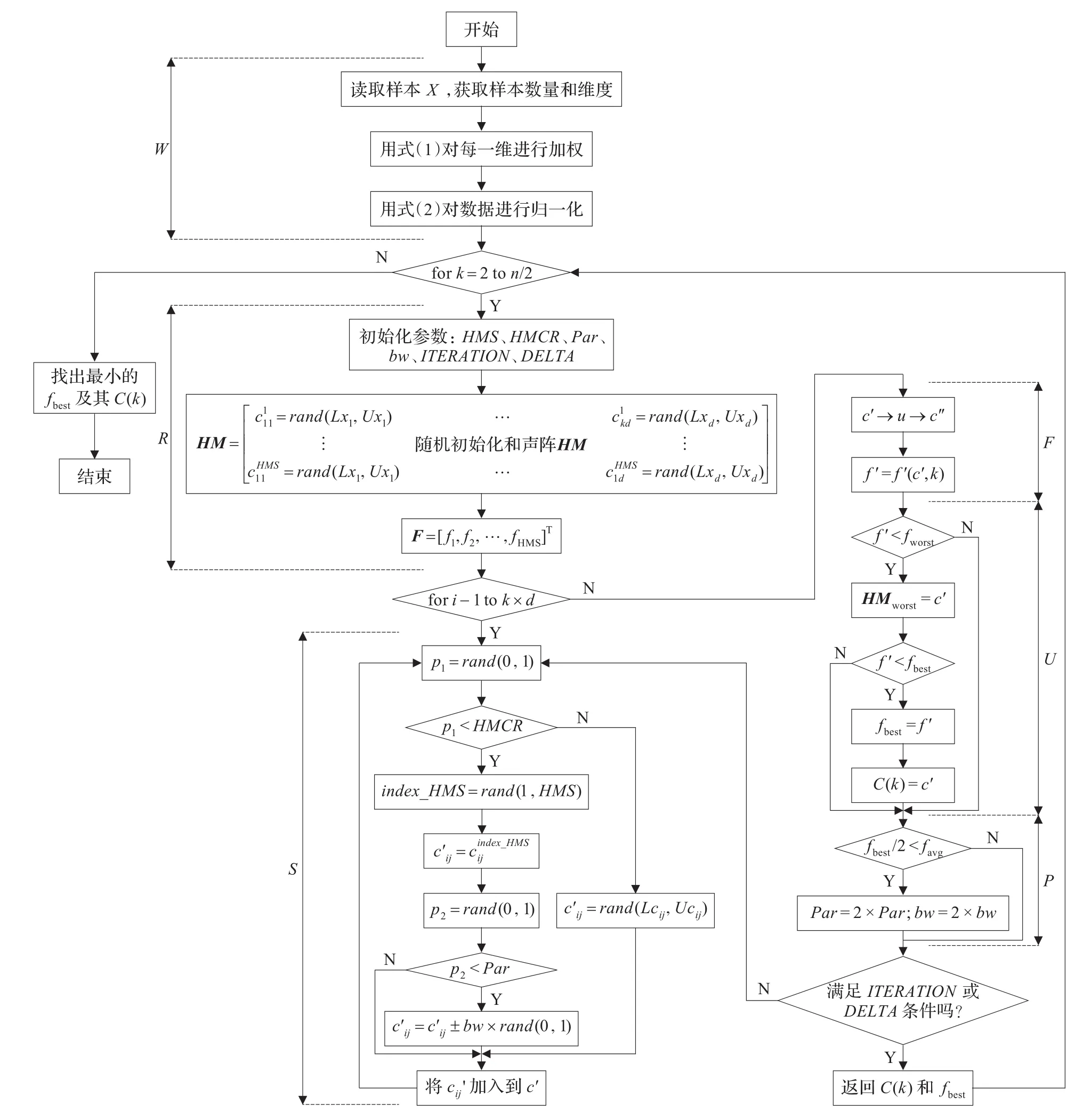
图1 算法流程图
6 算法收敛性
定理1 HSFC会收敛于全局最优。
证明当新解的适应度优于和声库中最差解的适应度时,和声库状态发生转换。下列三种概率影响了新解的产生:选择和声库的概率pMemory=HMCR×(1-par),调音的概率pPitch=HMCR×par,以及随机选择概率pRandom= (1-HMCR)。
因此,定义一个转移矩阵P来记录和声库中新解的概率变化值。设有一个随机状态转移矩阵P=MC·PA·RC,其中MC是pMemory的中间转换矩阵,PA是pPitch的中间转换矩阵,RC是pRandom的中间转换矩阵。
启发式算法在迭代过程中始终保持了最优解,确保可以收敛于全局最优,因此转移矩阵P是稳定的。从和声搜索算法的定义中可知,每次迭代中和声库都会更新最优解,因此矩阵P转移到任何全局最优状态的概率也会收敛到1,定理得证。
7 并行性能分析
为了分析和识别大规模科学计算中各处理器性能瓶颈。这里用回旋电磁数值实验代码(Gyrokinetic Electromagnetic Numerical Experiment,GENE)进行并行计算,GENE代码通过迭代求解具有五维相空间的非线性回旋方程,用于识别电磁等离子聚变产生的涡流特征。GENE可以运行在拥有大量处理器的超级计算机上,代码用MPI并行化的Fortran95实现。数据采集实验在ALTIX超级计算机上进行,GENE代码其中的1 024核中运行。通过测试可以收集GENE的不同代码区域的各种MPI属性值和可伸缩性,比如:节点性能、负载能力、信息组织方式等等。
首先将这些数据进行分析,对于处理器由其编号Process唯一确定,由于ID唯一表示了该CPU出现性能瓶颈的名称,而RegionID则唯一标示了GENE代码中出现性能瓶颈的区域位置,ID和RegionID的结合就可以确定GENE的哪一部分代码运行时出现了什么样的性能问题,而严重程度就是Severity。因此上述XML文件中,需要提取出来进行用于聚类的属性为:Process,ID,RegionID,Severity。对这些属性进行构造,就是由给定的属性构造和添加新的属性,以有利于聚类。比如,根据属性ID和RegionID可以构造Performance属性。通过这种组合属性,属性构造可以发现关于数据属性间联系的丢失信息,这对知识发现是有用的。于是构建了如表1的1 024行39列的数据矩阵Processor_ Performance。
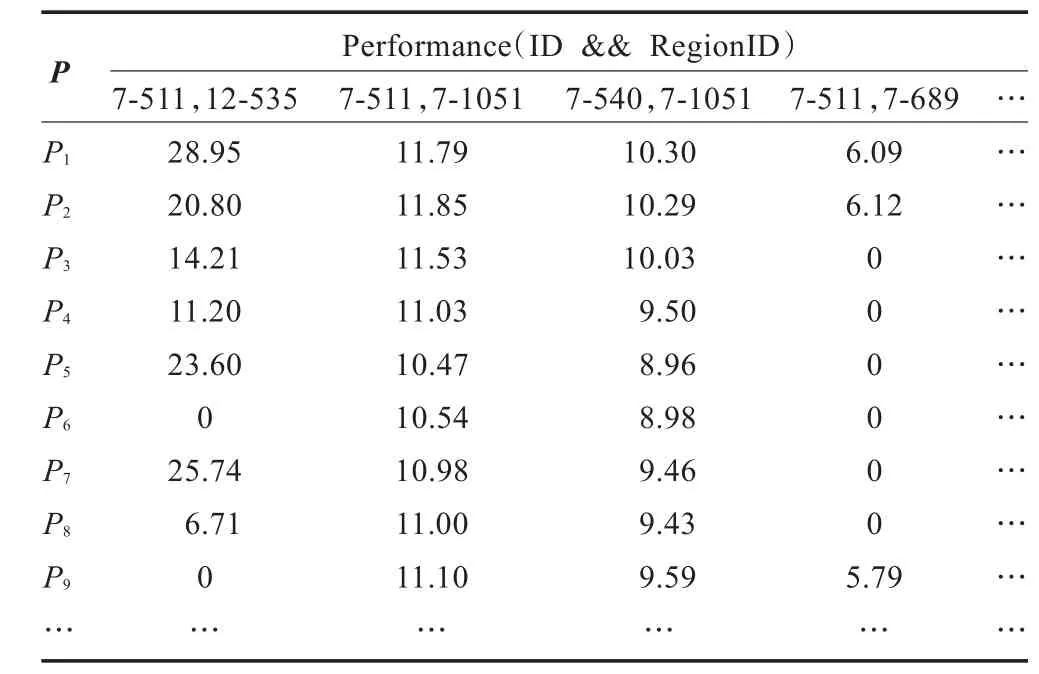
表1 性能分析数据
利用这些数据对这1 024个处理器进行聚类分析,把本文的HSFC和FCM、PSO聚类、文献[6]和文献[10]算法进行比较,其中PSO和FCM聚类时根据相关文献的经验指定分类数和参数。将瓶颈性能近似的处理器归为同一类,聚类的结果就是这1 024个处理器被自动分为8类(如表2)。
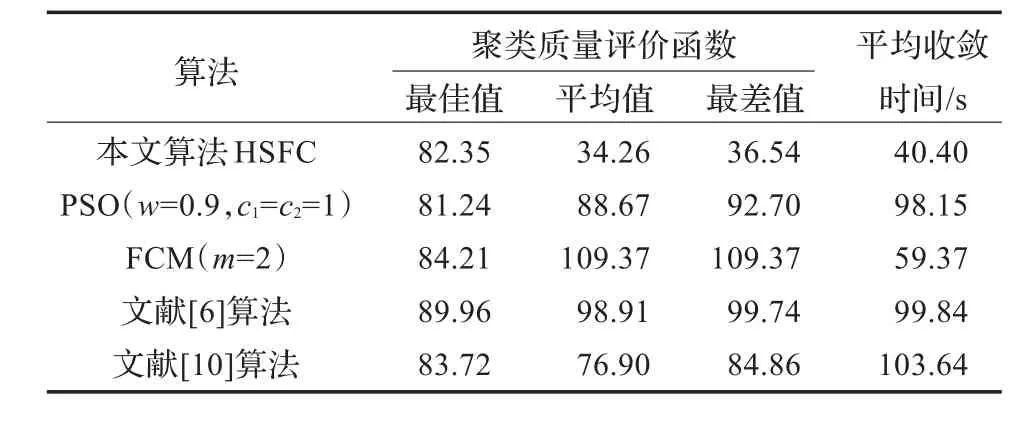
表2 并行性能聚类结果
从上面的比较可以看出,本文这种算法聚类质量比较高,而且耗时较少。虽然FCM算法速度也比较快,但是误差较大。因此采用本文的算法进行并行处理器性能聚类。
图2中的横坐标是处理器的编号,纵坐标是类别。根据这样的聚类,可以重新分配GENG的代码区域到处理器上,取得更好的计算性能。
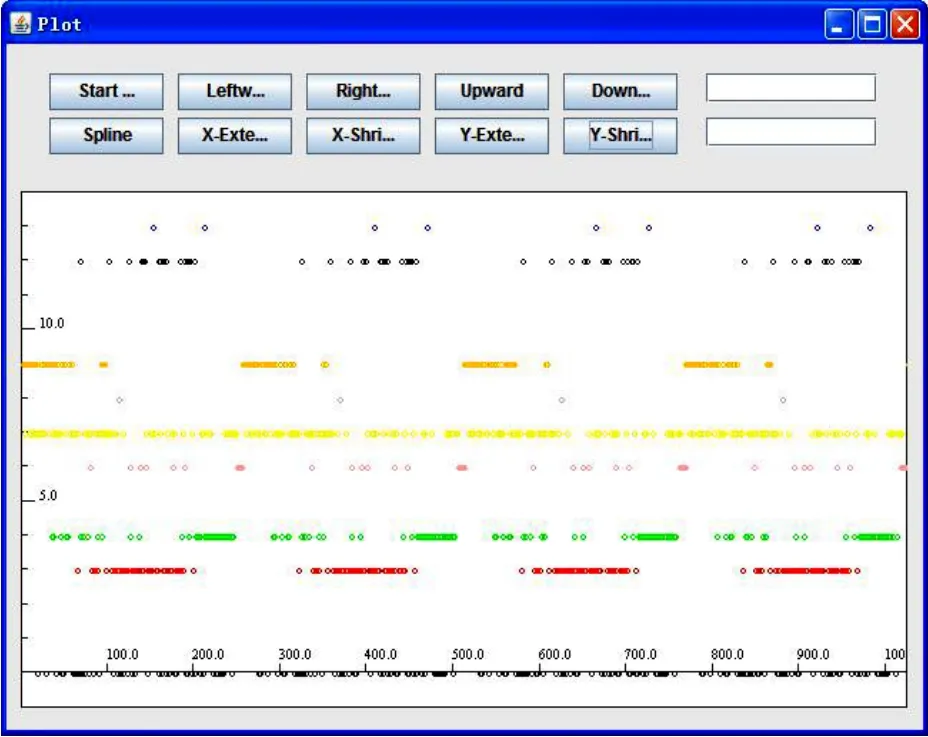
图2 处理器聚类结果
例如:p1,p20,p140,p230,p663,p915,…,被归为一类C1。
定义4Ci_Processor={Processorj},其中j是属于Ci类的处理器下标。
并行性能分析就是对于每一个处理器聚类组,找出对其具有较高严重程度Severity值的性能瓶颈集合。某处理器组的性能瓶颈集的计算需要借助Processor_Performance矩阵。根据数理统计中值理论,在该矩阵中某性能瓶颈Performancej在某处理器组Ci的Severity权值由下面公式计算。
定义5
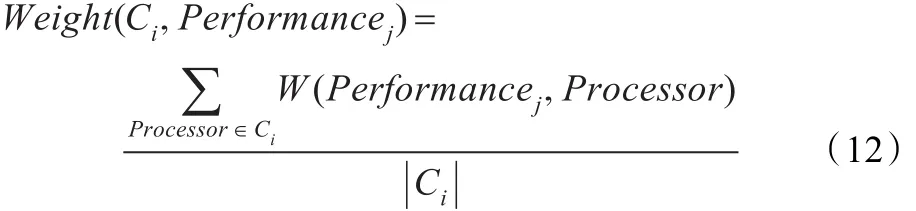
其中,表示某处理器组Ci中处理器的个数;W(Performancej,Processor)表示Processor在Performancej性能上的严重程度Severity。由此,可以计算出每个性能瓶颈对于每个处理器组的权值。显然,对每一处理器组而言,那些与之具有较高权值的性能瓶颈就构成了针对它的并行性能分析结果集。对于前面所述回旋电磁数值实验的Processor_ Performance矩阵及其ProcessorCluster聚类阵,利用权值计算公式,计算其权值矩阵ProcessorCluster-PerformanceWeight,结果如表3。

表3 并行性能加权聚类结果
设Severity权值的阀值S=5.00,则处理器组C1的性能分析结果集为{(7-511,7-689),(7-511,7-1051)},C2的性能分析结果集为{(7-511,12-535),(7-511,7-689)},C3的性能分析结果集为{(7-511,12-535)},…
举例解释一下C1性能分析结果,按照Severity权值排序,这一类主要的瓶颈问题如下。
(1)Severity权值8.50:CALL_REGION程序段(7-511)出现了Excessive MPI communication time性能问题(7-689);
(2)Severity权值6.00:CALL_REGION程序段(7-511)出现了Excessive MPI time in receive due to late sender性能问题(7-1051)。
定义6Ci_PerformanceWeight={Performancej},其中j是Ci类包含的所有性能瓶颈下标。
在并行程序运行时,首先需要根据处理器信息找出其所属的性能瓶颈组,然后参照该组的性能分析结果集。掌握了这些同一类处理器的性能瓶颈特征,程序管理员或开发者就可以预先知道某处理器可能会出现的性能瓶颈,从而及时重新分配任务或调度处理器,将可能出现的性能瓶颈防患于未然。
规则2IfProcessorj∈CithenProcessorj具有Performancej性能瓶颈。
比如:已知p1,p20,p140,p230,p663,p915,…被归为一类C1,处理器p1可能仅仅在CALL_REGION程序段(7-511)出现了Excessive MPI communication time性能问题(7-689)。但是由于C1类的处理器普遍会出现{(7-511,7-689),(7-511,7-1051)}这两类瓶颈问题,因此,可以推断处理器p1也会在CALL_REGION程序段(7-511)出现了Excessive MPI time in receive due to late sender性能问题(7-1051),程序员可以提前做出调整,以减少这种瓶颈带来的不利影响。
8 结束语
将随机启发式搜索算法之一的和声搜索算法运用于聚类中,仅仅保留了聚类的评价函数,改变了聚类的方式,从而提高了聚类的质量,本文尝试对其进行一些改进。和其他的算法相比,此HSFC的模糊聚类有如下优点:
(1)通过循环地改变聚类中心数量,HSFC根据这些不同的聚类中心数量得到聚类中心点及其评价函数,取其评价函数最小的一组聚类中心作为算法最终的结果,从而能够自动找到正确或合理的聚类中心数。
(2)通过特征属性加权,改变了每一维对聚类结果的影响,提高了聚类准确性。
(3)在算法运行后期,采用大概率调音保证了算法不会收敛到局部极小。
本文算法用于并行程序计算过程中的性能分析,将高维的性能瓶颈数据进行聚类,将若干处理器按照性能瓶颈的类型和严重程度进行归类,然后对每一类处理器组的性能瓶颈值进行加权并根据阈值进行筛选,最终得出每一类处理器组最有可能出现的性能瓶颈类型。这样程序员可以针对每个处理器所属的类别预知其可能出现的所有性能瓶颈,从而及时做出任务调整和处理器调度,提高并行程序运行效率。
[1]罗印升,李人厚,张维玺.一种基于克隆选择的聚类算法[J].控制与决策,2005,20(11):1261-1264.
[2]徐晓华,陈崚.一种自适应的蚂蚁聚类算法[J].软件学报,2006,17(9):1884-1889.
[3]李帅,王新军,高丹丹.基于内部空间特性的PSO聚类算法[J].计算机工程,2009,35(5):197-199.
[4]Geem Z W,Kim J H,Loganathan G V.A new heuristic optimization algorithm:harmony search[J].Simulation,2001,76(2):60-68.
[5]Alia O,Mandava R,Aziz M.A hybrid harmony search algorithmforMRIbrainsegmentation[J].EvolutionaryIntelligence,2011,4(1):31-49.
[6]Forsati R,Meybodi M R,Mahdavi M,et al.Hybridization of K-means and harmony search methods for Web page clustering[C]//Proceedings of International Conference on Web Intelligence and Intelligent Agent Technology,2008:329-335.
[7]Ayvaz M T.Simultaneous determination of aquifer parameters and zone structures with fuzzy C-means clustering and metaheuristicharmonysearchalgorithm[J].AdvancesinWater Resources,2007,30(11):2326-2338.
[8]Law M H,Figueiredo M A,Jain A K.Simultaneous feature selection and clustering using mixture models[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2004,26(9):1154-1166.
[9]Dy J,Brodley G C E,Mach J.Feature selection for unsupervised learning[J].Journal of Machine Learning Research,2004,5:845-889.
[10]Sarvari H,Khairdoost N,Fetanat A.Harmony search algorithm forsimultaneousclusteringandfeatureselection[C]// Proceedings of International Conference on Soft Computing and Pattern Recognition,2010:202-207.
[11]Huang J Z,Ng M K,Rong H,et al.Automated variable weighting in K-means type clustering[J].IEEE Trans on Pattern Anal Mach Intell,2005,27:657-668.
[12]Modha D S,Spangler W S.Feature weighting in K-means clustering[J].Mach Learn,2003,52:217-237.
[13]Friedman J H,Meulman J J.Clustering objects on subsets of attributes[J].J R Stat Soc:Ser B Stat Methodol,2004,66:1-25.
[14]Mohamed N A,Sameh M Y,Aly A F,et al.A modified fuzzy C-means algorithm for bias field estimation and segmentation of MRI data[J].IEEE Transactions on Medical Imaging,2002,21(3):193-199.
WANG Huaqiu1,LUO Jiang1,Michael GERNDT2,Ventsislav PETKOV2
1.School of Computer Science,Chongqing University of Technology,Chongqing 400054,China
2.Institute of Informatics I10,Technology University Munich,D-85748,Munich,Germany
Three methods are adopted to achieve a better clustering quality.Considering the different influences of each dimension attribute of data on the clustering effect,statistic method is used to weight each dimension to select feature.Some improvements are carried out for the probability of harmony search algorithm and combine fuzzy clustering algorithm with harmony search to rapidly find the optimal cluster centers.The iterative method is used to test clustering quality to get the best number of cluster center.The proposed algorithm is applied to parallel computing performance analysis to distinguish and identify the performance bottleneck category of various processors during parallel program running.Experimental results show that the proposed clustering algorithm outperforms other similar algorithms.This performance analysis method can improve the operating efficiency of the parallel program.
harmony search;fuzzy clustering;feature selection;parallel performance analysis
采取了3种必要的措施提高了聚类质量:考虑到各维数据特征属性对聚类效果影响不同,采用了基于统计方法的维度加权的方法进行特征选择;对于和声搜索算法的调音概率进行了改进,将改进的和声搜索算法和模糊聚类相结合用于快速寻找最优的聚类中心;循环测试各种中心数情况下的聚类质量以获得最佳的类中心数。该算法被应用于并行计算性能分析中,用于识别并行程序运行时各处理器运行性能瓶颈的类别。实验结果表明该算法较其他算法更优,这样的性能分析方法可以提高并行程序的运行效率。
和声搜索;模糊聚类;特征选择;并行性能分析
A
TP301.6;TP338.6
10.3778/j.issn.1002-8331.1202-0447
WANG Huaqiu,LUO Jiang,Michael GERNDT,et al.Research and application of harmony search fuzzy clustering with feature selection.Computer Engineering and Applications,2013,49(19):112-118.
教育部人文社会科学研究青年基金(No.10YJC870037);重庆市教委科学研究资助项目(No.KJ100805)。
王华秋(1975—),男,博士,副教授,主要研究领域为人工智能,数据挖掘;罗江(1987—),女,硕士生;Michael GERNDT,男,博士,教授;Ventsislav PETKOV(1985—),男,博士生。E-mail:wanghuaqiu@163.com
2012-02-29
2012-05-08
1002-8331(2013)19-0112-07
CNKI出版日期:2012-06-15http://www.cnki.net/kcms/detail/11.2127.TP.20120615.1725.008.html
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
家庭影院技术(2018年11期)2019-01-21 02:20:36
琴童(2017年8期)2017-09-04 23:09:24
电子制作(2017年23期)2017-02-02 07:17:06
唐山文学(2016年2期)2017-01-15 14:04:03
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2015年15期)2015-04-12 00:43:48
爆笑show(2015年1期)2015-03-26 18:07:33
河北科技大学学报(2015年5期)2015-03-11 16:16:37
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
