
异构环境下增强的自适应MapReduce调度算法
2013-07-19 08:43杨立身余丽萍
计算机工程与应用 2013年19期
杨立身,余丽萍
河南理工大学计算机科学与技术学院,河南焦作 454000
异构环境下增强的自适应MapReduce调度算法
杨立身,余丽萍
河南理工大学计算机科学与技术学院,河南焦作 454000
1 引言
MapReduce[1]是一个编程模型,也是一个处理和生成超大数据集的算法模型的相关实现。Hadoop[2]是MapReduce的开源实现,它不仅广泛应用于批量大作业同时也用于处理相应低效率的短作业。MapReduce的一个关键的优势是它能够自动处理故障,隐藏容错的复杂性,对用户完全透明。如果一个节点崩溃,MapReduce将其运行的任务分配给其他节点继续运行[3]。更重要的是如果节点可用但是其性能低下时,称低性能机器上处理的任务为掉队者,MapReduce会在另外一个节点运行一个推测执行任务,以更快地完成计算,该机制称为推测执行机制[4-5]。现有的Hadoop调度算法都是建立在同构集群的假设前提下的,并使用这些假设决定何时推测式地执行落后队列的任务,但是这种同构的假设在实践中是行不通的。
目前,要解决的问题是如何高效地通过运行推测执行机制将系统性能最大化。国外学者针对此现象提出了多种改进方法。文献[6]提出了LATE调度算法,核心思想是基于一个异构环境,使用静态的方法去计算任务的进度,对系统性能的提升效果甚微。文献[7-8]针对LATE调度算法的不足提出了SAMR调度算法,核心思想是基于历史信息动态地调整Map和Reduce任务各阶段的时间比例,找到真正需要启动备份任务的执行任务。以上几种算法都未考虑作业类型、数据集的大小对任务进度值的影响,因此并不能最大化地提高系统的性能。
本文针对以上算法进行改进,在SAMR算法的基础上提出了一个增强的自适应K-SAMR调度算法。考虑到其他影响任务进程的因素,该算法记录了每个节点的历史信息并采用K-means聚类算法动态地调整阶段进度值参数,准确地查找慢任务。并将慢节点分为Map任务慢节点和Reduce慢节点,有效地提高了系统资源利用率。
2 研究现状分析
2.1 Hadoop默认调度器
Hadoop默认的调度器[9]通过任务进度值Progress Score对推测执行任务进行选择,常使用0到1之间的值来标识每个任务的进度。由AvgProgress来表示每个作业的平均进度值,Progress Score[i]表示第i个任务的任务进度值。设定已经处理完成的任务条数为M,总共需要处理的任务条数N,所处的阶段的序列号为K,任务数量为P。Hadoop默认调度算法首先根据公式(1)和公式(2)获得PS的值,然后根据公式(3)判断任务是否为落后任务,并在另一个快节点上执行该任务的后备任务。

文献[10]指出该调度器的主要缺陷:首先,Hadoop默认调度器使用固定的阶段进度值M1=1,M2=0,R1=R2=R3=1/3,该方式没有考虑集群节点的异构性,在现实环境中会造成任务进度估计的失真。其次,Hadoop默认调度器根据任务进度值来启动备份任务是不合理的,该方式没有考虑异构环境下不同节点执行任务的速率之间的差异性。最后,Hadoop默认调度器可能启动不必要的备份任务。
2.2 LATE调度器
LATE调度器[11]通过重启剩余时间最长任务的备份任务来解决默认调度器的不足,假设任务已经运行的时间为Tr,任务的处理速度为ProgressRate,任务的最长剩余完成时间为TTE。LATE调度算法首先利用公式(1)计算任务的进度值PS,然后利用公式(4)和(5)计算任务的最长剩余完成时间:

尽管LATE选取剩余时间最长的任务去启动备份任务,但它仍然频繁地选择错的任务去备份。这是因为LATE调度算法仍然使用Hadoop默认调度算法的设定,并且未区分Map慢节点和Reduce慢节点,导致LATE调度算法对任务的剩余时间的估计不精确。
2.3 SAMR调度器
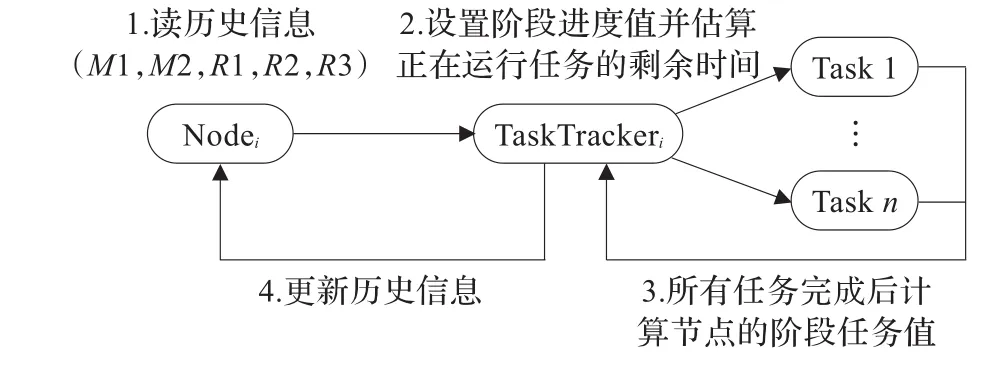
图1 在SAMR调度器中使用和更新历史信息
SAMR调度器通过估计任务执行时间来识别慢任务,但不采用固定的阶段进度值。如图1所示,当SAMR调度器估计一个节点上正运行任务的剩余时间时,它存储每个节点上的阶段进度值,读取存储在节点上的历史信息然后动态地设置阶段进度值。由于SAMR采用历史信息记录每个节点的阶段取值更贴近实际,因此,相对于Hadoop默认调度器、LATE调度器,SAMR调度器更能够适用于异构环境。
SAMR只考虑影响任务阶段进度值的其中一个因素,没有考虑在同一个节点上运行不同MapReduce作业的任务可以有不同的阶段进度值。原因是当执行不同MapReduce作业时,执行Map和Reduce阶段花费的时间不同,并且它们产生的大量中间数据也不同。另外,当处理大小不同的数据集时,相同的MapReduce作业的任务也会有不同的阶段进度值。例如,大的输入数据集会造成大的中间数据,这些将导致其需要花费更多的时间在Shuffle阶段[12]。
本文提出的K-SAMR算法是一个增强的自适应MapReduce调度算法。除了考虑硬件异构性的因素以外,还考虑了其他影响任务阶段进度值的因素。因此,K-SAMR算法在记录每个节点上历史信息的同时采用K-means聚类算法动态调整阶段进度值,估计任务的执行时间,查找慢任务。
3 K-SAMR调度器
3.1 K-SAMR算法的基本思想
K-SAMR算法使用机器学技术把存储在每个节点上的历史信息归类为K个聚蔟。如果正在运行的作业的Map任务完成量达到阀值PFM,K-SAMR算法将根据节点上完成的Map任务记录作业的临时Map阶段进度值M1。临时进度值M1用于查找与进度值M1最接近的聚蔟。然后,K-SAMR用聚蔟的阶段进度值估计节点上作业的Map任务的剩余完成时间,分析需要被重新执行的慢任务。如果正在运行的作业已经完成节点上所有的Map任务,那么所有K聚蔟的阶段进度值的平均值将被用于整个作业。在Reduce阶段,K-SAMR执行类似的进程。一个作业完成之后,K-SAMR计算每个节点的作业的阶段进度值,并保存这些新的进度值作为历史信息的一部分。最终,K-SAMR利用K-means聚类算法和机器学技术重新去归类存储在每个工作节点上的历史信息,并保存每个K聚蔟更新后的平均阶段进度值。通过利用更精确的阶段进度值来估计正在运行任务的剩余时间,和另外三种算法相比,K-SAMR算法能更准确地识别慢任务,K-SAMR具体算法如下:


3.2 Map任务完成的比例(PFM)和Reduce任务完成的比例(PFR)
K-SAMR调度算法利用PFM和PFR决定何时去计算临时阶段进度值。假设N代表一个集群中TaskTrackers的全部数量,FM代表一个作业中Map任务的总数量,FM[i]代表第i个TaskTracker中Map任务完成的数量,TR代表一个作业中Reduce任务的全部数量,FR[i]代表第i个Task-Tracker中Reduce任务的完成数量。当公式(5)和(6)满足条件时,K-SAMR算法才能计算每个作业的Map和Reduce阶段的临时进度值。

3.3 使用历史信息和临时信息
K-SAMR算法首先计算临时阶段进度值,然后同历史记录信息进行比较,最后找出适合作业阶段进度值的最佳组合。图2展示了在K-SAMR算法中使用Map临时信息和历史信息的方式;图3展示了在K-SAMR中使用Reduce临时信息和历史信息的方式。

图2 使用Map临时信息和历史信息的方法
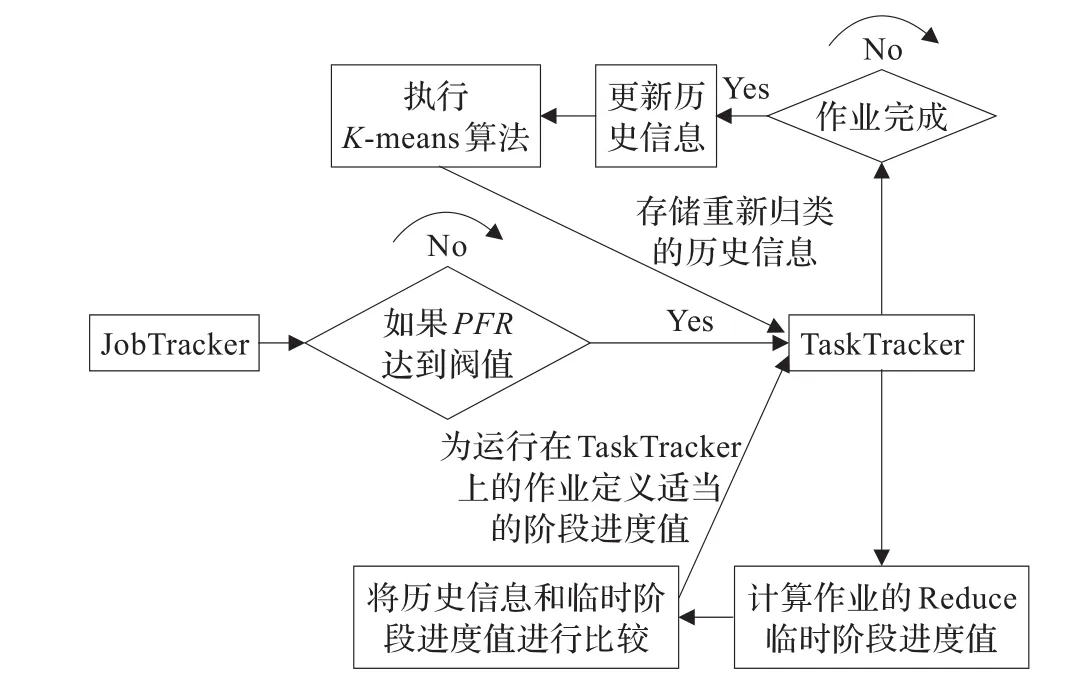
图3 使用Reduce临时信息和历史信息的方法
具体步骤如下:
(1)JobTracker首先查看PFM是否达到阀值。如果达到,K-SAMR算法将计算每个节点上Map任务完成的阶段进度值,并生成一个临时文件MapWeight来记录临时阶段进度M1。
(2)每个TaskTracker从本地节点读取历史信息(M1,M2,R1,R2,R3)。
(3)K-SAMR算法将历史信息与存储在临时文件Map Weight里面的信息进行比较。在Map阶段,K-SAMR算法将M1与K个历史信息聚簇中的平均结果进行比较,并找到最接近进度值的聚蔟的中心蔟,同时设置M1作为该组的平均结果;M2=1-M1。
(4)K-SAMR利用新的Map阶段进度值计算出正在执行的任务的速度和剩余时间,并判断出哪些是慢任务。
(5)在Reduce阶段中,K-SAMR首先查看PFR是否达到阀值。如果达到阀值,K-SAMR算法将计算每个节点上完成Reduce任务的阶段进度值,并生成一个临时文件ReduceWeights去记录临时进度值R1和R2。K-SAMR算法将R1和R2与K个历史信息聚簇中的平均结果进行比较,并找到最接近进度值的组,同时设置R1和R2作为该组的平均结果;R3=1-R1-R2。
(6)K-SAMR利用Reduce阶段进度值计算出正在执行的任务的速度和剩余时间,并判断出哪些是慢任务。
(7)当一个作业完成时,K-SAMR计算作业的所有Map和Reduce任务阶段的平均值,同时生成一个新的阶段进度值的聚簇作为历史信息的一部分。
(8)K-SAMR运用K-means算法去重新归类阶段进度的聚蔟,并且存储重新归类的历史信息。
3.4 慢任务探索算法
STT代表一个阀值,它用来判断一个任务是否为慢任务。假设第i个任务的剩余时间为TTEi,所用任务的剩余时间为ATTE,一个作业当前正在运行的Map数量和当前正在运行的Reduce数量是N。如果满足公式(8)和(9),则第i个任务被判断为慢任务。

根据公式(8)可得:如果STT太小以至于接近0,那么将会误判快的任务为慢的任务;如果STT太大以至于接近1,那么就发现不了慢的任务,从而不能启动备份任务。因此,需要去选择一个合适的STT的慢任务。
3.5 慢节点探索算法
SNT代表一个阀值,它用来判断一个任务是否为慢节点,假设系统中有N个TaskTrackers,第i个TaskTracker的节点Map任务的进度率为TRmi,Reduce阶段的进度率为TRri,平均进度率是为ATRm、ATRr。如果有M个Map任务和R个Reduce任务运行在第i个TaskTracker节点上,TRmi、TRri、ATRm、ATRr的计算公式如下:


对于第i个TaskTracker如果满足式(14),它是一个慢的Map TaskTracker,如果满足式(15),它就是一个慢的Reduce TaskTracker。

需要通过大量的实验来确定SNT的值。如果SNT取值太小,那么将会把一些正常的TaskTracker误判为慢Task-Tracker;如果SNT取值过大,则将会把一些慢的TaskTracker误判为正常TaskTracker。只有当申请任务的TaskTracker不是掉队者时,它才把慢的任务的后备任务交给该Task-Tracker执行。
3.6 K-means算法在K-SAMR中的应用
在统计和数据挖掘方面,K-means聚类算法是一种聚类分析方法[13]。K-means聚类算法的主要目标是将一个数据集划分为若干个聚簇,使聚簇内的对象尽可能相似,而类之间尽可能相异。
在K-SAMR中的K-means聚类算法的步骤为:(1)K-SAMR任意选择K个样本作为聚簇初始的中心点;(2)根据每个聚簇的中心坐标,把每个样本分配给距离其最近的聚簇;(3)更新聚簇的中心点坐标,即计算每个聚簇中所有样本的均值;(4)不断重复(2)、(3)步骤直至收敛。图4给出了K-means算法在K-SAMR中的使用流程图。

图4 K-SAMR中的K-means算法流程图
4 实验结果及性能分析
本文利用异构环境下已有的两种改进算法SAMR和LATE算法与K-SAMR算法相比较。在这三种调度算法的基础上改写Hadoop默认调度器,在新的三种调度器上,运行Hadoop自带的基准测试程序WordCount去评估算法的性能。
首先搭建有6台普通PC机组成的集群,其中1台为主节点,5台为工作节点,它们运行在同一个机架上。表1列出了集群的硬件环境和配置。其次设置合适的参数,提高系统的效率。实验设置了4个文献[6]中已经论证的最佳参数值,如下:PFM设置为20%,PFR设置为20%,K设置为10,STT设置为40%。其中,相同的PFM、PFR、STT参数值也应用于设置算法SAMR和LATE。HP对于SAMR算法是一个重要的配置,文献[8]表明HP为0.2时SAMR达到最佳的性能,所以把HP的值设置为0.2。最后,通过三个方面验证K-SAMR算法的性能:估计阶段进度值的能力;估计剩余时间的能力;鉴别慢任务的能力。

表1 Hadoop集群的硬件环境和配置
4.1 估计阶段进度值的能力
为了验证通过K-SAMR算法估计的Map和Reduce阶段进度值的准确性,对比表2和表3可以发现,通过K-SAMR算法估计Map和Reduce各阶段进度值和从系统收集的Map和Reduce阶段实际的阶段进度值相差不大,但是其与利用固定阶段进度值的LATE算法的结果相差很大;并且,通过SAMR算法估计的结果和从系统收集来的实际进度值之间的差值,比采用K-SAMR算法获得的进度值大得多。

表2 K-SAMR算法与真实进度值的比较

表3 SAMR算法与真实进度值的比较
4.2 估计剩余时间的能力

图5 Map任务剩余时间估计误差(WordCount 10 GB)
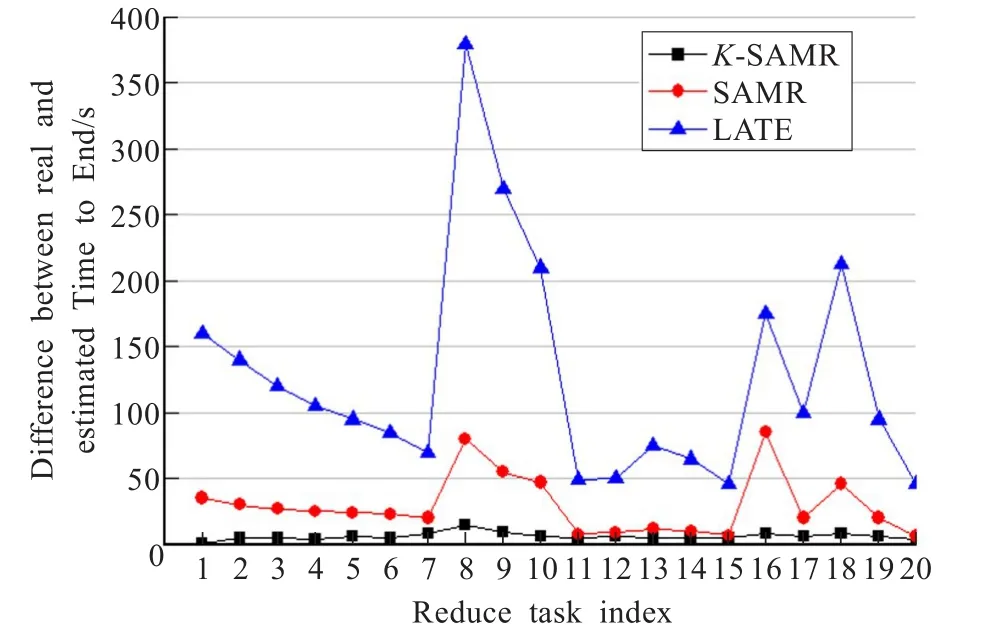
图6 Reduce任务剩余时间估计误差(WordCount 10 GB)

图7 Map任务执行时间
为了验证算法估计任务剩余时间的准确性,首先,通过运行10次WordCount程序来比较三个MapReduce调度算法的任务剩余时间;其次,分别设置PFM的值为20%,PFR的值为20%,K的值为10,STT的值为40%,SNT的值为30%;最后,比较三种调度策略的剩余时间估计误差。图5和图6分别显示了通过K-SAMR、SAMR、LATE算法运行1个10 GB大小的WordCount作业时,Map和Reduce阶段的剩余时间估计误差。一个作业有100个Map任务和20个Reduce任务,由于20个Map任务已经足够去说明差异,为了方便起见选取100个Map任务中的前20个Map任务,选取全部Reduce任务。在三种算法中,K-SAMR算法导致最小的估计误差。使用K-SAMR算法估计Map和Reduce任务剩余时间和真实的剩余时间的差异,分别小于4 s和5 s。使用SAMR算法估计Map和Reduce任务剩余时间和真实的剩余时间的差异,分别小于38 s和37 s。使用LATE算法估计Map和Reduce任务剩余时间和真实的剩余时间的差异,分别小于64 s和129 s。
4.3 鉴别慢任务的能力
为了验证算法鉴别Map掉队任务的能力,将K-SAMR、SAMR、LATE三个调度算法执行Map任务的时间与真实执行时间相互对比,从图7可以看到,K-SAMR选择第8个和第9个的Map任务为最慢的任务,SAMR选择第10个Map任务为最慢的任务,LATE选择第一个Map任务为最慢的任务。但是真正最慢的任务是第8个和第9个的Map任务,所以只有K-SAMR准确地鉴定了慢任务。
为了验证算法鉴别Reduce慢任务的能力,将K-SAMR、SAMR、LATE三个调度算法执行Reduce任务的时间与真实执行时间的相对比,从图8可以看到K-SAMR选择第1个Reduce任务为最慢的任务,SAMR选择第8个Reduce任务为最慢的任务,LATE选择第8个和第9个 Reduce任务为最慢的任务。但是真正最慢的任务是第1个的Reduce任务,因此只有K-SAMR准确地鉴定了慢任务。
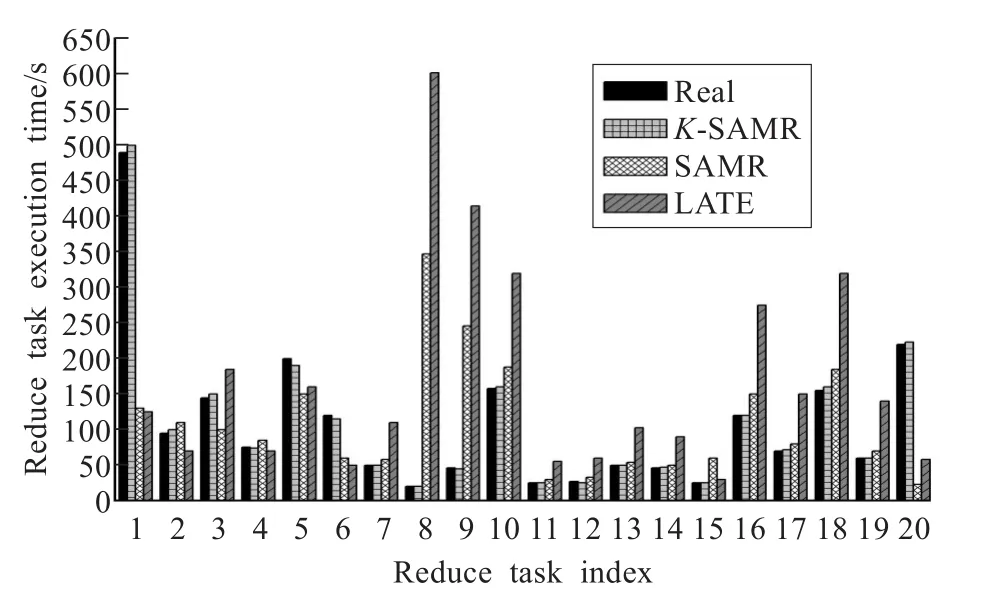
图8 Reduce任务执行时间
5 总结
针对现有Hadoop调度算法推测执行机制的不足,本文通过研究当前存在的MapReduce调度算法,提出了一种在异构环境下增强自适应性的MapReduce调度算法。该算法记录了每个节点的历史信息,采用机器学习技术K-means聚类算法将历史信息划分为K个聚蔟,并且动态地调节阶段进度值参数,平衡节点上的负载并准确地查找慢任务。最后,通过实验结果表明了本文K-SAMR算法的有效性。
[1]Jiang Dawei,Ooi Bengchin,Shi Lei,et al.The Performance ofMapReduce:anin-depthstudy[C]//Proceedingsofthe International Conference on Very Large Data Bases,2010:472-483.
[2]Dean J,Ghemawat S.Map reduce:a flexible data processing tool[J].ACM Transactions on Accessible Computing,2010,53(1):72-77.
[3]梁建武,周扬.一种异构环境下的Hadoop调度算法[J].中国科技论文,2012,7(7):495-502.
[4]张密密.MapReduce模型在Hadoop实现中的性能分析及改进优化[D].成都:电子科技大学,2010.
[5]Riedel E,Faloutsos C,Gibson G A.Active disks for large scale data processing[J].IEEE Computer,2001,34:68-74.
[6]Zaharia M,Konwinski A,Joseph A D.Improving MapReduce performanceinheterogeneous environments[C]//Proceedings of the 8th Conference on Operating Systems Design and Implementation,2008:29-42.
[7]陈全,邓倩妮.异构环境下自适应的Map-Reduce调度[J].计算机工程与科学,2009,26(1):2-6.
[8]Chen Quan,Zhang Daqiang,Guo Minyi,et al.SAMR:a selfadaptive MapReduce scheduling algorithm in heterogeneous environment[C]//Proceedings of the 10th IEEE International Conference on Computer and Information Technology(CIT-2010),2010:2736-2743.
[9]王凯,吴泉源,杨树强.一种多用户MapReduce集群的作业调度算法的设计与实现[J].计算机与现代化,2010(10):23-25.
[10]王昊,王向前,郑启龙.推测执行技术在HPMR系统通信优化中的应用[J].中国科学技术大学学报,2010,40(11):1191-1196. [11]李丽英.基于LATE的Hadoop数据局部性改进调度算法[J].计算机科学,2011,38(11):67-70.
[12]Seo Sangwon.HPMR:prefetching and pre-shuffling shared MapReduce computation environment[C]//Proceedings of the 11th IEEE International Conference on Cluster Computing,Sep 2009.
[13]黄敏,何中市,邢欣来,等.一种新的K-means聚类中心选取算法[J].计算机工程与应用,2011,47(35):132-134.
YANG Lishen,YU Liping
College of Computer Sciences and Technology,Henan Polytechnic University,Jiaozuo,Henan 454000,China
Aiming at the shortage of Hadoop default scheduling algorithm and LATE scheduling algorithm of heterogeneous environment,this paper proposes an enhanced adaptive MapReduce scheduling algorithm on the basis of SAMR scheduling algorithm.The algorithm records the history information of each node,and usesK-means clustering algorithm to dynamically adjust the progress value,aims to find the slow tasks which are really need begin back-up.Finally,the experimental results show that the enhanced MapReduce scheduling algorithm has some validity in the aspect of improving the estimation error of the tasks’execution time and accurately identifying the slow tasks.
MapReduce;speculative execution;heterogeneous environment;K-means algorithm
针对Hadoop默认调度算法和异构环境下LATE调度算法的不足,在SAMR调度算法的基础上提出了一种增强的自适应MapReduce调度算法。该算法记录了每个节点的历史信息,采用K-means聚类算法动态地调整阶段进度值以找到真正需要启动备份的落后任务。实验结果表明,增强自适应的MapReduce调度算法在提高任务执行时间的估算误差以及准确识别慢任务方面具有一定的有效性。
MapReduce;推测执行;异构环境;K-means算法
A
TP393
10.3778/j.issn.1002-8331.1302-0126
YANG Lishen,YU Liping.Enhanced adaptive MapReduce scheduling algorithm in heterogeneous environment.Computer Engineering and Applications,2013,49(19):39-43.
国家自然科学基金(No.12A520021);河南省科学和技术部财政支持重点项目(No.122102310309,No.122102210117)。
杨立身(1963—),男,教授,硕士生导师,主要研究领域为计算机网络与安全,管理信息系统,过程控制;余丽萍(1984—),女,硕士研究生,主要研究领域为云计算,云存储。E-mail:yulipingl520@163.com
2013-02-22
2013-04-17
1002-8331(2013)19-0039-05
CNKI出版日期:2013-04-26http://www.cnki.net/kcms/detail/11.2127.TP.20130426.1018.008.html
猜你喜欢
小学教学研究(2022年5期)2022-04-28
铁道通信信号(2020年10期)2020-02-07
成都信息工程大学学报(2019年3期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
电子测试(2017年15期)2017-12-18
中国洗涤用品工业(2017年2期)2017-04-16
雷达学报(2017年6期)2017-03-26
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
电子设计工程(2015年6期)2015-02-27
