
模糊聚类分析在我国各省市经济发展综合实力评价中的应用
2013-07-16 05:59韦相
湖北民族大学学报(自然科学版) 2013年1期
韦 相
(红河学院计算机科学与技术系,云南蒙自 661100)
改革开放以来,我国各省市因起点不同,再加上资源、技术、地域及政策等条件的差异,使我国各省市的经济发展水平存在较大的差异,特别是东部和西部的经济水平差异更大.因此,对各省市的经济发展水平进行分析,总结出经济发展的优势和劣势,有针对性的制定经济发展战略,有利于促进国民经济的协调发展[1].
聚类是根据数据自身的相似程度,将数据分到不同的类或者簇的过程,因此同一簇中的对象相似性大,而不同簇间的对象相似性小[2].一个对象要么属于此簇,要么不属于此簇,不存在介于二者之间的情况,这是一种硬划分的聚类算法[3-4].
模糊聚类方法在硬划分的基础上引进模糊性,它使得各个对象以不同的隶属度划分到各个簇中,模糊聚类方法基于Zadeh提出的模糊集概念和模糊数学方法.模糊聚类能够有效地对反映对象既属于这个集合,又属于那个集合这种现象,所得的聚类结果明显的优于硬聚类,更客观更准确地反映现实情况.
模糊聚类算法有模糊c-均值聚类算法和基于模糊关系的传递闭包等.本文使用基于模糊关系的传递闭包来实现对31省市的指标数据进行的聚类分析,基于两种原因:①省市的指标数据不好硬性划分,具有模糊性,而模糊相似矩阵能很好的处理模糊现象;②使用模糊c-均值聚类算法(FCM)[5]需要事先确定聚类的簇数c以及每个簇的聚类中心,而对于这些指标数据来说,事先很难确定簇数c和每簇的聚类中心,而模糊相似矩阵不需要事先确定聚类中心,可以根据等价矩阵,获得详细的动态聚类图,方便用户按照自己的理解方式划分簇数,因而该算法得到广泛的应用.文献[6]使用模糊聚类算法实现对Web日志的聚类分析,文献[7]使用模糊聚类分析对Web文档进行预取,提高网页服务器效率;文献[8]使用模糊聚类算法对DNA序列进行聚类分析,准确度很高.
1 经济指标的选择和数据收集
经济的协调发展涉及到很多因素,包括:人口、经济、社会、资源、环境等方面内容,每一方面的内部都涉及到很多的因素,所以它是一个内在关系极其复杂的现实系统,本文选取的指标包括:人口系统的人力资源相关指标、经济系统的经济增长相关指标以及社会系统的生活质量相关指标,建立起一个科学的综合评估指标体系[9].本文选取2009年全国31个省市的9项指标,从人力资源、经济增长和生活质量3个方面分析地方经济:
1)人力资源:X1-就业人数(万人);
2)经济增长:X2固定资产投入(亿元);X3-第一产业总产值(亿元);X4-第二产业总产值(亿元);X5-第三产业总产值(亿元);X6-人均生产总值(元);
3)生活质量:X7-城镇单位就业人员平均工资(元);X8-居民消费水平(元);X9-社会消费品零售总额(亿元).
上述指标的具体数据来源于《中国统计年鉴2010》,具体数据如表1[10].
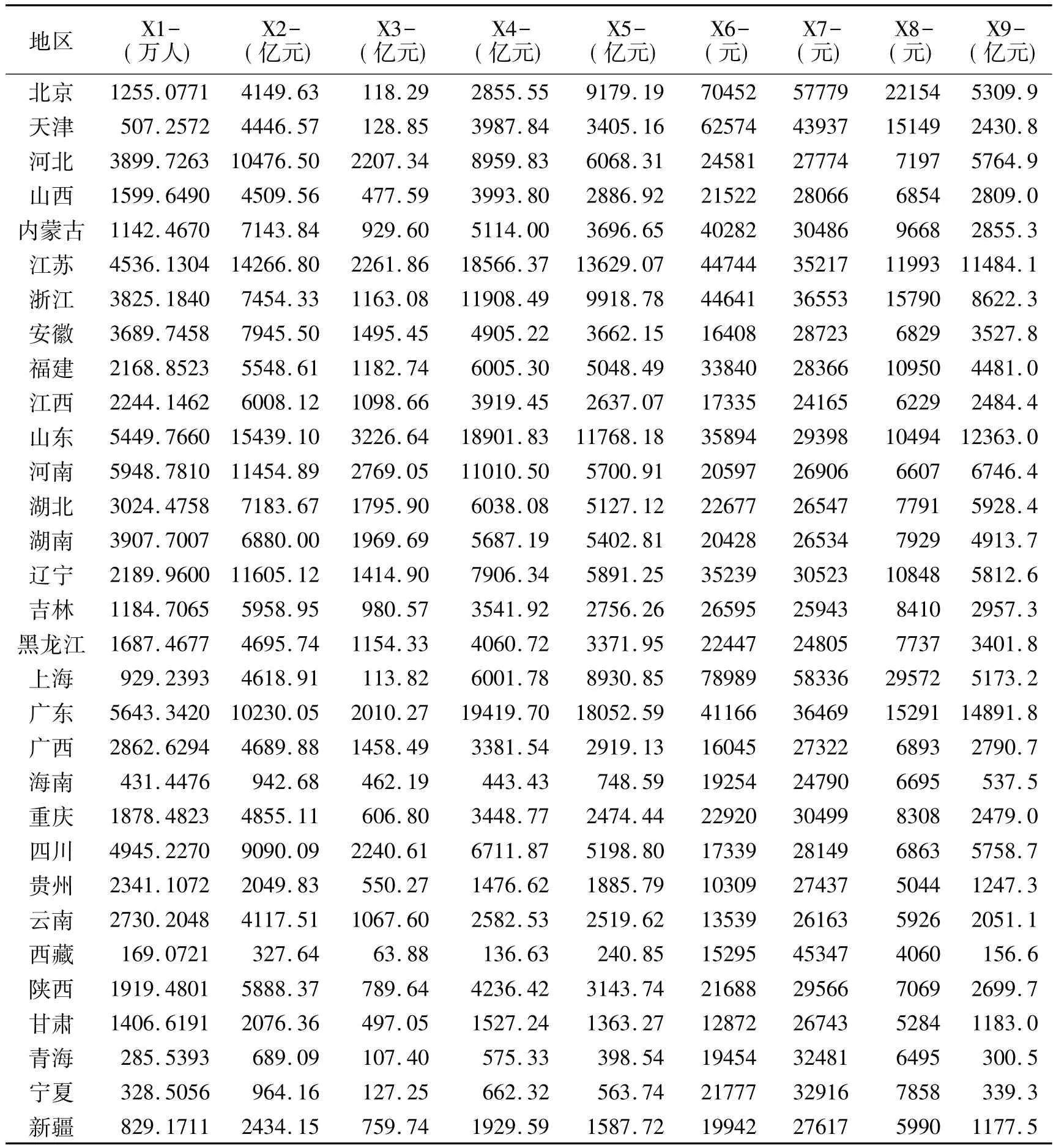
表1 31个省市9项指标原始数据Tab.1 The nine indicators raw data of the 31 provinces
对上表的数据进行标准化处理,本文采用的标准化方法是平移法的极差变换:

说明:max{xij1≤i≤31}表示第 j(1,2,…,9)列的最大值,min{xij1≤i≤31}表示第 j(1,2,…,9)列的最小值.
标准化后得到的数据如下表2(因内容过多,本文只给出16省的标准化数据).
2.1.1 线性关系的考察。以对照品溶液浓度为横坐标(X)、峰面积为纵坐标(Y),绘制标准曲线,得出回归方程。结果显示(表1),绿原酸、葫芦巴碱、D-(-)-奎宁酸和咖啡酸分别在14.6~146.0 μg/mL(r=1.000 0)、10.2~102.0 μg/mL(r=1.000 0)、11.6~116.0 μg/mL(r=0.999 8)、0.499 5~4.995 0 μg/mL(r=0.999 8)的浓度范围内线性关系良好。

表2 16个省市9项指标的标准数据Tab.2 The Nine Indicators standard Data of the 16 Province
2 模糊相似矩阵建立方法
根据以下两个定义,建立模糊相似矩阵.
定义1模糊相似关系:设有论域X,X×X是X上各元素之间的模糊关系,对于任意x,y∈X,满足:
i)自反性:R(x,x)=1;ii)对称性:R(x,y)=R(y,x);
当论域X={x1,x2,…,xn}为有限时,模糊关系R就构成模糊相似矩阵.
两个向量的相似性可以使用距离法或相似系数法.距离法包括:海明距离、欧氏距离和切比雪夫距离等;相似系数法包括:夹角余弦法和相关系数法等.采用切比雪夫距离法建立模糊相似矩阵,它的公式如下:
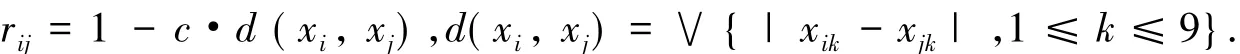
说明:xi表示第i个省市的特征向量(1≤i≤31),d(xi,xj)表示特征向量xi,和xj的距离,c为适当选取的参数,d(xi,xj)定义为2个特征向量之间的距离定义为其各坐标数值差的最大值.
根据上面的相似计算方法,对31个省市的特征向量计算相似关系,得到相似矩阵:

定理1[8]设R∈M(n×n)是模糊相似矩阵,任意自然数k,Rk也是模糊相似矩阵,例:R2=R◦R(k=2).
定理2[8]设R∈M(n×n)是模糊相似矩阵,则存在一个最小自然数k(k≤n),使得传递闭包t(R)=Rk,对于任何自然数b≥k,都有Rb=Rk,此时,t(R)是模糊等价矩阵.
通过求传递闭包t(R),可以将模糊相似矩阵改造成为模糊等价矩阵.
计算传递闭包t(R)过程:从相似矩阵R出发,经过过程R→R2→R4→R8,最多经过log2N+1(N为样本的数目31)后,必有R2k=(R2k)2,停止迭代,最终的R2k就是模糊等价矩阵.
算法参数c=1,求出的模糊等价矩阵.当λ=0.72时,得到的λ-截集的把各省市分为4类:
第一类:北京、上海
第二类:天津、浙江、广东、江苏
第三类:山东、河南、湖北、湖南、海南、重庆、云南、河北、山西、辽宁、安徽、福建、江西
第四类:内蒙古、吉林、黑龙江、广西、四川、贵州、西藏、陕西、甘肃、青海、宁夏、新疆
得到的λ-截集的分类结果如下,与文献[11]相比,结果相近.
3 结论和模型评价及改进
从聚了结果看,我国区域经济的发展不平衡,东部的经济水平较高,包括作为政治中心的北京和经济中心的上海,以及沿海沿江的天津、浙江、广东、江苏.而大部分的西部省市,经济发展水平较低,固定资产投入不足,第三产业总产值较低,居民消费水平较低.进年来,东西部的差距有进一步扩大的趋势.因此,调整国家经济产业结构,改善西部省份的投资环境,提高西部省市的教育水平,消除东西部人口的文化差异等是以后的工作重点.
本文针对省市分类,初始聚类数c不好确定的难点,使用了基于相似矩阵的模糊聚类法,该方法,操作简便,实用性强.基于相似矩阵的模糊聚类法也有它的缺点,即当聚类对象很多时,相似矩阵占用的存储空间很大,求解传递闭包的过程效率很低等.未来的工作方向:使用主成分分析方法或者粗糙集理论等对数据的指标个数进行约简,可以提供计算的效率.
[1]赏晋,杨有,李晓红.地区经济发展的聚类分析和实例判别[J].西华师范大学学报:自然科学版,2006,27(3):260-263.
[2]Margaret H,Dunham.数据挖掘教程[M].郭崇慧,田凤占,等,译.北京:清华大学出版社,2005.
[3]模糊逻辑与计算智能研究编委会.模糊逻辑与计算智能研究进展[C]//2005年中国模糊逻辑与计算智能联合学术会议论文集.北京:中国科学技术大学出版社,2005.
[4]王士同.神经模糊系统及其应用[M].北京:北京航空航天大学出版,1998.
[5]高新波.模糊聚类分析及其应用[M].西安:西安电子科技大学出版社,2004.
[6]李桂英,李吉桂.基于模糊聚类的Web日志挖掘[J].计算机科学,2004,31(12):130-132.
[7]朱培栋,卢锡城,周兴铭.基于客户行为模式的Web文档预送[J].软件学报,1999,10(11):1142-1147.
[8]易东.基因表达聚类结果的信息熵评价方法[J].第三军医大学学报,2004(4):317-319.
[9]朱庆芳,吴寒光.社会指标体系[M].北京:中国社会科学出版社,2001.
[10]中国统计年鉴编委会.中国统计年鉴2010[M].北京:中国统计出版社,2010.
[11]杨桂元,黄己立.数学建模[M].北京:中国科学技术大学出版社,2008.
猜你喜欢
中华诗词(2020年1期)2020-09-21
建筑(2020年5期)2020-04-01
铁道通信信号(2019年6期)2019-10-08
智富时代(2019年1期)2019-03-02
智富时代(2019年1期)2019-03-02
作文与考试·初中版(2018年26期)2018-10-16
领导决策信息(2017年35期)2017-10-20
领导决策信息(2017年34期)2017-10-20
中国公路(2017年6期)2017-07-25
雷达学报(2017年6期)2017-03-26
