
基于数据挖掘和融合技术的游戏关卡生成方法
2013-07-03 08:15:34齐彦君张冰怡冯志勇
计算机与现代化 2013年4期
齐彦君,张冰怡,冯志勇
(1.天津大学软件学院,天津 300072;2.中国民航大学中国民航信息技术科研基地,天津 300300;3.天津大学计算机科学与技术学院,天津 300072)
0 引言
随着计算机和智能手机的发展和普及,游戏已经成为一种非常受欢迎的娱乐方式并呈现出爆炸式的增长态势。游戏开发成为一个快速发展的行业。游戏开发的过程中,游戏关卡的设计是游戏开发的重点。但是如果所有关卡都由设计师逐一设计将花费大量的时间和资金。所以,关卡自动生成技术被应用于游戏关卡的开发中,大大降低了游戏的开发成本。
根据互联网消费调研中心发布的《2011年中国网络游戏黏着度及寿命调查报告》显示,游戏用户黏着度仍然低迷,大部分用户因游戏缺乏新鲜感而在3个月内流失[1]。出现该现象的原因,主要是因为没有充分考虑游戏用户玩游戏时得到的游戏玩法数据。数据挖掘与数据融合同为数据处理方法,在手段、功能上各有侧重。数据挖掘是运用归纳的思想从已有的数据中发现知识;而数据融合则是以演绎的思想实现对知识的应用,并获取新的数据[2-3]。本文提出了一种基于结合属性约简的数据挖掘和数据融合的关卡自动生成技术,用于动态生成游戏关卡,既可以降低游戏的开发成本,又引入了玩家的游戏玩法数据,更容易让玩家喜欢上该游戏。
1 研究背景
1.1 游戏关卡设计现状
现有的游戏关卡设计大都是由关卡设计师逐一设计开发出来的,这需要花费大量的时间和资本。国外的一个著名的关卡设计模型中,提出在关卡设计过程中,艺术学、工程学和设计学起到了非常重要的作用[4]。但是在一个以玩家为最终对象的模型中缺少对玩家在玩游戏时适应程度的分析,因此,需要把玩家的游戏玩法数据作为游戏关卡设计的重要参考信息。
1.2 决策树算法
决策树算法是数据挖掘[5]领域中一个非常重要的研究课题,它是一种以实例为基础,用于分类、聚类和预测的归纳学习方法。它的功能是根据研究对象的属性值和其它约束条件,构造一棵反映目标属性识别的决策树,正好可以解决评估玩家对于游戏的难易程度问题,并且多年来数据挖掘方面的研究者的研究工作也说明了决策树算法能很好地用于对目标属性的识别[6]。决策树算法发展至今,已经积累了大量的算法,它们各有优势,各有特点。考虑到系统需要实时生成游戏关卡,ID3算法可以很好地完成游戏难易程度的识别,并且相对比较高效。
ID3分类算法由Quinlan于1986年提出,使用信息增益作为属性选择标准,采用一种自顶向下、贪婪的搜索方法[7-8]。首先检测所有属性,选择信息增益值最大的属性产生决策树节点,由该属性的不同取值建立分支,再对各分支的子集递归调用该方法建立决策树节点的分支,直到所有子集仅包含同一个类别的数据为止,最后得到一颗决策树,用来对新的测试数据进行分类,即用于关卡信息生成模块[9-10]。
1.3 数据融合技术
在游戏关卡设计中,由于需要融合几个关卡的游戏玩法数据,获取更能代表游戏玩家对游戏的难易程度的数据,并不利用数据融合技术来直接确定游戏的难易程度。因此,根据各个不同的数据融合算法的特点,选择D-S证据理论[11]作为对游戏玩法数据进行融合的算法。
2 基于数据挖掘和融合技术的游戏关卡生成方法设计
玩家的游戏玩法数据(即用户玩游戏时产生的相关数据)对玩家和开发者都有着重要的意义,在这些数据中隐藏着游戏设计中可用的规则知识。研究如何发现和挖掘游戏玩法数据中的规则知识将会提高游戏的自动化和智能化程度。针对游戏玩法数据的特点,利用数据挖掘和数据融合相结合的技术[12-13]处理游戏玩法数据,得到该游戏对于游戏玩家的难易程度,然后利用该信息自动生成设计游戏关卡所需要的数据。有效利用这两种技术,可降低游戏开发成本并提高游戏的可玩性。
本文提出了一种基于数据挖掘和数据融合的游戏关卡自动生成方法,该方法的实现流程如图1所示,主要包括游戏玩法数据收集、数据预处理、基于信息增益的属性约简、决策树的建立、游戏玩法数据的融合、游戏关卡自动生成等。其中,数据挖掘过程中提出了一种新的基于信息增益的属性约简算法用于去除游戏玩法数据中的冗余属性;数据融合过程将对来自于不同关卡的几条数据进行融合,得到新的数据,并且再放入训练数据中,使训练数据更完备、更准确,降低了训练数据的模糊性和不确定性,再次进行数据挖掘所获得的决策树也更为准确。
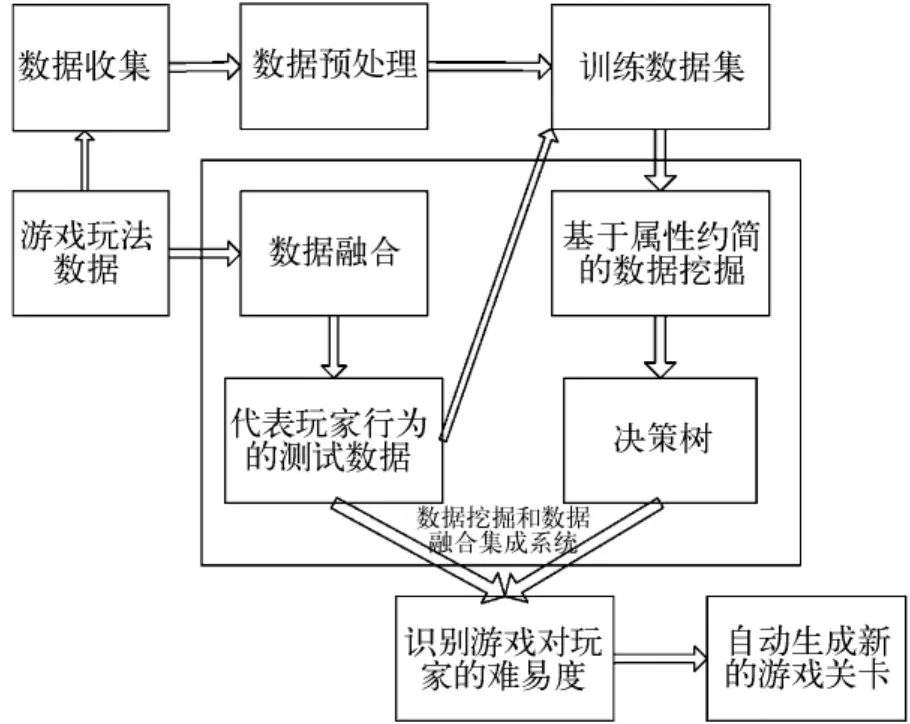
图1 系统流程图
本文以经典的推箱子游戏为例进行实验,验证游戏关卡的自动生成方法。
2.1 游戏玩法数据的获取
利用数据挖掘从推箱子游戏玩法数据中获取游戏的难易程度的识别情况,首先要对每个关卡中所获取的信息进行分析,得到与游戏难易程度有关的关卡属性,同时获得玩家在玩整个关卡时得到的信息。下面列出了通过分析得到的每一条游戏玩法数据的条件属性及代号:
(1)玩家是否通过该关卡a1;
(2)玩家玩该关卡时使用的步数a2;
(3)该关卡中箱子的个数a3;
(4)该关卡中地图的大小a4;
(5)该关卡中障碍物的个数a5;
(6)该关卡中箱子的分散度a6(即箱子在关卡中分布的情况)。
另外,需要获取的目标属性为:该关卡的难易程度d,分为困难、中等和容易3个等级。
当属性选择完成后,就需要按照该属性表获取数据。对于目标属性是由玩家在该关卡结束时通过主观选择得到的,即在游戏源代码的基础上加入一个选择游戏关卡难易程度的功能;其余属性则通过向游戏源代码中加入数据获取模块的代码来完成。
得到的游戏玩法数据必须用信息表的形式描述出来,本系统共获取了1000条数据。纵轴表示实例标记,横轴表示条件属性和目标属性,实例标记与属性的交点就是该条实例在该属性的值。这样就可以得到一张包含1000个实例、6个条件属性和1个目标属性的信息表。由于原始表格较大,表1是部分样本的信息。其中,目标属性中分别用1、2、3来标记容易、中等和困难3类属性值;条件属性中分别用1、2来标记通过关卡和未通过关卡两类属性值。
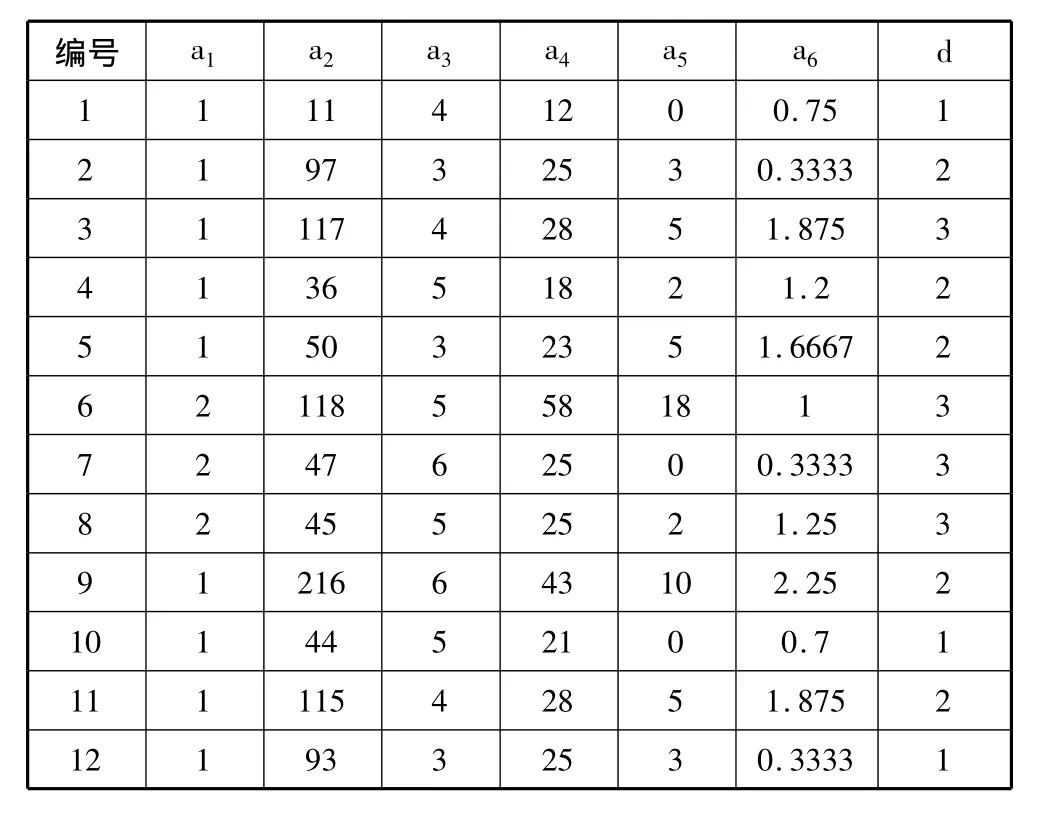
表1 原始信息表(只包含部分样本)
2.2 数据预处理
在运用数据挖掘技术进行数据处理时,要求使用离散的数据,因此在进行数据处理时首先要进行数据的预处理,即数据的离散化处理。离散化处理后的数据不仅可以使运算量缩减,还能在一定程度上降低噪声。本文利用布尔逻辑和粗糙集理论相结合的离散化算法[14]对原始数据进行离散化处理得到新的信息表,如表2所示。
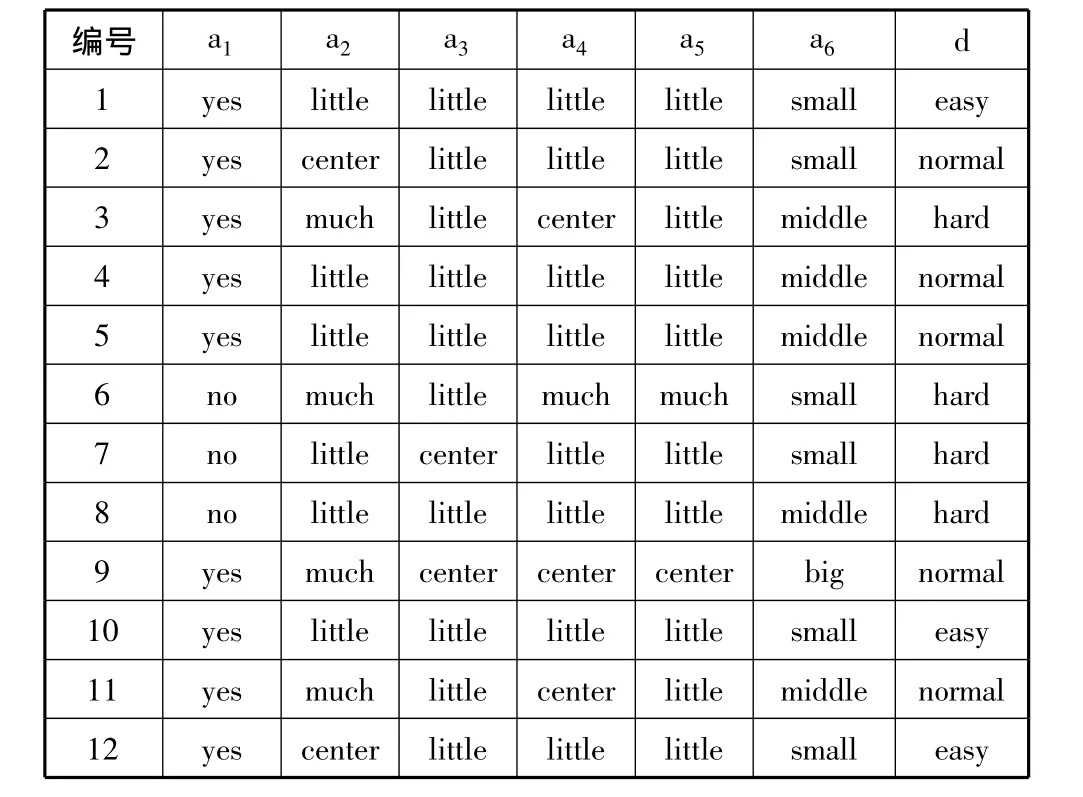
表2 离散化后的信息表(只包含部分样本)
2.3 基于信息增益的属性约简
数据经过预处理后,在作为数据挖掘模块中的训练数据之前,由于所获得的游戏玩法数据的属性中可能存在与目标属性无关或冗余的属性,因此本文提出了一种基于信息增益和属性相关性的属性约简算法。定义属性相关系数:
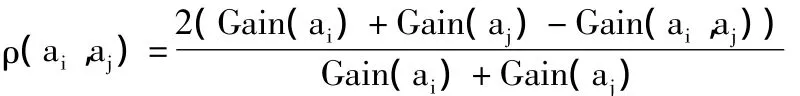
其中,Gain(ai)是按属性ai划分数据集所得的信息增益;Gain(ai,aj)是按属性ai和aj联合划分数据集所得的信息增益。该属性约简算法描述如下:
输入:训练数据T,训练数据属性集合P。
输出:处理后的数据T',选择后的属性集合P'。
方法:
(1)for属性集合P的个数do
(2)计算每个属性与目标属性的相关系数ρ
(3)end for
(4)将ρ按降序排列
(5)for属性集合P的个数do
(6)for剩余属性的个数do
(7)计算所选属性与其他属性的相关性,若ρ(ai,aj)≥ρ(ai,d),则将属性aj从P中删除,直到所有冗余属性被删除
(8)end for
(9)end for
由该属性约简算法可以得出,关卡地图的大小属性a4为系统的冗余属性,则删除属性a4,即把离散化后的信息表中的该属性对应的列数据删除掉,得到用于决策树算法的数据。
2.4 建立决策树
在收集的1000条数据中,游戏难易程度为“容易”、“中等”、“困难”3类目标的子集数分别为:S1=260,S2=450,S3=290。首先计算数据集S的熵值:
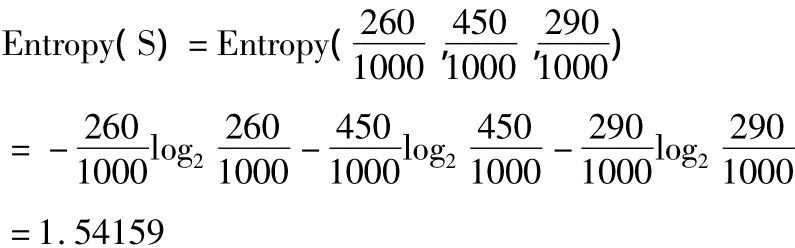
然后计算各个条件属性的信息增益,以条件属性“使用的步数a2”为例,分别计算它为little、center和much三个类别的熵,最终得到条件属性的信息增益值。
当地图大小为little时:
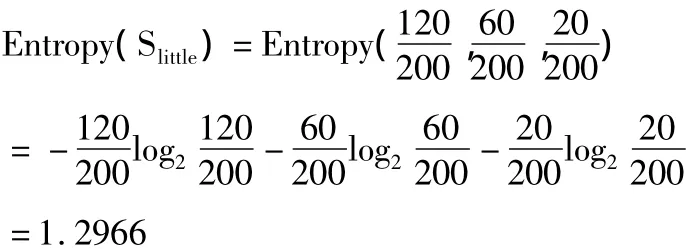
条件属性地图大小的信息增益为:
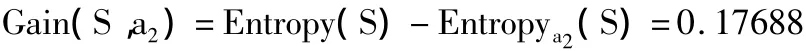
根据计算地图大小的信息增益的方法,同理,其他条件属性的信息增益分别为:
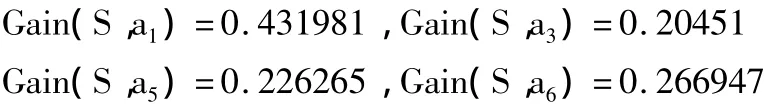
由以上对信息增益的计算结果可见,条件属性“是否通过该关卡a1”的信息增益最大,因此将该属性作为决策树的根结点进行测试;同时根据该属性可以将训练数据集分为2个分支。根据递归方法建立决策树,并对决策树进行后剪枝,得到最终的决策树,如图2所示。
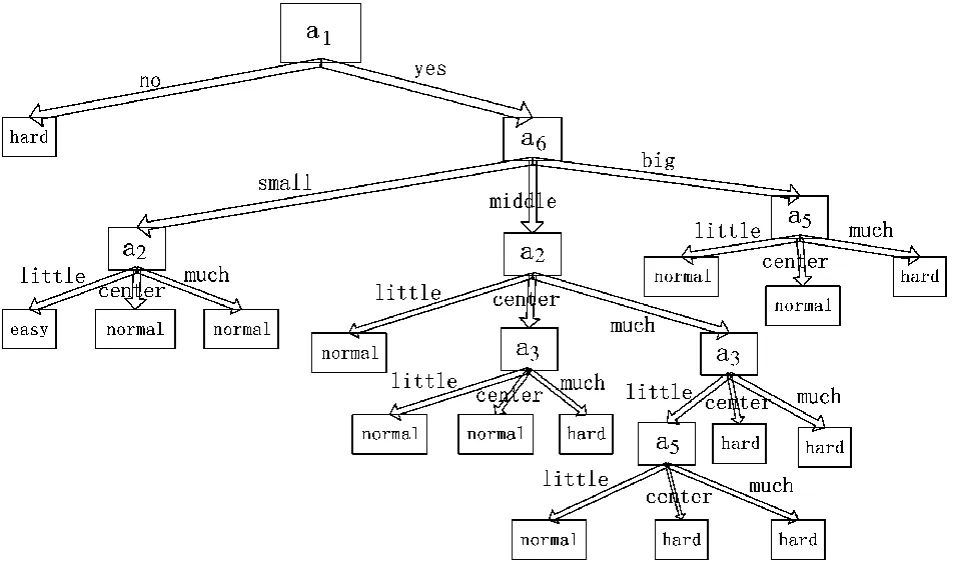
图2 判定游戏难易程度的决策树
使用得到的游戏玩法数据对决策树的识别情况进行测试,选取游戏难易程度为容易、中等和困难3个目标属性值样本各30个,共90个测试样本,得到的识别率如表3所示。
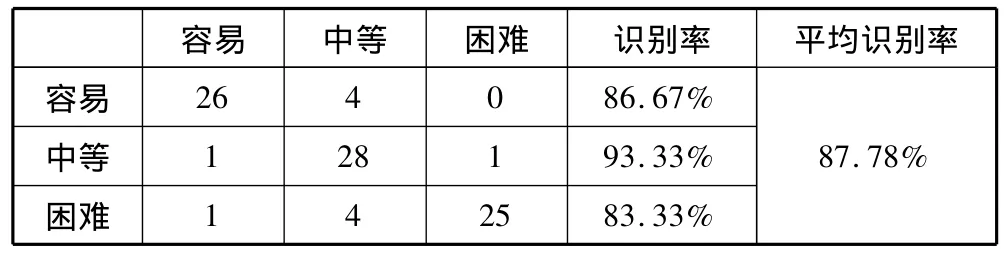
表3 决策树的识别率
由表3可得,建立的决策树可以很好地完成对游戏难易程度的识别。
2.5 游戏玩家数据的融合
数据融合是指对多组传感器数据进行多级别、多方面、多层次的处理和组合,从而产生新的有意义的信息[15],这里的传感器是广义的,可以指各种数据获取系统和相关数据库等,在本文中指玩家玩每一个关卡所得到的数据。
在数据融合模块中,主要的目的就是融合玩家在多个关卡中的数据,得出一条新的、可以更有效地代表玩家行为的数据。根据关卡所得到的数据的特点,选择D-S证据理论作为数据融合的算法[11]。由于每一个关卡得到的数据不能直接利用数据融合算法进行融合,首先,需要对数据进行处理:信息增益代表了属性特征对系统的重要性,因此,系统利用信息增益对关卡数据进行处理,定义关卡数据为D[n],数据挖掘得到的各属性的信息增益为Gain[n],各属性的最大值为 Max[n],处理后的关卡数据为 Data[n],那么处理规则为:
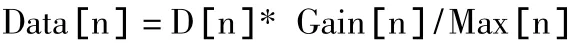
其中,n为属性的个数。
然后,利用D-S证据理论算法对数据处理进行融合后得到一条新的更能代表玩家行为的数据。最后,把该条数据转换成一条与关卡数据格式相同的数据,用于关卡信息生成模块并且把该条数据再放入训练数据中以完善训练数据集。
2.6 关卡信息生成模块
在关卡信息生成模块中,利用数据融合模块生成的新的关卡数据作为决策树的测试数据,从而得到游戏对于玩家的难易度,然后根据难易度来设置关卡信息。设置的规则为:如果难易度结果为容易,则提高关卡的难度,即关卡中箱子的个数和障碍物的个数都加1;如果难易度结果为中等,则保持关卡的难度,但是要改变关卡的一些数据信息,即改变箱子和目的地的位置以及地图的形状;如果难易度结果为困难,则降低关卡的难度,即关卡中箱子的个数和障碍物的个数都减1。最后,根据关卡信息自动生成新的更适合玩家的关卡,如图3所示。
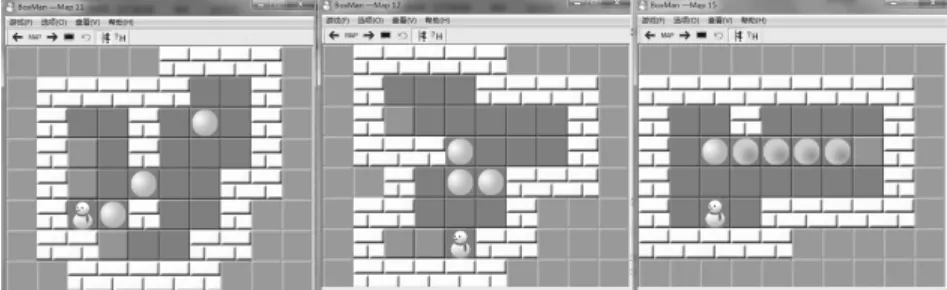
图3 自动生成的关卡图
自动生成关卡的原则为:游戏程序中提供没有箱子、障碍和目的地的关卡形状模板库,首先根据得到的难易度选择模板,然后根据关卡信息向关卡模板中放置箱子、障碍物和目的地,最终得到一个新的关卡。
3 实验结果与分析
为了验证系统的有效性,本文以经典的推箱子游戏为例进行实验。关卡数据包括7个属性,通过对部分玩家测试得到了1000条关卡数据。对于传统的游戏中100个关卡都需要关卡设计师逐一设计,会花费大量的时间和资本;而利用本文的关卡自动生成系统,只需提前设计好几个关卡,其余通过该系统动态生成,大大降低了开发时间和成本。
针对游戏的可玩性,本实验通过对50个玩家进行测试,每个玩家分别玩传统的推箱子游戏和基于关卡自动生成系统的推箱子游戏,记录玩家通过的关卡数,结果如图4所示。
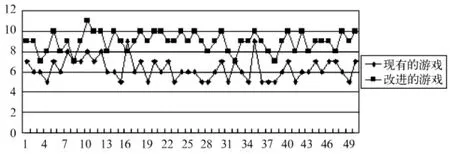
图4 实验结果
图4中,纵坐标为玩家通过的关卡数,横坐标为玩家编号。由图中数据可得,基于关卡自动生成系统的推箱子,更适合玩家的需求。因此,基于数据挖掘和数据融合的关卡自动生成系统可以有效提高游戏的可玩性。
4 结束语
传统的推箱子游戏,由于关卡信息是由设计师提前设计好的,所以,游戏开发花费大量的时间和成本并且可玩性比较差。实验证明,本文提出的基于结合属性约简的数据挖掘和数据融合技术的场景自动生成系统可以有效降低开发成本并提高游戏的可玩性。下一步的工作是进一步研究该系统在其他类型游戏中的效果。例如,在《暗黑》的地下城中的某个宝箱所呈现的道具取决于玩家打开宝箱的时间。这种生成技术可以被运用到游戏制作的大部分过程中,如法术制作、道具制作、武器制作、NPC对话系统以及屏幕上呈现的法术效果等。
[1] 王川.2011年中国网络游戏黏着度及寿命调查报告[EB/OL].http://zdc.zol.com.cn/246/2468679.html,2011-08-31.
[2] 王璿,高社生,赵霞.数据挖掘与数据融合集成系统模型[J].计算机工程与应用,2006,42(18):181-183.
[3] 何剑斌,郑启伦,彭宏.数据融合与数据挖掘的集成研究[J].计算机工程与应用,2002,38(18):204-206.
[4] Andy Clayton.Introduction to Level Design for PC Games[EB/OL]. http://www.loc.gov/catdir/toc/ecip041/2003006916.html,2007-06-24.
[5] 邢东山,沈钧毅,宋擒豹.从Web日志中挖掘用户浏览偏爱路径[J].计算机学报,2003,26(11):1518-1523.
[6] 袁霖,王怀民,尹刚,等.开源环境下开发人员行为特征挖掘与分析[J].计算机学报,2010,33(10):1909-1918.
[7] 杨育彬,李宁,张瑶.基于社会网络可视化分析的数据挖掘[J].软件学报,2008,19(8):1980-1994.
[8] 姜文瑞,王玉英,郝小琪,等.决策树方法在气温预测中的应用[J].计算机应用与软件,2012,29(8):141-144.
[9] 徐宝文,张卫丰.数据挖掘技术在Web预取中的应用研究[J].计算机学报,2001,24(4):430-436.
[10] 连一峰,戴英侠,王航.基于模式挖掘的用户行为异常检测[J].计算机学报,2002,25(3):325-330.
[11] 张晓明,王航宇,黄达.基于D-S证据理论的多平台协同数据融合[J].计算机工程,2007,33(11):242-243,246.
[12] 刘钦启,马玉祥,郝红侠.基于数据融合和数据挖掘的网络故障管理系统[J].微电子学与计算机,2006,23(6):74-76,80.
[13] 巫莉莉,徐艾洁,张波,等.基于数据融合和数据挖掘的网络教学资源体系[J].重庆工学院学报:自然科学版,2008,22(6):170-172,175.
[14] 程一伦.基于粗糙集的数据离散化方法研究[D].长春:吉林大学,2009.
[15] 陈超,李俊,孔德光.基于数据融合的源代码静态分析[J].计算机工程,2008,34(20):66-68.
猜你喜欢
数学大王·中高年级(2023年3期)2023-03-12 03:55:19
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
汽车观察(2018年10期)2018-11-06 07:05:26
电子制作(2018年16期)2018-09-26 03:27:06
童话世界(2017年11期)2017-05-17 05:28:31
中国汽车界(2016年1期)2016-07-18 11:13:32
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
物理通报(2015年9期)2016-01-12 06:41:46
新高考·高一物理(2015年8期)2015-11-26 08:07:04
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
