
Hadoop 平台下的并行Web 日志挖掘算法
2013-06-10 07:06周诗慧
计算机工程 2013年6期
周诗慧,殷 建
(山东大学(威海)机电与信息工程学院,山东 威海 264209)
1 概述
随着Internet的发展,Web已成为全球最大的数据仓库。Web 所蕴含的数据不仅是网页上的文字和图片,还包括网络的拓扑信息、网页的链接结构以及用户对网站的访问和操作记录。然而,如何从Web 的海量数据中挖掘出蕴含其中的信息,一直是国内外学者研究的热点。将传统的数据挖掘技术应用于Web 领域的技术即Web 挖掘[1]。Web 挖掘按应用可以分为3 类:Web 内容挖掘,Web 结构挖掘,Web使用挖掘[2]。Web 内容挖掘是从Web 的网页内容中提取知识;Web 结构挖掘从Web 的组织结构和链接关系中挖掘出信息;Web 使用挖掘是利用Web 日志发现用户的兴趣模式,因此,Web 使用挖掘也称作Web 日志挖掘。在通常情况下,相对于挖掘内容和结构,挖掘用户的使用更有意义。
目前对Web 数据挖掘的研究主要集中在对挖掘算法的改进上,这虽然能够提高系统的有效性,但却缺乏对系统计算能力的改善[3]。当面对海量的Web 数据时,基于单一节点的Web 挖掘算法将面临时间和空间复杂性上的瓶颈。想要解决这一问题就需要将并行计算应用到Web 挖掘中,但并行处理系统是由多个节点组成的,这就会存在节点失效、负载不平衡等问题,而且传统的并行处理模型在易编程和易扩展方面表现欠佳。
Hadoop 是Apache 下的一个开源框架,是一个更容易开发和并行处理大规模数据的分布式计算平台。同时并行计算存在的问题如负载平衡、工作调度、分布式存储、容错处理、网络通信等也都由Hadoop 负责解决。因此,本文对Hadoop 进行介绍,包括HDFS 和MapReduce 的组成结构和工作原理,并设计一种基于Hadoop 的Web 日志并行挖掘算法。
2 Hadoop 相关技术
Hadoop 是一个集成了分布式文件系统HDFS 和大规模并行计算模型MapReduce 的开源框架[4]。Hadoop 具有如下优势:(1)可伸缩性,能够处理petabytes 级数据,并可以无限扩充存储和计算能力。(2)可靠性,可以维护同一份数据的多份副本并自动对失败的节点重新分布处理。(3)高效性,Hadoop 能并行地处理数据。同时,Hadoop 也是低成本的,因为它对硬件的要求不高,所以可以运行在普通的微机集群上。
2.1 Hadoop 的分布式文件系统
Hadoop 的分布式文件系统(Hadoop Distributed File System,HDFS)由 1 个 NameNode(管理节点)和 N 个DataNode 数据节点(数据节点)组成,这2类节点采用Master/Slave(管理者/工作者)模式运行[5]。其中,NameNode 充当Master 节点,DataNode 充当Slave 节点。其底层实现原理就是当有输入文件提交到Master 节点后,Master 将输入文件切割成多个Block 并为每个Block 拷贝数份副本,拷贝的副本数目是可配置的,然后将这些Block 分散地存储在不同的Slave 节点上,从而实现容错处理。NameNode 是整个文件管理系统的核心,负责维护文件系统的NameSpace(名字空间),NameSpace 上记录着输入文件的分割情况、每个Block 的存储位置以及每个Block 所在节点的状态信息。DataNode 是整个文件系统的实际工作者,它们负责存储Block,并定时向NameNode 汇报存储块的状态信息[6]。
2.2 MapReduce 并行计算模型
MapReduce 编程模式解决了传统并行计算在易编程性上的瓶颈,使得程序员更容易开发分布式并行计算程序。程序员只需要编写2 个函数:Map 函数和Reduce 函数,这2 个函数的输入和输出都是键值对集合。Map 对输入的<key,value>集合进行处理,生成中间结果<key',value'>集合。MapReduce 底层自动将具有相同key'值的键值对中相应的value'进行合并,生成<key',List[value']>集合,并将其作为Reduce 函数的输入。Reduce 函数再进一步处理生成新的<key'',value''>集合作为输出文件。
Hadoop 下的MapReduce 编程模式同HDFS 一样采用Master/Slave 架构,由主控节点(JobTracker)和计算节点(TaskTracker)2 种节点组成。JobTracker 节点负责任务的调度和对TaskTracker 节点的管理,TaskTracker 节点负责执行Map 和Reduce 任务。TaskTracker 每隔一段时间就会向JobTracker 发送信号来证明其处于正常工作的状态,JobTracker 就会将该TaskTracker 放入空闲列表。
3 基于Hadoop 的Web 日志挖掘算法
3.1 系统架构
在一个Hadoop 集群中,HDFS 的管理节点和Map Reduce 的主控节点可以使用同一台机器,也可以分别使用不同的机器。同样数据节点和计算节点也可以共用同一台机器。本文实现的基于Hadoop 的Web 日志挖掘系统架构如图1 所示。其中,Master 节点负责NameNode 和JobTracker节点的工作;Slave 节点既要用来存储数据块还要执行Master 节点所分配的映射和化简任务。

图1 基于Hadoop 的Web 日志挖掘系统架构
日志收集服务器每天定时将待处理的日志导入Master节点。Master 节点将原始的日志文件作为输入文件切分成M 份数据块,分散存储在不同的Slave 节点上并更新NameSpace。初始化完成后,Master 节点根据MapReduce底层实现的调度算法为空闲列表中的每个Slave 节点分配Map 或Reduce 任务。Slave 节点接收到任务后,首先将运行程序所需的文件和任务文件从NameNode 复制到本地文件系统。然后创建实例来运行任务。Map 任务生成的中间结果保存在本地Slave 节点上。MapReduce 底层将Map 生成的中间结果合并后,再分发到各个被分配执行Reduce 任务的Slave 节点上作为输入文件。最后Master 节点将各个Reduce 任务的结果进行合并作为最终输出文件发送到结果展示服务器。
3.2 数据预处理
所有服务器响应的请求都会被记录在Web 日志中,同一时间内服务器可能为成百上千个用户会话服务,同一用户会话的记录是不连续的。因此,必须对Web 日志进行预处理,将分散的、杂乱的日志记录整理成用户会话文件。数据预处理技术可以改进数据的质量,从而有助于提高其后的挖掘过程的精度和性能[7]。Web 日志预处理主要包括以下几步:数据清理,用户识别,会话识别,路径补充和事务识别[8]。设L={l1,l2,…,ln}为用户访问集合,L 中的每个元素都代表一条日志记录。令l∈L,用l.uid 表示用户标识,l.url 表示用户所访问的页面地址,l.time 表示访问时间。设D={t1,t2,…,tm}为用户事务集,任意事务t 即表示一个用户会话。令t=<uidt,urlt>,t∈D。其中,urlt代表用户ID 为uidt的用户一次会话下浏览的页面序列,令:

3.3 基于Hadoop 的FP-growth 算法
目前Web 日志挖掘算法主要有基于关联规则的Apriori算法、最大向前访问路径(Max Forward Path,MFP)算法、基于聚类分析的k-means 算法及相应的改进算法等。其中,基于逐层搜索迭代方法的改进Apriori 算法被广泛应用于Web 日志挖掘系统中。然而Apriori 算法通过LK-1项集生成候选集Ck的思想导致当数据量巨大的时候可能产生海量的候选项集,另外可能重复地扫描数据库以匹配检查候选集合。这2 种情况会影响Apriori 算法的执行效率和性能,带来巨大的网络传输开销。采用分治策略的频繁模式增长算法FP-growth 能够做到不依靠产生候选项集的方式进行关联规则挖掘[9],从而解决了Apriori 算法的不足。FP-growth算法是近十年来数据挖掘方向最热门的研究主题之一,在序列模式挖掘、结构模式挖掘、关联挖掘等方面都起着重要作用[10]。
使用关联规则的挖掘算法一般分为2 步:
(1)发现所有的频繁项集:任意频繁项集A 的支持度计数都要大于等于预定义的最小支持计数(这里采用的是绝对支持度,代表在事务集T 中包含项集A 的事务t 出现的次数。相对支持度则表示A 在事务集中出现的概率)。项集A的支持度计数表示为:Support _ count (A)。
(2)由频繁项集产生强关联规则:规则A ⇒ B必须满足事先定义好的最小支持计数 Support (A ⇒B)和最小置信度Confidence (A ⇒B),其中:
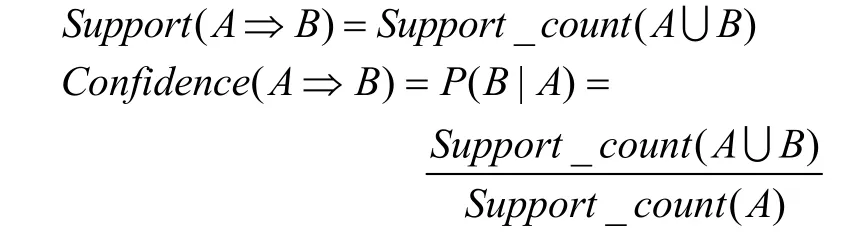
本文提出基于Hadoop 的Web 日志挖掘算法——并行FP-growth 算法,将以上2 步交由Master 和Slave 节点上共同完成。算法的具体描如下:
(1)计算出全局频繁1-项集,这一步可以由一对Map/Reduce 完成。
1)将事务集D(即预处理后得到的形如<uidt,urlt>的键值对集合)分割成M 份分发到不同的Slave 节点上。由Map函数识别出本地事务集中的每一个url,这里的url 就是挖掘算法中的项。将每一个url 作为输出键值对的key,对应的value 设为1。
2)Reduce 函数将具有相同key 值的value 值进行累加得到每个url 出现的次数,然后删除那些出现次数小于最小支持计数的url。合并所有Reduce 的输出文件即得到全局频繁1-项集的集合F_list。将F_list 按支持计数的降序排列得到L_list。将L_list 分为r 组:subL_list1,subL_list2,…,subL_listr。
(2)根据L_list 的分组情况对事务集重新分组。将本地事务集相应地划分为subD1,subD2,…,subDr 并发送给r 个Reduce 任务。然后对各个子事务集进行并行FP-growth 挖掘。这步也由一对Map/Reduce 完成。
1)由Map 函数来完成事务集的分组操作。该Map 函数扫描本地事务集中的每个事务t,如果lkt.url∈subL_listi,1≤i≤r,则将事务t 添加到subDi 中。Map 函数伪码如下:

2)Reduce 函数收到子事务集subDi 后,创建subDi 的频繁模式树并对其进行挖掘。该 Reduce 中调用的方法insert_tree(创建树)和FP-growth(挖掘树)就是传统的创建和挖掘频繁模式树的算法。该Reduce 中调用的挖掘树算法跟传统算法相比,增加了一个参数subL_listi,这是因为传统的FP-growth 算法是扫描全局的L_list,而本文只需要扫描局部subL_listi。Reduce 函数的伪码如下:


3)根据生成的频繁模式集和置信度公式推出关联规则。
基于Hadoop 的并行FP-growth 算法可以有效地将一棵FP 树分成多个小FP 树,在多台Slave 节点上并行计算,然后对各个Slave 节点上的挖掘结果取并集,得到目标的频繁模式全集,最终根据频繁项集的支持度计数和置信度推出关联规则。
4 实验结果与分析
为验证本文算法的性能,本文实验使用加速比作为评估指标。加速比是指同一任务在单处理器系统和并行处理器系统中运行消耗时间的比率,常用来衡量并行处理的性能和效果。实验测试了在不同数目节点、不同大小数据集(分别为1 MB、1 GB 和2 GB)下本文算法的加速比,如图2所示。

图2 加速比测试结果
可以看出,当数据量较小时,加速比小于1,说明并行处理的时间反而大于单机的执行时间,这是因为基于Hadoop 的算法需要传输中间文件且Hadoop 框架的启动、调度都需要一定的执行时间,而数据量较小时执行算法本身所需的时间并不长,所以当数据量较小时Hadoop 平台所消耗的时间比重偏大,从而导致了并行处理时间大于单机执行时间。然而随着数据量的增大,并行算法在执行效率上就体现出了优势。此外,随着节点数目的增加,算法的执行效率也得到了相应的提高,不过当节点数目大到一定程度时,加速比增长率的提高并不多,因此,可根据数据集的大小选择合适的节点数目。
该实验证明了并行FP-growth 算法优于串行FP-growth算法,并且随着数据量的增大,并行FP-growth 算法的优势也越来越明显。
5 结束语
本文在Hadoop 集群平台下设计并实现了Web 日志挖掘的FP-growth 算法。实验结果证明,该算法适用于大规模数据的挖掘应用。Web 日志挖掘具有非常广泛的应用领域,本文的并行Fp-growth 算法已经得到Web 日志中频繁页面序列。根据这一结果,下一步研究将对网站的访客进行个性化推送,当访客浏览了一组频繁页面序列中的大部分页面时,可以向其推送该组频繁模式的剩余页面。同时,也可以得到页面之间的强规则,进而分析网站模块之间的关联,对改善网站的链接结构提出相关意见。
[1]费洪晓,覃思明,李文兴,等. 基于访问兴趣的Web 用户聚类方法[J]. 计算机系统应用,2010,19(4): 62-65.
[2]王 凯,渠 芳,王 辉. 利用Web 挖掘技术实现个性化推送服务[J]. 情报杂志,2006,25(11): 86-88.
[3]程 苗,陈华平. 基于Hadoop 的Web 日志挖掘[J]. 计算机工程,2011,37(11): 37-39.
[4]王振宇,郭 力. 基于Hadoop 的搜索引擎用户行为分析[J].计算机工程与科学,2011,33(4): 115-120.
[5]赵卫中,马慧芳,傅燕翔,等. 基于云计算平台Hadoop 的并行K-means 聚类算法设计研究[J]. 计算机科学,2011,38(10): 166-168,176.
[6]刘永增,张晓景,李先毅. 基于Hadoop/Hive 的Web 日志分析系统的设计[J]. 广西大学学报: 自然科学版,2011,36(Z1): 37-39.
[7]Han Jiawei,Kamber M. Data Mining Concepts and Techniques[M]. [S. l.]: MorganKaufmann Publishers,2002.
[8]赵立江,何钦铭. 一种个性化Web 推荐系统的设计与实现[J]. 武汉理工大学学报,2004,28(5): 681-684.
[9]谈克林,孙志挥. 一种FP 树的并行挖掘算法[J]. 计算机工程与应用,2006,42(13): 155-157.
[10] Chen Min,Gao Xuedong,Li Huifei. An Efficient Parallel FP-growth Algorithm[C]//Proc. of Conference on Cyberenabled Distributed Computing and Knowledge Discovery.Zhangjiajie,China: [s. n.],2009.
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
电脑爱好者(2020年19期)2020-10-20
河南水利年鉴(2020年0期)2020-06-09
电子制作(2019年13期)2020-01-14
计算机工程(2014年6期)2014-02-28
长春大学学报(2013年8期)2013-06-21
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
