
大数据分析(BDA)及其在情报领域的应用
2013-06-10 03:25:14张春磊杨小牛
中国电子科学研究院学报 2013年1期
张春磊,杨小牛
(中国电子科技集团公司第36 研究所,浙江嘉兴 314033)
0 引 言
2012 年3 月29 日,美国联邦政府发布公告称将开发“大数据研发项目”,以最大限度地利用规模飞速增长的数字化数据。一石激起千层浪,“大数据”这一并不是非常新的术语再次引起了世界各方的高度重视。
而大数据研究的核心并非数据的“量”有多大,而是如何有效、有序、系统地处理(包括访问、收集、保护、存储、管理、分析、挖掘、共享、辅助决策等)大量数据。因此也衍生出一个非常重要的研究领域——大数据分析(BDA)。
1 大数据简述
有关大数据,目前定义较多。通常来讲,大数据指的是规模超过了当前典型数据库软件工具获取、存储、管理、分析能力的数据集。可以看出,这种描述实际上是一种动态的描述,因为当前的技术总是在不断发展。严格来说,“大数据”更像是一种策略而非技术,其核心理念就是以一种比以往有效得多的方式来管理海量数据并从中提取价值。可以从如下4 个方面(“4 V”)来阐述“大数据”理念。
(1)数据类型多样(Variety)。即,所处理的对象既包括结构化数据,也包括半结构化数据和非结构化数据。
(2)数据处理高速(Velocity)。即,各类数据流、信息流以高速产生、传输、处理。
(3)数据规模海量(Volume)。即,所需收集、存储、分发的数据规模远超传统管理技术的管理能力。
(4)数据价值密度低(Value)。即,大数据中的价值密度很低,因此也增加了价值挖掘的难度。
由于海量数据中既包括结构化数据也包括非结构化数据,因此,分布式计算与分布式文件管理即成为了“大数据”策略的核心。
2 大数据分析(BDA)
如上所述,大数据分析中的“分析”实际上是一个广义的概念,包括了采集、恢复、存储、管理、挖掘等,然后通过分发、知识共享等手段最终实现对决策的支持。
2.1 BDA 概述
目前有关BDA,尚无明确定义。简而言之,就是将先进的分析技术用于大数据集。因此,BDA 主要关注两方面内容:大数据本身及分析技术本身;如何将二者有机融合,以实现从大数据中提取有价值的情报并用以辅助决策之目的[1]。
具体来说,可用于BDA 的分析技术包括了预测分析、数据挖掘、统计分析、复杂结构化查询语言(SQL)等,以及那些可以支持大数据分析的数据可视化、人工智能、事实聚类、文本法分析、自然语言处理、数据库等相关技术。可以看出,大多数BDA 技术其实均可归入“发现分析”或“发掘分析”技术的范畴,而发现、发掘情报也是BDA 的主要目标之一。
可以看出,实际上很多BDA 技术并非什么新技术,只是由于其非常适用于“大数据”这一新兴对象,因此,重新“焕发青春”。
2.2 BDA 关键技术与工具及其发展趋势
2011 年,相关机构进行了“大数据分析工具、技术与趋势”调查[1]。该调查列出了几乎所有与大数据分析相关的工具与技术,其中包括如下几类:新兴的,如云计算、MapReduce、复杂事件处理(CEP);不是新兴但适用于大数据分析的,如数据可视化、预测分析;已有且比较成熟的,如统计分析、手工编码的SQL。
此次调查可相对比较客观地展现BDA 关键技术与工具及其发展趋势。相关技术与工具的当前使用情况及未来发展趋势,如图1 所示。从图中可以看出,隶属于第一组的工具与技术基本上可以代表BDA 关键技术与工具的发展趋势,即,高级分析技术与工具、高级数据可视化技术(ADV,未来发展势头最为迅猛的技术)、实时仪表盘、内存内数据库和非结构化数据分析技术等。
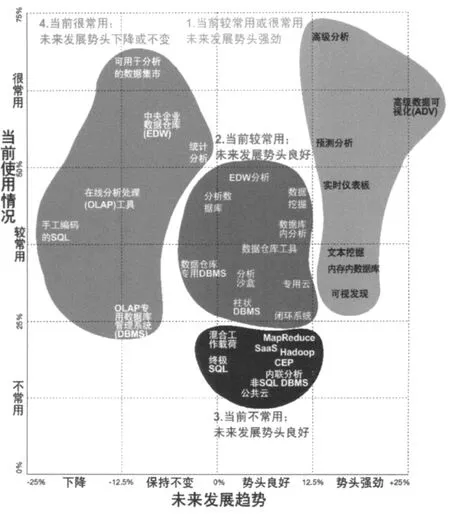
图1 BDA 技术与工具的当前使用情况及未来发展趋势
2.3 BDA 浅析
从功能角度来讲,BDA 实现了从大数据到情报(即,价值)的转换,而这种转换本身与大数据的“4 V”特性分不开。转换过程必须采用各种BDA平台、工具,如,阿帕奇Hadoop。Hadoop 技术与平台使得大数据分析人员可以对原始数据进行分析,并得到支持决策所需的情报。
考虑到大数据的一些新特性,BDA 也必须采用一些新的方法和流程来实现情报提取。以利用Hadoop 技术与平台实现BDA 为例,典型的BDA 实施流程与常用的OODA 环(观察、定位、决策、行动)有些类似,包括大数据访问(大数据聚集(大数据分析(决策(行动等环节,且并最终实现人在环路或人不在环路的闭环。
从分析对象来看,BDA 主要分析静态大数据(big data at rest)和动态大数据(big data in motion)。
3 BDA 在情报领域内的应用研究
著名的非SQL(noSQL)数据库开发公司Objectivity 所开发的Objectivity/DB、InfiniteGraph(IG)等大数据分析工具是典型的可用于情报领域的工具[3~6],下面主要以这两种BDA 工具为例介绍BDA 技术在多源情报融合以及对象关系分析过程中的应用情况。
3.1 BDA 用于多源情报融合
BDA 用于多源情报融合的主要任务是通过对海量、多源、多类型数据(如,文本、图片、视频、话音等)进行相关,将其转换为用户所需的各类专用情报(如,通信情报(COMINT)、电子情报(ELINT)、雷达情报(RADINT)、遥测情报(TELINT)等)。
Objectivity/DB 大数据分析工具在美空军网络中心协同目标瞄准(NCCT)项目中的应用场景如图2 所示。图中,在机器到机器(M2M)接口的支持下,Objectivity/DB 实现了自动多源情报融合。该工具在多源情报融合方面主要解决的问题包括复杂数据索引与搜索、多源情报集成、异构数据库联合等。
3.1.1 多源情报集成
多源情报融合所面临的首要问题就是如何实现多源情报集成。

图2 Objectivity/DB 在NCCT 中的应用场景
借助于其分布式风险管理与跟踪系统,Objectivity/DB 可实现地理空间情报、气象情报、风险事件跟踪与后勤情报等的集成。它通过检验规划行动与实际行动的偏离度来确保情报集成按照强制性规则来实施,这种校验通过一个专家知识库来实现。用户实现如下功能:显示、浏览、放大数据;产生简报文件;查看任务需求;查看、分析、仿真一个规划;与其它规划人员进行电视电话会议。
3.1.2 复杂数据索引与搜索
作为《藤野先生》和《〈呐喊〉自序》的作者,鲁迅留给后来者的不仅仅是文本,还有他本人赋予文本的意义。固然,从阐释的角度来说,这种文本与意义的绝对统一仅仅存在于鲁迅自己的意识中。但作为后来者,如果不在关注文本的同时关注鲁迅为文本赋值的过程,就一定会遇到阐释上的困难。因为鲁迅所留下的不仅仅是一个故事,还有关于这一故事的意义。
多源数据融合所面临的第二个问题是复杂数据索引与搜索。
传统上,从多个同类源获取数据比较容易,例如,利用开放式数据库互连来访问多个关系数据库中的数据、采用统一的结构化文件格式等。
然而,复杂数据(如,来自计算机辅助设计系统、生物信息系统或遥感传感器的数据)的存储和操纵要困难得多。因为传统搜索语言不具备搜索声纹、图片、指纹、实体模型、声呐、雷达等多源数据。这些复杂数据类型可以在关系数据库中表示为二进制大对象(BLOBS),这些数据并非随时都可翻译成通用数据定义语言(如XML)、相关数据集通常非常庞大,且数据集之间的关系数量也非常庞大。这些数据通常位于结构化文件内,且仅能借助于人类或编码知识来索引。通常这些数据库都会采用“蛮力”搜索来从这些文件中找到可识别的文本串。利用一个统一的数据统一层,Objectivity/DB 大数据分析工具可具备索引各种复杂数据及其关系的能力。
在大型数据库搜索方面,Objectivity/DB 采用一种并行搜索引擎(称为“并行查询引擎”)来实现。该引擎可快速确定可能包含所查询对象的“数据容器(data container)”,然后利用用户可配置的线程数来进行迭代,直到找到目标数据容器。
3.1.3 异构数据库联合
实现异构数据库联合是多源情报融合所面临的又一问题。
Objectivity/DB 工具采用单一逻辑视图来实现异构数据库联合。其存储管理器可管理、构造所有数据库;此外,在此体系结构上还可以增加传统的数据库管理系统网关,该网关可以采用开放式数据库连接(ODBC)或各种中间件来为对象管理器提供请求服务。
单一逻辑视图具备如下优点:数据始终处于现有系统的控制之下;面向对象的应用程序只要使用一个单一的应用程序接口(API)即可访问异构数据源;经常需要遍历的对象、关系可以表示为数据库中的代理,这样即可消除昂贵的联合运算成本。
3.1.4 情报分析
Objectivity/DB 工具进行情报分析的流程,如图3 所示,可以看出,它通过采用一个协同工作环境构建了一个情报分析系统。图中:“Web 使能的协同工作环境”可支持各种操作,包括建模、规划、评估、决策支持等;软件代理负责根据假定来对开源信息进行分类;插件架构是开放式、自适应的。
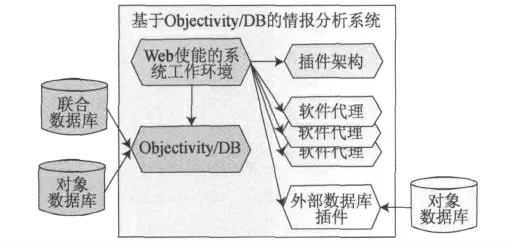
图3 Objectivity/DB 情报分析流程
3.2 BDA 用于关系分析
随着网络中心战(NCW)不断深入人心,各类电子信息系统之间几乎都已经或正在朝着网络化运作方向发展,例如,网络化通信系统、组网雷达系统、一体化组网探测系统等均属此类。因此,在进行情报分析的过程中仅仅分析来自单个节点(即,点)的情报已不足以支撑决策,而还必须对各单元之间的关系(即,线和面)进行分析。
总之,关系分析也是BDA 在情报领域中的主要应用之一。同样,Objectivity 公司在该领域也颇有建树,其InfiniteGraph(IG)分布式图数据库的主要功能之一就是进行关系分析,并最终生成支持决策所需的综合情报。
3.2.1 IG 数据库的体系结构概述
IG 数据库的构建基于一种高度可扩展的分布式数据库体系结构,其中,数据和数据处理在网络中都采用分布式结构,如图4 所示。单个图数据库可以进行分割,并分布在多个磁盘卷和机器中,这样,即可实现跨机器边界的数据查询。同样的数据库客户端可以通过本地访问或通过本地网络访问图数据库。

图4 IG 数据库体系结构
图中相关模块功能如下所述:(1)锁定服务器负责处理来自数据库应用程序的数据库读写锁定/解锁请求,即,负责整个数据库访问管理。与开源数据库访问不同,对IG 数据库的访问在建立数据库实例时不受控制,而是在事务级进行控制。(2)每台装有数据库的机器中海有一个单独的数据服务器进程,这些进程可通过本地或远程方式来访问磁盘卷上的数据。(3)数据服务器负责处理来自分布式图数据库的远程数据库应用程序请求。
3.2.2 IG 用于关系处理
IG 主要通过结合一系列数据库技术和图论技术来实现对相关情报的关系分析。它利用图的顶点和边来分别表示要素(包括事件/地点、人员/组织、行为)和要素之间的关系,并实现“连点为线”(基于某种规则实现点到线的映射),最终通过对点、线的分析来产生预期分析成果。这种处理方法与传统数据库有着很大不同:传统数据库按照要素而非按照节点(顶点)、关系(边)来存储、处理数据。
IG 关系处理流程如图5 所示。具体流程为:(1)对已经获取的情报数据库对象进行分类,确定对象属于节点还是属于连接关系;(2)对分类后的数据库对象进行“顶点↔边”映射,以形成数据关系图;(3)基于事先确定的规则对生成的数据关系图进行分析;(4)在分析的基础上得出辅助决策结论;(5)再通过各种可视化手段来将分析结果呈现给用户(图中未标出)。

图5 IG 关系处理流程
4 结 语
BDA 相关理论、技术、工具其实并非全新,其应用前景非常广阔。尤其是在情报领域内的应用,其前景更是一日千里、势不可当。当然,BDA 在情报领域中的应用仍有很多具体的理论、技术层面问题尚未解决。如,在赛博战领域如何利用BDA 实现赛博态势感知、在电子战领域如何利用BDA 实现有源与无源情报的分类与融合等。此外,随BDA 而来的诸多新类型情报也有待进一步研究,如,移动情报、云情报、社会情报、大数据情报等[7]。
[1]PHILIP RUSSOM. Big Data Analytics[Z]. tdwi.org. 4th season,2011.
[2]RICH GUTH.Deriving Intelligence from Big Data in Hadoop:A Big Data Analytics Primer[Z].Karmasphere.com. 2012.
[3]Achieving Real-Time Multi-INT Data Fusion:Using Objectivity/DB to Correlate Multiple Data Sources[Z/OL].(2012-11-15). http://www.objectivity.com.
[4]JOHN WALTERS.Big Data Technology In Defence Applications-Leveraging Graph Analytics[Z]. 2012.
[5]Using An Object Database In Intelligent Network Applications[Z/OL]. http://www.objectivity.com. 2006.
[6]Infinite Graph:The Distributed Graph Database[Z/OL].(2012-11-15). http://www.objectivity.com. 2012.
[7]Grow with Tomorrow's Intelligence...Today[Z]. http://www.scalable-systems.com. 2012.
猜你喜欢
现代装饰(2022年5期)2022-10-13 08:49:18
现代装饰(2022年4期)2022-08-31 01:42:30
现代装饰(2022年3期)2022-07-05 05:59:04
河北理科教学研究(2021年4期)2021-04-19 13:34:44
小太阳画报(2020年11期)2020-12-10 06:50:08
小太阳画报(2020年10期)2020-10-30 01:57:15
计算机教育(2020年5期)2020-07-24 08:53:00
读者(2017年18期)2017-08-29 21:22:03
小天使·一年级语数英综合(2015年10期)2015-10-14 06:37:12
计算机工程(2015年8期)2015-07-03 12:20:35
