
开源软件自动化评估证据框架*
2013-06-08 10:06王怀民史殿习朱沿旭
计算机工程与科学 2013年2期
袁 霖,王怀民,尹 刚,史殿习,朱沿旭
(1.信息工程大学电子技术学院,河南 郑州 450004;2.国防科学技术大学计算机学院,湖南 长沙 410073)
1 引言
开源软件OSS(Open Source Software)是指源代码可以自由获取的计算机软件。开源软件的开发者通过一种开放的软件许可协议保护其著作权,开源软件的源代码、文档、开发日志、缺陷等数据允许用户自由地使用、修改和传播,这种开放模式使开源软件功能和质量能够得到迅速提升。据统计,截止到2010 年12 月,仅SourceForge(sourceforge.net)一个开源社区中注册的软件项目就已经接近30万个,注册成员超过270万,超过4 600万用户在使用该社区的开源项目,每天的下载量超过200万次[1]。随着开源软件及其应用的飞速发展,互联网上已经形成了规模巨大、种类丰富的开源软件资源,这些资源以代码、构件等形式免费提供给全世界开发人员使用。高效、合理利用这些软件资源能够极大地提高自身软件系统开发效率以及提升软件项目质量。因此,如何从公共可获取的开源软件资源中快速获取和使用高质量、满足自身特定需求的开源软件已经成为了当前软件工程领域的研究热点。但是,现有针对开源软件的质量评估模型存在评估过程复杂、繁琐,评估结果主观性太强等问题,不能满足用户准确、快速、全面了解相关软件可信性的需求,难以适应互联网时代大规模开源软件项目评估的趋势[2]。
可信证据是指经过查证确定属实,并能够用来证明软件资源质量真实情况的证据[3,4]。开源软件在整个生命周期中产生了大量的、各种类型的数据,其中隐含了大量关于软件项目性能和质量方面的可信证据信息,这些信息能够真实地反映软件产生过程及其产品属性,有助于对软件进行评估和预测。本文通过对现有开源软件质量评估模型以及互联网上与开源软件质量相关的信息进行分析和总结,提出了一种开源软件可信性自动化评估证据框架。该框架适用于采用开源方式开发的软件可信评估,主要针对目前可自动化获取的可信证据,并且能够由用户自己选取其所关注的可信属性及证据。不同于已有模型的人工评估方法,该方法避免了手动评估繁琐、重复的过程,充分考虑了用户个性需求及软件的领域特征,提高了评估的灵活性。基于该证据框架设计的开源软件可信证据查询平台,将有益于克服当前评估方法繁琐、复杂、主观性太强等一系列问题,能够满足面向互联网的大规模开源软件的评估需求。
2 相关工作
现有大部分的软件度量模型都具有层次式结构,主要包括传统软件度量模型和开源软件度量模型两大类,传统模型主要关注产品本身及其软件开发过程,开源软件质量评估模型更关注软件项目的应用和社区支持情况。目前,已经存在的、具有较大影响力的开源软件质量评估模型主要有以下几种:
(1)OSMM 模型。OSMM(Open Source Maturity Model)[5]是由世界知名的Capgemini咨询公司发起并建立的。该模型主要基于如下假设:开源项目的质量与其成熟度成正比。其成熟度被分解为六个部分:产品软件、社区支持、文档、培训、产品整合度和专业服务。每个部分包含一个权重,评估人员对每个测度给出一个量化的分值,基于预先设定好的权重对其进行评分。尽管OSMM 评估方法相对较简单易用,但没有考虑软件自身产品的特征。
(2)OpenBRR评估模型。OpenBRR(Open Business Readiness Rating)模型[6]是由卡内基·梅隆大学的开放源代码研究中心、O′Reilly CodeZoo、SpikeSource及Intel公司联合发起的,其意图是使整个开源社区(包括企业用户和开发者)以标准和开放的方式对开放源代码软件进行评级,以方便对开源软件进行评估并促进其应用。Open-BRR 使用一系列较高级别的评估准则,如功能性、支持度、服务、应用范围以及开发过程等。评估的过程需要首先指定一组评估属性的关注程度,进而通过打分和加权方法给出整体分值。OpenBRR 方法在软件属性设定上较之OSMM 更加完善,但在具体测度的设置上仍存在较大问题。此外,该评估模型的属性测度设置过于主观,难以实现自动化。
(3)QSOS模型。QSOS(Qualification and Selection of Open Source Software)模型[7]主要用于对开源项目进行质量评估和选择。其评估和选择过程分四个重复的阶段:定义评估指标;收集来自于开源社区的评估指标,并对质量测度进行打分;基于用户需求定义备选质量测度;验证被评估软件对用户需求的符合程度,进而选出较符合用户需求的开源软件。QSOS模型的主要问题在于整个评估过程过于复杂,难于掌握。
3 数据源
开源软件在其整个生命周期内产生了大量的、各种类型的、公开的数据,这些数据主要包括以下形式:(1)项目开发过程日志;(2)源代码数据,包括项目开发的各个版本源代码信息;(3)各种项目相关的项目文档;(4)开发人员交互历史信息,如email、论坛等信息;(5)缺陷跟踪系统信息,包括项目所有缺陷当前状态、严重类型、修改等信息。这些数据能够真实地反映软件产生过程及其产品属性,有助于更好地理解软件开发过程的本质特征,对提高软件开发效率及其产品质量具有重要意义。研究发现,上述数据主要分布在软件的各种资源库及相关Web页面上。
3.1 软件资源库
软件资源库是指软件演化过程中产生和归档的所有制品,是软件生命周期中所有相关数据的总和,主要包括存储于软件控制管理系统、缺陷跟踪系统以及交互文档数据中的各种数据信息[7]。
(1)软件配置管理系统。软件配置管理系统对软件开发过程中的源代码数据及项目开发的相关文档进行管理和版本控制。目前,软件配置管理系统SCM(Software Configuration Management)主要可分为集中式与非集中式两种,其中集中式SCM 系统的代表是Subversion(SVN)和CVS(Concurrent Version System),非集中式系统的代表是GIT 和Mercurial。开源领域早期最常用的是CVS,但之后出现了从CVS向SVN 移植的趋势,近年来又开始从集中式系统向非集中式系统过渡。
(2)缺陷跟踪系统。缺陷跟踪系统BTS(Bug Tracking System)主要用于管理软件生命周期中出现的缺陷信息,对各种缺陷进行记录、状态跟踪。当前开源领域普遍使用的系统有Mazilla社区的Bugzilla系统、SourceForge的Tracker系统以及Debian社区的Debbugs系统。这些系统提供的功能大致相同,其中Bugzilla的可定制性更强,因为它允许在缺陷报告中扩展特定项目所独有的域,因此多数大型的独立项目都采用了Bugzilla系统。
(3)用户及开发人员邮件列表。邮件是实现人员在开源开发中进行信息交互的主要方式。邮件列表的工作原理是将一组开发者邮箱用一个邮件地址来描述,向邮件列表地址投递的邮件会被分发至该组中的所有邮箱。为实现订阅和消息归档等管理工作的自动化,开源社区通常会使用高级的邮件列表管理软件。网上的大多数开源项目通过Web界面的形式对外提供其邮件列表文档,部分开源项目还提供了能够将所订阅列表中的邮件归档的在线服务。已有研究表明,通过一定的数据挖掘及文本分析技术可以从中获取到与项目相关的大量有价值的信息。
3.2 基于Web的可信证据
除来自于开源软件项目资源库的各种数据外,目前还有大量与软件质量相关的信息分布在互联网Web页面上,如项目近期下载量、开发人员团队信息、版本发布信息、补丁发布信息、安全漏洞等。在上述介绍的开源软件质量模型中,如OpenBRR、QSOS、OSMM 等都分别使用了这部分信息作为开源软件的相关质量测度,但这些模型在应用过程中都以评估人员手动获取并分析这些信息为主要评估途径。这种方式造成了评估过程异常繁琐、复杂,即使专业人员对一个软件进行评估也要投入巨大的时间和精力,而有限的权威机构显然无法完成对大规模的开源软件进行评估的任务,这与互联网时代软件数量的飞速增长是非常不适应的。因此,自动化地定位和获取、合理组织和使用互联网上的开源软件质量信息,可以避免手动评估的繁琐重复过程,能够极大地提高评估效率,使得用户可以准确、快速、全面地了解相关软件项目的各种信息,有益于面向互联网的大规模开源软件评估系统的实现。
4 开源软件可信证据自动化查询平台
通过分析可以发现,开源软件资源库及相关项目页面信息中包含了大量与可信性相关的证据信息,其中很多证据信息可以通过自动化的方法获取到。本文在此基础上构造了基于互联网的开源软件可信证据查询平台,该平台实现的基本流程如图1所示,其基本步骤如下:
(1)目前,不论是软件各种资源库数据(如版本控制系统、缺陷跟踪系统、邮件库等)的镜像技术还是Web页面信息定位与提取技术都已存在较成熟的工具和方法[8~12]。通过使用bundle 或plugin形式的特定收集器,开源软件可信证据查询平台可对不同组织方式、不同数据结构的各种资源库信息和Web页面信息进行自动化的镜像和爬取。所有收集器镜像和爬取的原始数据被存入本地原始数据库,本地原始数据库支持增量式的镜像和存储策略,其主要功能是存储项目资源元数据,包括项目源代码文件、项目版本信息、Email消息、缺陷状态等相关数据。
(2)本地原始数据库中存储的数据主要是非结构化的原始数据,这些数据一般不能直接反映相关软件项目的可信属性,需要对其进行进一步的解析。可信证据收集与计算平台通过特定的数据解析器,将同一项目来自于不同数据源的数据解析成标准的、格式化的数据存储于本地结构化数据库,以便于进一步进行可信证据的挖掘与计算。
(3)可信证据计算工具集依据结构化数据库的更新信息,实时地对结构化数据库中的相关数据(包括代码提交行为、缺陷列表、角色分工、邮件列表)进行处理,采用聚类、相关性分析、频繁项挖掘以及机器学习等方法,将结构化数据库中的数据进行量化处理,形成用户可以直接感知的可信证据,存储至可信证据库。
(4)用户通过开源软件项目名称和版本号向可信证据平台提出查询请求,平台把证据库中所有关于该项目的证据信息返回给用户,用户根据这些证据信息可以迅速地对该项目进行准确、全面的了解。
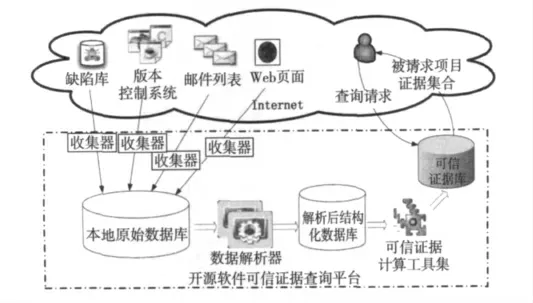
Figure 1 Trustworthiness evidence inquire platform for open source software based on Internet图1 基于互联网的开源软件可信证据查询平台
5 可信评估证据框架

Table 1 Trustworthness evidence framework表1 可信证据框架
实现基于互联网的开源软件可信证据查询平台的关键是一组能够准确反映开源软件质量信息的可信证据集合,并且所有可信证据项都可以在互联网上自动地获取。本文基于已有开源质量模型,通过对上述主要数据源的组织方式、数据结构进行深入研究后,提出了一种可自动实现的开源软件可信评估证据框架,如表1所示。
表1中,I18N/L10N 是指对项目进行国际化和本地化的任务,分别是单词“Internationalization”和“Localization”的缩写。
6 FireFox案例
本节将通过一个著名开源浏览器软件Mozilla Firefox(3.6.13)说明上述证据框架和可信证据查询平台的可行性,具体分析结果如表2所示。由表2的Firefox案例分析可知,由于该证据框架中的证据项能够从Web页面和各种项目相关资源库中自动地获取,因此可以极大地简化开源软件的评估过程,使得用户可以准确、快速、全面地了解其所需要项目的所有相关信息,并且在开源软件定位和搜索技术日益成熟的情况下,该证据框架中的可信证据项可以方便地添加和修订,使其不断准确和完善。需要指出的是,由于项目成熟程度、社区组织方式、开发人员任务分工等因素的影响,该证据框架不表示对任何一个开源项目均能完整地获取其所有证据项,当项目相关数据的获取受到限制时(如表2中平均文档更新频率和翻译人员存在个数)或许仅能够获取到其中部分的证据类型。为尽量克服这种情况,证据框架中的一些证据项存在互补情况,如项目下载量与所占市场比例,以及翻译人员与支持语言版本数等证据。因此,本文所提出的证据框架致力于尽可能全面地、自动地为用户提供相关软件的证据信息,而在最终的证据使用上,由用户根据自己需求灵活选取。
7 结束语
本文针对开源软件评估过程中存在的问题,构建了面向开源软件的可信评估证据框架,并基于该框架提出了一种面向互联网的开源软件可信证据查询平台的实现方法,利用该平台能够极大地提高开源软件可信评估的效率,使得用户能够准确、快速、全面地了解相关软件项目的各种信息。最后,以一个知名开源软件Firefox为例证实了该证据框架以及证据查询平台的可行性。该方法适用于采用开源方式开发的软件可信证据获取,不同于人工评估过程,该方法主要针对可自动获取的可信证据项,避免了手动评估繁琐重复的过程,可由用户自己选取其所关注的可信属性及其证据项,充分考虑了用户个性需求及软件的领域特征,提高了评估的灵活性,并能满足大规模开源软件评估要求。

Table 2 Firefox trustworthness evidence analysis表2 Firefox可信证据分析
[1]https:∥www.sourceforge.net.
[2]Wang Huai-min,Yin Gang.Software trustworthy evolution in cyber age[J].Communication of the CCF,2010,6(2):28-36.(in Chinese)
[3]TRUSTIE-STC.Software trustworthiness evidence framework specification(V2.0)[EB/OL].[2011-04-30].http:∥www.trustie.net/download/STEFS-2.0.pdf.
[4]TRUSTIE-STC.Software trustworthiness classification specification(V2.0)[EB/OL].[2011-04-30].http:∥www.trustie.net/download/STCFS-2.0.pdf.
[5]Golden B.Making open source ready for the enterprise:The open source maturity model[EB/OL].[2008-05-10].http:∥timreview.ca/article/145.
[6]Business Readiness Rating.Business readiness rating for open source[EB/OL].[2005-12-30].http:∥www.openbrr.org.
[7]QSOS.Method for qualification and selection of open source software(qsos)version 1.6[EB/OL].[2006-04-30].http:∥www.qsos.org.
[8]Keqdi H,Collard M L,Maletic J I.A survey and taxonomy of approaches for mining software epositories in the context of software evolution[J].Journal of Software Maintunauce and Evolution:Research and Practice,2007,19(2):77-131.
[9]Linstead E,Bajracharya S,Ngo T,et al.Sourcerer:Mining and searching internet-scale software repositories[J].Data Mining and Knowledge Discovery,2009,18(2):300-336.
[10]Godfrey M W,Zou L.Using origin analysis to detect merging and splitting of source code entities[J].IEEE Transactions on Software Engineering,2005,31(2):166-181.
[11]Ostrand T J,Weyuker E J.A tool for mining defect-tracking systems to predict fault-prone files[C]∥Proc of MSR'04,2.04:85-89.
[12]Gousios G,Spinellis D.A platform for software engineering research[C]∥Proc of MSR'09,2.09:31-40.
附中文参考文献:
[2]王怀民,尹刚.网络时代的软件可信演化[J].计算机学会通讯,2010,6(2):28-36.
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
创新作文(1-2年级)(2019年3期)2019-09-03
法大研究生(2017年1期)2017-04-10
红土地(2016年3期)2017-01-15
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
幼儿智力世界(2016年6期)2016-05-14
发明与创新(2016年33期)2016-04-16
上海理工大学学报(社会科学版)(2015年3期)2015-11-30
