
基于Cluster的并行内存数据库恢复子系统模型研究
2013-06-06 10:44袁文亮钟宝荣何先平
池州学院学报 2013年6期
袁文亮,钟宝荣,何先平
(1.池州学院 数学与计算机科学系,安徽 池州 247000;
2.长江大学 a.计算机科学学院;b.理学院,湖北 荆州 434023)
基于Cluster的并行内存数据库恢复子系统模型研究
袁文亮1,钟宝荣2a,何先平2b
(1.池州学院 数学与计算机科学系,安徽 池州 247000;
2.长江大学 a.计算机科学学院;b.理学院,湖北 荆州 434023)
文章提出的恢复子系统模型是根据差分日志记录的特点,将已提交事务的日志经并行日志管理器收集后并行写入到多个磁盘,通过“协调者”全局检验点和站点局部检验点的协调操作,具有更高的并发度和更高的系统吞吐量,并且能快速的支持系统失败恢复。经过验证试验表明该子系统有效的减少了日志信息量,缩短了系统的恢复时间,提高了系统的性能。
并行内存数据库;差分日志;恢复子系统;检验点
引言
基于Cluster的并行内存数据库,是将数据分片到机群的站点上,而每个站点上的整个数据库放在内存里,一般事务所涉及的数据无需要进行I/O操作即可进行存取(检验点事务需要I/O操作),跨平台之间的数据存取通过网络通信来实现,这样提高了事务执行的效率,为高性能应用提供了保障。目前,主机互连网络技术已经取得了很大的发展,其带宽不断增加,而存取延迟则不断下降。在千兆以太网中,每个主机能得到128 MB/s的带宽,其网络存取的延迟仅为40μs左右,这个存取延迟和带宽比硬盘的I/O操作要快的多。但是,由于内存的脆弱性,在发生故障时,内存数据库中的数据将全部丢失。为此,基于Cluster的并行内存数据库系统需要一种高效、可靠的恢复机制以使在发生故障时能将数据库恢复到一致的状态。
本文的并行内存数据库恢复方案是利用差分日志记录的特点,在并行日志管理器将已提交事务的日志并行写入到多个磁盘,通过全局检验点控制和各站点局部检验点的具体操作,具有更高的并发度和更高的系统吞吐量,能快速的支持系统失败恢复。
1 恢复子系统模型与主要数据结构
恢复子系统设计如图1所示。系统中有日志管理器和并行日志管理器。日志管理器在事务运行时生成和管理日志,当事务对数据进行更新,日志管理器根据数据对象的旧值和新值,生成差分日志。当事务进入提交状态,差分日志和事务提交投票信息(Commit和Abort)一起,由事务参与者返回给事务发起者站点。在事务成功提交后,事务发起者站点的并行日志管理器将来自各个参与者的日志记录乱序合并,然后并行地把日志一起写入磁盘。
称设置了一致全局检验点的站点为 “协调者”。当一个站点检验点被触发 (该站点即为协调者),协调者传递消息给各站点,要求各站点进行基于分区的内存数据库一致局部检验点。任何一个站点局部检验点结束时,返回消息给协调者。只有所有的站点都返回消息给协调者后,这次全局检验点结束。这样设置的优势在于,当子事务所操作数据中有分布式数据,当整个事务提交后,如果该站点失败,可以直接Redo该事务。
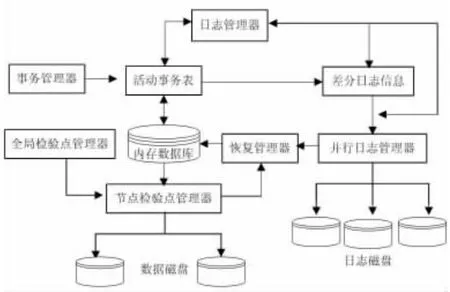
图1 恢复子系统模型
为了恢复的需要,系统在每个站点的内存中创建并维护三个表:活动事务信息表(ATIL)、MMDB数据分区表以及并行日志管理器内维护的链表LTD。其中ATIL表由事务管理器创建并维护,为系统中的每一个活动子事务创建并维护一条记录,该记录包含两个域:TID和TState,其中TID表示子事务标识;TState表示该子事务所处状态 (活动、阻塞、预提交、提交等状态)。日志管理器根据ATIL表中TState的值决定是否将差分日志返回给事务发起者站点。事务发起者的LTD表包括三个域,链表存放最近一个全局检验点来,提交事务的各参与点的信息,对应的Redo日志在日志磁盘的起始页及长度。在恢复过程中,根据LTD表的内容,可查找到失败站点在最近一个全局检验点来所写出的日志记录所在的日志磁盘的始页及长度,从而可以得到改失败站点在最近一个全局检验点来的所有日志。
MMDB数据分区表由恢复管理器负责维护,它为各站点的内存数据库中每个数据分区都维护一条记录,该记录包括三个域:PID、Ubit和Tuf。其中PID为数据分区的标识。Ubit为更新位,用来表示PID分区的更新是否写入固定存储器,Ubit为1表示该分区没有写,Ubit为0表示该分区已经写。Tuf为标识位,标识PID分区自上一个检查点操作以来的更新频率,Tuf为整数值N,N值越大,说明该分区更新的频率越大,Tuf为0,表示该分区没有被更新。
2 差分日志
差分日志(differential log)是基于按位异或操作的。用表示按位异或操作。当事务将数据对象的值B(beforeimage)更新为值A(after image)时,该操作相应的差分日志Dl(B,A)定义为BA。
差分日志具有如下基本特点:
1)交换律:V1V2=V2V1。
2)结合律:(V1V2)V3=V1(V2V3)。
定理1 (乱序重做与撤消)数据对象的初始值是V0,,x的最终值为Vm,Dli(i=1,…,m)是上的差分日志,可以通过把差分日志乱序应用到V0,得到Vm。
证明:假设差分日志以Dlk(1),Dlk(2),…,Dlk(m)的顺序应用到V0上,(k(i)∈{1,2,…,m},且当i≠j有k(i)≠k(j)).当m=1,V0Dlk(1)=V0Dl1=V1.假设当m=n时,上述结论成立,那么当m=n+1的时候,假设k(i)=n+1,根据异或操作的交换律,有V0Dlk(1)Dlk(2)… Dlk(i-1)Dlk(i)Dlk(i+1)… Dlk(m)=V0Dlk(1)Dlk(2)… Dlk(i-1)Dlk(i+1)… Dlk(m)Dln+1=…=V0Dl1Dl2… Dln+1=Vn+1。
根据 定理1,得出如下的结论:1)差分日志记录相对于传统的Undo/Redo日志而言,只需记录位异或操作的结果而无需记录数据对象的旧值和新值,日志的数据量可以减少近一半。2)只要有初值,就可以在数据对象的初值上按照任意的顺序应用差分日志记录都可以得到数据的最终值。根据这个结论,在系统正常运行时可以对多个站点来源的日志记录进行乱序的整合,然后并行的将其写入多个日志磁盘。在恢复过程中,从多个日志磁盘并行读取记录并且及时无序应用到数据对象上,可以提高系统恢复的效率。
3 检验点机制
在全局检验点的协调下,各站点采用基于分区更新频率的动态局部检验点模式,检验点进程和事务并发执行。根据预先设置的阈值α,当某站点MMDB页表中脏页所占比率大于阈值α时,检验点进程被触发。
检验点算法描述如下:
(1)当站点的MMDB页表中脏页所占比率大于α时,检验点进程被触发。该站点为“协调者”;
(2)协调者传递消息给各站点,各站点准备进行局部检验点;
(3)各站点进行局部检验点;
(3.1)根据MMDB数据分区表统计各站点的更新频率 Tuf(i),i=1,…,N。
(3.2)设DP是数据分区按照Tuf的降序列表。DP第一个结点是Tuf最大的数据分区i,对该分区进行事务一致的检查点操作:首先在数据分区i的日志记录中写入 BC(Begin Checkpoint)日志记录,表示该分区检验点开始,也是该站点的局部检验点开始;将分区 i内所有的数据页面中的数据对象读取到内存缓冲区中,该分区检验点结束;
(3.3)按DP顺序依次读取各分区的数据页面,当该站点所有分区的数据页面都读取完毕后,在日志中写入 EC(End Checkpoint)日志记录,表示该该站点的局部检验点结束;将内存缓冲区的内容刷到固定存储器中,形成新的检查点文件;
(3.4)把各个数据分区的Tuf置为0;
(4)站点返回消息给协调者;
(5)协调者收集各站点返回消息,决定本次检验点是否成功。如果成功,则清空链表LTD。
4 恢复
并行内存数据库站点失败,进行恢复的基本单位是数据分区。由于更新频率高的数据分区很有可能再次被存取,所以应该尽快的将在列表DP中靠前的数据分区恢复。而在列表DP靠后的数据分区可以暂时放在稳定外存里。在站点的恢复过程中,一旦关键的数据分区(列表DP中靠前的数据分区)装载完成。系统就可以接纳新所需事务。为了保证系统新事务的尽快投入运行,必须对新事务的数据请求尽快进行满足;如果新事务所需存取的数据分区,还没有载入内存,则事务管理器堵塞该事务,等待所需数据分区载入后再唤醒该事务的执行。站点恢复步骤:
(1)失败站点向并行日志管理器提出日志查找申请。
(2)并行日志管理器根据链表LTD信息。得到最近一个全局检验点后该站点的提交的日志记录。并返回给失败站点。
(3)根据该站点每个数据分区的更新频率,得到不同数据分区被事务更新的频繁程度。
(4)恢复管理器按频繁程度读取分区检查点文件,并且以异或操作应用到内存缓冲区数据影像上(数据影像初值为0)。
(5)恢复管理器的日志装载线程将并行日志管理器传递来的日志装载到内存缓冲区,再乱序应用到分区数据影像上。
(6)分区数据装载和差分日志乱序应用完毕以后,将该分区标记为可用状态。关键的数据分区恢复完成后,如果有等待事务,由事务管理器唤醒等待事务继续运行。
5 验证试验
由于采用差分日志记录法,在进行日志的恢复的时候,Redo日志信息通过链表LTD从日志磁盘收集过来以后,不需要一个排序过程,可以直接应用到内存数据影像上。
验证试验操作平台的性能数据为:磁盘寻道概率为50%,磁盘寻道平均时间约为5ms,网络速度为1000Mbps。实验环境中并行内存数据库系统有6个站点,2个日志磁盘,数据分片为 256MB,整个数据库的大小是 256*6=1.5GB,最近检查点以来运行的事务的数量是400K,差分日志记录的日志数据大约是267MB。实验数据如图2。
从图2可以看出,在系统恢复的前几秒,整个数据库数据恢复的比率较低,系统吞吐量受到了影响也较低,恢复过程中的前5秒、5~10秒,系统的平均吞吐量分别只有37.2Ktps和42.9Ktps。随着数据库恢复过程的深入,新事务所存取的数据已经驻留在内存中,系统的吞吐量增长明显,在恢复过程中的 10~15秒、15~20秒、20~25秒以及 25~30秒,系统的平均吞吐量分别为 60.2Ktps、87.2Ktps、97.3Ktps、104.3Ktps,成明显的递增的趋势,最后到达峰值——116Ktps。

图2 恢复过程中的系统吞吐量
6 小结
恢复机制是利用差分日志的乱序应用的特性,在事务提交后,并行的写出日志到多个日志磁盘。检验点被触发后,在全局检验点协调下,采用基于数据分区的局部检验点模式,恢复过程中不仅各个日志磁盘可以并行装载,而且数据分区的装载和日志的装载及应用可以并行进行,能尽快的把数据分区恢复到最近的一致状态。特别是在子事务操作的分布式数据比较频繁的并行内存数据库系统中,具有很好的应用价值。不足之处在于全局检验点协调如果不成功,将会导致检验点重复多次被激活。
[1]LEE I,YEOM H Y,PARK T.A new approach for distributed main memory database systems:A causal commit protocol[J].IEICE Transactions on Infor-mation and Systems E Series D,2004,87(1): 196-204.
[2]周晓云,覃雄派,等.一种高效的并行内存数据库事务提交与恢复技术[J].中国矿业大学学报,2009,38(1):68-74.
[3]杜晔,郭丽丽.空间实时内存数据库恢复机制研究与实现[J].计算机工程与设计,2013,33(2):734-739.
[4]邱元杰,刘心松,杨峰.一种高效的分布式并行数据库日志机制[J].计算机研究与发展,2004,41(11):1942-1948.
[5]周晓云,覃雄派.基于网络内存的内存数据库高效恢复技术[J].系统工程理论与实践,2011,31(2):81-87.
[6]STEPHEN B,KORTH H F.An almost-serial pro-tocol for transaction execution in main-memory data-base systems[C]// FREDERICK H L.Proceedings of the 28th International Conference on Very Large Data Bases.Hong Kong:VLDB Endowment,2002:706-717.
[责任编辑:桂传友]
TP311
A
1674-1104(2013)06-0045-03
2013-06-19
国家自然科学基金项目 (60873021/F0201)。
袁文亮(1979-),男,湖南娄底人,池州学院数学与计算机系讲师,硕士,研究方向为现代数据库理论。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
电脑爱好者(2020年10期)2020-07-28
河南水利年鉴(2020年0期)2020-06-09
数码世界(2018年2期)2018-12-21
小学生(看图说画)(2017年6期)2017-11-06
电子设计工程(2015年12期)2015-02-27
电子设计工程(2014年19期)2014-02-27
长春大学学报(2013年8期)2013-06-21
