
CPPL:A New Chunk-Based Proportional-Power Layout with Fast Recovery
2013-05-23 05:36JianglingYinJunyaoZhangandJunWang
ZTE Communications 2013年4期
Jiangling Yin,Junyao Zhang,and Jun Wang
(Department of Electrical Engineering&Computer Science,University of Central Florida,Orlando,Florida 32816,USA)
AbstractIn recent years,the number and size of data centers and cloud storage systems has increased.These two corresponding trends are dramatically increasing energy consumption and disk failure in emerging facilities.This paper describes a new chunk-based proportional-power layout called CPPL to address the issues.Our basic idea is to leverage current proportional-power layouts by using declustering techniques.In this way,we can manage power at a much finer-grained level.CPPL includes a primary disk group and a large number of secondary disks.A primary disk group containsonecopy of available datasetsand is alwaysactivein order torespond toincoming requests.Other copies of data are placed on secondary disks in declusterd way for power-efficiency and parallel recovery at a finer-grained level.Through comprehensive theoretical proofs and experiments,we conclude that CPPL can save more power and achieveahigher recovery speed than current solutions.
Keyw ords power proportionality;parallelismrecovery;declustering;layout
This work is supported in part by the USNational Science Foundation Grant CCF-0811413,CNS-1115665,CCF-1337244 and National Science Foundation Early Career Award 0953946.
1 Introduction
T o satisfy the requirements for performance,reliability,and availability in large-scale data analytics,distributed processing frameworks,such as Yahoo!Hadoop and Google MapReduce,have been adopted by many companies.The increasing number and size of data centers raises the problemof power consumption.To reduce power consumption,efficiency must be increased,and low-power modes for underutilized resources are required.Power proportionality has been used to evaluate the efficiency of computer power usage[1]-[3].Power proportionality means that power used should be proportional to the amount of work performed,even though thesystemisprovisioned tohandleapeak load.
Achieving power proportionality in a CPU requires dynamic voltage scaling[1],[4]-[6].However,achieving power proportionality in a storage system is very difficult because most hard drives do not work in multipower states.There are very few dual-rotation-rate hard drives on the market,and it is impossible to finely scale the power consumed by disks.A feasible alternative for a large data center is to use dynamic server provisioning to turn off unnecessary disks and save power[7]-[10].A CPU's dynamic provisioning schemes depend on the specific data layout,but powering disks on and off does not.At any point,all active disks in a storage system need to contain an entire data set in order to guarantee uninterrupted service for incomingrequests.
In recent years,several research efforts have resulted in group-based proportional-power layout schemes for storage systems.Lu et al.[11]introduced a family of power-efficient disk layouts for simple RAID1 data mirroring.Thereskaet et al.[2]developed a power-aware data layout in which all servers are divided into groups of equal size,and each group contains a copy of the entire data set.Amur et al.[10]developed a layout that is different from the power-aware grouped layout and in which thesizeof each group isdifferent.Toachieve ideal power-proportionality,the groups comprise an increasing number of disks.
All of these layouts use disk/server groupsfor simplicity.
There are two main limitations for group-based proportional-power layouts.First,the whole disk group is either powered on or off,so unneeded disks often consume power and result in performance loss.Second,a group-based layout usually requires a whole group of disks to be powered on,even if a single disk fails.Recovering a failed disk is also slow because of limited recovery parallelism across groups and no data overlap within agroup.
In thispaper,wedevelop a new chunk-based power-proportional layout called CPPL to solve these problems.Our basic idea is to leverage current power-proportional layouts by using declustering techniques to manage power much more finely.Wesummarizethecontributionsof our paper asfollows:
1)We establish a set of theoretical rules to study the feasibility of implementing ideal power proportionality with practical data layouts.Wealso study the effectsof ideal power proportionality on disk recovery.
2)We study specific CPPL layouts according to the theory and address power proportionality by configuring the overlapped data between the primary disks,i.e.disks in a primary replica group(p disks)and non-primary disks,i.e.disks not in theprimary replicagroup(non-p disks).
3)We conduct comprehensive experiments using a disksimbased framework.Our experimental results show that CPPL can save more energy than current solutions and is capable of higher recovery speed than current solutions.
2 Power-Proportional Storage System
Fault tolerance and load balancing[12],[13]are of primary concern in a traditional storage system and are usually achieved by randomly placing replicas of each block on a number of disks comprising the storage system.Shifted declustering[14]is a concrete placement scheme that has these properties but also maintains mapping efficiency.However,the data is distributed,which means subsets of disks cannot be powered down tosaveenergy without affectingdataavailability.
To discuss these properties by metric,we suppose that the total number of data chunks(data units)is Q,and each chunk has k replicas.The chunks are stored on a system that runs in a data center comprising n disks.We can number the data chunks with an ID 1,2,3,...,Q and name all the disks 1,2,...,n.The replicas of chunk i(1≤i≤Q)are stored on different disks,and( )i,j(1≤i≤Q and 1≤j≤k)represents the j th replicaof chunk i.
2.1 Fault Tolerance
We define vθas the number of overlapping chunks ofθ disks.It is an important factor in disk recovery because if disks fail,only those containing overlapping chunks can provide recovery data for the failed disks.For example,if one disk fails,another active disk needs to provide data for recovery.For the best recovery perfomance,the failed disk should have at least onechunk that overlapswith all other activedisks.
2.1.1 Distributed Reconstruction
Proof:We mapβdisks toβsets containing the IDof the data chunks and record them as.This statement can be proved by induction,and||Siis the number of chunksin set Si.have the same capacity)and allδ2are equal on this precondition,vβis a constant for any two setsfrom S.
Assuming that this statement is true for x-1(2≤x-1<β),then vx-1is a constant for any number of sets smaller than x-1 in S.From the inclusion-exclusion principle,wehave
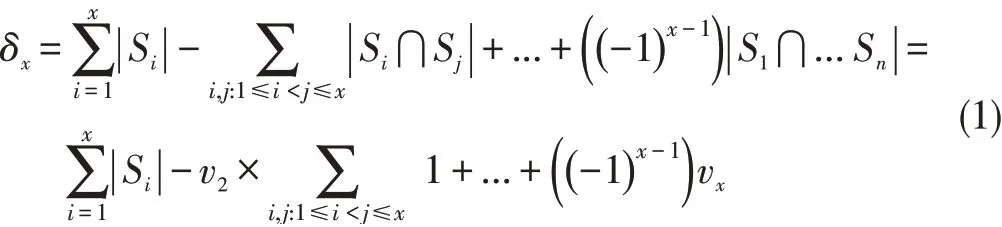
By precondition,δxis a constant and so vxis also a constant.Theproof iscomplete.
Theorem:If a layout can support parallel recovery for θ failed disks,then the disks will be laid with data chunks in such a way that the difference ofρθshould be at most 1 for 1<θ<n.
Proof:Suppose the storage system conforms to a degradation model where x (n>x≥1)disks fail.We rename these disks(d1,d2,...,dx).The system needs to recover these disks by requesting available chunks from the remaining active disks.Through parallel recovery,the data chunks on the failed disks should be as distinct as possible so that there is more available data on the active disks.According to lemma 2,x failed disks will have the same vx.The total vxfor n disks is,and the total number of overlapping data chunks based on x is.
To fully support fault tolerance,chunks with identical IDs should be stored on different disks.Thus,each different x chunk with identical chunk IDcounts once,and the total count for Q different data chunks is Q×The count from a disk and chunk perspectiveshould beequal:where vx=Q×.Wehave,sothe proof iscomplete.

2.1.2 Power-Proportional Reconstruction
In this section,we describe how a layout can satisfy the distributed reconstruction while supporting power proportionality.Specifically,we describe how the overlap of chunks changes between any two disks when the powering-up disks change.Suppose that m disks are active at time t and any pair of disks(i and j)from m have overlap chunks of xi,j.The number of paired disks among m active disks is.Thus,the sum of pair chunks among any two disks is m2×xi,j.On the other hand,consider m active disks storing Q chunks in portions.The total number of paired chunksis
A storage system should be highly available;that is,it should be k-way(k≥2)replication storage that can at least provide(k-1)failure correction.This means that there no two replicated chunks are located on any one disk.Thus,the sum of paired chunks fromthe twoperspectives are equal:

where xi,j=
In(3),k,Q and n in a stable storage system are usually constant,and xi,jis a function of m and increases with m.Fig.1 shows how xi,jchanges with m.In Fig.1,k=4,n=12,and Q=9.Values of xi,jbelow 0 are taken to be 0 because a negative xi,jmeans no overlapping chunks for any pair of disks in the m active disks.From Fig.1,overlapping chunks on any two disks change with the number of poweringup disks.Specifically,if the disks are numbered 0 to 11 and m=12 or 4,the overlap chunks that could be found between disk 0 and disk 1 will be 0.8 or 0.35 at different times.Therefore,the chunks need to be redistributed on disk 0 and disk 1.
As mentioned in the introduction,there is the problem of migrating petabytes of data and frequently switching servers on and off.It is very difficult to keep a fully distributed reconstruction whilemaintainingpower proportionality.
2.2 Group-Based Power-Proportional Data-Layout Policy
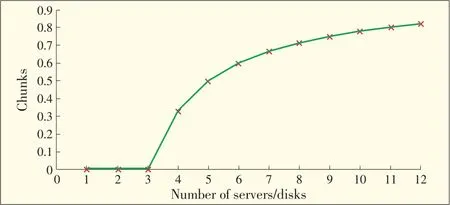
▲Figure1.Overlap chunksshared by any twoactivedisks for k=4,n=12,Q=9.
Group declustering was first introduced to improve the performance of standard mirroring.It was then extended to multiway replication for high-throughput mediaserver systems[15].Group declustering involves partitioning all disks into several groups,and the number of groups is equal to the number of datacopies.Each group storesacompletecopy of all data.In contrast to standard mirroring,data in the first group is scattered across all of the servers in the second group.In[2],the authors propose a power-aware group-data policy that can be implemented usingagroup-declusteringscheme.
Fig.2 shows the group-based layout,which can achieve power proportionality at the group level because any group can be used to provide one copy of the data service.The first problem with this method is that disks in each group share nothing,and better reconstruction parallelism cannot be achieved.For example,when all disks are powered on during busy periods but disk 4 fails,then disks5 and 6 cannot provideavailabledata to disk 4 for recovery.The second problem is that power is not proportional during recovery because all of the disks in other groups need to be powered on,even though only one disk has failed.For example,if disk 1 in the first group fails,then all of the disks in the second or third groups should be powered on for recovery.Thethird problemisthat when theincoming request comes with bias,which causes overload on a certain disk,the system may need to power on another entire group of disks to share the workload of the busy disk.This occurs because the data on the busy disk is evenly scattered acrossother group of disks.
2.3 Ideal Power Proportional Service
This section discusses the possibility that power used is proportional to the services provided by the storage system.Powering down or putting disks on standby means that the chunk data in the corresponding disks is not available for service,and user requestscould beviewed asthe total number of chunksretrieved.The service provided by the disks is depends on two things:the required data must be available on that disk and the service request on the disk must not exceed the maximum workload(requestsper second).
Observation 1:It is impossible for a storage system to achieve power proportionality by powering-down or idling disksunlesseach disk storesexactly onedatachunk.
Proof:We evaluate power proportionality in the following discussion.In the storage system,the amount of chunk data that is available for service is k×Q when all of the disks are powered on.Over a period of time,suppose partial data(service)is accessed and the number of chunks for retrieval is x.Then,the proportion of chunks that are available is(0≤x≤kQ).
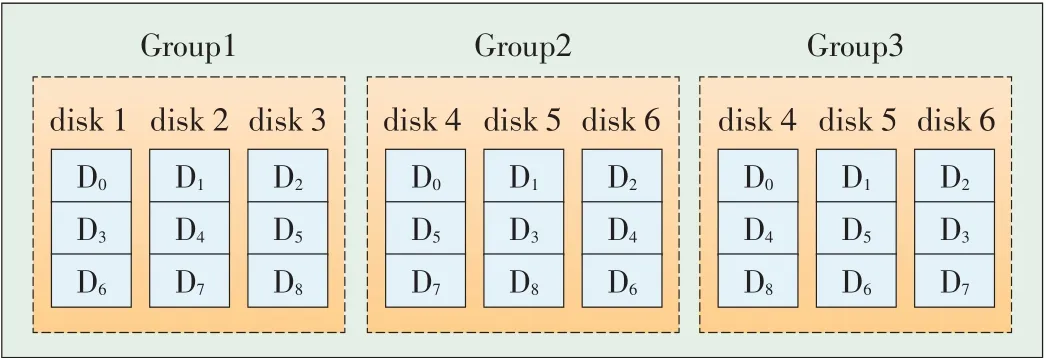
▲Figure2.Three-way replication data layoutsby group declustering.
The power used by the disks could be represented by the number of active disks.We assume that all disks consume the same amount of energy if they are powered on over a period of time.Thus,the maximum amount of power used is n;that is,all disks are powered on.Also,suppose that not all disks are active so that they can provide service,and the number of activedisksis y.Then,theproportion is.
The power used is proportional to the service performed,which satisfies;that is,
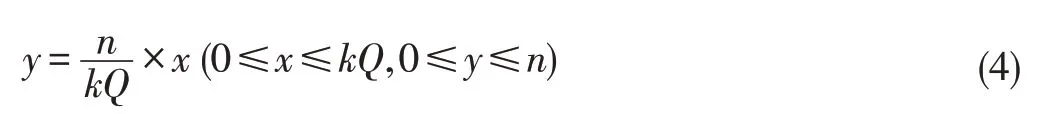
Given a fixed storage system,k,Q and n should be constants.Thus,the number of active disks y is a linear function of the number of requested chunks x.Both x and y should be integers(0≤x≤kQ,0≤y≤n).If,y will be a non-integer,and the power will not be proportional.If=1(i.e.kQ=n),then x=y and the power used is proportional to the service.Thus,power proportionality can be achieved if and only if kQ=n.This meansthat each disk only storesexactly onedatachunk.
3 Design of a Chunk-Based Power-Proportional Layout
In our proposed scheme,we follow theorems previously discussed.First,the proposed scheme keeps has the fast recovery property of the storage system,and combination theory is used to select disks on which to place chunks.Then,we modify the layout scheme to support power efficiency.According to our observations in section 2,it is impossible to achieve absolute power proportionality.Thus,the design goal of the proposed schemeistoapproximatepower proportionality,that is,tomaximize the efficiency of additional power usage when the system hastopower-on another disk.
3.1 Chunk Based Data-Layout Scheme
To achieve better recovery parallelism,any β disks(2<β<n)should have the same number of overlap chunks vβ.This number will only be greater than zero when the number of disks under consideration is no larger than the replicas k.If k+1 disks have overlapping chunks,one chunk will be required to have more than k copies.Thus,to place k copies of a chunk,k disks are selected as a set on which to place them.For n different disks,the total number of subsets is,and we count them from 1 to.The k copies of chunk i are placed into the disks of the i th subset.If<Q,the combination sets are repeated to place chunks.With k=2 and n=6,the subsets of disks in Table 1 are mapping,with count from 1 to=15.The(i=26)%15=11 and the subset comprising disks x1=3 and x2=5(the two copiesof chunk 26)arestored on disks3 and 5.
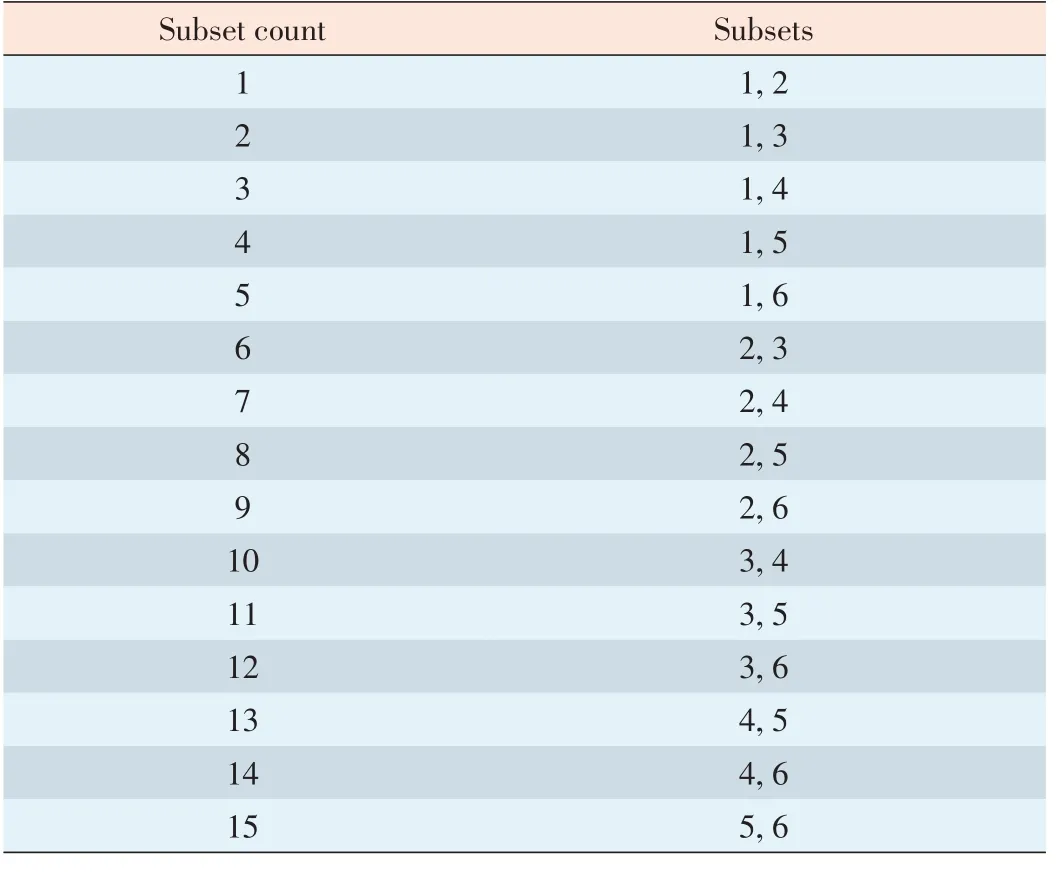
▼Table1.Subcountingexample
In general,the following equation tells us that the i th subset comprises k disks with an index value of(x1,x2,...,xk).In Table 1,(i=26)%15=11=11,the index is 3 and 5:
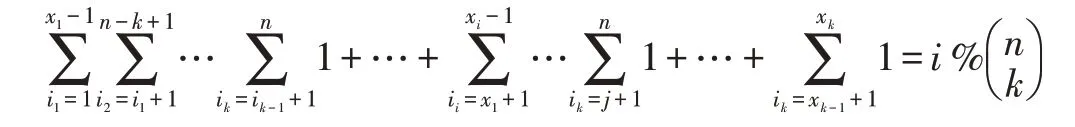
According to the combination series,any two disks share the same number of overlap chunks when=0.Because we place k copies of each chunk into k disks and we take these k disks as a set from the combination series,any two disks have an equal chance of being together.This ensures that any two disks in the series of sets will have the same number of overlapping chunks.The data in one disk will be evenly declustered to other disks.For the example,in Table 1,disk 1 has the same number of chunks as any other disk.We have proved that shifted declusteringcan providefull parallelismrecovery[14].
3.2 Approximating Power Proportionality
It is very difficult to achieve perfect or ideal power propor-,y cannot get all the integers from 0 to n.This does not make sense because k×Q<n,which means that the number of disks is more than all the chunks.Iftionality.Researchers exploit different data layouts to approximate power proportionality on different levels.In practice,the storage system always keeps at least one copy of all data chunksactive:

Suppose a layout has p disks as an isolated group,and φ(Δx)is the extra number of disks that containΔx for service.According to the discussion in section 2.1,the goal is to achieve

The three relative variables areΔx,φ(Δx),and p,and the key is to find the correlation betweenΔx andφ(Δx).Generally,φ(Δx)has an increasing relationship withΔx;that is,more service requests lead to more active disks.IfΔx=0,then only one copy of the chunk data is needed,andφ(Δx)is also zero.Thus,p≈is not an integer,we let p=to make p smaller and savemorepower.
Dynamic provisioning and reload dispatching can create a suitable relationship betweenΔx and φ(Δx)if extra disks need to be powered on to respond to incoming requests.However,this usually entails the migration of petabytes of data,which makes the storage system more volatile.In the groupbased layout,if the primary group is busy,another group of disks can be powered on to ensure service quality.Sometimes it may be not necessary to power on the entire group of disks when only one or two disks are overloaded(i.e.the I/O requests per second exceeds the setting).Thus,the policy of turning on a whole group of disks does not maximize efficiency for additional power usage.
Our proposed layout maximizes efficiency for additional power used.Specifically,we map each non-p disk to a p disk with different percentages of overlap chunks and also preserving the declustering.The advantage of this policy is that the mapping relationship with different percentages provides a much more flexible power-up selection.In Fig.3,n=9,k=3,Q=30,p=3,and non-p=6.The subsets(1,0),(1,1),and(1,2)show there are three copies of chunk 1.If over a period,an extra disk is needed to share the workload of p1,then d1or d2could be powered on because they share more overlap chunks(6/10)with p1.To preserve the declustering,d1or d2also share some chunks with p2and p3.
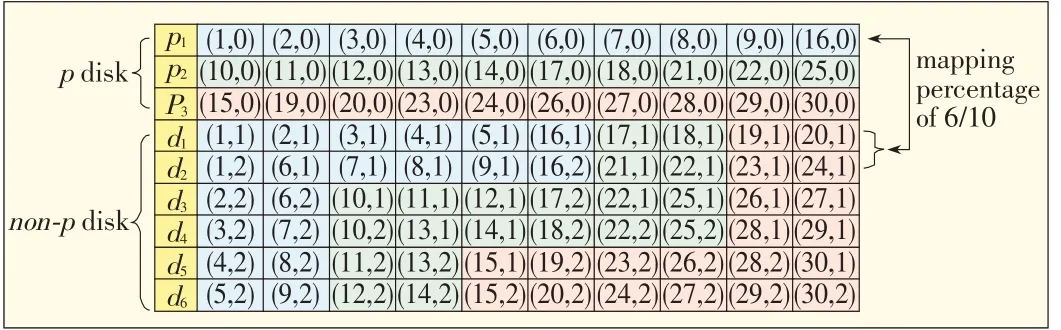
▲Figure3.An exampleof 30chunkswith 3copiesdistributed into p disksand non-p disks.
We record the p disk as p1,p2,...,ppand the non-p disks as d1,d2,...,dn-p,and the percentage of overlap between pi and djis vpi,j.The value of vpi,jis fixed to the value of p,which is(i=1,2,...,p).For i=1 in Fig.3,
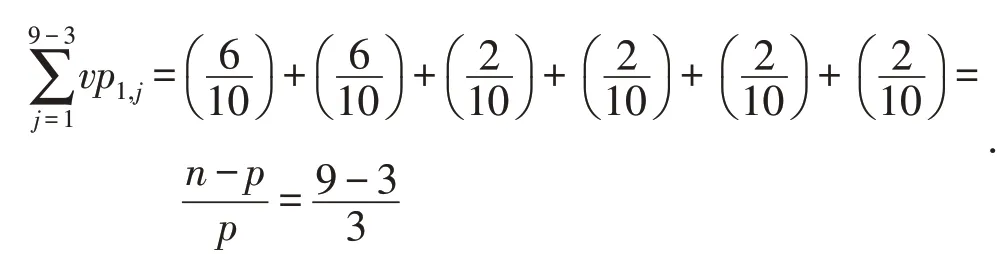
we have Specifically,if the data on p disks is evenly declustered on non-p disks,then vpi,j=
For specific storage systems with different incoming request distributions,the chosen percentages between p disks and non-p disks could be different.With more bias services to provide(many I/Orequests to a certain disk),a larger overlap percentage should be chosen for data declustering.The power on/off strategy is very simple in our layout.Most of the time,the system only needs one copy of the data for general service,and the system leaves p disks powered on.If the workload on a p disk exceeds the maximum setting,the system activates the disk that has more overlap chunks in order to share the workload of thebusy disk.
3.3 Fast Recovery and Power Efficiency
Distributed reconstruction cannot be maintained when the system provides proportional service by switching disks on or off.The overlapping chunks between any two disks change with respect to the number of active disks.In this section,we describe the policy of the proposed layout that allows the storage system to remain power efficient when disks fail.Disk failure,especially multidisk failure,is a difficult issue to address because many combinational failures need to be considered.In this paper,we consider disk crash failures,not arbitrary Byzantine failures,and we assume that the failed disks are providing services.If thedisksarenot in service,wecan taketimetoperformthe recovery.The recovery policy takesinto account availablility and load balance when powering on extra disks for recovery.For availability,one copy of every chunk needs to be active in the system because all of the data may be accessed immediately.Load balancing involves how to schedule the ongoing access load of the failed disks and the recovery load for thefailed disk.
The ongoing access load of the failed disks must be handled immediately by the storage system in order to retain QoS.To power up fewer disks,the disks that have greater data overlap with the failed disk are invoked first.A complete data copy of the failed disks should be found in the active disks,and the group of disks that contain a complete copy of the failed disks are called the recovery group.From Fig.3,d1and d2could be recovery group of p1.For power efficiency,we select a smaller number of disks(the default is 2)as a recovery group for each p disk.The disks in the recovery group have a higher percentage of overlap.If a primary server fails,the file system activates the corresponding recovery group.This is the failure-recovery strategy.The percentage of overlap is determined in the following manner:each p disk will map to two disks with a higher percentage of overlap and which contain a c omplete copy of the data on the p disk.The p disk also maps to disks with an equal percentage of overlap.
Thus,if the workload in the whole system is low,the extra number of power-up disks could be smaller(2 is default).In the example drawn from Fig.3,the failed disk only causes two disks to be powered on.Also,the non-p disks share the same number of overlapping chunks,and this fully supports parallel recovery.For example,when all disks are powered on and d1has failed,all the other eight disks can provide data to d1.The number of overlapping chunks determines the recovery speed.In fact,the maximum recovery parallelism of CPPL is n-p and that of group-based recovery is
4 Experiments and Evaluation
We run simulations on DiskSim[16]in order to determine the performance of thechunk-based layout in amultiway replication architecture.We implemented the address-mapping algorithms for CPPL,and we also implemented a group-based layout called Power-aware grouping[2].We then determined performancethrough service-request-driven simulations.
The architecture simulated on DiskSim is shown in Fig.4.At the top layer,a trace generator or input trace is read.The green boxes represent existing DiskSimmodules,and the white boxes represent added modules for implementing our mapping algorithms,load monitor,and schedulingpolicy[17].
4.1 Proportional Service Performance
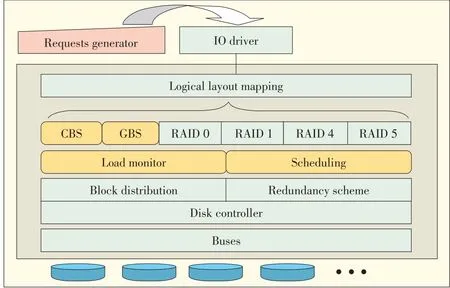
▲Figure4.DiskSim simulation architecture.
In normal service,the disks containing a copy of data are powered on in order to respond to incoming requests.We use Shortest Queue First(SQF)to assign the requests to active disks.The algorithm always tries to assign the new request to the active disk with the lowest workload.If the requested data is not on the disk,the process will continue to search until the request can be responded to by an active disk.If the process fails to assign the request to active disks,more disks need to be activated.With a power-aware grouped layout,another group of disks is powered up if the active disks cannot provide the requested service.With a chunk-based layout,the powerup order of thedisksisfirst considered by thedisksthat can leverage better load balancing with the highest ongoing service of the p disks(as discussed in section 3.2).Also,we add the metric ideal power proportionality(ideal PP)with respect to workload.
With numerous requests under different workloads,we found that the chunk-based layout saves more power than the group-based layout without affecting user experience.Fig.5 shows power usage for the OLTP I/O trace called Financial I trace,which is a typical storage I/O trace from Umass Trace Repository[18].Because any real trace has a specific bias,we use statistics to evaluate the performance under a variety of workloads(Fig.6).For each workload,100 different request cases are run.The graphs show the overall average percentage of power used when all disks are powered on.The power usage curve of a chunk-based layout is lower than that of a poweraware grouping.These results agree with our design principle.When only a few disks are overloaded,a smaller number of disks are powered on in order to share the workload of the busy disks.
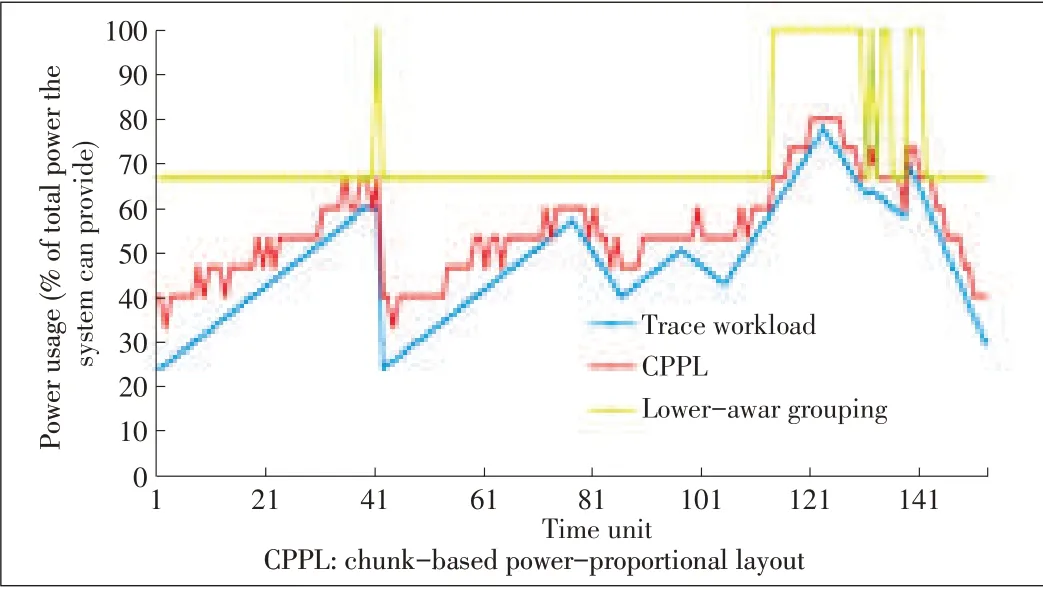
▲Figure5.Power performancecomaprison for Financial Itrace.
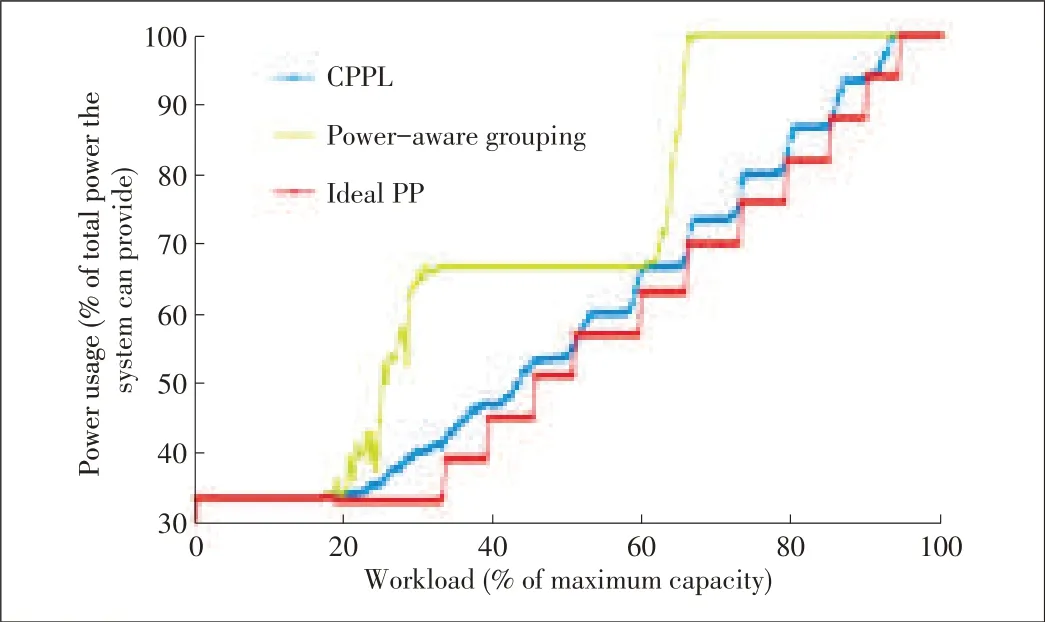
▲Figure6.Power usagein failure-freemode.
4.2 Degraded Mode Performance
In this section,we discuss power performance when the system is in degraded mode.The system should be able to handle theongoingaccessrequestsof thefailed disksaswell astherecovery work for the failed disks.For both layouts,we apply the SQF algorithm so that the workload can be handled without affecting user experience.The algorithm tries to assign the workload of the failed disks to the active disk with the lowest workload.If this workload cannot be assigned to these active disks,more disks need to be activated.The system first tries to respond to the requested service without failure.During the runtime,oneor twoactivedisksarerandomly chosen tofail.
Fig.7 shows the power usage for CPPL in failure-free mode and with a single server failure.The power curves are parallel and increase proportionally with workload.The moderate gap between the two curves is the extra power used by the recovery group.Thisresult agreeswith our design in section 3.3.The extra number of power-up disks is smaller when one disk fails.However,with the group-based layout in Fig.8,power usage in failure-free mode moves in three steps that are not proportional to the workload.This disproportionality occurs because all of the disks are divided into three groups,i.e.k=3.Moreover,a whole group of disks needs to be powered on,even if the workload is light.Fig.9 shows power usage in degraded mode.We found that more than 30%of power can be saved by using CPPL instead of a group-based layout.
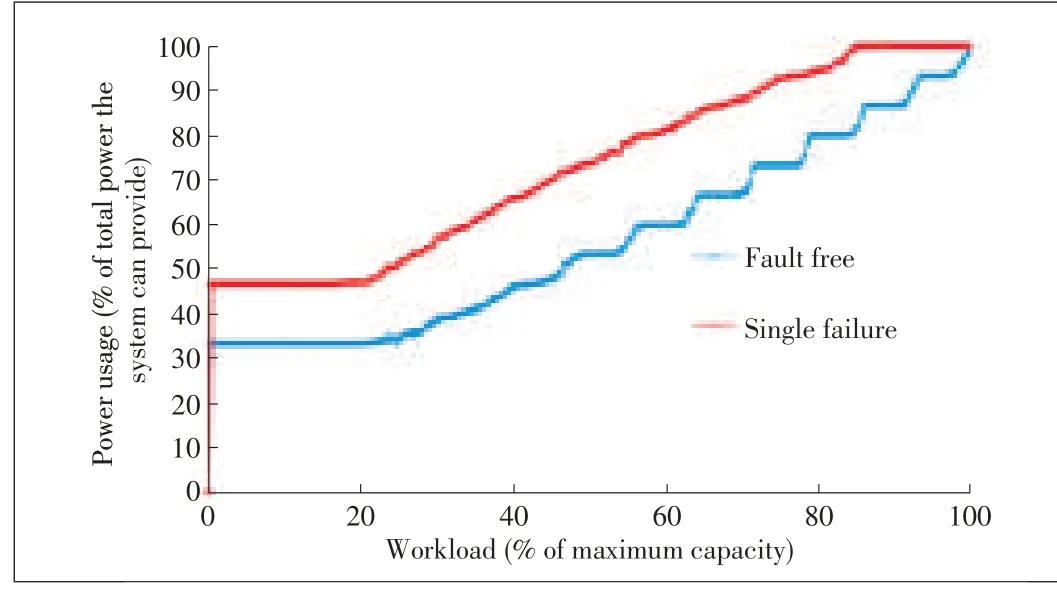
▲Figure7.Power usagefor CPPL:Failure-freemodevs.degraded mode.
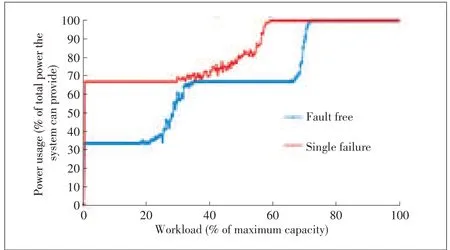
▲Figure8.Power usagefor power-awaregroupinglayout:Failure-freemodevs.degraded mode.
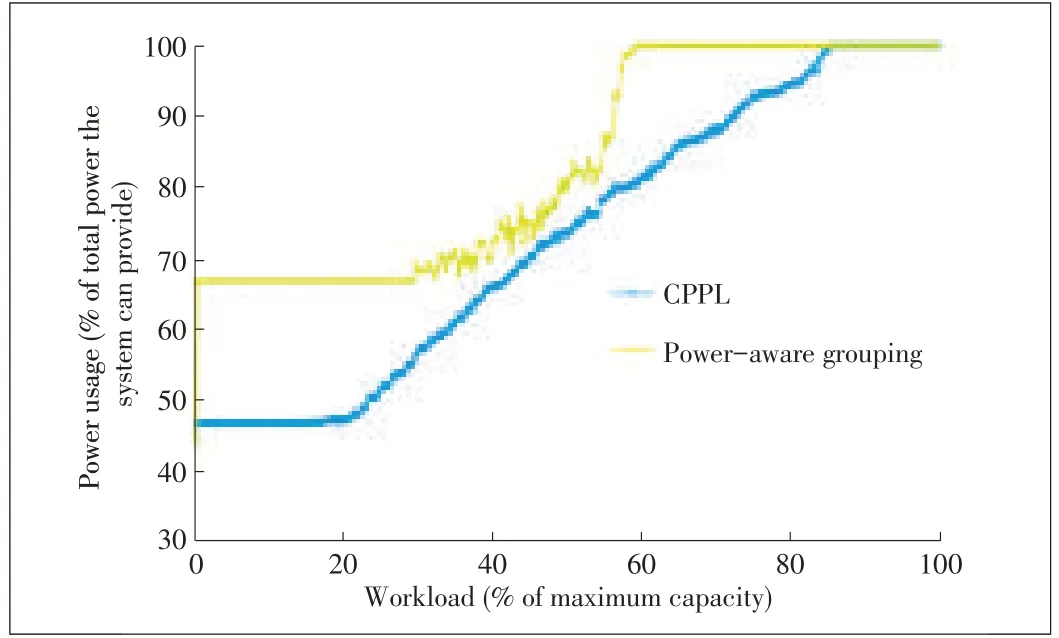
▲Figure9.Power usagein degraded mode.
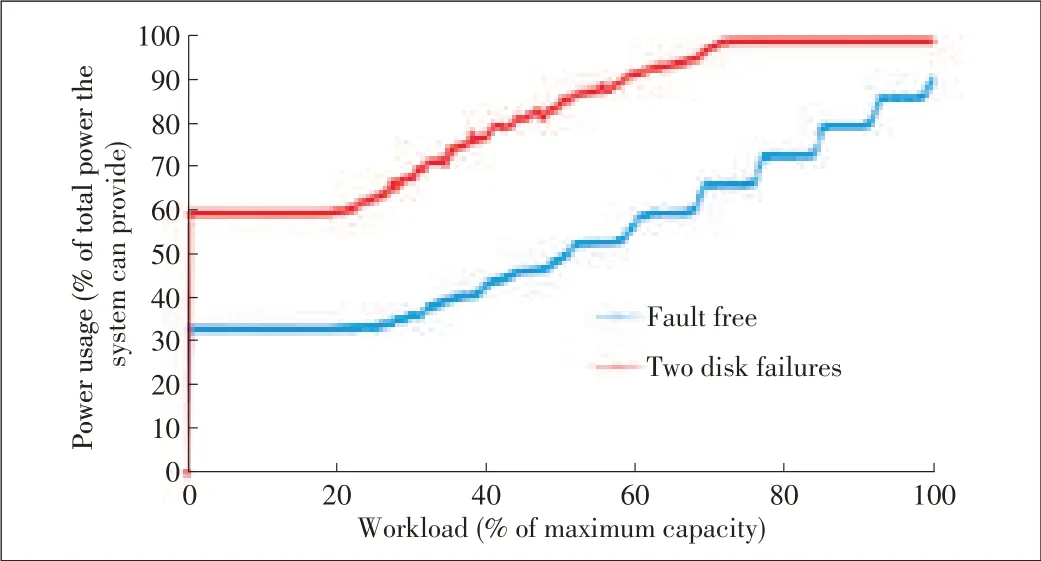
▲Figure10.Power usagefor CPPL:Failure-freemodevs.degraded mode(two disk failures).
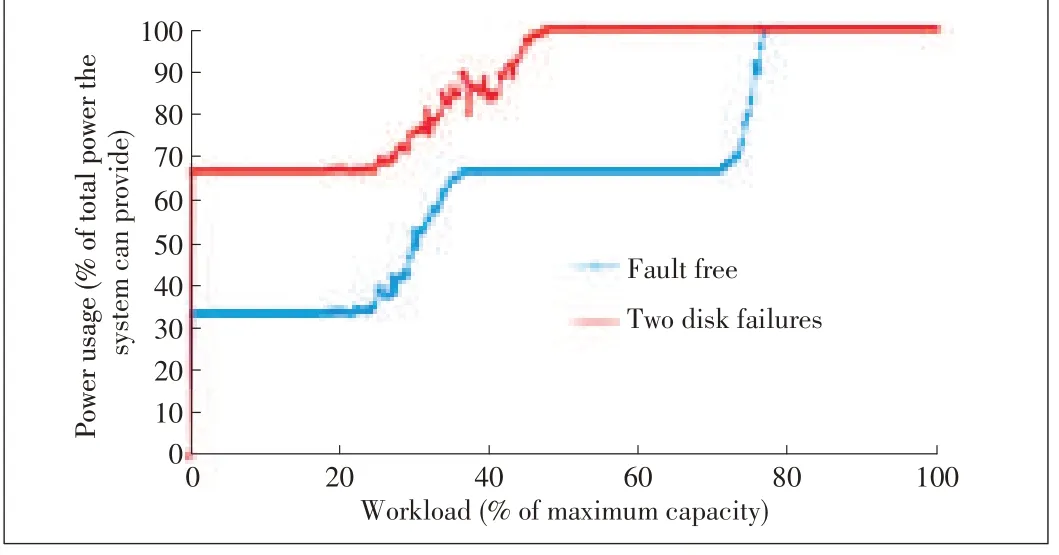
▲Figure11.Power usagefor power-awaregrouping:Failure-free modevs.degraded mode(two disksfailures).
Figs.10 and 11 show power usage of CPPL and poweraware grouping,respectively,in failure-free mode and twodisk-failure modes.Two disks fail in the simulation,so the wholeworkload isthework capability of n-2 disksin failurefree mode.In Fig.10,the increasing relationship between the power curves is proportional,which means that the extra power used for recovery is the same for different workloads.However,gap between the curves in Fig.10 is bigger than that for a single failure.This is expected because more disks need to be powered on in two-disks-failure mode.Fig.11 shows that less power is saved with two-disk failure and all disks are powered on from the workload of 50%.Fig.12 is the power usage comparison for CPPL and power-aware grouping in degraded mode.
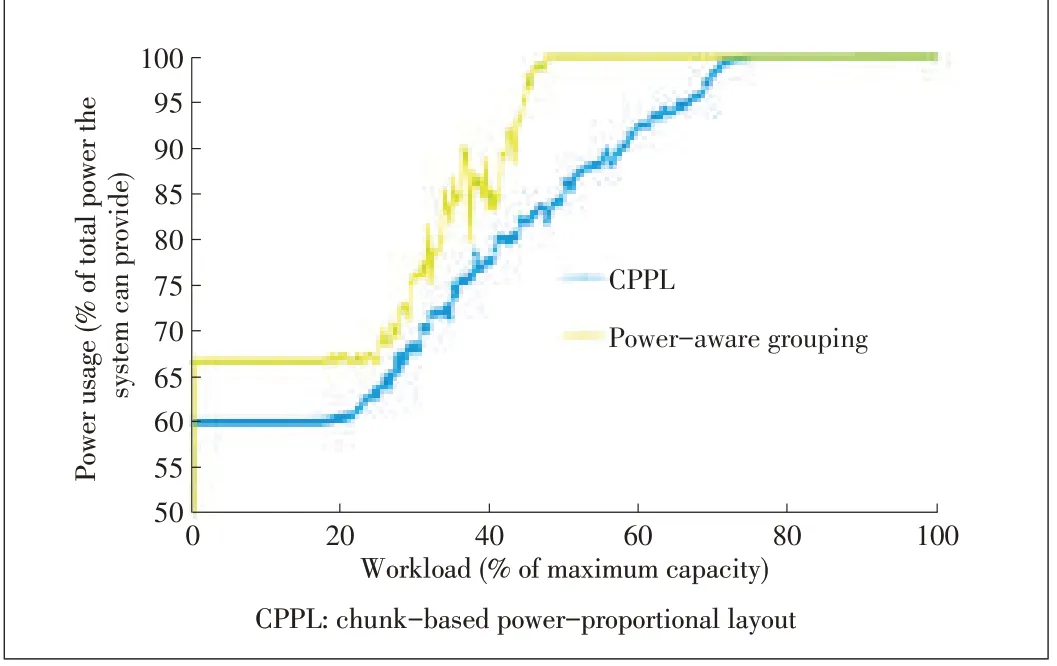
▲Figure12.Power usagein degraded mode.
5 Conclusions
In this paper,we have exploited the data-placement layout in storage architecture based on multiway replication.We have theoretically analyzed the characteristics of an ideal layout,which can support power proportionality and parallel recovery.We proposed a data-placement layout based on chunks.The proposed scheme manages power much more finely and still enables parallel recovery.Compared with group-based layout schemes,our proposed scheme saves much more power than group-based schemes and provides better recovery without affecting user experience.

- ZTE Communications的其它文章
- Cloud Computing
- Software-Defined Data Center
- Computation Partitioning in Mobile Cloud Computing:A Survey
- MapReducein the Cloud:Data-Location-Aware VM Scheduling
- Preventing Data Leakagein a Cloud Environment
- Virtualizing Network and Service Functions:Impact on ICT Transformation and Standardization