
Computation Partitioning in Mobile Cloud Computing:A Survey
2013-05-23 05:35LeiYangandJiannongCao
ZTE Communications 2013年4期
Lei Yang and Jiannong Cao
(Department of Computing,Hong Kong Polytechnic University,Hong Kong)
Abstract Mobiledevices areincreasingly interacting with clouds,and mobilecloud computinghasemerged asa new paradigm.An central topic in mobile cloud computing is computation partitioning,which involves partitioning the execution of applications between the mobile side and cloud side so that execution cost is minimized.This paper discusses computation partitioning in mobile cloud computing.We first present the background and system models of mobile cloud computation partitioning systems.We then describe and compare state-of-the-art mobile computation partitioning in terms of application modeling,profiling,optimization,and implementation.We point out the main research issues and directions and summarize our own works.
Keyw ords mobile cloud computing;offloading;computation partitioning
1 Introduction
C loud computing is an important new paradigm in IT service delivery and has been driven by economies of scale.It enables a shared pool of virtualized,managed,dynamically configurable computing resources to be delivered on demand to customers over the Internet and on other availablenetworks.With theadvancesin technologies for wireless communication and mobile devices,mobile computing has become integrated into the fabric of everyday life.Increased mobility means that users need to run stand-alone mobile applications and/or access remote mobile applicationson their devices.
The application of cloud services to the mobile ecosystem has created a new mobile computing paradigm called mobile cloud computing(MCC).MCCoffers great opportunities for the mobile service industry because it allows mobile devices to utilize elastic resources offered by the cloud.There are three MCC approaches:1)extending cloud service access to mobile devices;2)enabling mobile devices to work collaboratively as cloud resource providers[1],[2];and 3)augmenting the execution of mobile applications by using cloud resources(i.e.by offloading selected computing tasks of mobile applications onto the cloud).This allows us to create applications that far exceed what ispossiblewith atraditional mobiledevice.
Of thethree MCCapproaches,most of therecent research focuses on the third because it represents the general trend but is more challenging.This paper discusses computational partitioning,an essential problemin the third MCCapproach.Computation partitioning involves partitioning the execution of application between the mobile device and cloud so that execution cost is minimized.This cost can be measured in term of completion time,throughput(if the application is to process streaming data),energy consumption,and data transmission over the network.Execution cost is usually created by the application itself,the computing capability of the mobile device,and thebandwidth/quality of connection tothecloud.If themobile device has high computing capability or the network bandwidth is not fully utilized,we can assign more functions to the mobile side.If the device has poor computing capability but the network bandwidth is good,we can execute more functions at thecloud side.
We present the literature on computation partitioning according to the taxonomy in Fig.1.We divide research on computation partitioning into two categories based on system model.One of these categories is user-independent computation partitioning,where partitioning decisions are independent,and each user can make an optimal partitioning decision.The other category isuser-dependent computation partitioning,whereuser partitioningdecisionsdepend on each other becauseparticular resources that could affect user partitioning are shared.In this model,the allocation of shared resources and user partitioning decisions should be considered jointly.Partitioning decisions are made according to global information of all users,and the aim is to minimize execution cost for all users.We found that the state-of-the-art computation partitioning model
Section 2 describes the two system models.Section 3 describes state-of-the-art independent computation partitioning in termsof application modeling,deviceprof iling,network prof i ling,and implementation approaches.We describe how to represent the application in a way that correctly reflects the properties of the application and makes the partitioning decision more convenient.Device prof iling and network prof iling involves collecting device and network information that is critical to the partitioning decision.This information includes the device computing capability,device CPU/memory state,and network bandwidth.Optimization involves minimizing the application's execution cost based on the cost model,which measures the cost of partitioning.The cost may be increased completion time,data processing throughput,energy consumption,or a combination of these.The implementation approach is the way in which the tasks of an application are remotely executed at the cloud side in a practical system.A client-server approach,VM migration approach,or agent approach may be taken toremotely executetasksin thecloud.
Section 4 describesresearch issues in computation partitioning.These issues include energy efficiency,mobile access management,workload management,performance modeling and monitoring,and security.In section 5,we present our current work on a)modeling and partitioning data-streaming applications,b)prof iling network bandwidth and partitioning an application when bandwidth is fluctuating,and c)user-dependent computation partitioning.The first two areas are studied in terms of the user-independent computation partitioning model.In section 6,weconcludethepaper.
2 Background and System Model of Mobile Cloud Computation Partitioning
A mobile cloud system comprises mobile devices,wireless access,and clouds.A mobile device can offload some computation to the cloud,and this can reduce computational cost(e.g.execution time or energy consumption)of the mobile device.However,such of floading creates additional overhead.If we treat the application as a black box that has computational cost when executed locally and data transmission cost when executed remotely,we can decide whether the application should be executed locally or remotely.However,this level of off loading decision-making is too coarse.For complex applications that can be divided into a set of dependable parts,we need to make off loading decisions for all the parts,and the decision made for one part depends on the other parts.Of floading decisions should be optimized for every part of the application:This is computation partitioning.
The partitioning decision depends on device information,network bandwidth,and the application itself.Device information includes the execution speed of the device and the workloads on the device when the application is launched.If the device computes very slowly and the aim is to reduce execution time,it is better to off load more computation to the cloud.Network bandwidth affects data transmission for remote execution.If the bandwidth is high,the cost in terms of data transmission will be low.In this case,it is better to of fload computation to the cloud.Each part of the application requires computation and data transmission if it is off loaded to the cloud.The ratio of the amount of computation(in term of execution instructions)to data transmitted is called the compute-to-communication ratio(CCR).If the CCRishigh,theapplication iscomputationintensive,and it is better to execute tasks remotely.If the CCR is low,the application is data-intensive,and it may be better to execute tasks locally.Unlike device and network information,CCRisastatic factor that inf luencesthe partitioning decision.Different applications usually have different CCRs.Device and network information usually change over time.Collection and estimation of device and network parameters in real time is called prof iling and is a challenging issue that will be discussed in the next section.When the device and network parameters are profiled,an optimization problem can be solved and thepartitioningdecision can bemade.
We now discuss the system models for user-independent computation partitioning and user-dependent computation partitioning.In the user-independent model,each user makes their own partitioning decision,but partitioning can be done at various places in the mobile cloud system(e.g.at the device side,access network,or cloud side).Fig.2 shows three cases is the independent model[3]-[11].In our recent works,we have studied the user-dependent partitioning model[12].Therefore,in our survey here,we focus on the independent computation partitioning model,and user-dependent computation partitioning is dealt with in the section that summarizes our own work.for the user-independent model.The blocks marked Pindicate the partitioning function.Partitioning can be done at the mobileside(Fig.2a),cloud side(Fig.2c),or within theaccessnetwork(Fig.2b).The blocks marked Sindicate the scheduling of off loaded computation from mobile users to cloud servers.In this model,partitioning and scheduling are decoupled.Each user'spartitioningdecision ismadeindependently.

▲Figure1.Taxonomy of thesurvey.
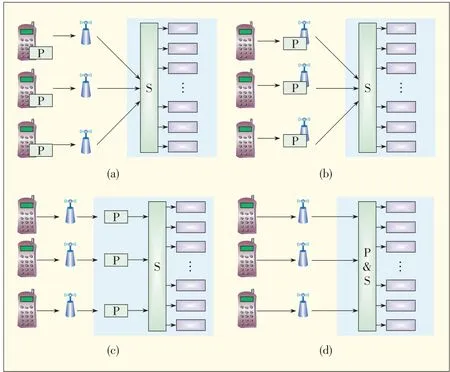
▲Figure2.(a),(b)and(c)areuser-independent system models,and(d)istheuser-dependent model.
In the user-dependent model,partitioning depends on that of other users.This model is suitable when users are competing for shared resources,such as servers at the cloud side.Because of this competition,the optimality of a partitioned execution not only depends on the partitioning itself but also on the availability of the resources(which varies according to other users'partitioning).Thus,we need to consider the prof iling information of all users and make partitioning decisions that guarantee optimal average performance for all users rather than optimal performance for each individual user.Fig.2d shows how partitioning is done at the cloud side with scheduling for all users.The block marked P&Sindicates partitioning coupled with scheduling.
The user-independent model is intuitive,and most existing works pertain to this model[3]-[11].A critical assumption of this model is that resources shared by users are always enough,and the allocation of resources does not inf luence the execution of application that has been partitioned in advance.It is assumed that the cloud always has enough servers to accommodate the computations off loaded from mobile devices and that execution time is the metric for optimization.Off loaded computation should be executed on the servers without delay;otherwise,the performance of the partitioned execution is sacrif i ced.Thisassumption istruewhen thecloud hasnearly unlimited computing resources or the number of mobile users offloading computation to thecloud doesnot exceed tothe cloud'scapacity.This model is suitable for a system that serves a small or predictable number of users,and the cloud guarantees optimal partitioningfor each individual user.
The user-dependent model applies when the computation loads from mobile users exceed the capacity of the cloud,and users need to compete for resources at the cloud side.In this scenario,instead of optimizing performance for each individual user(asin the user-independent model),the objective is to optimize overall performance.We suggest that the user-dependent model is suitable for use in large-scale system with unpredictable workloads.In the user-dependent model,coupling of partitioning and allocation of shared resources make partitioningmorechallenging.Thismodel wasf irst proposed in[11].
3 State-of-the-Art Computation Partitioning for Mobile Cloud Computing
3.1 Application Modeling
An application model may be the model used by programmers to develop applications.It may also be the mathematical model that represents the structure of the application.The former provides programming abstractions for application development,and the latter is the formal representation of the application to be partitioned.The latter usually depends on the programming model.Thus,we describe the application model from the perspective of programming.In our survey,three application models are:procedure-call,service-invocation,and dataf low.
In a procedure-call model,an application is represented by a set of procedures,and each procedure can call other procedures[3],[4],[8].Thus,we can use a procedure-call tree or graph to model the structure of an application.In the tree/graph,the node represents the procedure,and the edge represents the call relationship.The programmers write the application according to a procedure-oriented paradigm.The problem in partitioning is deciding whether each procedure should be of f loaded or not.Thismodel can beapplied tomost applications.
In a service-invocation model,an application comprises a set of services.We usually use a service-invocation graph to model the application.In thisgraph,thenodeindicatestheservice,and the edge indicates the service that the programmers need in order to program the application using a service-oriented methodology.The work in[5]and[6]pertains to this model.In[5],an application with a set of weblets is decomposed.A weblet is a kind of web service that can be executed at either the mobile side or cloud side.I.Giurgiu et al.[6]build their partitioning system on a distributed service computing platform called AlfredO[13].This platform has been used to decompose and couple Java applications into software modules.
The service-invocation model and procedure-call model decompose an application at different granularities.The service model decomposes the application at its functionalities,and the decomposed modules are loosely coupled.The procedurecall model decomposes the application according to the structure of the code.The decomposed procedures are tightly coupled with each other,which creates programming diff iculties in terms of distributed execution.However,in terms of the application's representation methodology,the service-invocation model and procedure-call model are the same.They use a very similar graph to model the application.
The dataf low model is suitable for modeling most media applications that have continuous incoming data to process.In this model,the application comprises a set of dependable stages.The output data at each stage becomes the input data of the next stage.At each stage,a particular operation is performed on the incoming data.Dataf low can be represented by a directed acyclic graph in which each node is a stage and each edge indicates the data dependence between the two connecting stages.In[9]and[11],the application to be partitioned ismodeled as dataf low graphs.Fig.3 shows the dataf low graph of a face-recognition application.
3.2 Pro fi ling
The prof iling process involves collecting information related to the application,device,and network.Application information includes the execution load(not dependent on devices)of each part of the application as well as the amount of data transmitted between two dependent parts.Because the application information isstatic,it can begathered off line.
Collecting device-related and network-related information can be difficult.In terms of device prof iling,we are concerned with estimating parameters such as energy consumption,computation capability,and CPU/memory workloads.In terms of network prof iling,we are concerned with parameters such as bandwidth,latency,and package loss rate.Parameters such as device computing capability and energy consumption are static,so they can be acquired off line.Other parameters,such as CPU/memory workloads and network bandwidth,may vary in real environments,thusweneed toestimatethemonline.
MAUI[3]profiles the energy consumption of each part of the application according to a model that shows energy consumption as a function of CPU cycles.The model is learned offline from real measurements.The authors of MAUIalso evaluate the accuracy of the model and show that its error margin is less than 6%.MAUI[3]estimates network parameters,such as bandwidth and latency,online through recent offloading opportunities.It also updates its estimations when there is no off loading by transferring a 10 KB file to the server.The profiled parametersareused tomakeonlinepartitioningdecisions.
CloneCloud[4]prof iling comprises two phases:online and offline.In the off line phase,the partitions of an application are obtained for various execution conditions(including those related to the device and network characteristics).The execution conditions are acquired by real measurements,regardless of the overhead.The partitions and corresponding execution conditions are stored in the database of the device.In the online phase,the system estimates the execution condition and searches the matched partition from the database.In[4],the authors do not describe how to estimate the execution condition accurately and eff iciently in theonlinephase.
Odessay[9]doesnot prof ile the application,device,and network independently.Instead,it directly prof iles the running time of each stage and data transmission time of each connector.The information is updated when the application starts to execute again.This information is used to determine the partition in the next execution.Most related works on computation partitioning take the approach of Odessay[5],[8].This approach avoids the overhead created by direct profiling of networks and devices;however,it may not beasaccurateasdirect prof iling because the partition is always made according to the last execution condition.The partition leads to bad performance when the execution conditions change quickly.This often happens in mobile environments where the wireless connection drops or bandwidth fluctuates.In our current research,we focus on estimating network bandwidth efficiently in real time and then updating the application's partition,even during the course of the execution of the application.
3.3 Optimization
Computation partitioning requires partitions to be optimized according to prof iling information.The optimization metric can be execution time,energy consumption,data traff ic,or a customized,weighted summation of these.MAUI[3]was proposed to optimize the energy consumption of devices.CloneCloud[4]and ThinkAir[8]support the optimization of either execution time or energy consumption,depending on the programmers'choices.Odessay[9]aims to optimize the makespan for datastreaming applications.The framework in[11]was proposed to optimize the processing throughput for streaming applications.In[5],the authors propose hybrid optimization that can be customized by theend user.
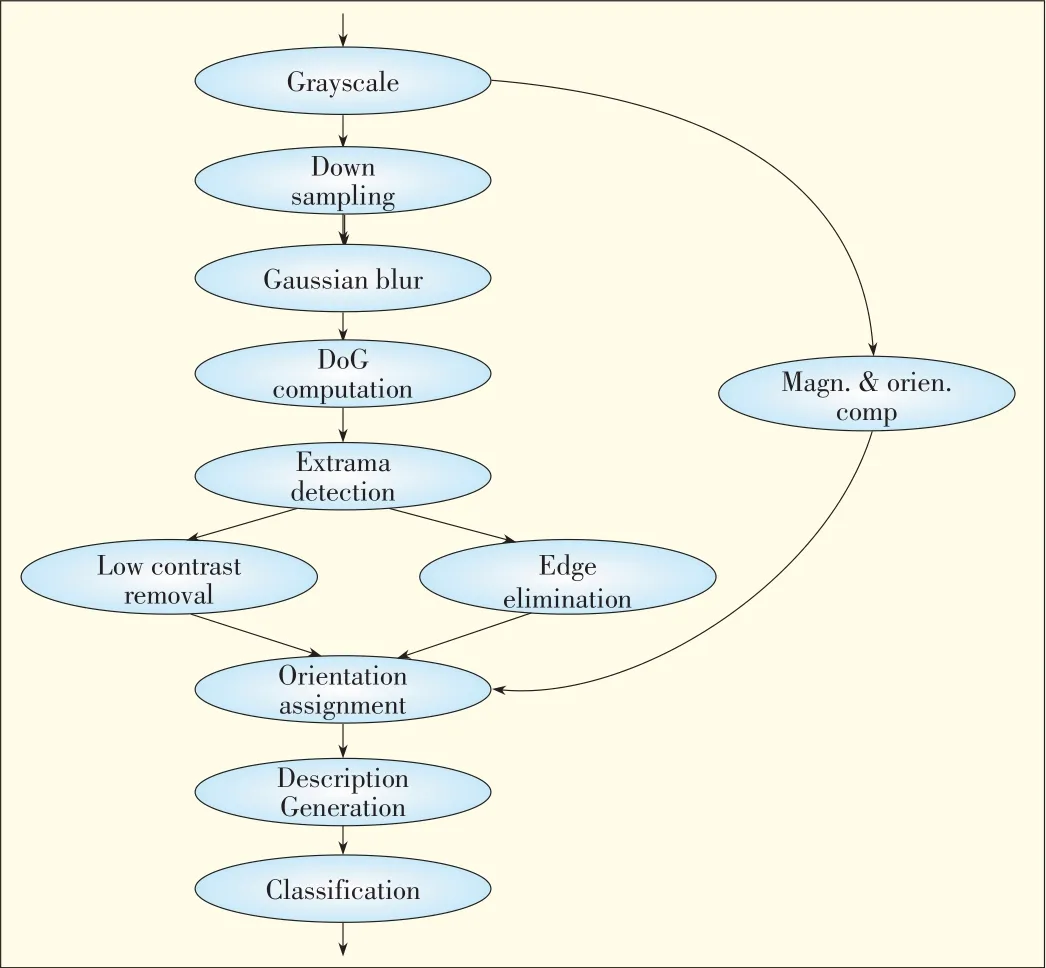
▲Figure3.Dataf low graph for an image-based face-recognition application.
Optimization can be done online or off line.The offline approach is taken to determine the optimal partitions for various execution conditions in the offline phase.In the online phase,one of the partitions is selected according to the current profiling conditions.The more the execution conditions traversed,the more accurate the online partition is.The online approach enables optimization on the f ly according to prof iling condition.Online optimization is accurate but creates overhead.In[4]and[5],the offline approach is taken,and in[3],[9]and[11],theonlineapproach istaken.
Online optimization can be done by the mobile device,in the cloud,or even in a wireless network.Most existing works describe optimization by the mobile device[3],[4],[9],[14].In[11],optimization is done in the cloud.If optimization is done on the mobile device,the prof iled parameters do not need to be transmitted over the network.This causes additional computational overhead on the device.Optimization in the cloud can avoid this problem,but the mobile device needs to be continually connected in order to transmit the prof iled parameters.This is suitable for partitioning complex applications.
3.4 Implementation
We classify implementation approaches to partitioning as client-server communication,VM migration,and mobile agent.The client-server approach requires the program codes to be pre-installed on the cloud servers.When one function of the application isoff loaded onto the cloud,this function is usually performed by the Remote Procedure Call(RPC)protocol or by Remote Method Invocation(RMI).In[15]and[10],the client-server communication approach is taken to implement the partitioned execution.The drawback of this approach is that it is prone to failure due to network disconnection.The codes on the cloud/server side need to be changed from the original codes on the mobile device.Deployment of the partitioningsystemisnot convenient.
Virtual machine(VM)migration is used to implement partitioned execution in[3],[4],[8],and[16].At the mobile side,the application runs on a VM.When a decision is made to offload some part of the application to the cloud,the whole VM migrates to the cloud.The VM migrates back to the mobile side when the application part isf inished in the cloud.Thisapproach does not require the application to be pre-installed in the cloud;however,VM migration creates more overhead than remote procedure call because the execution state of the VM,including the memory and register state,needs to be transmitted.
Scavenger[17]usesamobileagent toimplement remoteexecution.It provides a platform that can help the user easily program and deploy partitioning-enabled applications.Dynamic deployment of application can be realized using this approach.However,agent management is required,and this causes overhead on themobiledevice.
4 Research Challenges
4.1 Energy Efficiency
The processing capability of mobile devices is increasing,and energy consumption has become a significant issue for mobile applications.Most device vendors look for approaches to increasing the battery life.Besides inventing new battery technologies,there are many other approaches to saving energy at the system and application layers.Computation partitioning is an important approach to saving energy on devices.With this approach,energy-consuming components of the application,e.g.computationally intensive algorithms,are of floaded to the cloud.However,the difficulty with this approach is designing effective mechanisms to monitor and profile the energy consumption of applications on mobile devices.Designing models for estimating energy consumption during data transmission is alsonot easy.Both theprof iled information and modelsarecritical topartitioningtheapplication in order tosaveenergy.
We need to design energy-eff icient partitioning software on the mobile device.The computationally intensive part of the computation partitioning software is the optimization.As discussed in thelast section,optimization can bedoneoff line.Partitions that are generated from offline optimization are stored on the mobile device.Whenever the execution environment changes,the application is conf igured with the optimal partition from all the backup partitions.Offline optimization saves energy overhead.In[4],offline optimization is proposed.Another approach to energy saving is optimization in the cloud.We have proposed a partitioning framework that implements optimization in thecloud by usingagenetic algorithm[13].
Other researchers look for techniques to optimize energy consumption during data transmission.Offloading computation to the cloud requires transmission of the computation input data.Issues related to energy consumption during data transmission in computation partitioning need to be tackled.E.Uysal Biyikoglu et al.[18]design an energy-eff icient data transmission mechanism that monitors network quality and transmits the data accordingly.If the network quality is good,data is transmitted;otherwise,no data is transmitted in order to save energy.
4.2 Mobile Access Management
In the mobile cloud partitioning system,mobile access networks such as 3G/4Gcellular networks and wireless local area neworks(WLANs)are important components for connecting the mobile devices to the cloud.The quality or bandwidth of the user's connection to the cloud directly determines the partitioningof theapplication.
4.2.1 Network Intermittence
A practical issue is how to partition the application when the network connection is intermittent.The application is usually partitioned according to a cost model that includes computational cost(on both the mobile and cloud sides)and offloading cost(e.g.data transmission cost).In most works,it is assumed that offloading cost does not change during application runtime.This is not practical in mobile environments.In reality,network connectivity can fail because of wireless network holes,which are places where there is no signal or the signal is too weak to maintain a connection.Even when the network is connected,throughput or bandwidth can fluctuate because of the user's mobility.Fluctuating network status gives rise to offloading cost.
C.Shi et al.[19]solve this problem by assuming future network connectivity is perfectly known.They designed an offline algorithm to calculate the optimal partition given a future network bandwidth.In practical systems,weneed to design an online algorithm to partition the application[20].This algorithm can update the partition of an application from time to time during the course of execution and according to the predicted network status.The prediction of network bandwidth is also a critical issuetobeaddressed.
Several previous works discuss the prediction of future network status from historical mobility observations.Such an approach has been used in other applications,the first of which was wireless sensor network(WSN)data delivery.In[21],routing is improved by using a mobility-prediction algorithm.H.Lee et al.[22]study the problem of delivering data from data source nodes to the mobile sink.They predict the nodes that the mobile sink is likely to pass by and stash data on these in advance.There are also many early works on mobility prediction in cellular/Wi-Fi networks.These works discuss ways of improving network handoff by predicting the next cells/APs[23],[24].
4.2.2 Network Resource Allocation
Another issue is network resource/bandwidth allocation for user-dependent computation partitioning modeling.If mobile users offload computation to clouds through the same access networks,network resources or bandwidth will be limited.We need to allocate resources to mobile users.A user who is allocated more bandwidth has lower off loading cost,and a user allocated less bandwidth has higher off loading cost.Users'partitioning decisions depend on each other because users are competing for shared network resources.Thus,the partitioning problem needs to be solved in light of network resource allocation.
Network resources may include both cellular networks and WLANs.The research problem can be stated in different ways.One way is:we need to allocate cellular network and WLANresources to mobile users so that overall system performance is maximized.Another way is:we need to determine how many of each type of network resource should be leased by the application provider and how to allocate resources to mobile users so that maximumperformance isachieved for the lowest cost.
4.3 Workload Management
Workload management is another important issue in computation partitioning.The workload is the computations off loaded from mobile users to the cloud.The mobile cloud application needs to serve a large number of mobile users.When the scale of applications increases,properly managing the workload at cloud clusters is essential for efficient use of cloud resources and for good system performance.In the user-independent model,workload management is unrelated to the computation partition of each user.Traditional workload scheduling and balancing mechanisms can be used to tackle the problem[25]-[27].Next,we discuss workload management in the user-dependent model.
4.3.1 Workload Schedulingin a Centralized Cloud
In the user-dependent model,the workload management is correlated with the application partition of each user.For good system performance,it is better to consider computation partitioning and cloud workload management together.First,we consider the problem using a simple system model[12].The application is modeled as a sequence of dependent tasks,and mobile users run the same application.On the centralized cloud there is a set of server nodes that accommodate the workload(tasks)off loaded by users.The objective is to schedule the tasks of all users onto their mobile devices and the cloud servers.Each user device can only execute tasks from itself,not from other users.The problem is abstracted as a job-scheduling problem that is similar to(but more diff icult than)a traditional job-scheduling problemsin parallel computing.
The f irst classic job-scheduling problem is Task Scheduling Problem for Heterogeneous Computing(TSPHC)[28].In this problem,an application is represented by a directed acyclic graph(DAG)in which nodes represent application tasks and edges represent inter-task data dependencies.Given a heterogeneous machine environment,where machines have different processing speeds and the data transfer rate between machines differs,the objective of the problem is to map tasks onto the machines and order their executions.In this way,task-precedence requirements are satisf ied,and completion time is minimized.In general,TSPHC is NP-complete,and eff icient heuristics have been proposed in theliterature[28],[29].
The workload-scheduling problem[12]can be modeled as close to TSPHC as possible.In the system model[12],there areλ×n tasks,whereλis the number of users and n is the number of tasks in the application.The machines can be abstracted as a set of r cloud servers/VMs and one mobile device.The data transfer rate between the cloud VMs is infinite but constrained between any pairs of mobile device and cloud VM.The problem is to map the tasks onto(r+1)machines so that the precedence constraints in the application graph are satisfied,and the weighted summation of the completion time of all the tasks is minimized.The tasks that appear last in the application f low are assigned a weighting of one,and others are assigned aweighting of zero.
The key difference between the workload-scheduling problem[12]and TSPHCis the optimization objective.In TSPHC,the optimization objective is to minimize the makespan,that is,the maximum completion time for all the tasks.In[12],the objective is to minimize the total weighted completion time.Although eff icient heuristics have been proposed to minimize the TSPHC makespan,few solutions have been proposed to minimize the total weighted completion time.Some early efforts were made to minimize the total weighted completion time on a single machine or parallel machine,but communication was not considered.Even simplified solutions to the workload scheduling problem in[12]are NP-hard[30].
The second classic scheduling problem is Hybrid Flow Shop(HFS)scheduling[31].In this problem,the job is divided into stages,and there are a number of identical machines in parallel at each stage.Each job has to be processed at stage one,then stage two,and so on.At each stage,the job needs to be processed on one machine only,and any machine will do.It is assumed that all the jobs are released at the beginning,and the problem is to f ind a schedule to minimize the makespan.The application and its functional modules in our problem are analogous to a job and stages in HFS.The mobile devices and cloud VMs may be modeled as machines in HFS.However,the workload-scheduling problem in[12]is much different from that in HFS.In[12],there is communication overhead between stages,which makes the problem more complex than that in HFS.In[12],both the cloud VM and mobile device can execute any module of the application,so a set of machines is not partitioned into subsets according to the stages.The objective in[12]is to minimize the total completion time rather than the makespan.
4.3.2 Workload Schedulingin Distributed Clouds
Workload scheduling in the user-dependent model is more challenging when we consider that the cloud consists of geographically distributed data centers.In this model,there exists a set of mobile users from different regions.Each user has a partitioned execution of the application.The cloud contains a set of data centers that are distributed in different regions.Each data center has a certain capacity in terms of computing resources.For each user,off loading thesamecomponent to various data centers can create different offloading costs because the connection delay and/or bandwidth is different for different data centers.We need to partition the application for mobile users as well as allocate the offloaded computation to computing resources at different data centers.There are two types of workload scheduling:inter-datacenter and intra-datacenter scheduling.Both scheduling types should be considered when partitioning the computation of an application for each user so that overall system performance(e.g.the application execution time)ismaximized.
Several recent works on cloud computing have described solutions to the scheduling problem for distributed clouds[30]-[33].P.Gao et al.[32]developed an optimization framework to schedule data access requests/workloads from users to distributed data centers.The scheduling issue is studied with the aim of minimizing energy consumption in the cloud.Y.Wu et al.[33]studied the scheduling of video-on-demand access requests/workloads to geographically distributed clouds.The scheduling problem was studied together with the video-placement problem.The objective was to minimize the operational cost while satisfying the delay constraints on video access requests.
The request-schedulingproblemfor livevideo streamingapplications was also studied in[34].However,the existing works[32],[33],[34]do not apply to workload scheduling in computation partitioningsystemsbecauseschedulingand partitioning are coupled in the user-dependent model and cannot betreated separately.
4.4 Performance Modeling and Monitoring
An important issue is how to design a performance model for various mobile cloud applications,including applications centered on content delivery and sensing delivery as well as userinteractive applications.All these types of applications have different performance requirements in terms of end users and systems.We need to design an accurate performance model that can illustrate both sets of performance requirements.
To develop such a performance model,we have investigated many software engineering works and ISO standards[35]-[35]that proposed appropriate performance models for various software systems.In Jain's model[37],the system is supposed to give three outcomes for a given request:correct,incorrect,or refusal to give an outcome.Three system performance metrics have also been def ined:speed,reliability,and availability.The performance model for a mobile-cloud partitioning system needs to be developed by adding more practical performance metrics,such as Service-Level Agreement(SLA),time behavior,utilization,capacity,and recoverability.
Another issue is how to detect anomalies or performance degradation in amobile-cloud partitioningsystem.In traditional internet applications,anomalies are detected by manually analyzing the logs[38].This method is not feasible for a largescale cloud system.Some researchers have taken a pattern recognition approach[39],[40]to automating the analysis of massive volumes of system logs.Because of the complex computational cost of analysis,this approach is not feasible for a system that requires real-time anomaly detection and recovery.Methods based on log analysis are not enough to detect anomalies or performance degradation in mobile cloud applications.Usually,the performance of a mobile cloud application depends on more complex factors,including failure or ineff iciency of the mobile device,wireless network,or clouds.Collecting and analyzing logsfrommobile devicesmay not bepossiblebecause of high costs or privacy issues.Faced with these diff iculties,weneed todevelop suitableapproachesto detectinganomalies and performance degradation in mobile cloud applications.
To solve this detection problem,we can use a hybrid method that integratestheloganalysisand real-timeperformancemonitoring.At the cloud side,we can detect anomalies by analyzingthesystemlogs,and at themobileside,wecan design lightweight performance monitors.We also need to design network protocols to monitor the performance of interactions between mobilesand the cloud.
4.5 Security
There are three security issues in a mobile cloud partitioning system.The first issue is authentication between computations that pertain to the same application.Authentication indicates the secure communication channel between two computations that may be executed on different mobile or cloud platforms.The second issue is access control for sensitive user data.Because the computations of an application may run on a public,untrusted cloud platform,we should design secure mechanisms for controlling access to sensitive data from mobile devices.For example,computation requires access to very sensitive data,it is better to do that computation in trusted environments,e.g.on themobiledeviceor on atrusted cloud platform.The third issue is to build and verify a trusted execution environment,including the mobile platform and cloud platforms.This is a fundamental problem in cloud computing.The work by X.Zhang et al.[41]is one of the few works that describesecurity problemsspecif ically for mobilecloud partitioning systems.The authors propose a solution for authentication and secure session management between weblets/computations runningat thedevicesideand cloud side.Theauthorsalsopropose a secure migration mechanism and approach to authorizing cloud webletsto accesssensitive user data.
5 Summary of Our Own Work
We reviewed the related literature and found that several new and challenging issues need to be urgently addressed.First,little work has been done on partitioning data-streaming applications(which are quite popular today)because of a device's ability to collect streaming media data.The challenge is how to design models and architectures for partitioning these applications.Second,wireless connectivity loss and bandwidth f luctuations often occur in mobile environments.The challenge is in designing partitioning mechanisms that can still guarantee high performance in these conditions.Third,for largescale mobile cloud applications,the number of mobile users(mobile load)can be unpredictable.The challenge isin designing partitioning mechanisms that can achieve optimal overall performance,even when the systemisoverloaded.
In our work,we develop and implement a real-world application,and we show that computation partitioning is a feasible way of improving performance.Then,we propose our solutions in terms of the above challenges.Our research on this topic can be categorized as computation partitioning in an RFID tracking application,performance optimization for user-independent computation partitioning,and performance optimization for user-dependent computation partitioning.
We study the application of computation partitioning in an RFID tracking application[42].We focus on a system for attaching RFID readers on moving objects,and we deploy passive RFID tags in the environment.The moving object collects the noisy RFID readings and continuously estimates its position in real time.Traditional approaches,such as Particle Filter(PF),can by highly accurate but require much computation on the device.These approaches are difficult to implement on mobile devices that are constrained in terms of computing capability and battery.Other existing approaches,such as Weighted Centroid Localization(WCL),are cheap in terms of computational cost but are very inaccurate,especially when the object is moving quickly.Thus,we propose an adaptive approach to achieving accuracy and energy efficiency.Our approach can be used to choose costly PFor cheap WCL,depending on the estimated speed of the object.It can also be used to adaptively partition the computations between the mobile device and infrastructure servers or clouds(depending on the quality of the network connections).We evaluate our solution in real-world experiments and show that our proposed computation partitioning scheme outperforms other schemes in terms of accuracy and energy consumption.
We also study two issues in user-independent computation partitioning,where every user can make their partitioning decision according to their own information.The f irst issue is partitioning of the data-streaming application.Existing approaches can be taken to optimize the makespan of streaming applications.Throughput/processing speed is more important for streaming applications.We propose an algorithm to maximize throughput and develop a reference-implementation architecture for partitioning and execution of streaming applications[11].The second issue is solving the computation partitioning problem when network connectivity is intermittent and bandwidth fluctuates.The existing one-time partitioning approach may significantly degrade performance when the network fluctuates.We develop a predictive partitioning algorithm that exploits knowledge of user's mobility to predict network status,and weupdatethepartition based on thepredicted network status[20].We evaluate our approach according to real data traces that are collected in a campus Wi-Fi hotspot testbed.The results show that our method significantly reduces completion time compared with previousapproaches.
Last,we study the same issues in user-dependent computation partitioning.Most related works pertain to the user-independent model,but we are the first to study and propose a user-dependent computation partitioning model[12].In this model,user partitioning decisions depend on each other because users compete for some shared resources,e.g.cloud servers and wireless access bandwidths.Thus,to achieve high system performance,allocation of shared resources needs to be considered in conjunction with user partitioning.This problem is different from and more diff icult than classic job-scheduling problems.We design both offline and online algorithms to solve this problem.With benchmarks,we show that our off line algorithm outperforms listing scheduling algorithms by 10%in terms of application delay.We also validate the eff iciency of our onlinealgorithmusingreal-world load traces.
6 Conclusion
The rise of mobile cloud computing is rapidly changing the ITlandscape.Computation partitioning has recently been studied in order to achieve high-quality service provisioning and operational eff iciency for the cloud providers.Despite the signi f icant benef its offered by the new computing paradigm,current technologies are not mature enough to realize its full potential.Challenges related to energy eff iciency,mobile access management,workload management,performance modeling and monitoring,and security still exist in this domain and are beginning to attract the attention of the research community.This paper discussed state-of-the-art mobilecloud computation partitioning.It covered system models,key technologies,and research issues and directions.This work is intended to deepen the understanding of design challenges in mobile cloud computing and pavetheway for further research in thisarea.
Acknowledgments
The research is supported in part by Hong Kong RGCunder GRF Grant 510412,and the National High-Technology Research and Development Program(863 Program)of China under Grant 2013AA01A212.

- ZTE Communications的其它文章
- Cloud Computing
- Software-Defined Data Center
- MapReducein the Cloud:Data-Location-Aware VM Scheduling
- Preventing Data Leakagein a Cloud Environment
- CPPL:A New Chunk-Based Proportional-Power Layout with Fast Recovery
- Virtualizing Network and Service Functions:Impact on ICT Transformation and Standardization