
基于广义Hough变换的手写汉字文档关键词提取
2013-05-14 11:33陈睿,唐雁
网络安全与数据管理 2013年6期
陈 睿,唐 雁
(西南大学 计算机与信息科学学院,重庆400715)
从手写汉字文档图像中提取关键词是一项重要的任务,它能够作为文本相关笔迹鉴别的预处理步骤,其实质是从数字图像中识别和定位目标物体。目标物体识别一般通过将目标物体模型的特征与数字图像中检测到的实体的特征进行匹配的方式实现。学术界提出了大量基于整体和局部方法的能够抗旋转和位移的目标物体识别和定位技术[1-3]。整体方法基于整体特征,如边界和区域。这些方法包括不变矩、Fourier描述子和互相关。局部方法使用局部特征,包括关键点(Dominant Point)、局部最大曲率和多边形近似。
Hough变换是检测直线、圆和其他解析曲线的有效方法,对它的研究一直非常活跃[4-5]。Hough变换在目标识别中有效的原因就在于其把目标的识别转化为对在参数空间投票多少的判定。最初的Hough变换只能用来检测形状有解析表达式的目标。为了检测形状任意的、没有解析表达式的目标,BALLARD[5]提出了广义Hough变换(GHT)算法。GHT的实质也是让轮廓边界点进行投票,只是投票地点不是由表达式的参数确定,而是定义一个参考点和一套投票机制,通过投票的集中程度来判定目标是否存在。GHT解决了任意形状边界目标的识别,但它需要目标物体的完整轮廓边界点信息。
对于手写汉字文档图像中的关键词提取问题,也可以看作是一类特殊的目标识别问题,其特殊之处在于手写汉字字符和单词没有一个完整的轮廓,即使找到汉字的最小外包轮廓也不能描述汉字的大量内部形变结构特性。然而,基于点对点匹配投票思想的广义Hough变换同样适用于手写汉字的目标识别问题。这就需要对传统的基于轮廓边界点的投票机制进行改进,改为基于每个字符像素的投票机制,同时局部特征和匹配策略也要做相应的修改。
[6]提出了一种改进的 GHT变换算法,能有效地对具有旋转和部分遮挡的物体进行识别。它采用一个两阶段的GHT策略,将三维参数空间(旋转角度θ、横轴坐标x和纵轴坐标y)转化为一个一维参数空间(θ空间)和一个二维参数空间(x-y空间)进行投票,将 θ空间中投票的结果用作x-y空间投票的条件,降低了运算量,提高了识别精度。但是该算法有很大的局限性:(1)它需要目标的完整轮廓,这对汉字字符和单词不适用;(2)它假定场景图像中只包含一个待识别的目标物体,否则x-y空间的投票无法进行,这就无法实现对场景中包含的多个目标物体进行匹配定位。
1 改进的广义Hough变换算法
针对手写汉字的特点,对广义Hough变换做了改进。首先将模板图像和文档图像进行二值化和骨架化,对模板图像中的每个字符像素提取5个局部特征作为参考表的内容,分别是分叉数、曲率、法线方向、重心夹角和重心距离;再用文档图像中的每个字符像素与参考表中的每一项进行匹配投票。下面依次介绍这5种局部特征。
1.1 分叉数
分叉数是与字符像素相连接的分支数目。传统的分叉数计算方法是对字符像素的8个邻接点计算顺时针(或逆时针)方向上像素值由1到0的跳变数目。由于手写汉字骨架图中形变大、分支多,断裂和冗余连接普遍存在,采用传统的分叉数计算方法不能充分体现字符的分叉程度。针对这个问题,提出了一种改进的计算分叉数的方法。
设经过二值化和骨架化的模板图像为 R,R={rij|i=1,…,m;j=1,…,n},其中 m 和 n 分别为模板图像的行数和列数,字符像素定义为R中值为1的点。对于当前考虑的字符像素rij,其半径为t的邻域定义为:A(rij)={rxy|x=i-t,i-t+1,…,i+t;y=j-t,j-t+1,…,j+t}。下面给出字符像素rij在半径为t的邻域中的分叉数的计算。
算法 1:y=ForkNum(R,i,j,t)
(1)置 y=0,A(rij)={rxy|x=i-t,i-t+1,…,i+t;y=j-t,jt+1,…,j+t};
(2)从A(rij)的左上角开始沿顺时针方向将A(rij)的边界点依次放入点集 P,P(rij)=A1,1…2t+1∪A2…2t+1,2t+1∪A2t+1,2t…1∪A2t…2,1={pi|i=1, …,8t};
(3)依次从 P中读取每个像点 pi(i=1,…,8t)的值,当pi=1 且 pi+1=0 时,置 y=y+1;当 i=8t时,将 p1作为 p8t+1考虑;
(4)输出分叉数 y,算法结束。
如图1所示,黑色方块表示字符像素,其中包含白色圆点的黑色方块表示当前考虑的字符像素,方形区域代表当前考虑的二维邻域,其大小为 11×11(半径为5)。图1(a)~图1(f)分别代表分叉数从1~6的情况。如果采用传统的分叉数计算方法,这6种情况下的分叉数都为2。从图中可以看出,采用本文方法得到的分叉数能够较准确地反映出字符的局部分叉程度。邻域大小的选择很重要,当邻域大小为3×3时,本方法等价于传统的分叉数计算方法。当邻域过大时,由于笔画断裂的原因,得到的分叉数不能准确反映字符的局部分叉程度。本实验中,采用字符大小的20%左右的邻域计算效果最好。例如,对于平均字符大小为25×25的汉字文档图像,采用11×11的邻域进行计算。
1.2 曲率
曲率是表示曲线弯曲程度的量。平面曲线的曲率就是针对曲线上某个点的切线方向角对弧长的转动率,通过微分来定义,表明曲线偏离直线的程度。曲率越大,表示曲线的弯曲程度越大。对于汉字字符图像的每个像素,其曲率反映了笔画的弯曲特性。对于给定大小的邻域,采用边界点到中心点连线的向量夹角来表示曲率,其范围是[0,180°)。
算法 2:y=Curvature(R,i,j,t)
(1)置 y=0,用算法 1 的方法计算 A(rij)和 P(rij);
(2)依次从 P中读取每个像点 pi(i=1,…,4t)的值,将其中连续值为 1的点划分到集合 Sj(j=1,…z,z≤2t)中;如果 p1=1 且 p4t=1,则置 S1=S1∪Sz,z=z-1;
(3)依 次 计 算 Sj(j=1, …z,z≤2t)中 每 个 点 集 的 重 心位置 cj,并将其加入到集合 C 中,得到 C={ck|k=1,…,z};
(4)依次取出 ck和 ck+1,以 ck为起点、rij为终点建立向量 v1,以 rij为起点、ck+1为终点建立向量 v2,计算 v1和v2的夹角 θ,置 y=y+θ;当 k=z时,将 c1作为 cz+1考虑;
(5)置 y=y/z,算法结束。

如图2(a)所示,白色圆点O代表当前考虑的字符像素,白色圆点A和B代表两个边界点集的中心点,像点O的曲率定义为向量AO和OB的夹角。对于图2(a)中的像点O,其曲率为15.26。对于分叉数大于2的字符像素,其曲率为相邻边界点集的中心点两两组合后与字符像素构成向量的夹角的平均值。如图2(b)所示,白色圆点O代表当前考虑的字符像素,白色圆点A、B和C代表三个边界点集的中心点,像点O的曲率定义为向量AO和OB的夹角、BO和OC的夹角及CO和OA的夹角的平均值,即 23.20°、151.70°和 5.10°的平均值 117.83°。
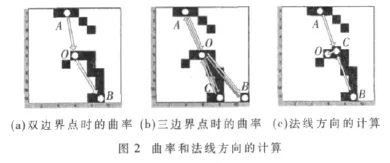
1.3 法线方向
曲线的法线是垂直于曲线上一点的切线的直线。对于具有相同曲率的笔画段,若其旋转角度不一样,则表明两字符具有较大差异。这个差异可以通过字符像素的法线方向来体现。对于给定大小的邻域,法线方向为边界点连线中点与当前考虑像素的连线构成的向量的方向角,即与横轴按逆时针方向所成夹角,范围是[0,360°)。
算法 3:y=NormalAngle(R,i,j,t)
(1)置 y=0,用算法 1 和算法 2 计算 A(rij)、P(rij)、集 合 S和集合 C={ck|k=1,…,z};
(2)依次取出 ck和 ck+1,计算 ck和 ck+1的连线中点 mk,以mk为起点、rij为终点建立向量v,计算v与横轴夹角θ,θ∈[0,180°);若 v 在三、四象限,置 θ=360°-θ。 置 y=y+θ;当 k=z时,将 c1作为 cz+1考虑;
(3)置 y=y/z,算法结束。
如图2(c)所示,像点O的法线方向定义为线段AB的中点C与O所构成的向量CO的方向角,其值为198.94°。对于图2(b)中像点 O的法线方向,由线段 AB、BC、CA的中点为起点,O为终点的3个向量的方向角的平均值构成, 即 213.40°、120.85°和 19.25°的平均值为117.83°。
1.4 重心夹角
对于模板图像中的每个字符像素,它与模板图像重心连线构成的向量的方向角定义为重心夹角,值域为[0,360°),记为 GravityAngle(rij)。 如图3 所示,字符像素 A的重心夹角定义为模板图像重心O到A构成的向量OA的方向角,其值为 151.09°。
1.5 重心距离
重心距离定义为字符像素到模板重心的连线的长度,记为GravityDist(rij)。如图3所示,字符像素A的重心距离即OA的长度,其值为11.16。
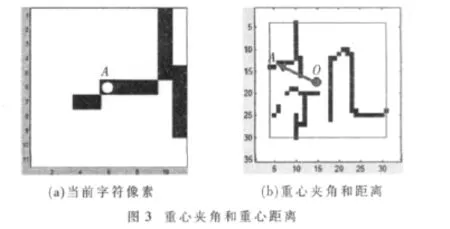
1.6 参考表
对于给定模板图像的每个字符像素,计算上述5个局部特征,它们构成了参考表RTable中的一行。在后续的匹配过程中,对文档图像中的每个字符像素也提取这5个局部特征,然后与参考表中的每一行进行匹配,如果匹配度大于某个阈值,则在参数空间中进行投票,最终在参数空间中形成局部峰值,即定位到的模板图像的位置。
对于图4(a)中的模板图像“计算机”的每个字符像素,计算它的5个局部特征,得到图4(b)中的参考表,其中每一行对应一个字符像素的5个局部特征。

1.7 投票算法
设经过二值化和骨架化的模板图像和待检索的文档图像分别为 R 和 I,其中 R={rij|i=1,…,m;j=1,…,n},I={ixy|x=1,…,k;y=1, …,l},k>m,l>n; 参 考 表 为RTable(rt)={rts|s=1,…,z};邻域半径为 t;角度差阈值为ta;参数空间图像为 S,S={sxy|x=1,…,k;y=1,…,l},k>m,l>n;匹配度阈值为 tm;匹配度定义为 sxy与 R中字符像素个数的比值,投票算法如下:
算法 4:Vote(R,I,Rtable,ta,tm)
(1)依次读取I中的每个字符像素 ixy(ixy≠0),在给定邻域 t中计算它的 5个局部特征 ForkNum(ixy)、Curvature(ixy)、NormalAngle(ixy)、GravityAngle(ixy)和 GravityDist(ixy);
(2)对于当前 ixy,依次读取参考表的每一行的 5个特 征:RTable(rts,1)、RTable(rts,2)… RTable(rts,5)。 如 果RTable(rts,1)≠ForkNum(ixy), 取 下 一 个 ixy, 重 复 步 骤 (2);若 abs(RTable(rts,2)-Curvature(ixy))>ta|abs(RTable(rts,3)-NormalAngle(ixy))>ta,取下一个 ixy,重复步骤(2);
(3)用 RTable(rts,4)和 RTable(rts,5)计 算 模 板 图 像 中以字符像素rts为起点、重心点G为终点的向量v,做向量运算ixy+v得到参考图像S中的投票点sxy,置sxy=sxy+1。取下一个 ixy,转步骤(2);
(4)统计 S中所有 sxy,sxy>tm,将其作为匹配点画出外包矩形。
2 实验
本文对96名学生建立了一个手写文档数据库,每名学生都书写了一段相同的文字。如图5所示。图5(a)中的关键词取自图5(b)中左上角的“计算机”,它们都经过了二值化和骨架化处理。在图5(b)中,标记投票数超过给定阈值的点,并对以该点为重心的关键词还原其大小,用方框标出。在这个例子中,角度差阈值取为30,邻域半径取为5,匹配度阈值取为0.07。从图中可以看出,匹配点和方框集中的地方就是关键词出现的地方,算法对关键词“计算机”的提取非常准确。


图6为对图5(c)中模板图像进行匹配定位的结果,其中图5(c)的关键词取自图6中右下角的“计算机”。在这个例子中,角度差阈值取为30,邻域半径取为 5,匹配度阈值取为0.055。从图中可以看出,算法找出了全部9个“计算机”的准确位置,但是在图像的右上部分出现了一个误匹配,将“处理图”和“计算机”匹配,其原因为算法在计算字符像素的局部特征时只考虑了该像素邻域中的字符形状特征,不能描述模板图像整体的特征,加上手写汉字骨架图中形变大、分支多,断裂和冗余连接大量存在,影响了算法定位的准确性。针对这个问题,对匹配定位的结果,即提取出的关键词图像,与原模板图像进行相关运算,去掉相关度低于给定阈值的匹配结果。经过实验统计,给定合适的阈值(其范围是[0.5,1.2]),在96篇手写文档中“计算机”整词匹配的正确率能够达到85%。
本文提出了一种基于广义Hough变换的手写汉字文档关键词提取技术。本技术使用具有形变的手写关键词图像作模板,对该模板的每个字符像素抽取局部特征建立参考表。对于待提取的手写文档图像,采用字符像素逐点匹配和投票的方式进行广义Hough变换,在参数空间中定位出手写关键词图像的位置。本算法对手写汉字文档图像中具有局部形变、部分旋转和缩放的手写关键词能够有效提取。后续工作如下:对文档图像进行字符分割,对单个字符进行匹配定位。在此基础上,对超过一定数目且位置相邻的字符进行组合得到整词,再进行整词匹配提取关键词,建立训练集以进行笔迹鉴别。
参考文献
[1]LENG W Y,SHAMSUDDIN S M.Writer identification for Chinese handwriting[J].Int.J.Advance.Soft Comput.Appl,2011,2(2):160-173.
[2]Tan Jun,Lai Jianhuang,Wang Changdong.A stroke shape and structure based approach for off-line Chinese handwriting identification[J].I.J.Intelligent Systems and Applications,2011,3(2):1-8.
[3]MOKHTARIAN F,MACKWORTH A K.Scale-based description and recognition of planar curves and two-dimensional shapes[J].IEEE Trans Pattern Anal Mach Intell,1986,8(1):34-43.
[4]HAN M H,JANG D.The use of maximum curvature points for the recognition of partially occluded objects[J].Pattern Recognition Pattern Recognition,1990,23(1-2):21-33.
[5]BALLARD D H.Generalizing the Hough transform to detect arbitrary shapes[J].Pattern Recognition,1981,13(2):111-122.
[6]TSAI D M.An improved generalized Hough transform overlapping objects[J].Image and Vision Computing,1997,15(12):877-888.
猜你喜欢
农业工程学报(2022年7期)2022-07-09
故事作文·低年级(2021年12期)2021-12-21
作文成功之路·小学版(2020年7期)2020-08-24
吉林大学学报(理学版)(2020年3期)2020-05-29
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
电子制作(2018年18期)2018-11-14
自动化学报(2018年7期)2018-08-20
