
基于词汇链与互信息的关键词抽取研究
2013-05-10 12:08任莉莉方元康
池州学院学报 2013年6期
任莉莉 ,方元康 ,2
(1.池州学院 数学与计算机科学系,安徽 池州 247000;2.南京航空航天大学 计算机学院,江苏 南京210016)
引言
随着现代科技和信息技术的迅猛发展,网络上的数据以接近指数级的速度在递增。如何科学、准确、快速地从这海量的数据中检索到有价值的信息,已成为当前需要迫切解决的问题之一。目前中文文档中关键词出现的数量一般为3~8个,且相互间存在着一定的相关性,关键词不仅能快速直观地表达文档主题内容,更为重要的是对一篇文档内容的高度凝练。
国内外对关键词自动抽取技术进行了大量的研究,也取得了一系列的研究成果。主要有:(1)基于词的统计信息的方法,比较典型的有:TFIDF、词共现、复杂网络等方法[1-2],这类算法相对简单易行,通用性较好,解决了早期快速抽取关键词的问题。但没有考虑到文档的句子结构、语义内容及其属性,往往会出现与主题无关的高频词,不能深入挖掘文本语义内容;(2)基于机器学习的方法,比较典型的有:朴素贝叶斯算法[3],基于决策树的算法以及基于最大熵算法[4]。此类方法比较耗时,需要大量带关键词标注的数据去建立关键词的分类模型。(3)基于语义的方法,典型的有通过构建词汇链抽取文档关键词,虽然词汇链能够表达文档的语义结构,但是,在其过程中需要判断词语间的语义相似度,而语义相似度的计算需要知识库的支持,因此,未包含词及其关键短语,不能被很好地识别,从而影响关键词抽取的质量[5-6]。
针对现有关键词抽取方法存在的不足,提出了一种既考虑词语的语义关系、又兼顾词语的统计分布,即综合考虑词汇链和互信息的关键词抽取算法,有效地解决现存关键词抽取准确率较低之不足,在抽取关键词的准确度方面有明显的提高。
1 相关研究
1.1 词汇链
词汇链是由Hirst于1991年首先提出,是一系列语义上相关的词汇所组成的集合,这些词汇围绕一个主题而被集合在一起,能够反应文本的主题信息。词汇链在计算机理解语义以及理解文档主旨方面具有重要的作用,因此而被广泛应用于机器翻译、信息检索、文本挖掘等知识领域。对于任意一篇文档都可以得到若干词汇链,这些词汇链所表达的主题共同决定了文档的主旨。因此,可以借助词汇链表达词语间的语义关系以及消除包含在 《知网》中词语的语义歧义。构建词汇链的思路为:初始化词汇链;选取候选词汇集中的第一个词语w1的语义构成初始词汇链L1;依次读入候选词汇集中每个候选词的语义序列;计算候选词汇集中每两个词语的语义相似度,如果最大相似度大于预设的阈值,则加入对应词汇链的尾部,否则建立新的词汇链;直至候选词汇集中所有的词汇计算完毕。
1.2 互信息
互信息是统计模型中衡量两个随机变量之间关联程度的常用参数,反映了两变量之间结合的紧密程度。在研究自然语言词语相互关系时,互信息可以被作为描述两个词语之间相互关联程度大小的度量,它不依赖于知识库的特点,为解决未包含词的抽取提供了思路。若两词语的互信息值较大,说明两个词语之间的相关联性越大。反之,说明两个词语之间的相关联性越小。
定义1 若wi和wj为中文文档中的两词语,p(wi)表示词语wi出现的概率,p(wj)表示词语wj出现的概率,p(wi,wj)表示联合概率,MI(wi,wj)为两词语的互信息,则:

式(1)[7]描述了两词语紧密结合的程度。其中,MI(wi,wj)>>0:表明 wi和 wj关联强度大;MI(wi,wj)≈0:表明 wi和 wj无关;MI(wi,wj)<<0:表明 wi和 wj具有互补的分布,不存在关联的关系。
1.3 候选关键词的权重计算
1.3.1 特征的选取 候选关键词有众多的特征,综合考虑各方面因素,选取以下特征作为候选关键词的特征:(1)TFIDF:计算词语在大规模语料中的重要性,即词汇在文档中出现的次数越多,而且在别的文档中出现的次数越少,就认为该词语在文档中的权重越大。(2)位置特征:表示词语在文档中出现的位置,如:出现在标题、主题句以及结论部分中的词语极为重要,不同的位置特征也反映了该词语在文档中的重要程度。(3)词汇链的长度:即词汇链所包含词语的数目。(4)相关度:表示该候选词与其它候选词之间的语义相关度,与文献[9]不同的是,本文采用的计算相关度方法,不但可以有效解决部分未登录词的重要性问题,亦可以解决部分具有极高关联性而相似度值不理想的问题。
1.3.2 权重计算 候选关键词的选取使用下面的权重计算公式:

其中:TFIDFi为词频特征;Loci为位置特征;Chain为词汇链的长度,即该链包含词语的数目;Ri为词汇的语义相关度。a,b,c,d分别为系数因子,当不采用某类特征时,其系数因子设置为0。
2 基于相似度和互信息的相关度计算
《知网》将义原分为10大类,每一类都是由一个树状结构来表示。义原在树中的上下位关系构成了相似关系,横向关系构成了其关联度。对于《知网》中的词语可以通过计算其语义相似度来建立词汇链。本文采用[8]提出的基于《知网》的词语语义相似度计算方法。而有时《知网》中的词语间相似度值不是很理想,却有很高的相关联性,例如:“计算机”和“软件”相似度值不理想,但却有着很强的相关联性;对于未包含词,在具体的文章中也非常有意义,亦可以用相关联性表示其深层语义特征,因此,词语间的相关联度对于文档的中心思想也有一定的指示作用,在某种程度上也能表达文档的深层语义特征。互信息为解决以上问题提供了新的思路。本文探索性地把统计中的互信息模型引入到语义分析中,试图提高关键词抽取的性能。
定义2设词语wi和词语wj为文档中的两词语,且 Sim(wi,wj)为两词语的语义相似度,MI(wi,wj)为两词语的互信息值,R(wi,wj)为两词语的相关度,则:

式(2)描述了两词语相关性的强弱,其中,α、β为可调节的参数,α+β=1。参数α、β对于两部分的重要性,由于前者更能反映语义信息,因此参数α的设置偏重些,实验中设为0.6。
一词语与该词所在词汇链集中的其它词语的R值进行相加,如果Ri的值越大,则表示它和候选关键词义集合中其它词的关联程度越大,因此,可以作为判断词语重要性的依据。如公式(3)所示:

3 算法的描述
输入:过滤后的文本。
输出:反映文档主题的关键词。
步骤1数据预处理。对过滤后的文本进行分词,过滤停用词,统计每个名词在文本中出现的频率、词性特征以及位置标注。分词工具使用中科院计算技术研究所研制的基于层叠隐马尔可夫模型的汉语词法分析系统。该系统具有中文分词、词性标注、用户词典等功能。选取其中的名词及名词性词组组成词汇集。
步骤2利用下列公式计算词汇集中每个词汇的TFIDF值,选取n个TFIDF值最大的词汇构成候选词汇集{w1,w2,w3,…,wn}。

其中,TFIDFi为词汇在文档中的权重,tfi为词汇在文档中出现的次数,ni为包含词汇的文档数,N为语料库中的文档总数。
步骤3词汇语义相似度的计算。利用定义1中的公式计算候选词汇集中任两个词汇的互信息值及文献[8]中的算法计算包含在《知网》中任两个词汇的语义相似度。
步骤4对于《知网》中的词语构建词汇链。构建词汇链的过程见2.2节。
步骤5对于未登录词,计算其与词汇链中每个词语的互信息值,若大于0,加入该词对应词汇链的尾部。
步骤6重复5,直至全部候选词语计算完毕。
步骤 7 利用公式(3)计算 Ri的值、公式(4)计算每个词语的权值。最后按权值的降序对候选词汇集中的词语进行排序,输出最后的结果。算法中出现的参数,n取值为20,相似度阈值取0.3,实验效果较好。
4 实验设计与结果
4.1 评价标准
评价标准:准确率和召回率作为测试抽取效果的指标。准确率是自动标引正确的关键词数目与自动标引的关键词数目的比值,表示:

召回率是自动标引正确关键词数目与手工标引正确关键词数目的比值,表示:

4.2 实验方法
实验数据来源于复旦大学国际数据库中心自然语言处理小组提供的中文分类语料,该语料共为2815篇文本,随机选取其中的五百篇进行实验。其中环境类、计算机类、交通类、教育类、经济类、军事类、体育类、医药类、艺术类、政治类各50篇。首先手工从每篇文档中标注关键词,然后使用基于统计的关键词抽取方法、基于词汇链的关键词抽取方法和本文提出的方法进行关键词抽取,并用3.1的评价标准进行评价。
4.3 实验结果及分析
图1、图2列出了三种关键词抽取方法进行比较实验结果。分别设抽取关键词数目为3、5、7、10时,进行四组对比。实验结果显示:基于词汇链和互信息的算法性能最好,接下来是词汇链的算法,性能最差的是统计的算法。从研究结果中可以看出:词汇链和互信息综合考虑后,关键词抽取的性能更佳。
通过对比可以看出:当抽取关键词数目为3、5时,准确率依次递增;当抽取的关键词数目为5、7、10时,准确率依次递减。从数据分析还可以得出:本文提出的算法其性能、稳定性相对较好,因为除了考虑词频因素以外,还兼顾到语义因素,因此,一些词频相对较低,相似度不是很理想而具有很高相关度的、贴近文章中心思想和深层语义信息的关键词能被抽取出来。所以,关键词数分别为5、7、10时,准确率依次递减。

图1 不同关键词抽取方法精确率对比
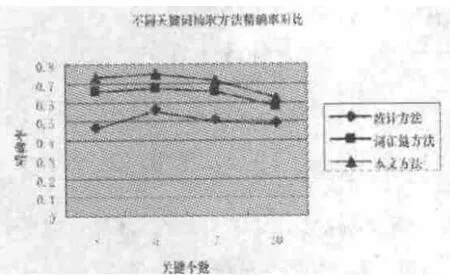
图2 不同关键词抽取方法召回率对比
5 结束语
基于词汇链和互信息的集成创新,建立了一种新的关键词抽取算法。分析词语之间的语义关系,结合词频特征、位置特征、改善部分未包含词及相似度不理想而具有很高相关联度的关键词识别问题,实验表明,此方法抽取的关键词更贴近文档的深层语义,表现出良好的抽取效果。
[1]Akiko A.An information-theoretic perspective of tf-idf measures.Information Processing and Management,2004,39(1):45-65.
[2]任克强,赵光甫,张国萍.基于带权语言网络的网页关键词抽取[J].计算机工程与应用,2008,44(8):155-157.
[3]Witten I H,Paynter G W,Frank E,Gutwin C,Nevill-Maning C G.KEA:Practical automatic key-phrase extraction[C]//Proceedings of the 4th ACM Conference on Digital Libraries.Bereley,CA,USA,1999:254-255.
[4]李素建,王厚峰,俞士汶,等.关键词自动标引的最大熵模型应用研究[J].计算机学报,2004,27(9):1192-1197.
[5]王立霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(1):1-4.
[6]索红光,刘玉树,曹淑英.一种基于词汇链的关键词抽取方法[J].中文信息学报,2006,20(6):25-30.
[7]袁里驰.一种基于互信息的词聚类算法[J].系统工程,2008,26(5):120-122.
[8]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,5(2):59-76.
[9]刘金岭,冯万利,张永军.基于词汇链的中文短信主题语句抽取方法[J].计算机工程与应用,2012,48(7):132-134.
[10]刘铭,王晓龙,刘远超.基于词汇链的关键短语抽取方法的研究[J].计算机学报,2010,33(7):1246-1255.
[11]倪娜,刘凯,李耀东.科技文献关键词自动标注算法研究[J].计算机科学,2012,39(9):175-179.
[12]蒋效宇.基于关键词抽取的自动文摘算法[J].计算机工程,2012,38(3):183-186.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
开放教育研究(2020年2期)2020-03-31
信息安全研究(2016年4期)2016-12-01
现代语文(2016年21期)2016-05-25
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
电测与仪表(2015年9期)2015-04-09
弹箭与制导学报(2015年1期)2015-03-11
