
Silvermont架构:英特尔的反攻尖兵
2013-04-29 00:44:03
CHIP新电脑 2013年7期

弹指一挥间,第一代Atom处理器发布到如今已经整整5年了,5年对于IT业界而言是一个不算短的时间。不过,Atom处理器却没有如英特尔期待的那样,复制它的前辈们在桌面和笔记本电脑平台上的辉煌:除了在上网本和一体机流行的时期有过短暂的惊艳表现之外,大多数时间它都纠结于并不出色的性能、令人难以接受的耗电量和较大的发热量之间。它的对手——ARM架构处理器则在新兴的智能手机和平板电脑市场中出尽了风头,甚至把触手伸向了服务器领域。
但是平心而论,这5年来Atom处理器的进步可谓非常显著。无论是从晶体管数量、运算能力还是从微架构革新等方面来看,Atom处理器的发展速度都超越了摩尔定律的藩篱,甚至创造了x86处理器的多项“第一”,特别是x86架构SoC处理器实现了可谓革命性的进步。
虽然此前英特尔似乎并未把精力过多放在Atom平台上,但目前这种情况似乎有所改观。Sivermont架构的Atom处理器有望成为英特尔在低功耗高性能处理器领域扭转乾坤的里程碑。
Silvermont:英特尔的新微架构
英特尔5月中旬刚刚发布了Silvermont微架构,这也是英特尔寄予厚望、对抗ARM Cortex A15内核的秘密武器。与上一代微架构Saltwell相比,Silvermont有着诸多新特性。
全新的乱序执行引擎
数年前的手持移动设备处理器,如ARM Cortex A8内核处理器、英特尔早期的Atom(Bonnell)以及高通的Scorpion处理器都采取“顺序执行”模式。从Coretex A9开始,ARM采用了乱序执行的设计,CoretexA15则采用更优化的管线进一步提升了性能。针对这样的形势,英特尔将Atom升级为采用了乱序执行引擎的Silvermont微架构也顺理成章。
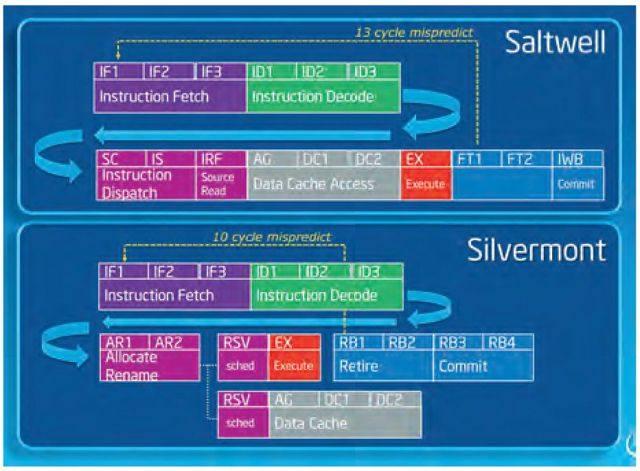
与此前的“Saltwell”微架构相比,Silvermont微架构的执行效率更高。前者流水线误预测为13个时钟周期,后者则仅为10个时钟周期。不过,英特尔尚未给出Silvermont具体的管线长度。参考Saltwell为16级管线,大致可以预测Silvermont的管线在14~17级之间。与乱序架构对应,Silvermont对分支预测器做出了改进,增加了一个间接分支预测器,这使得指令预测更加准确。两方面的改进使得Silvermont比Bonnel/Saltwell的每时钟周期指令效率提升了5%~10%。综合节能和性能考虑,英特尔在Silvermont微架构中仍然采用了双发射指令的结构(Cortex A15是3发射,目前的酷睿微架构为4发射)。
多内核和新指令
Silvermont微架构最多支持8个内核协同运算。由于目前新一代智能手机和平板电脑皆已采用四核处理器,因此更新的Silvermont支持到8个内核并不稀奇。考虑到Atom处理器的单个内核运算能力基本领先于同一时代的ARM处理器,所以可以预见,在今年年底发布的Silvermont系列处理器将再度夺得性能锦标。
Silvermont微架构还能够支持64位运算。去年年底英特尔已经推出了基于Atom平台的64位服务器芯片S1200,功耗仅为6W。Silvermont微架构对64位运算的支持也符合时代的潮流。除了服务器的需求外,随着移动设备运算量的增大,64位运算的普及也势在必行。Silvermont微架构的竞争对手之一ARM Cortex A15仅支持32位运算,在这方面英特尔仍有一定优势。Silvermont微架构还支持SSE 4.1/4.2、POPCNT及AES-NI指令集,弥补了上代产品的缺憾。
新的能效特性
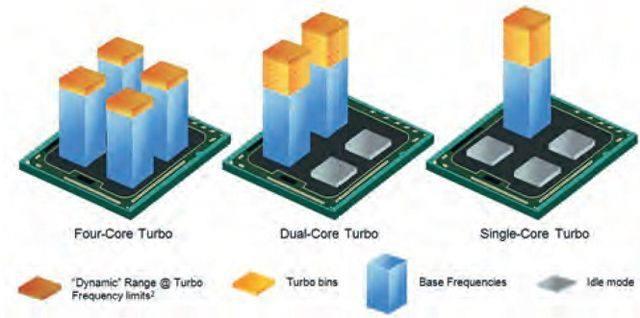
Atom处理器在节能方面表现不佳是此前它屡战屡败的原因之一,不过Silvermont处理器可望摘掉耗能大户的帽子。在Silvermont出现之前,Atom处理器已经支持英特尔的Turbo Boost技术,但它们的表现并不尽如人意。Silvermont微架构加入了硬件功耗控制单元,它可以监控处理器的发热并动态处理SoC芯片内各模块的功耗分配,在处理器温度允许的范围内,运行频率可以得到最大幅度的提升,TDP上限也可被短时超过。Silvermont也允许对单一CPU或GPU内核加速,从而提升效能。在处理器节能状态方面,Silvermont对C6状态模式进行了改进。新增加的“CacheRetention”(缓存留置)可使得二级缓存状态介于部分活跃和完全关闭之间,进一步提高了处理器的节能效果。
制造工艺红利助推Atom
Tick-Tock策略曾经有效地帮助英特尔摆脱了Pentium 4带来的困境,如今英特尔也把这套策略搬来对抗ARM。众所周知,英特尔拥有目前最为先进的半导体加工工艺,这使得它在新一代超节能处理器的竞争中占据优势。Silvermont微架构处理器将会采用英特尔已经成熟的22nm、3D晶体管工艺制造,而目前主流的ARM处理器还都在使用28/32nm工艺。
在每晶体管耗能和漏电率方面,英特尔的22nm工艺占据着明显的优势。在工作电压为1.0V时,22nm工艺处理器比32nm工艺处理器快18%,而在0.7V工作电压时快37%,可见仅仅工艺提升就能够给同功耗的处理器性能带来将近20%~30%的提高。而用于Atom处理器的22nm工艺很可能还将获得进一步改进。借助这些进步,Silvermont微架构处理器单内核运行频率很可能达到2.5GHz级别,节电性也将进一步提高。就目前的情况来看,英特尔还将借助工艺优势推行Tick-Tock战略。目前已经可以确认,英特尔在下一代Atom处理器Airmont中将会采用14nm工艺生产,上市时间约为2014年下半年。
Atom处理器家族四面开花
基于Silvermont微架构衍生的新一代Atom处理器家族,目前已知的处理器有4种,四核的“Bay Trail-T”处理器芯片计划用于平板电脑,相关产品将在2013年圣诞节购物季推出。据称Bay Trail处理器的计算性能是英特尔目前平板电脑产品的两倍以上。此外,Bay Trail-M/D平台还将用于入门级笔记本电脑和低端一体式台式机市场,如近来流行的混合模式笔记本电脑等。根据英特尔方面的资料,与现在的处理器Atom Z2760相比,Bay Trail单线程性能有2~4.7倍的提升,多线程性能有2.5~4.4倍的提升,进步相当显著。频率较低,同时大幅降低能耗的“Merrifield”将用于智能手机平台,据英特尔表示,它的性能和电池续航时间均优于当前产品,还支持情境感知和个性化服务、面向Web流的超高速连接以及更高的数据、设备和隐私保护等功能。此外,“Avoton”将接替S1200处理器,进入数据中心内的微型服务器、存储和扩展性负载。它的特性包括64位指令集、集成结构、错误代码校正、英特尔虚拟化技术以及超强的软件兼容性等。“Rangeley”则主要针对网络和通信基础设施,比如入门级到中端路由器、交换机和安全设备。这两款产品均计划于今年下半年上市。
SoC芯片进军服务器
早在数年之前,英特尔万亿次计算项目取得的成果就已经显示,多个小内核并行组成的处理器有能力进行高强度的运算,如同一大群蚂蚁和大象都有能力搬走一座米山那样。不过,在面对一些轻量的需求,如网络服务请求时,低能耗处理器可能更具备成本的优势。如果将至强处理器比作大象的话,那么目前的超节能处理器就是蚂蚁。尽管大象力气大,但每次需要运载的重量可能都远不及大象的承载力,很多能量被白白消耗;而蚂蚁尽管每次只能扛起一粒米,但蚁群可以根据米粒数量决定派出蚂蚁的数目,尽可能多地节约能源。有鉴于此,英特尔和ARM都把微服务器(面向大量的轻量需求)领域作为自家超节能处理器的重要发展方向。
2012年年底,英特尔推出了面向微服务器的64位Atom处理器S1200,它的TDP仅为6W。惠普公司2013年4月份发布的服务器Moonshot就采用了这款处理器,该服务器的目标市场为云计算和软件定义服务器领域。惠普表示,Moonshot服务器能耗降低了89%,体积减少了94%,而且成本也仅为原来的37%。Moonshot可以满足呈指数增长态势的云计算需求。只要有10家大型网络服务供应商将它们传统的服务器换代为Moonshot服务器,它们每年就能节省总价值1.2亿美元的能源使用支出,并减少近100万吨的二氧化碳排放量,相当于减少了18万辆汽车的尾气排放量。而英特尔声称,还有约20家合作伙伴准备采用Atom处理器。
x86尚需努力
尽管业界对英特尔在SoC超节能处理器领域取得的进展给予肯定,但大部分评论者对Atom处理器的前景依然表示谨慎。毕竟此前的差距并非一代Silvermont就可以弥补,想要在这一领域呼风唤雨,英特尔还需要更加努力。而x86集团的另一位重要成员AMD目前尚未拿出令人信服的产品,或许注重图形表现的SoC处理器才是它的关注所在。
Baytrail:首次磨刀
Baytrail对英特尔来说,可谓十年磨一剑,除了在制程上首次令Atom赶上主流PC的22nm外,又是和酷睿微架构等价的Silvermont低功耗微架构的首款商业化产品。该产品融入了Turbo Boost技术,实现原理与下图所示的Sandy Bridge架构如出一辙,但是它具备更强的单个核心供电控制技术,在“低”下去的时候节能表现将大大提升。
随着发展重点从保持30年优势的PC领域转向移动计算领域,英特尔将越来越多的技术引入移动平台。如果将Silvermont的发展轨迹与酷睿微架构的产品放在一起对比,那么明显可以看到其更新速度更快。在引入日益成熟的22nm工艺之后,移动平台产品将有望率先引入14nm工艺,光凭制程上的两代优势,Atom性能及低功耗表现就将大幅领先。
管线周期
Silvermont架构和前代的Saltwell架构相比,新增的乱序执行能力对管线深度提出了较高要求。为了避免Pentium 4 Willamette架构的超长流水线在分支错误返回浪费过多时钟周期,英特尔刻意缩减了Silvermont的管线,这也在很大程度上控制了核心发热量。
顺序执行和乱序执行
在最为理想的状态下,一条指令的执行按照如下的步骤进行:首先进行指令获取,如果该指令的运算对象已经在寄存器中,则指令会被发射到合适的功能单元执行,并将结果写回到寄存器中。但是,如果在当前的时钟周期下运算对象不在寄存器中(比如在内存中),那么处理单元会消耗一定的时间来等待它。对于顺序执行处理器而言,只有等待到运算对象之后,指令才能够被继续执行下去。乱序执行则将这段等待的时间利用起来:指令首先被存入指令缓冲区。如果运算对象并不在寄存器中,那么后面其他可执行的指令将会被先执行,结果写入另一个缓冲区。等到前面的指令执行后,再按照原先的顺序将指令写入到寄存器中。
很显然,对于复杂和大量的指令,乱序执行的效率更高,但也需要处理器有更强的运算能力,这通常意味着会消耗更多的能源。因此,究竟采用顺序执行管线还是乱序执行管线,归根结底要取决于设计者对运算能力和能耗的平衡。早期ARM和Atom处理器出于对能耗的严苛要求,均设计为顺序执行,但随着人们对移动平台运算能力要求大幅度提高以及半导体工艺不断改进,乱序执行处理器逐渐成为宠儿。
声音
“通过我们的设计与制程技术的共同优化,Silvermont已经超出了我们预期的目标。借助我们在微架构开发领域的专长以及领先的制程技术,我们提供的技术包能够显著地提升性能和能效,同时具备更高的频率。我们为此成就深感自豪,并坚信Silvermont将为各种全新的低功耗英特尔系统芯片奠定强大而灵活的基石。”
——Belli Kuttanna 英特尔院士兼首席架构师
猜你喜欢
科普童话·神秘大侦探(2023年1期)2023-05-30 12:48:10
现代装饰(2022年4期)2022-08-31 01:41:24
今日农业(2021年9期)2021-07-28 07:08:36
汽车零部件(2019年10期)2019-11-13 06:55:26
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
信息安全研究(2018年12期)2018-12-29 11:01:56
测控技术(2018年5期)2018-12-09 09:04:26
电子测试(2018年18期)2018-11-14 02:30:34
单片机与嵌入式系统应用(2018年11期)2018-04-15 16:38:55
电子世界(2015年22期)2015-12-29 02:49:41
