
基于短波测量数据的信道模型聚类方法
2013-04-23 02:56:06吴永宏任源博管英祥蒋宏奎
电波科学学报 2013年3期
金 珠 吴永宏 任源博 管英祥 蒋宏奎
(中国电波传播研究所,山东 青岛 266107)
引 言
对于依靠电离层反射的短波信道而言,电离层的分层结构、电离层多模式传播和多跳传播、电离层不均匀性和不规则运动,以及电离层的吸收、反射损耗共同决定了短波信道的传播特性,使得短波信道的多径延时、衰落、多普勒频移和多普勒展宽在产生机理和表现方式上区别于蜂窝信道[1-2].信道测量是研究短波信道传播特性的有效途径,通过对信道测量数据分析,可以得出某次传播数据的信道参数,但是这些参数表现为随机、离散特性,无法用来描述某个链路的信道特性.论文提出了使用减法聚类算法[3],按照一定刻度将某链路实测数据提取出的信道参数分别进行一维和多维聚合分类,从而得到表征此链路特性的典型信道参数和信道模型.
1 信道测量数据分析
1.1 数据说明
论文使用的信道测量数据是2012年1月12日至2012年1月17日由青岛发射,北京接收的数据,发射数据是由一串PN信号组成,每次突发波形的时长为30 s,产生数据样本为1 482个,其中有效数据(接收信噪比>-3 dB)1 135个.
1.2 数据分析原理
数据分析的原理是基于PN序列特性,使用相关法求得信道冲击响应函数,再由信道冲激响应求得信道散射函数,从而得到一系列信道参数[4-5].设发送原始信号为
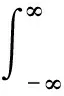
(1)
式中:c(τ,t)表示信道冲激响应;n(t)表示噪声.当输入信号x(t)是由时间长度为T的PN序列组成的信号时,经过单位冲激响应为c(τ,t)的信道后,将接收到的信号y(t)以时间长度T分段,取第l段信号yl(t)与输入信号x(t)做相关运算
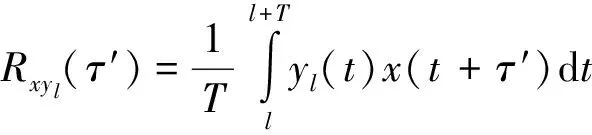
(2)
由公式(2),可以得到冲激响应函数在τ=τ′,t=tl时的值,当变化τ′和tl时,就可以得到冲激响应函数C(τ,t).信道C(τ,t)的时变特性可以看作以t为变量的平稳随机过程,C(τ,t)的自相关函数[6]
RC(τ1,τ2,Δt)=E[C(τ1,t)C*(τ2,t+Δt)],
(3)
在多径信道中,衰落与延时认为不相关,可得
RC(τ1,τ2,Δt)=RC(τ1,Δt)δ(τ1-τ2),
(4)
式(4)可表示为RC(τ,Δt)=E[C(τ,t)C*(τ,t+Δt)],
(5)
以Δt为变量通过对式(5)做傅里叶变换可得
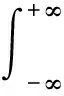
(6)
s(τ,υ)为散射函数.
1.3 信道参数计算
文中希望通过对信道测量数据的分析,得到由电离层反射信道引起的、对短波通信影响很大的时频色散参数,并使用这些参数归纳短波信道模型.
1) 最大附加延时
描述时间色散的参数有平均附加延时、延时展宽和最大附加延时,这些参数都可以由延时功率谱得到[7],延时功率谱(如图1所示)可以通过1.2节的散射函数得到
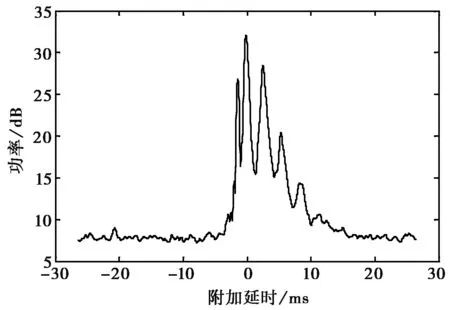
图1 延时功率谱
(7)
由于信道参数统计聚类出的信道模型应贴近短波调制解调器的设计,因此选择计算最大附加延时.延时功率谱是基于固定延时参考量τ0的附加延时τ的函数,τ0是第一个到达的可检测信号.计算最大附加延时dτ时,选取延时功率谱多径分量的最大值max(P(τ))为参照,设置一个噪声门限值max(P(τ))-X为噪底,以区分接收的多径分量和加性噪声,其中X的取值范围为6~10 dB.那么最大附加延时
dτ= max(τ|(P(τ)-max(P(τ)))>-X) -min(τ|(P(τ)-max(P(τ)))>-X),
(8)
2) 多普勒展宽
信道的频域色散特性可用多普勒展宽参数来描述,由散射函数可得到多普勒功率谱
(9)
数据多普勒功率谱如图2所示,多普勒展宽即多普勒功率谱二阶中心矩的平方根[7]. 那么多普勒展宽为
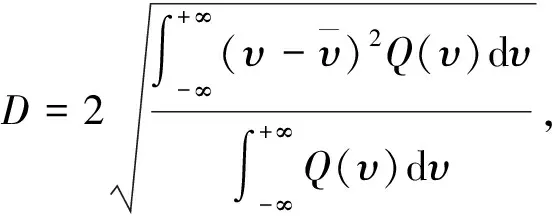
(10)
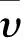
图2 多普勒功率谱
2 信道模型聚类
2.1 聚类算法原理
聚类是将一个数据集划分为若干组,使组内相似性大于组间相似性,实现这样一种划分需要一个相似度度量,即取两个输入向量,返回反映这两个向量间相似性的数值.由于大多数相似度度量对输入向量中心元素值域非常敏感,因此每个输入度量都必须归一化,即其绝对值在单位区间[0,1]内.
减法聚类的原理[5]是将每个数据点作为可能的聚类中心,并根据各个数据点周围的数据点密度来计算该点作为聚类中心的可能性.在迭代出第一个聚类中心后,从剩余的可能作为聚类中心的数据点中,继续采用类似的方法选择下一个聚类中心,这一过程一直持续到所有剩余数据点作为聚类中心的可能性低于某一阈值时,从而决定输入和输出变量的隶属度函数个数.
设{x1,x2,…,xi,…,xn}是s维空间的n个数据点,不失一般性,假定数据点都已归一化到一个超立方体中,将每个数据点都作为聚类中心的侯选点.计算每个数据点xi的密度指标
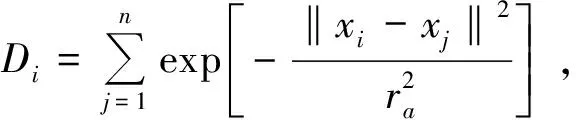
(11)
式中ra是一个正数,定义了该点的邻域直径,如果数据点xi周围有多个邻近的数据点,则xi具有高密度值,半径以外的数据点对该点的密度指标贡献非常小.计算每个数据点的密度指标后,选取具有最高密度指标的数据点xc1作为第一个聚类中心,Dc1为密度指标.设当前选出了第k个聚类中心xck,其密度指标为Dck,则用Dck修正每个数据点的密度指标
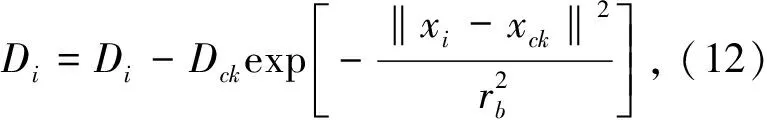
式中rb是一个正数,定义了一个密度指标函数显著减小的邻域,通常rb>ra,以避免出现相距很近的聚类中心,这里取rb=1.5ra.通过修正后,显然靠近聚类中心的数据点的密度指标将显著减小,使得这些点不太可能被选为下一个聚类中心.按下面算法来对第k个聚类中心进行判决:
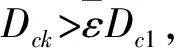
2) 当Dck<εDc1,认为xck不是聚类中心,终止聚类过程.
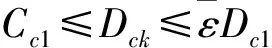
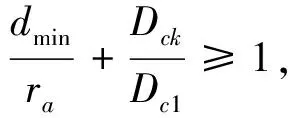
(13)
式中dmin为xck已经确定的聚类中心距离的最小值,当式(13)成立时,认为xck是聚类中心,当式(13)不成立时,认为xck不是聚类中心,并将该数据点的密度指标设为0,选择余下数据点中具有最高密度指标的点为待确认的点,重新进行判决.
2.2 聚类结果
使用2.1节介绍的聚类算法对青岛北京链路的最大附加延时和多普勒展宽参数做一维和二维聚类统计,可得到对应参数的典型值及此链路的典型信道模型.
1) 一维参数聚类结果
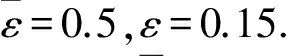
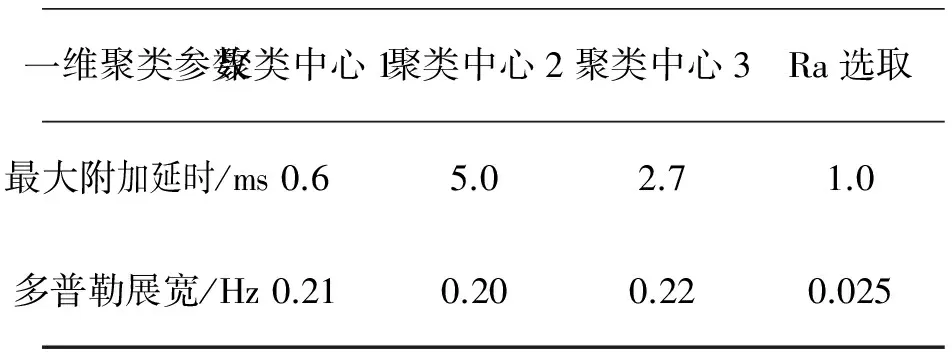
表1 一维参数聚类结果
2) 二维参数聚类结果


表2 二维参数聚类结果

图5 最大附加延时和多普勒展宽二维参数的分布特性
由以上的聚类结果可以看出,文中所用的测量链路和测量时间段内,信道的路径延时差异较大,而小尺度衰落,即多普勒展宽差异较小.
2.3 聚类结果验证
使用聚类算法的目标是聚类出的典型信道参数及信道模型出现概率大并且参数集中度高,因此可以通过计算聚类中心半径范围内参数所占比例来验证聚类结果的合理性.
从图3(见 571 页)可以看出,最大附加延时落在聚类中心1半径范围内的值占所有参数比例接近40%,落在聚类中心2和3的值分别占比例为20%和18%,依次划分的典型信道参数类型包含了78%的信道参数值.并且,使用聚类算法找出的信道参数典型值具有发生概率大和代表不同信道特性的特点.同样,从图4(见 571 页)可看出多普勒展宽值的聚类结果满足要求.从图5可以看出,二维参数落在聚类中心1、2和3的半径范围内的概率分别为40%、18%和12%,依次划分的信道模型包含了70%的二维信道参数种类.聚类中心均落在参数发生概率大、集中度高的位置,并且三个聚类中心可以代表三种不同的信道模型.
2.4 分时段聚类结果及信道质量评价
短波信道特性随季节、时段、太阳黑子等变化而变化,因此通过将具有同样季节、时段、太阳黑子参数的数据用来做聚类分析更具有科学性.由于论文使用测量数据存在局限性(仅限于前后6天的测量数据,且样本数量较少),根据短波信道特性,可将测量数据分为白天(5∶00—21∶00时)和晚上(22∶00—23∶00时,及1∶00—4∶00时)两个时段,按照上述聚类方法聚类,可分别得到白天时段和晚上时段的最大附加延时和多普勒展宽二维参数的聚类结果,如表3、表4所示,其中聚类中心1对应的信道模型发生概率大于聚类中心2,聚类中心2对应的信道模型发生概率大于聚类中心3.由聚类结果可看出,白天时段信道的路径延时小于晚上时段,而多普勒展宽无明显差异.

表3 白天时段二维参数聚类结果

表4 晚上时段二维参数聚类结果
以小时为单位,分别计算出白天时段和晚上时段对应测量数据的二维信道参数落在表3和表4中每个聚类中心半径范围内的概率,分别如图6、图7所示,横坐标代表时刻(以小时为单位计),纵坐标代表在对应时刻内,信道参数落在每种聚类中心半径范围内的概率,当数据样本足够多时,可以认为在对应时刻内,每个聚类中心对应的信道模型发生概率.从图6可以看出,在白天时段,8时至15时的时段内,聚类中心1和聚类中心2的发生概率较大,信道情况较好,而与此时段相聚越远的时段,聚类中心3的概率越大,信道情况越差.从图7可以看出,聚类中心1对应的最差信道在凌晨1时发生的概率最大,而与1时相距越远的时刻,聚类中心1的发生概率越小,聚类中心2的发生概率越大,信道特性越好.因此根据聚类中心对应的信道模型在不同时刻的分布情况,可以定量描述信道特性.
综上所述,使用聚类法分析信道模型,既可以得到不同信道模型的典型参数(聚类中心),又可以将信道特性按照一定刻度分类,来定量描述和评价信道质量.
3 结 论
依据青岛-北京链路短波信道测量数据,从数据样本中计算出影响短波通信的重要信道参数,使用减法聚类算法,将随机离散的信道参数进行归纳统计,得到此链路的典型信道参数和信道模型.通过分析一维和多维信道参数在聚类中心半径范围内的分布特性验证了聚类算法的合理性.从而解决了离散随机信道的定量描述问题,为短波频谱管理[8]提供了随机信道质量评定依据.
[1] THEODORE S. Rappaport Ts Wireless Communications Principles and Practices [M]. 4th ed. New Jersey: Prentice Hall, 2002.
[2] 姚永刚, 赵正予, 谢树果, 等. 电离层后向散射探测中m序列和FH序列的应用. 电波科学学报, 2001, 16(4): 522-528.
YAO Yonggang, ZHAO Zhengyu, XIE Shuguo, et al. The applications of m sequence and FH sequence to ionospheric backscattering sounding. Chinese Journal of Radio Science, 2001, 16(4): 522-528. (in Chinese)
[3] BEZDEK J C. A convergence theorem for the fuzzy ISODATA chustering algorithms [J]. Transaction on Pattern Analysis and Machine Intelligence, 1982, 2(1):1-8.
[4] CHEN C C, HUANG C C. Fast feedforward channel sounding RAKE receiver[J]. Electronics Lerrers, 2000, 36(20):1731-1733.
[5] WATTERSON C C, JUROSHEK J R, BENSEMA W D. Experimental confirmation of an HF channel model[J]. Transaction on Communication Technology, 1970, 18(6):792-803.
[6] 涂旭东. 宽带短波信道特性和建模研究[D]. 四川成都: 电子科技大学, 2004.
TU Xudong. Wideband HF Channel Characteristics and Modeling Study[D].Chengdu Sichuan: University of Electronic Science & Technology of China, 2004.(in Chinese)
[7] BALABAN J R, SHANMUGAN S K. Simulation of Communication Systems: Modeling: Methodology and Techques[M]. 2nd ed. New Yonk:kluwer Academic Publishers, 2000.
[8] CAPAR F, JONDRAL F. Resource allocation in a spectrum pooling system for packet radio networks using OFDM/TDMA[C]∥ IST Mobile and Wireless Telecommunications Summit, Thessaloniki,2002.
猜你喜欢
自动化仪表(2020年10期)2020-11-13 03:31:00
中国生殖健康(2019年8期)2019-01-07 01:18:20
人民音乐(2016年1期)2016-11-07 10:02:42
时代风采(2016年12期)2016-07-21 15:07:45
时代风采(2016年10期)2016-07-21 15:07:34
林业与生态(2016年3期)2016-02-27 14:24:23
船舶力学(2015年6期)2015-12-12 08:52:20
发明与创新(2015年33期)2015-02-27 10:40:10
西南军医(2015年5期)2015-01-23 01:25:07
汽车维护与修理(2014年10期)2014-02-28 12:15:01
