
“方言同音字汇”自动生成软件①的设计及实现
2013-04-23 12:26程南昌
中文信息学报 2013年1期
程南昌, 侯 敏
(1. 中国传媒大学 文学院, 北京 100024; 2. 百色学院 中文系,广西 百色 533000; 3. 中国传媒大学 有声媒体语言分中心, 北京 100024)
① 软件下载地址: http://ling.cuc.edu.cn/chs/News_View.asp?NewsID=192(中国传媒大学有声媒体语言资源网);http://www.newhua.com/soft/115881.htm(华军);http://www.crsky.com/soft/27371.html(非凡)。
② 引自著名语言学家张振兴给笔者的邮件,此处引用已经过张老师同意。
1 引言
中国是方言大国,每种方言都有自己的语音系统,整理每种方言的语音系统是方言调查的基本任务。“方言同音字汇,简单说就是把同音的字列放在一起。先把同韵母的字放在一起,再把同声母的字放在一起,然后把同声调的字放在一起。如果韵母、声母、声调都相同的字,只听读音,无法分辨到底是哪个字。”②在进行方言田野记音调查之后,第一步要做的,也是最重要的,就是整理出“同音字汇”。在同音字汇整理出来后,才能初步了解整个方言的语音系统,这是最基础的工作。有了同音字汇,方言调查者才有可能进一步记录语音材料(例如,变调、儿化、轻声、音变等),整理方言的词汇和语法,方言研究者才有可能进行方言语音系统以及古今语音演变的研究。另外,行内的人也可以通过同音字汇来判断调查者的记音是否正确,他人通过同音字汇也可以进行该方言的研究。因此,研究方言的人非常看重“同音字汇”。但是“方言同音字汇”的制作相当困难,传统是采用做卡片的方式,做好一个同音字汇需要很长时间,稍不小心,就会出错,是一项很艰苦的“体力活”。可以说,“方言同音字汇”的制作,已成为制约加速方言调查工作的“瓶颈”。因此,利用计算语言学的知识,开发“方言同音字汇”自动生成软件,就成为我们的一项重要任务。
2 相关研究综述
随着计算机的出现,人们开始利用计算机辅助方言方面的调查与研究,以减轻方言调查者的工作量。在“同音字汇”自动处理方面,相关研究工作主要有以下三个方面。
上海师范大学潘悟云(2006)利用Visual Foxpro开发了一个“汉语方言计算机处理系统”,在该系统的第四个功能“方言音系分析”中,可调入按一定格式建立的Visual Foxpro数据库字表,生成同音字表。但是用户在使用中必须严格采用该系统所规定的VFP数据库格式,否则即会出现运行错误,并且要求数据库中一定要有汉字、中古声母、中古韵母、中古声调等14个字段。[1]此外,该软件最终生成的同音字表虽然按韵、声、调的顺序对同音字进行了排序,但每一组同音字都有声、韵、调三个属性,要整理成文本形式的同音字汇“竖排表”,还需要一定的时间。
广西民族大学海柳文[2]利用Visual Foxpro开发的“汉语方言民族语言语音材料处理软件”。在进行“同音字汇排序”时,该系统只能按英文字母的音序进行排序,因此影响了同音字汇生成的精度。
广西师范大学刘村汉[3]基于Excel开发的“方言字音处理系统”,在生成同音字汇时,要进行复杂的公式运算,操作一不小心,就有可能出错。对计算机不熟悉的方言调查者学习和操作起来有较大的难度。
以上软件在同音字汇自动生成方面做出了有效的尝试,并且取得了一定的效果,但是由于在使用与操作上不够方便,因此,有必要进一步开发一种更加方便快捷的同音字汇自动生成软件。
3 软件的设计与实现
3.1 相关知识
在方言田野调查中,往往要依据一个基本的《方言调查字表》作为参照,丁声树、李荣[4]的《汉语方言调查简表》就是一个有代表性的字表,收字2 500多个。现行的《方言调查字表》为了照顾古音的音韵地位收了不少生僻字。我们在制作软件的过程中,采用的测试字表共收字3 810个。李如龙[5]认为在现行的《方言调查字表》中,有些字在许多方言中问不出音,勉强问出来也往往不可靠。对一般性调查来说,这就徒然增加了许多负担。然而对任何一种真实的方言,该字表又是不够用的,总有些方言特有的音节调查不到,单是根据这个字表记音,整理出来的同音字表会有遗漏。所以,学者们通常都以《方言调查字表》为基础,略去他们正在调查的方言里不用的字,根据该方言的实际情况补充《方言调查字表》里没有的字,最后得到一个该方言的用字总表。汉语的字由字形、字音、字义三部分构成。假如不考虑字义,把同形同音的字算一个字,把同形而不同音的字(例如,普通话中的种: zhong214、zhong51、chong35)算不同的字,对用字总表中每个字的读音进行比较,找出读音相同的字,最后就可以得到一个同音字汇表。理想的同音字汇表中收录的字都是该方言里用到的字,而没有收录的都是该方言里不用的字。
因此,方言同音字汇自动生成软件,要面对的是开放的方言调查字表,要求软件可以自动判断字表的字数进行统计分析。所需要的数据包括“索引、字目、声、韵、调”。如果把零声母也算作一类,每个字都应该有“声、韵、调”三个属性。制作同音字汇主要是对“同音字”按一定的规律进行排序,但是并不排除一个音只有一个“字”的情况,这样的字也要被列入同音字汇中,可以把它看成是同音字的特例,它只与它本身相同。张振兴[6]中的“快(kuai31)、怪(guai24)”就属于这种情况。
3.2 开发工具
前面提到的三个同音字汇软件,都是利用Visual Foxpro数据库或Excel进行排序, 而Visual Foxpro数据库或者Excel的排序主要是针对英文字母,由于国际音标的集合远远大于英文字母,且排列与英文字母不同,所以排序的时候会有很多困难。基于此,我们在制作同音字汇自动生成软件的时候,数据库只用于存储,从数据中读取所需要的数据信息后,所有运算都用程序进行,所采用的程序开发语言为C#2008和Delphi XE,数据库为Access(2003/2007)、Excel(2003/2007)。采用C#2008和Delphi XE的一个重要原因是它们都支持Unicode编码,因为常用的国际音标基本上是大字符集,大都是Unicode编码的,例如“云龙国际音标”[7]。采用Access与Excel作为数据库的原因有三个: 一是支持Unicode编码;二是Access与Excel作为 Microsoft Office 的系统程式,在windows系统上的安装非常容易,为大多数用户所熟悉;三是它们使用简单方便,可移植性非常强,小巧灵活,用来存储方言字表绰绰有余。
3.3 软件设计
3.3.1 软件运行的流程
从数据库中读入“ID(索引)、字目、声、韵、调”五个字段的信息→软件自动分析出该方言的“声、韵、调”系统→用户对软件自动分析出的“声、韵、调”排序→根据用户要求的“声、韵、调”顺序对字表进行排序,如省略该人机互动过程,软件将按默认的顺序排序→过滤掉相同的声、韵、调→生成同音字汇竖排表。
3.3.2 数据的读入
软件所需要的数据有两个,一个是方言调查者在记音调查后得到的字表,这个字表用国际音标记录了每一个字目的“声”“韵”“调”三个属性。本软件提供了三种方法读入这些数据。
第一,当用户没有建立自己的Access或者Excel数据库来存储字表时,用户可以从word、txt等文档中复制字表到本软件提供的数据库中。
第二,如果用户的字表存储在自己建立的Access数据库中,软件则可以与之挂接,并自动加载该数据库的表和字段,用户可以很方便地通过下拉框选择字表和字表中的各个字段。
第三,如果用户的字表存储在Excel表中,软件也可以与之挂接,自动加载字表和各个字段。
当软件读入方言调查字表后,便能自动分析出该方言的声、韵、调系统。本软件所需要的第二个数据就是方言调查者在软件得出的声、韵、调系统的基础上提供的顺序表。通常,声母是按发音部位排,韵母按开口度排,声调是按平、上、去、入排,因每个方言点的语音系统都不相同,一般来说,应由用户即方言研究者自己设定。字目的“声、韵、调”三个属性,如果按不同的方式进行组合,可以有六种排序方式。如果用户没有对声、韵、调进行排序,软件将按默认的“韵、声、调”顺序排列,韵母相同的,按声母排,韵母和声母都相同的,再按声调排。
3.3.3 排序算法
为了便于说明,现在假设有一个方言字表,它有24个字目,具体见表1。

表1 方言字表* 语料从广州话方言调查字表中提取出,广州话方言调查字表由广西师范大学陈小燕教授提供。凡有国际音标处,为防止乱码,都以图片的形式显示。
假定调查该方言的学者给出的韵、声、调排列顺序如表2所示。

表2 韵、声、调顺序
整个排序过程将采用韵、声、调再加上字表所有字目的四重循环。循环流程图如图1所示。
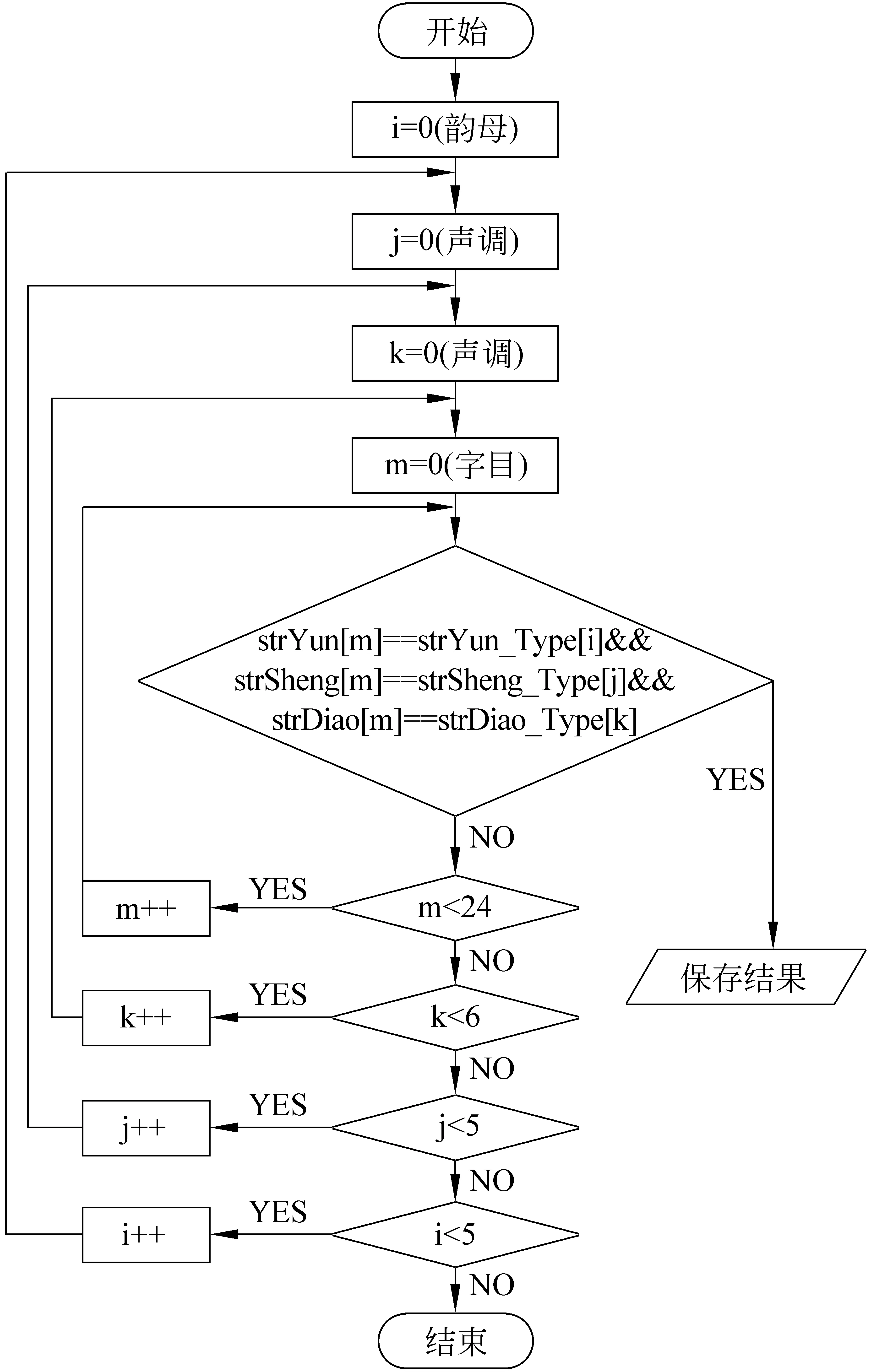
图1 排序过程流程图
图1中“strYun[m] == strYun_Type[i] && strSheng[m] == strSheng_Type[j] && strDiao[m] == strDiao_Type[k]”一句表示,当字表中的某个字目的声(strSheng)、韵(strYun)、调(strDiao)在循环中符合条件的时候。
到这里,按韵、声、调的顺序排序的过程就完成了, 循环总次数为: 韵的个数×声的个数×调的个数×字目的个数,在这里就是5×5×6×24=3 600次。排序结果见表3。

表3 按韵、声、调排序后的字表
在表3中,所有的字目都按韵、声、调的顺序进行了排列,其中ID为24的“惹”字没有与之同音的,软件把它当作同音字的一种特殊情况,也自动进行了排序。
这样生成的同音字汇是一个表格的形式,每个字都有声、韵、调三个属性,不利于观察和使用。因此最后一步,就是要把相同的“声、韵、调”属性过滤掉。所有属于同一个韵母的字,韵母只表示一次;所有属于同一个声母的字,声母只表示一次;所有属于同一个声调的字,声调只表示一次。最后生成的同音字汇形式是一个文本,叫同音字汇竖排表。这一步算法设计相对前面的排序要简单一些,因此不再赘述其实现原理。前面表1中提供的24个字目的字表最终生成的同音字汇竖排表见表4。

表4 同音字汇竖排表
到此,同音字汇的生成全部完成。
3.4 软件实用性分析
作为一个实用软件,应最大限度满足用户需求。本软件在技术上的特点主要表现在以下三个方面。
1. 体积小,可移植性强。软件编译完成后,包括数据库在内,总大小只有3.19MB。
2. 运行速度快。我们在普通家用电脑上用桂林官话、北京话、广州话三种方言进行了测试,电脑的操作系统为win7,内存2GB。表5是测试结果。

表5 三种方言测试结果
以上数据说明,字表大,排序需要的时间并不一定就长,排序时间主要取决于方言的声、韵、调系统是否复杂。三种方言中,耗时最多的是声、韵、调系统最复杂的广州话,但是也仅仅只用了四分之一秒。
3. 无需安装,使用方便快捷。本软件由于采用的是比较通用的Access与Excel数据库,而且程序界面友好,学习与使用都比较容易。
4 软件的应用
同音字汇自动生成软件于2008年开发完成。广西师范大学方言专家陈小燕教授使用本软件对“广州话”“桂北五通平话”“钟山董家垌土话”“玉林白话”“粤西封开粤语”“桂林官话”“全州湘语”“陆川客家话”“桂林大河平话”“仁义话”“桂岭话”等十几种不同方言进行了测试,准确生成了这些方言的同音字汇,取得了令人满意的效果。为了惠及更多的方言研究者,我们在国家语言资源监测与研究中心有声媒体语言分中心网站上发布了“方言同音字汇自动生成软件”,供用户免费下载。随着软件影响的扩大,华军和非凡软件园也收录并发布了本软件。仅就华军网用户IP信息显示,本软件的用户除了国内(含港、澳、台),还包括了美国、马来西亚、韩国、挪威、泰国等国家。
5 结语
“计算语言学(computational linguistics)是用计算机研究和处理自然语言的一门新兴的边缘学科。”[8]同音字汇自动生成软件利用计算机来处理方言,用来生成同音字汇竖排表,可以大大减少方言研究者的劳动量。目前计算语言学在处理人类的自然语言方面取得了突出的成就,在国内,计算语言学在处理汉语共同语(普通话)方面取得了长足的进步,但是在处理方言和少数民族语言方面,相对还比较薄弱,因此,这方面的研究亟需进一步加强。
致谢:
百色学院院长卞成林(博士)教授安排笔者参与了由广西师范大学方言专家陈小燕(博士)教授主持的“高山汉”方言的田野调查活动,从而了解了方言同音字汇的基本原理。同音字汇自动生成软件的测试语料由陈小燕教授提供。在软件开发过程中,使用了语言学家潘悟云教授的“汉语方言计算机处理系统”与“云龙国际音标”。广西师范大学在读硕士研究生刘艳平及上海师范大学在读博士研究生吕嵩崧对软件进行了测试与反馈。在本文写作过程中,得到了著名语言学家张振兴教授的指导。在此对各位专家、同学表示衷心的感谢!
[1] 潘悟云.汉语方言计算机处理系统[DB/OL].[2011-06-11].http://www.eastling.org/resource.htm.
[2] 海柳文.汉语方言民族语言语音材料处理软件设计[J].广西民族大学学报,2005,11(3):60-64.
[3] 刘村汉.方言字音Excel处理系统[CP/OL].2005-05-05[2011-06-11].http://pgsu.jnu.edu.cn/show.aspx?id=636&cid=12.
[4] 丁声树,李荣. 汉语方言调查简表[M].北京: 中国科学院语言研究所,1956.
[5] 李如龙.汉语方言学(第二版)[M].北京: 高等教育出版社,2007.
[6] 张振兴. 漳平(永福)方言同音字汇[J].方言,1982(3):203-228.
[7] 李龙,潘悟云.国际音标输入法及其实现[J].语言研究,2006,26(3):67-70.
[8] 冯志伟.计算语言学基础[M].北京:商务印书馆,2001.
猜你喜欢
东方少年(2022年28期)2022-11-23
西藏科技(2022年3期)2022-04-22
今日农业(2021年15期)2021-11-26
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
新世纪智能(高一语文)(2019年11期)2020-01-13
新世纪智能(高一语文)(2019年11期)2020-01-13
小天使·一年级语数英综合(2019年6期)2019-06-27
小天使·一年级语数英综合(2019年2期)2019-01-10
读书文摘·经典(2018年10期)2018-10-12
