
事件超图模型及类型识别
2013-04-23 12:25何炎祥
中文信息学报 2013年1期
肖 升,何炎祥
(1. 武汉大学 计算机学院,湖北 武汉 430072; 2. 湖南第一师范学院 信息科学与工程系,湖南 长沙 410205)
1 引言
事件类型识别是指探测到事件后,根据其特征将其归入预定事件类型的过程。此过程是事件抽取的前提和基础,其结果将直接影响后期的事件模板匹配及事件元素提取[1]。
目前,已有的事件类型识别方法多为基于向量空间模型的机器学习方法。与基于规则和模板的识别方法相比,此类方法采取的机器学习策略使其在可移植性方面有了显著提高[2]。但受限于向量空间模型的独立性假设(单向量模型的分量或多向量模型的分向量表征的事件特征相互独立),此类方法在完成文本到表示模型转换时丢失了所有关联信息[3],而这些关联信息(如概念逻辑关联、句法语义约束等)却往往是类型识别的重要依据,例如:
1) 触发词缺失。如在事件“离婚女向前夫讨宠物探视权[4]”中,表征“离婚”的触发词缺失,如果不考虑“离婚女”、“前夫”与离婚事件之间的概念关联就很难将其正确归类。
2) 触发词暗指。如在事件“此次空难夺去了81人的生命[4]”中,“夺去”不能直接表征伤亡事件,必须通过“夺去生命”与伤亡事件之间的因果关联才能确定此处“夺去”暗指伤亡。
3) 触发词误指。如在事件“恐怖袭击是布什必须面对的挑战”中,“袭击”并不表征袭击事件,如果仅认触发词,而不考虑“袭击”和动词“是”之间的句法约束就很可能对其错误归类。
4) 触发词多指。如事件“生意失败使他失去了家产”和“车祸使他失去了生命”中均包含“失去”(即“失去”多指),如不考虑它与“家产”及“生命”之间不同的语义约束就很难将两者分别归入破产事件和伤亡事件。
类似现象举不胜举,为弥补缺陷,用图模型表示事件关联信息的研究随之展开。研究初期主要侧重于间接表示,即以特征文本为中介将文本的向量空间模型转化为图模型,但此举并不成功[5];其后,研究转向直接表示,即不通过转化而直接用图来表示事件(结点代表事件,边代表两事件之间的关系,边上的权重用于量化一个事件对另一个事件所产生影响的大小,即影响因子)[6]。与前期相比,改进后的表示无疑更加明确,但仅描写事件关联而不描写事件元素关联的方案过于粗糙,加之图的边又只能描述结点集上的二元关系,因此事件类型识别中遇到的诸多多元关系仍难以描写,例如:
1) 事件关系。如在事件“林晖被证监会指控违规交易”中,“林晖”、“证监会”、“违规交易”、“指控”4者关联形成的指控事件关系“触发词(受控方,指控方,罪名)”就无法用二元关系描述。
2) 共指关系。如在事件链“汉光公司成立于1988年,1997年他们在收购明波公司后达到事业顶峰,随后逐年亏损,2002年该公司因资不抵债而破产。”中,参与者“汉光公司”、“他们”、“该公司”所形成的共指关系显然无法用二元关系描述。又如在事件链“2001年9月11日恐怖分子对美国发动了袭击,这一事件对美国影响深远,这也直接导致美国发动日后的反恐战争”中,事件“袭击”、“这一事件”、“这”所形成的共指关系也无法用二元关系描述。
3) 事件聚类关系。如任职、离职、调职三类事件可聚合为职务变更事件,这种聚合关系也无法用二元关系描述。
可见,将表示事件的数学模型由图泛化为超图,利用超图对多元关系进行描写势在必行。随着超图相似度计算在信息检索领域的成功应用[7-9],基于超图的事件类型识别方法日渐可行,鉴于未见相关报道,本文尝试做此研究,以期达到抛砖引玉的效果。
本文首先引入超图、事件超图及事件超图模型,然后根据事件超图模型的结构,提出了超边判别加顶点相似度计算的事件类型识别方法,最后用实验求证了该方法的有效性。
2 超图及事件超图
超图这一概念最早由C.Berge于1970年提出,初衷是表示多端子网络所联成的超网络的拓扑结构[10],其理论在计算机科学和人工智能领域得到长足发展,并被广泛应用于电路设计、关系数据库、数据挖掘、行为分析等子领域[11]。
超图有无向和有向之分,由于事件或事件元素形成的多元关系(如事件链中的因果关系,文本中事件元素的语序关系)均有可能表现出有序性,因此本文选择不仅能描写多元关系而且能描写多元有序关系的有向超图来表示事件。
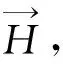
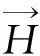
绘图时,用被称为触须(tentacle)的连续曲线连接顶点和超边,形式上,用t(vj,Ei)表示vj到Ei的触须,整个有向超图所有触须组成的触须集记作T[12]。若Ei∩Ej≠∅,则对∀vk∈Ei∩Ej而言,都既存在vk到Ei又存在vk到Ej的触须。



定义5子超图(Subhypergraph) 设H1=
1)V中元素代表事件中的非触发词元素,如参与者(人物、组织)、环境因素(时间、地点)等。
2)E中元素代表触发词。
3)T中元素t(vj,Ei)(vj∈V,Ei∈E)表示事件元素vj和触发词Ei之间存在指向关系。例如,有施事做出动作则有触须从代表施事的顶点指向代表动词的超边。
4)PH=(PV,PE)为一对语言符号集,存在标记函数pv:V→PV、pe:E→PE分别为V、E贴标。
5) 存在权值函数W:T→N(N为自然数集),对∀t∈T有W(t)表示t(vj,Ei)中vj到Ei的相对位置(位置矩阵值)。
由上可知,超图是事件超图的父类,事件超图是超图为表示事件元素间的多元有序关系而产生的子类。下面借助实例进一步解释事件超图的相关概念,举例如下:
①[2006年8月31日]T[詹夏来]H辞去[芜湖市委书记]P1一职,[t1] [e1]调任[安徽省政协副主席]P2,[t2] [e2]兼任[奇瑞公司董事长]P3。
例①的事件超图如图1所示。

图1 事件超图实例
从图1中可以清楚地看出:
1) 借助标记函数,事件超图为代表事件元素的顶点(实心黑圈)和超边(方框)贴上了标签。图中“T”、“H”、“P1”、“辞去”等都是标签。
2) 顶点T、H、P1、P2、P3分别代表职务的时间实体、人名实体和3个职务实体;d+(T)=3,d-(T)=0,d(T)=3(另外4个顶点的情况依此类推)。
3) 有向超边辞去、调任、兼任分别是3个事件的触发词;T(辞去)={T,H},H(辞去)={P1},δ(辞去)=3(另外两条超边的情况依此类推)。
4) 超边的交集点T、H到每条超边都有触须。
5) 在例①中,P1是“辞去”后面的第1个事件元素,因此两者的相对距离为1,加之P1是“辞去”的出点,因此两者的关联矩阵值为-1,所以标记在触须上两者的位置矩阵值为-1(其他触须上的权值依此类推)。
6) 搜索与“辞去”相连的顶点可以找到事件“辞去(T,H,P1)”(其他事件的搜索类似),可见事件这种多元关系在事件超图中得以表达。
7) T,H分别具有3条同向的触须,这说明T、t1、t2所形成的时间共指关系以及H、e1、e2所形成的人物共指关系都能在事件超图中形成清晰表达。
8) 例①中的事件链由事件“辞去(T,H,P1)”、“调任(T,H,P2)”、“兼任(T,H,P3)”三者组成,表示这三者的超图都是图1的真子超图,可见,通过子母事件超图不仅可以表示事件还可以表示事件链。
综上可知,与图相比,超图特别是有向超图更加适合事件表达和建模。
3 基于事件超图模型的类型识别
事件类型识别是一个依靠先验知识的二值判定过程[4],事件超图模型是支撑这个过程的物质基础,它是事件超图为应对事件类型识别而与其他组件结合所形成的表达模型。
3.1 事件超图模型
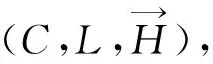
1) 类描述是指用事件超图表示某类事件在不同观测层面中可能表现出来的属性及其结构。
例如,免职事件的非触发词元素在4个层面的属性及其结构可表现为“O+_+H+P”(O代表组织实体,H、P的含义同例①,“_”代替触发词)、“N(/NP) +_+ N(/NP)+ N(/NP)(“/”后的内容是可选项)”、“主语+_+宾语+宾补”、“施事+_+经事+系事”[14],其触发词类别是免职动词。如果用EHM对其进行描述,结果如图2所示。

图2 免职事件在4个层面的事件超图模型
图2中顶点和超边的属性也由标记函数以贴标方式加入。非触发词元素的属性及其结构实际上就是它们在该层面的语言学特征及其序关系。
2) 实例描述是指用事件超图描述某一事件在不同观测层面中表现出来的属性及其结构。例如:
②[中共中央] O已撤除[张文康] H的[党职] P。
用EHM对例②进行描述,结果如图3所示。
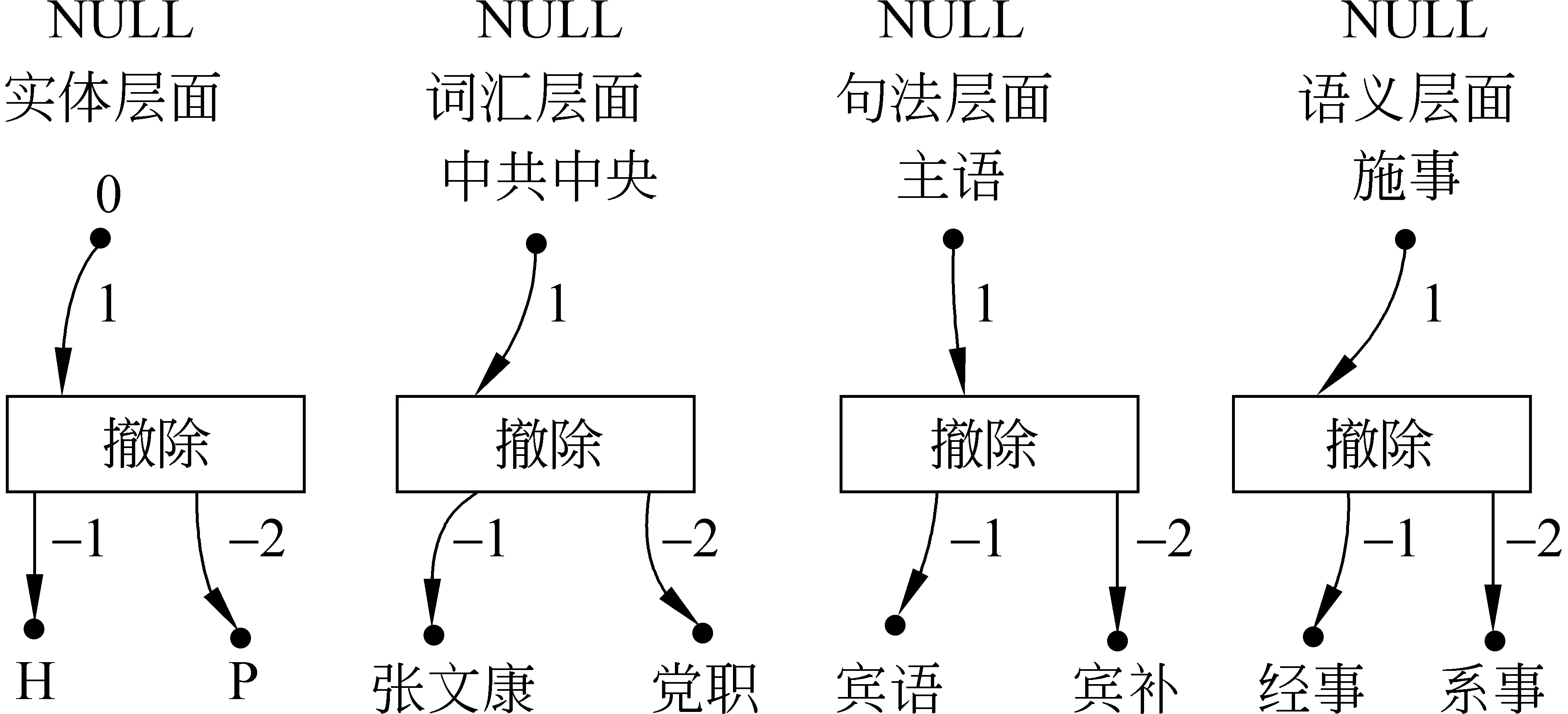
图3 例②在4个层面的事件超图模型
如果将图2、图3分别视为标准模型和比较模型,那么两模型的比较本质上就是依靠先验知识的事件类型识别。显然,标准模型就是先验知识,模型元素的相似度就是识别依据。就图2、图3而言,两者的相似度表现为以下3点。
1) 在未完成事件类型识别之前,具体事件的事件类型无法确定,因此类型组件C的记录为“NULL”。
2) 免职事件的触发词是免职动词,例②的触发词是“撤除”,根据文献[14]的研究成果,“撤除”属于免职动词。
3) 除词汇层面的词形属性(如“中共中央”、“张文康”、“党职”)外,例②的非触发词元素在4个层面的其他属性(命名实体、词性、句法角色、语义角色)及属性结构(实体序列、词性序列、句式、论元结构)都与免职事件一样。探其根源,不难发现,叙述同类事件需要以大致固定的语序来描述基本相同的事件特征,这使得同类事件具有相似的元素及元素序列,当这种相似性映射到4个层面上时,就会使这些层面上的属性及其结构也趋于相似。事实上,这种相似性已在浅层语义分析(又称语义角色标注)中得以应用[15],本文以此为基础构建的顶点相似度计算框架将不会成为空中楼阁。
如果以2)、3)的分析为依据,例②中的事件属于免职事件,这与事实吻合。可见,超边和顶点在4个层面上的属性及其结构可以成为事件相似度计算和类型识别的重要标准。
3.2 事件相似度计算及类型识别
事件相似度计算是事件类型识别的方法基础。基于EHM的事件相似度计算本质上是模拟模型元素的比较过程(3.1节),因此可分为超边判别和顶点相似度计算。
1) 超边判别即判断比较模型中的触发词是否属于标准模型中的触发词类别。本文将采用词表匹配而非同义词相似度计算[16]来完成此过程。之所以如此,一方面因为标识事件类型的触发词有限且固定,另一方面因为同义词相似度计算所依赖的词汇句法分析实际上存在于随后的顶点相似度计算中,因此过早引入触发词相似度计算显然得不偿失。
2) 3.1节中,顶点相似度比较涵盖了4个层面,作为人工过程,这些都易于操作,但就机器实现而言,语义层面的比较暂时需要放弃,因为目前中文语义角色标注的准确率还难以满足实际需求[17],没有准确的语义角色作为先验知识,语义层面上的相似度计算只能是纸上谈兵。况且,实体、词汇、句法3个层面上的属性及其结构比较属于浅层句法分析,而此过程又是浅层语义分析的基础[17],因此暂时放弃语义层面的比较不是好逸恶劳,而是步步为营。
在顶点相似度人工比较过程中,每个层面都用到了两种粒度的比较单位,一种是原子级的属性,另一种是分子级的属性结构,属性是基本的比较单位,原则上不可再分,属性结构是具有拓扑结构的属性集合,可以部分或整体参与比较。在事件类型识别中,两种比较单位的相似度都需要计算。
(1) 属性的相似度计算公式为式(1):
上式中,Ps、Pc分别表示标准模型和比较模型的属性集(超图的顶点集),由于比较在相同观测层面进行,因此Ps和Pc中元素的内涵相同,加之标准模型的属性个数|Ps|为常量,所以两集合公共属性的个数实质上就反映两者在特定层面的相似度。
(2) 属性结构相似度计算公式为式(2):

至此,本文已针对EHM设计了一个两部分(超边和顶点)三层面(实体、词汇和句法)双粒度(属性和属性结构)的事件类型识别方法,此方法的流程如图4所示。

图4 基于事件超图模型的类型识别流程
图4中,虚线框区分了超边和顶点两部分运算,粗实线标识了标准模型中各个层面的属性及其结构。图中显示,当触发词类别相同时,三个层面的相似度计算结果依据相应权值进行累加,当最终结果大于阈值时,判定事件类型相同,否则继续扫描下一事件类型,直到所有事件类型被扫描完为止。按权累加的公式如式(3):
(1-βi)Simps(PSs,PSc))
(3)
上式中,α、β分别是层面权值和粒度权值,虽然两者的具体取值因事件类型而异,但已有成果表明α∈[0.2,0.27],β∈[0.2,0.3],阈值γ=α+β[18]。
下面通过实例验证上述事件类型识别流程的可行性。例如,任命事件的触发词包括“任命、选、选举、提名、选聘”,该事件在实体、词汇、句法3个观测层面的属性及其结构分别表现为: “H(/O)+_H+P、H+被[H(/O)]+_P(“[]”中的内容是可省略项)”,“N(/NP)+_+N(/NP)+N(/NP)、N(/NP)+被N(/NP)+_+N(/NP)”,“主+_宾+宾补、主+被[宾]+_ 宾”[14]。现有4个例子如下:
③ [墨总统]H任命[马里奥]H为[外交部长]P。
④ 这次任命被[参议院]O认定为非法行为。
⑤ [张双]H被提名为[局长]P。
⑥ 《赵氏孤儿》被提名为“华表奖”优秀影片。
经计算,γ的取值区间为[0.4,0.57],例③、④、⑤、⑥的Simm(Ms,Mc)值区间分别为[0.6,0.81]、[0.2,0.38]、[0.4,0.54]、[0.14,0.31]。因此,例③、⑤能突破最小阈值从而被识别为任命事件,而例④、⑥则反之,这与事实吻合。其实,例④正是前言所提的触发词误指,而例⑤、⑥则是触发词多指,可见,基于EHM事件类型识别方法(下文称本文方法)的可行性不仅体现为选正而且体现为判误。
4 实验及结果分析
3.2节的实例证明,本文方法基本可行,但面对成规模的真实语料,本文方法是否有效还依赖于实验及其结果分析。为此本文设计了两个实验,实验1用于测定方法自身的效率,实验2是对比性实验,用于评判方法的优劣。
实验1选取的事件类型是职务变更(如例①-⑥所示),此类型可分为3大类6小类,共有触发词(职务变更动词)37个[14],子类和触发词的包含关系如表1所示。
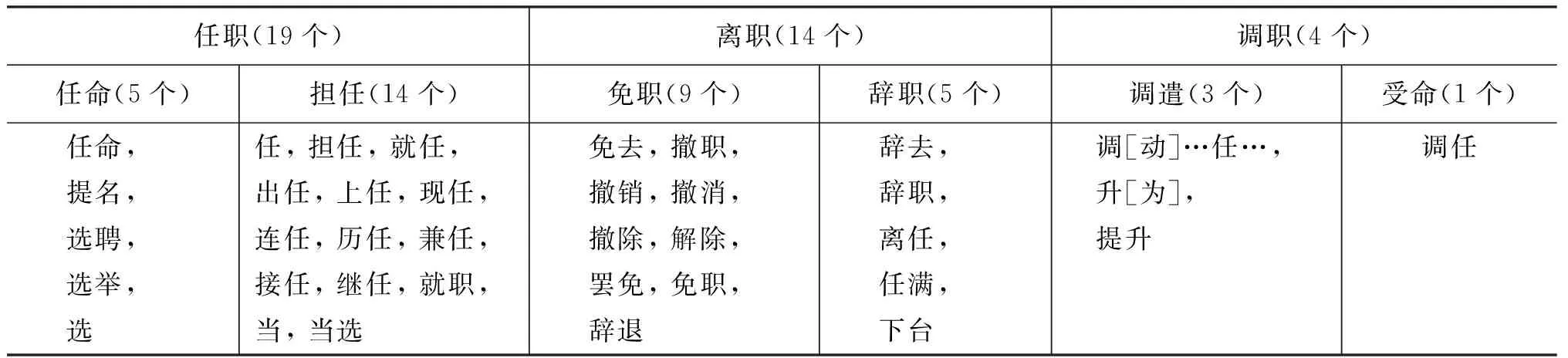
表1 职务变更事件的类别及其触发词
根据文献[14]提供的属性及其结构,实验1为每个子类建立了标准模型,以备调用。由于职务变更事件多见于新闻报道,因此实验1选用华中师范大学语言研究所开发的《长江日报》语料样本作为实验语料,该样本收录了《长江日报》1993~1997年间的3 103篇短文,经人工判定,其中有294篇相关文档和711个相关事件(任命126个,担任243个,免职108个,辞职72,调遣108个,受命54个)。针对上述事件类型和语料,课题组实现了一个半自动化模块用于完成图4中的事件类型识别流程,主要步骤如下。
1) 触发词判别。以表1为词集判断文本中是否存在触发词,若存在,确定其类别并转向此类型的标准模型,若不存在,显示无此类别。判别结果显示,共有324篇候选文档和783个候选事件(任命135个,担任261个,免职117个,辞职81,调遣126个,受命63个),后经人工筛选,确定其中有252篇相关文档和576个相关事件。据此推算,触发词对事件文档的召回率为85.7%,准确率为77.8%,对事件的召回率为81.0%,准确率为73.6%。较高的召回率说明,本文方法以触发词匹配为准入条件是可靠的,同时,相对较低的准确率说明,不单独拿触发词作为类型识别的充分条件是正确的。
2) 实体识别。先根据触发词初定783个候选事件的事件类型,然后选取一组实体识别程序对与其非触发词元素相关的实体进行判别标注。实验1放弃了时间、地点等几乎与每个事件都相关的可用实体,将精力集中在H、O、P这3个必要实体的识别上,语料表明,除H外,O、P都是可穷尽的,除少数不规则形式外,它们都可以通过列举方式获得。例如,组织实体O可用“—党、—国/州/省/地区/直辖市/市/县/区、—部/厅/局/处、—厂/公司、—委员会/协会/理事会/董事会、—校/院/系/所/室、”等列举,职务实体P可以用“—长、代—、副—”等列举。同时,实体除单独存在外,还可能形成组合体,组合体将视为具有最后一级实体特征的整体被标注。H、O、P的组合规则如下:
(1) O+P=P: 省委O+书记P=省委书记P。
(2) P+H=H: 局长P+周鹏H=局长周鹏H。
(3) O+H=H: 政治部O+邓凯H=政治部邓凯H。
(4) O+P+H=H: 总部O+部长P+宋文H=总部部长宋文H。
经步骤1)、2)后,语料形如:
⑦……[蒋祝平]O出任[[湖北省]O[省长]P]P。(《长江日报》,1995-03-14, 01版次)
例⑦中,“湖北省”实指“湖北省人民政府”,因此应该被认定为O。步骤2)后,实验构建比较模型在实体层面的事件超图,并调用标准模型在该层面的事件超图与之进行相似度计算。
3) 分词及词性标注。此步骤在实体识别及组合之后进行,当某一文本片段被标注为实体后,其内部不再进行分词处理。经此步骤后,语料形如:
⑦……蒋祝平/NP出任/V[湖北省省长]/NP。/W
例⑦中,“湖北省省长”作为组合实体后不再分词,直接标注为NP。步骤3)后,进行词汇层面的相似度计算。
4) 浅层句法分析。在分词及词性标注的基础上确定H、O、P的句法成分。经此步骤后,用例形如:
⑦……蒋祝平/主出任/谓[湖北省省长]/宾。
语料分析可知,职务变更文本具有主动(如例③)和被动(如例④、⑤、⑥)两种句式。主动句式中,H充当主语和宾语,O充当主语,P充当宾语和宾补;被动句式中,H充当主语和介宾,O充当介宾,P充当宾语;例⑦的结果与此吻合。步骤4)后,进行句法层面的相似度计算。
步骤2)~4)完成了顶点相似度计算,接下来需要根据α和β的值进行带权累加,由于没有成果指明职务变更事件中α和β的最优取值,因此实验1仍按例③~⑥(3.2节)的方式进行区间估值并据此完成类型识别。至此,实验1结束,结果如表2所示。

表2 职务变更事件类型识别结果
注: Precision(准确率)=识别正确的事件数/候选事件数
Recall(召回率)=识别正确的事件数/实际事件数
F-score(F值)=(2×Precision×Recall)/(Precision+Recall)
表2纵向显示,本文方法在准确率较高的前提下获得了很高的召回率,这说明在本文方法有效地保障下,实验结果与事件在语料中的真实分类非常接近。回顾实验过程可知,触发词召回了大多数相关事件,但误指和多指同时也增加了候选事件,在本文方法判误功能的作用下,多加的候选事件被排除,因此实验结果更接近召回事件的真实分类,也更接近整个语料的真实分类。可见,表2中高值的召回率事实上是对本文方法有效性的侧面肯定。
表2横向显示,任职事件的识别效率要高于其他事件。这是因为与其他事件相比,任职事件各个层面的属性及其结构更加简单,因此,通过句法语义分析,寻找可靠而简单的匹配规则仍是提高此类方法效率的重中之重。
实验2选择的比较对象是基于向量空间模型的SVM(支持向量机)方法和ME(最大熵)方法。作为目前较具代表性的事件类型识别方法,两者的效率均已得到相关成果的肯定[19-20],与其比较,既可以看出不同数学模型对结果的影响,又可以看出不同特征获取方式对结果的影响。本文之所以没有选用完全相同的特征(位置信息)进行对比性实验,主要因为位置信息并不完全适用于SVM方法和ME方法的表达和分析,加之准确的位置信息需要人工校正,而作为主流机器学习方法,SVM方法和ME方法的长处在于自动化,因此选用无需人工干预的特征更能代表其应用本质。
为获取高可信度,实验2基于相同语料和离职事件(离职事件的识别效率居中,理论上最适合代表本文方法的效率)测定了上述两种方法的效率(方法过程可参看文献[19]和[20]),实验结果如表3所示。
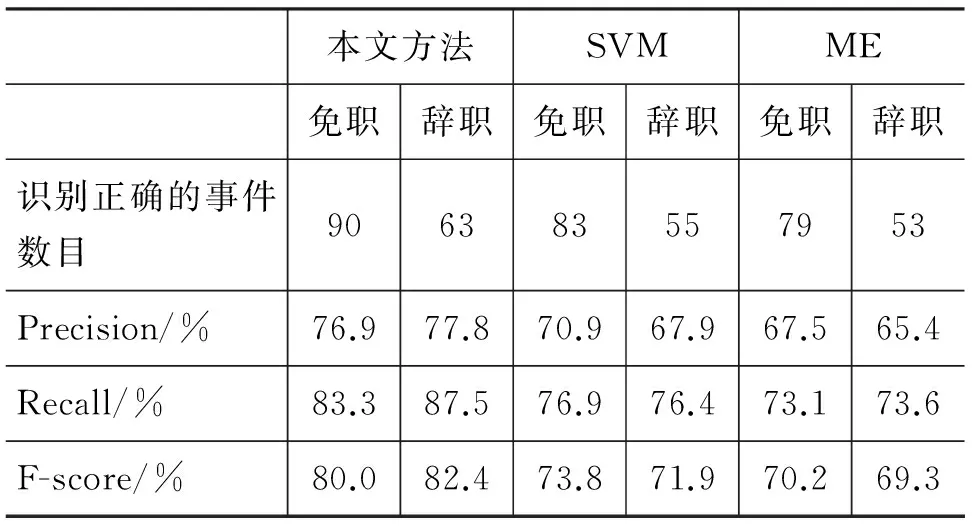
表3 本文方法与其他方法的对比分析
注: Precision,Recall,F-score的定义与表2同
表3显示,与机器学习方法相比,本文方法在效率上存在一定优势。究其原因,一方面本文方法的规则基础是人工构建的标准模型,与机器自动获取特征并形成规则相比,这无疑更准确更规范;另一方面,本文方法使用了属性和属性结构两种粒度的规则,而基于向量空间模型的方法却无法应用具有拓扑结构的规则,这也必将影响识别结果。
此外,表3显示,SVM方法的效率高出ME方法约3%,这与SVM方法更适应小规模语料有关,如果实验2选取大规模语料,在特征一定的前提下,两者的效果理论上不会有较大差别,可见,对不同分类器而言,特征选取更为重要。
综合实验1、2的结论可知,本文方法已具备应用潜力,值得深入研究。
5 结束语
本文方法从数学模型角度对现有事件类型识别方法做出了改变,这种改变不仅体现在表达层次上(用超图描写事件多元有序关系),而且体现在计算层次上(用图模型相似计算事件相似)。从研究过程和实验结果看,这种改变积极而富有成效,但与此同时,它也不可避免地为本文方法带来了以下有待解决的问题。
1) 本文方法以触发词匹配为准入标准,并且放弃了语义层面的比较,因此无法应对触发词缺失和误指现象,如何扩充事件超图对概念逻辑关联的描述能力用于解决此问题亟待研究。
2) 本文方法在综合各层面相似度时采用的是线性拟合,这显得不够细腻,如何针对具体应用最大限度地改进拟合方式仍值得探讨。
3) 目前,事件抽取被视为浅层的文本理解问题,因此本文方法以浅层句法分析为基础的应对思路并无不妥,但随着研究的深入,此问题有向深层转化的趋势,因此,如何提高分析技术,挖掘具备可计算性的深层句法语义规则有待研究。
4) 本文方法属于基于模板的识别方法,与机器学习方法相比,此方法在正确性方面虽然占据优势,但可移植性却无法相提并论,因此如何引入机器学习策略,使其具备自动生成事件超图的能力值得研究。
当然,本文属于基础性研究,很多问题的解决不可能一蹴而就,但只要认定超图是事件表达的有效工具,上述问题都会随着研究的深入迎刃而解。
[1] 赵妍妍,秦兵,车万翔,等.中文事件抽取技术研究[J].中文信息学报,2008,22(1):3-8.
[2] 赵军,刘康,周光有,等.开放式文本信息抽取[J].中文信息学报,2011,25(6):98-110.
[3] 张晓艳.新闻话题和关联追踪技术研究[D].长沙:国防科技大学博士学位论文,2010.
[4] Linguistic Data Consortium.ACE(Automatic Content Extraction)Chinese Annotation Guidelines for Events[OL].http://www.ldc.upenn.edu/Projects/ACE/.[2005-05-09].
[5] 周昭涛,卜东波,程学旗.文本的图表示初探[J].中文信息学报,2005,19(2):36-43.
[6] 仲兆满,刘宗田,周文,等.事件关系表示模型[J].中文信息学报,2009,23(11):56-60.
[7] 肖泉,蔡淑琴,叶波.基于超图结构的知识相似度计算模型研究[J].情报学报,2010,29(5):805-812.
[8] 蔡淑琴,肖泉,吴颖敏.基于超图的知识表示及检索相似性度量研究[J].图书情报工作,2009,53(8):102-105.
[9] Zhou Dengyong,Huang Jiayuan,Bernhard Scholkopf.Learning with Hypergraphs:Clustering, Classification, and Embedding[C]//Proceedings of 20th Annual Conference on Neural Information Processing Systems,2006,Vancouver/Whistler,Canada:IEEE,2006:1601-1608.
[10] C Berge.Graph and Hypergraph[M].Amsterdam:North-Holland,1973.
[11] 崔阳,杨炳儒.超图在数据挖掘领域中的几个应用[J].计算机科学,2010,37(6):220-222.
[12] 徐洪珍,曾国荪,陈波.软件体系结构动态演化的条件超图文法分析[J].软件学报,2011,22(6):1210-1223.
[13] G Gallo,G Longo,S Nguyen.Directed hypergraph and applications[J].Discrete Applied Mathematics,1993,42:177-201.
[14] 袁毓林.用动词的论元结构跟事件模板相匹配——一种由动词驱动的信息抽取方法[J].中文信息学报,2005,19(5):37-43.
[15] 陈耀东,王挺,陈火旺.半监督学习和主动学习相结合的浅层语义分析[J].中文信息学报,2008,22(2):70-75.
[16] 刘茂福,李文捷,姬东鸿,等.基于事件项语义图聚类的多文档摘要方法[J].中文信息学报,2010,24(5):77-84.
[17] 王鑫,孙薇薇,穗志方.基于浅层句法分析的中文语义角色标注研究[J].中文信息学报,2011,25(1):116-122.
[18] Chen F,Farahat A,Brants T. Multiple Similarity Measures and Source-pair Information in Story Link Detection[C]//Proceedings of Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics.Boston,MA,USA:Association for ComputationalLinguistics,2004:313-320.
[19] 于江德,李学钰,樊孝忠,等.最大熵模型的事件分类[J].电子科技大学学报,2010,39(4):612-616.
[20] 李荣陆,王建会,陈晓云,等.使用最大熵模型进行中文文本分类[J].计算机研究与发展,2005,42(1):94-101.
猜你喜欢
通信技术(2021年12期)2022-01-25
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
——以“把”字句的句法语义标注及应用研究为例
中文信息学报(2017年6期)2017-03-12
中国卫生(2016年2期)2016-11-12
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
终身教育研究(2012年4期)2012-03-25
中学生数理化·高一版(2009年6期)2009-08-31
岁月(2009年3期)2009-04-10
