
于数据挖掘(算法)的二进制目标自动建模研究
2013-02-26 08:39:22丁雪平
大众科技 2013年10期
丁雪平
(安徽财经大学管理科学与工程学院,安徽 蚌埠 233030)
1 引言
人类正以惊人的速度产生着大量的数据,如何对这些数据进行处理并得到我们需要的信息,对企业进行有效的指导,越来越受到众多研究者的关注。随着大数据时代的到来,数据挖掘的工作也变得越来越难,处理数据的时间也要求越来越短。如果企业在面对这些海量的数据时,缺乏有效的分析手段,这些蕴藏着大量的、有价值的、相互关联的信息的数据就很有可能成为企业的包袱,甚至是垃圾。数据挖掘技术的应用,成为企业的一笔宝贵的财富。
数据挖掘(DM)又称数据库中的知识发现(KDD)。所谓数据挖掘是指从大量的、有噪声、模糊、随机的数据中揭示出隐含的、先前未知的并且具有潜在价值信息和知识的一个过程。数据挖掘是一种决策支持过程,它是一个交叉学科领域,受多个学科的影响,包括数据库系统、统计学、机器学习、可视化、信息科学等。高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。本文讲述了某金融机构市场部门希望通过为每一位客户提供最适合他的报价,进而在未来的商业竞争中为了获取更为有益的结果。
2 数据挖掘常用算法
数据挖掘的算法有很多,本文选取了几种比较常见的算法,神经网络、贝叶斯网络、决策树、SVM(支持向量机)、KNN、CHAID、QUEST,就优缺点以及适用范围进行简单的比较,如下表1所示。

表1 常用算法比较
由上表可以看出,各种算法都具有许多优缺点,使用范围也是比较有限的。在我们不知道选用何种建模方法更好、更适合的情况下,可以选用二进制目标自动建模方法,这种建模方法可以同时运用多种模型进行预测估计,综合多个模型的优点,并且使得对各种方法的尝试和对结果的比较变得更容易。例如,我们不需要为神经网络选择某个快速、动态或修剪的方式,完全可以全部尝试,或者就直接进行综合以后整体模型的估计,选择执行最好的来指导我们进行预测。该模型还可以选择需要使用的特定建模方法以及每种算法的特定选项,也可以为每个模型指定多个变量。
3 二元分类器
在建模的过程中,我们经常会遇到一些因变量是类别变量,甚至有些是二元变量。如客户的流失情况,仅有客户流失与客户不流失这两种情况;客户的响应情况,也只有响应与不响应这两种结果。例如是否给予客户可能拖欠贷款。在数据挖掘中我们可以使用二元分类器节点进行解决这类问题。
二元分类器就是将一个线性分类利用超平面划分高维空间的情况:在超平面一侧的所有的点都被分类成“是”,另一侧则分成“否”,也就是说透过这个分类器只可以将资料分成两个类别(是或否)。在数据挖掘中,二元分类器能够自动创建和对比二元结果,可以在单次传递中预测和比较多种不同的建模方法,从而简化了对各种算法进行尝试以及对结果的比较,即二元分类器自动建模的关键作用就是无需人工选择建立何种模型,以及如何建模,它完全可以自动建模,并且同时可以比较不同模型的优劣,展示出我们需要的结果。它还可以选择需要使用的特定建模算法及每种算法的特定选项。例如,您无需为神经网络选择快速、动态或修剪之中的某个方式,完全可以全部尝试,而且每种可能的设置组合都可以使用,这就是在数据挖掘中的好处了。此外,在数据挖掘SPSS Clementine软件中该节点可基于指定的选项估计模型集并基于指定的标准对所生成的候选模型进行排序。也就是说一个相对简单的流,能够生成和排列一组候选模型,您可以从中选择那些执行比较好的,然后采用整体节点将它们合并成单一的聚合模型。这种方法综合了自动化与多个模型相结合的好处,聚合模型往往会产生比从任何一个模型更准确的预测。尤其是对于那些不知道哪种模型最适合评估或预测的情况下,可以尝试多种方法,然后进行比较,选择录用最好的模型。
二元分类器节点可用于创建和对比二元结果(是或否,流失或不流失等)的若干不同模型,使用户可以选择给定分析的最佳处理方法。由于支持多种建模算法,因此可以对用户希望使用的方法、每种方法的特定选项以及对比结果的标准进行选择。节点根据指定的选项生成一组模型并根据用户指定的标准排列最佳候选项的顺序。
4 基于实例的二进制目标的自动建模
二进制是计算技术中广泛采用的一种数制。任何一个二进制数据只需要用0和1两个代码来表示就够了。与二元分类器的原理几乎相同,在用二进制目标进行分类预测的时候,我们通常选择“1”表示“是”表达肯定或者是通过,归为第一类;“0”表示“否”表示否定或者没有通过,归为第二类。在这整个分类的过程中都是自动化的,无需人工操作,即得到了最后想要的结果,即自动建模。基于此,本文如下举一个具体的例子进行说明。
本示例基于某一金融公司,金融公司收集了过去四种不同活动的销售信息(分别标明为 1、2、3、4),希望通过对这些历史数据进行分析,进而在以后的营销活动中为每一位客户匹配合适的报价以创造更好的结果。公司记录了向21928名顾客进行推销的详细信息(campaign,)、该顾客是否接受(response)、以及顾客的一些个人信息和其他服务信息,如年龄(age)、性别(gender)、收入(income)等等,全部记录在数据文件pm_customer_train1.sav中。由于四种活动举办的时间、收集的数据量等都有所不同,其中销售计划 2中的记录数量最多,数据比较全,因此本文将重点对一个时间段的销售计划进行建模研究。
(1)数据训练
第一步:添加SPSS源节点,导入数据。数据已跟踪到特定的客户在过去活动中,所提供的活动字段值表示的是历史数据。
第二步:添加类型节点,并选择response作为目标字段,方向设置为输出,其余字段的方向均为输入方向,并将其类型设置为标志。
第三步:添加选择节点。数据包含四项不同活动的信息,但我们将重点分析在一个时间段的活动。由于纪录数量最多属于销售计划于(数据中的编码为 campaign=2),因此我们可以使用Select节点来选择仅包含这些记录中的数据流。
第四步:添加二元分类器节点,进行模型估计。在一、 两分钟之后,一份报告展示出关于每个在运行期间的模型估计所列出的详细的信息。(在实际情况下,在一个大的数据中,往往需要估计数百个模型,这可能需要花费几个小时)。我们可以浏览结果并生成建模节点、 模型掘金或为任何您想要使用或进一步探索的模型评价图。在默认情况下,模型是基于总体准确性排序,因为这是选择的二进制分类器节点中的量。以这个标准来衡量,我们可以从图2中看出排名最好的C51模型,但其他几个模型也近乎准确。我们可以通过单击列标题,在不同的列中进行排序,或者可以通过工具栏上的下拉列表选择所需的方法。
第五步:根据这些结果,我们决定选择模型中生成的三个最准确的模型,并将它们添加到流中,使用整体节点结合他们。通过结合多个模型的预测,我们可以避免限制在各自的单个模型中,进而达到更高的整体准确度。
第六步:添加一个分析节点,输出结果。形成的样本流如图所示:
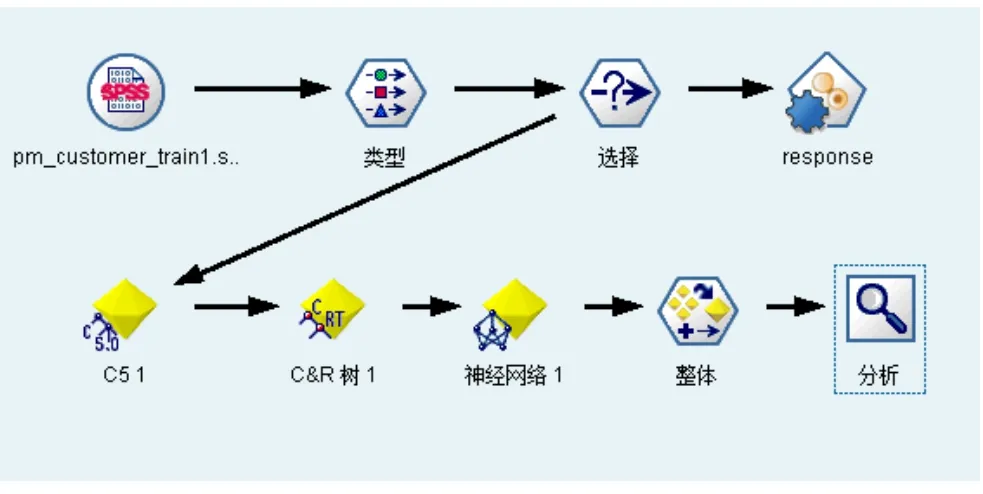
图1 二元分类样本流
(2)模型结果分析
本文选择单个模型中执行最好的C51来分析。从C51模型执行结果可以看出客户是否会购买这种金融产品的主要影响因素是收入(income) 、交易数量(number_transactions)、营销分部(branch)有关。并且影响力最大的是收入,占80%以上。
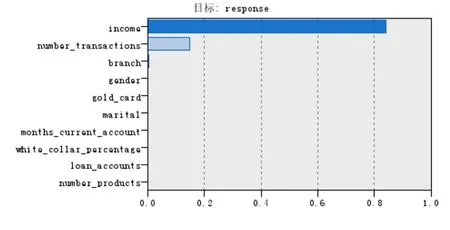
图2 变量重要性判别
基于变量的重要性,我们选最重要的这一个收入作为分类节点来演示对客户进行的聚类,如下表所示:
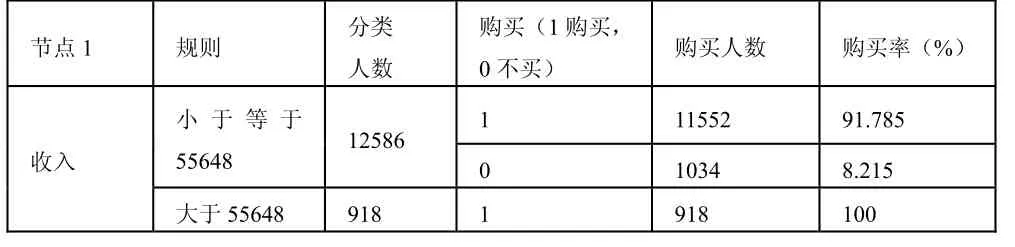
表1 C51聚类
由表可知,收入大于55648的人有918个客户,他们100%会购买这这项金融产品,我们不需要再进行分类,我们可以直接进行预测,只要收入高于此数目,就极有可能购买这项金融产品,我们无需在这些客户中花费大量精力去营销。而收入小于等于55648的客户有12586人,其中没有购买的人有1034人,占8.215%,我们不知道这些不购买客户的具体特点,因此我们继续进行聚类分析。结下来选择交易数量作为分类节点进行聚类。可知交易量小于12的那些客户中,有92.996%的客户没有购买此金融产品,因此我们可以对这些客户群制定策略,进行重点营销。而对于交易量大于12的那些客户可选择branch作为分类节点进行聚类分析,我们能够分析出哪一个行销分支机构的营销工作进行的比较好,进行的不好的那些分支机构如何有针对性的改进工作,提高营销效率,进而是整个组织获得更大的利润。聚合模型的执行结果如图3所示。
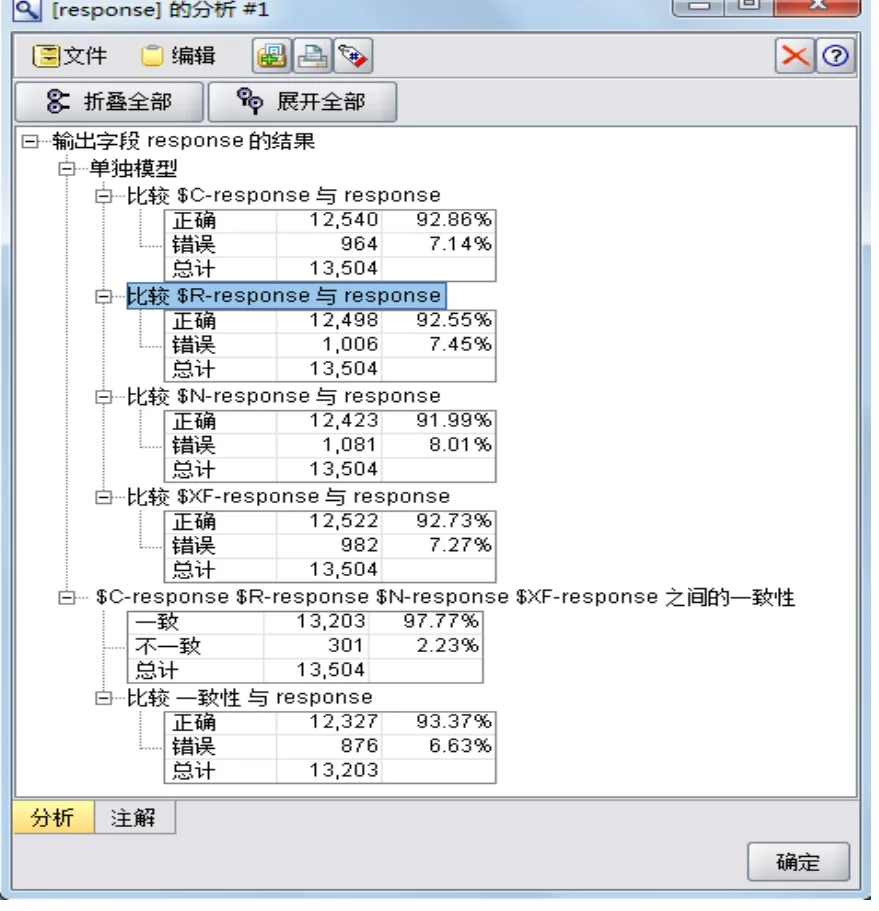
图3 分析节点处理结果
本文把由单个C51,C&R树和神经网络模型生成的预测,分别被命名为$C-response, $R-response,and $N-response(用每个模型类型的前缀与目标字段的名称相结合来确定这些字段名称)。整体模型则命名为$XF-response。在训练数据后进行衡量的测量中,预测值与实际响应相匹配的情况分别为92.86%,92.55%和92.18%。
由上图可以看出,整体模型的整体精确性为92.78%,这4个模型之间的一致性也高达97.77%。在这种情况下虽然不是跟那最好的三个单个模型一样精确,但是区别很小,都在92%以上,因此是有意义的。总体而言,当集成模型应用到数据集以外的训练数据时,通常将有可能表现的更好。
综上所述,本文使用二元分类器节点比较了多种不同的模型,选择生成结果中那些执行较精确的模型,并将它们添加到流,与整体节点结合使用,进行分析预测。基于集成模型、C51、C&R树和神经网络模型上进行最好的锻炼数据,集成模型分析的结果几乎和最好的单个模型一样,并且如果把集成模型应用到其他数据库时,可能会有更好的表现。如果目标是使尽可能多的过程自动化,无需深入挖掘任何一种模式的具体细节时,这个方法就可以让我们获得一个可靠的模型。
5 结语
针对数据挖掘的几种主要算法,分析了各自的优缺点及其所适用的领域。目前数据挖掘逐渐从高端的研究转向常用的数据分析。在国外像金融业、零售业等这样一些对数据分析需求比较大的领域已经成功地采用了数据挖掘技术来辅助决策。尽管如此,数据挖掘技术仍然面临着许多问题和挑战。如超大规模数据集中的数据挖掘效率有待提高,开发适应于多数据类型、有噪音的挖掘方法,网络与分布式环境下的数据挖掘,动态数据和知识的数据挖掘等。总之,数据挖掘只是一个强大的工具,它不会在缺乏指导的情况下自动地发现模型,而且得到的模型必须在现实生活中验证。数据分析者们必须知道他所选用的挖掘算法的原理是什么以及是如何工作的,并且要深刻了解期望解决问题的领域,理解数据,了解其过程,只有这样才能解释最终所得到的结果,从而促使挖掘模型的不断完善和提高,使得数据挖掘真正地满足信息时代人们的要求,服务于社会。
[1] 邵峰晶.数据挖掘原理与算法[M].北京:科学出版社,2009.
[2] 陆安生.决策树C5算法的分析与应用[J].电脑知识与技术,2005.
[3] Jiawei Han,Micheline Kamber,Data Mining: Concepts and Techniques, Second Edition[M] Beijing: China Machine Press. 2007.
[4] 陈良维.数据挖掘中聚类算法研究[J].微计算机信息,2006.
[5] 王立伟.数据挖掘研究现状综述[J].图书与情报,2008(5).
[6] 夏艳军,周建军,向昌盛.现代数据挖掘技术研究进展[J].江西农业学报,2009.
[7] 陶翠霞.浅谈数据挖掘及其发展状况[J].科技信息,2008(4).
[8] 谈恒贵.王文杰.李游华.数据挖掘分类算法综述[J].微型机与应用,2005(2).
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
电子测试(2018年1期)2018-04-18 11:52:35
电力与能源(2017年6期)2017-05-14 06:19:37
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
信息通信技术(2015年6期)2015-12-26 01:16:46
电测与仪表(2014年15期)2014-04-04 12:05:20
