
语料对齐研究与Macken 句子层以下对齐模式介评
2013-01-24 07:45陈吉荣
当代教育理论与实践 2013年5期
陈吉荣
(辽宁师范大学 外国语学院,辽宁 沈阳116029)
一 语料对齐研究背景
随着计算语言学的兴起,语料库在外语教学中的重要作用日益突显。“以语料库语言学理论为基础的翻译语料库,汇集了译成外语的各种真实的语料,并对语言现象用计算机进行统计、比较和分析。作为一种实用方法,翻译语料库不仅可以为探讨翻译文本的性质、译者的个人风格、源语对文本类型的影响,以及其他一些翻译学者和语言学家感兴趣的问题提供了广泛的研究空间。同时,作为一种具体而又详细的资源,它还可以为研究者验证理论上的翻译性质是否有效,实践中的翻译方法是否可行”[1]。由于基于语料库的翻译教学形式具有学习直观化、资料多元化、译作精准化、效果显著化等四大方面的特点和优势,平行双语语料库在外语教学与研究中发挥着越来越大的作用。但是,由于不同的语言在拼写形式、语法逻辑和词汇搭配等方面存在着差异,语料对齐就成为外语教学和研究中的一个重要环节。
目前,国内外对语料对齐技术都有研究。近20年来,国内的语料对齐研究取得了很大的进步。已经发表的科研成果论文有51 篇。这些研究成果可以分成以下几个方面:第一大类是对齐算法研究,如薛松的《汉英平行语料库中名词短语对齐算法的研究》,刘小虎等的《基于词典和统计的语料库词汇级对齐算法》和熊伟等的《面向小词典的高效英汉双语语料对齐算法》。第二大类是语料库建设研究,如高翔等的《句对齐有声语料库在英语语音教与学中的应用》,赵芳婷等的《纳-汉双语语料库构建及双语语料对齐》,张跟兄的《蒙汉双语对齐语料库》、刘非凡等的《大规模非限定领域汉英双语语料库建设及句子对齐研究》,徐德宽等的《论文摘要汉英对齐语料库的建设及应用》,陈晴等的《基于双语句对语料库的词对齐模型》。第三大类,是关于对齐方式的研究,如李秀英的《基于历史典籍双语平行语料库的术语对齐研究》,刘冬明的《汉英双语平行语料库中对齐方法的研究》,肖健的《英中可比语料库中多词表达自动提取与对齐》。第四大类是多语种对齐研究,如毕雪华的《汉维双语语料库中句子对齐技术的研究》,艾山·毛力尼亚孜的《汉维哈柯双语语料库加工系统词对齐技术的研究》,王成平的《信息处理用彝、汉、英三语平行语料库的建设与语料对齐技术研究》,雪艳的《汉蒙词语对齐及相关技术研究》。
国外的语料对齐技术研究在对齐单位上主要以句子以下的单位为主,例如Louise Deléger 的研究表明,可以通过平行文本语料库的字对齐技术来翻译医用术语。通过语料库的字对齐技术,获得了平均值为[(74.8% +77.8% +76.3%)/3=76.3%]的语言准确的新术语翻译,该研究验证了使用文本语料对齐技术可以帮助译者翻译新的术语,这一发现也为其他不同的翻译过程提供了理论框架,有利于外语教学和研究。此外,国外对基于长度基础和文本基础的对齐技术也很重视。Christopher C.Yang 等的研究表明,长度基础和文本基础是对齐平行文件的两个主要方法。许多平行文本对齐技术试图采用不同的文本单位作为翻译单位,以此来衡量双语词法,自动翻译验证和自动活获取翻译知识,其中翻译对齐技术在自动语料库建构过程中起到了对齐文本的重要作用。通过基于长度基础和文本基础的自动题目对齐方式来建构平行语料库又可以为语料对齐和语料库构建提供新的思路。第三,在语料对齐技术中使用自构建语义图示,如Qing Maa 等的研究表明,可以使用SOM 作为自构建设计或者图示。研究者最初使用从中日两国报纸上选取的、根据其语法关系所做的对应词语作为自构建词语,然后把这些词语解码为向量提交给SOM,并考虑其间相互的语义关联,再使用词语相似度来进行计算。自定义的单语语义图示可以根据不同的标准来评估,例如准确度、F 值、回溯,还可以通过词簇规律比较和多样的统计分析来进行。这种基于语义基础的字对齐技术对语料对齐研究也很有启发。第四,使用P - NNT 与GMM 的句对齐技术。Mohamed Abdel Fattah 的研究表明,尽管平行语料库在多语加工过程中已经成为一个重要的来源,句子对齐的平行语料对于机器翻译来说意义重大。这种方法主要使用几率性的神经性网络和高斯混合模式,萃取文本对中的特征向量,例如长度、标点符号评分值和同源评分值。通过使用P-NNT 与GMM,使得语料对齐错误分别减少了27%和50%,并且,这些新的方法对任何语言对都适用。Victoria L.Fossum 等还研究了词对齐过程中的整合与解析。
这些语料对齐的研究对外语教学中的语料库建设、语料对齐技术与语料对齐方式等都有很多适用价值,值得借鉴。考虑到国内外语教学特别是翻译教学的特点,句子层以下的语料对齐技术更有实用性。
二 Macken 句子层以下对齐模式
黄俊红等对2007年以前的国外语料库对齐技术做了综述性评价,指出目前四种主要的对齐技术,并分析了各自的优缺点。例如,句子级对齐技术是最为重要且较为成熟的自动对齐技术,但是在处理复杂句子的对齐以及不同语系的句子对齐时,准确率可能却并不高。基于词汇层的对齐方法虽然可以提高对齐的准确性,但却费时。多词组合单位对齐在不同语系语言对的对齐过程中可能出现问题,从句和段落的对齐也有其自身优缺点,从句的对齐更难且容易出错[2]。针对中国外语课堂教学特别是翻译教学的实际情况,多数学生没有接受过长时间、有计划的翻译实践与翻译能力训练,课时少、课堂内外翻译实践有限,学生在解决翻译问题时的语言单位小于成熟的译者或者训练有素的译员,前者往往以词或者短语为翻译单位,而后者常常以句子为翻译单位。同时,中英两种语言在类符和形符、切分单位、断句以及术语分类方面有很大差异,句子层的对齐模式有时候会出现不准确的情况。考虑到这些实际因素,则句子层以下的对齐模式是可以借鉴的方法。
根据MACKEN 的定义,句子层以下的对齐方式是指:“在句子水平以下的翻译对应的自动对齐,可能是词,词组或者词块”[3]。关于句子层以下的对齐技术,也有一些相关研究。Lars Ahrenberg 认为数据的选择和突出样本将会对词语级别的对齐技术产生影响。Rada Mihalcea 等探讨了词对齐技术中的分享责任。Wu Hua 等认为词对齐技术改善了翻译质量并且节省了20% 的翻译时间,Declan Groves 等研究了数据导向的翻译和数据导向的分析在语料对齐中的作用。此外,Katharina Probst 等研究了使用类似评分系统来改善句子层以下的对齐方式的双语词典,Y.Choueka 等研究了一个比较全面的双语词汇对齐系统,这些研究为句子层以下的对齐技术研究提供了理据。
2007年,比利时的Lieve Macken 发表了研究论文Analysis of Translational Correspondence in View of Sub-sentential Alignment。2010年,他的理论更加成熟,完成了博士论文Sub - sentential Alignment of Translational Correspondences。综合这两个研究成果,Lieve Macken 句子层以下对齐模式其特点就非常明显。
Macken 的句子层以下对齐模式既适用于计算机辅助翻译教学也适用于一般情况下的人工翻译。其主要特点是关注不同的文本类型,并且关注准确性。该模式使用了各种不同的文本类型的平行文本,目标使用者最终设定为人类译员,目的是为其提供一个具有极高精确性的对齐划分单位模式,并对对齐做出评价。
虽然在实际的验证过程中,Macken 使用了英语与荷兰语的语言对,但是他认为这种句子层以下的对齐模式是不受语言对限制的,可以在翻译活动中通用。其中,手动引用的语料库包括三个不同类型的关联:直接对应的常规关联,不同类型的专门翻译转换的模糊关联,以及无对应的零关联。不同文本类型的不同的写作和翻译文体呈现出不同数量的常规关联、模糊关联和零关联。而句子层以下的对齐模式是由级联模式构成的,包含两个阶段。在第一个阶段,以词汇对等和句法相似性为基础将锚点词块进行关联。在第二个阶段,使用引导方式来萃取专门翻译模式中的语言对。这种对齐模式是词块驱动的,只需要针对源语言和目标语言的极浅的语言加工工具,例如词性标签与词块。
为了产生词汇对应,Macken 试验了两种不同类型的双语词典:手工的双语词典和概率的双语词典。在引导实验过程中,Macken 使用精确的GIZA + +与字对齐相交。预设的系统改善了相交的GIZA+ +字对齐的回溯性,保持了精确性,并使得对齐结果在融合计算机辅助工具和双语术语萃取工具方面更有用。而且,对齐不连续词块的系统能力使得该系统对包含分离的言语构建和短语动词的语言更为有用。该模式可以指导双语术语萃取,也可以将其与商业翻译记忆系统进行比较。
三 对外语课堂教学应用的启示
Macken 句子层以下的对齐模式对于外语课堂教学的启示主要体现在如下方面:
第一是增强了语料对齐技术的准确性,有利于提高课堂教学质量。在Macken 的对齐模式中,特别重视精确性和回溯性。精确性是指系统所产生的多少关联是准确的。回溯性是指系统建立了多少关联,也因此是衡量系统覆盖率的指标。这两个特点在对齐模式的四个评估矩阵中都有体现。
第二是为语料对齐提供了多种量化的评估途径。主要包括四个方面:F 值,对齐错误率,加权F 值,词块水平的F 测试计算。在这些计算公式中,同时进行手动对齐与自动对齐的比较。例如,F 值的计算公式为:
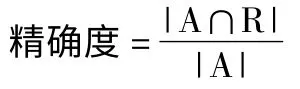
A 代表系统自动对齐的数对,R 代表手动对齐的数对。
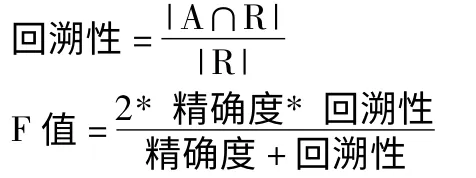
由上述公式可以看出,精确性和回溯性的计算是取手动对齐和自动对齐的交集,两者的比较和差异可增强译者对句子层以下翻译对齐单位的认知,从而辨别翻译错误并学习新的翻译方式。类似的,在对齐错误率的计算中,Macken 也采用了上述计算思路,特别是他对准确对齐和可能对齐的区分更增加了对错误分析的准确性,同时也兼顾了翻译过程中多样化的表达。Macken 的加权F 值更加关注短语对齐,其赋值方式和算法思路与前两项也类似。
第三,对于复杂多样的翻译对等来说,比较并为不同的对齐系统赋分并不容易,因为这些对齐不能简单地以对错来划分。Macken 的对齐模式为各种多变的翻译对等提供了解释的途径。
第四,学生可以通过此模式更为直观地了解翻译对等,对翻译级阶、翻译单位等都有更为深入的认识。同时也有利于在课堂教学中选一个好工具,提高速度,同时降低建库的成本。
[1]李丙奎.析翻译语料库与翻译教学和翻译人才培养[J].语文学刊,2011(12):27 -29.
[2]黄俊红,范 云,黄 萍.双语平行语料库对齐技术述评[J].外语电化教学,2007(6):21 -25.
[3]Macken L.Sub - sentential Alignment of Translational Correspondences[D].Universiteit Antwerpen,2010.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
思维与智慧·上半月(2022年4期)2022-04-08
小哥白尼(神奇星球)(2021年4期)2021-07-22
天津外国语大学学报(2020年1期)2020-03-25
海外华文教育(2016年1期)2017-01-20
湖南工业职业技术学院学报(2016年6期)2016-04-17
汽车观察(2016年3期)2016-02-28
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
