
基于熵的聚类入侵检测算法研究
2013-01-10 03:48叶正旺
通化师范学院学报 2013年12期
叶正旺
(通化师范学院 网络信息中心,吉林 通化 134002)
随着计算机网络技术的飞速发展,信息产业得到了巨大发展,同时也给网络信息安全带来了威胁.保障网络信息环境安全已经成为全社会各行各业高度重视的问题.网络入侵检测技术是对计算机和网络资源上的一些恶意攻击行为或者特征使用行为进行识别,为入侵特征提取提供重要信息.入侵检测系统能够检测来自外部的入侵攻击行为,通过对审计追踪事件分析,发现系统中未授权行为和异常活动,是信息安全防护的重要途径.
基于上述的研究背景,本文进行了以网络入侵为主的基于聚类技术的入侵检测的研究.本文把信息论的知识引入到聚类的重新分类中,提出了以聚类分析为主线的入侵连接记录的检测算法.为了提高检测算法对未知入侵的检测有效行为,提出了一种新的聚类算法用于进行入侵检测,通过计算数据记录中记录信息熵和相对熵对聚类重新聚类来分析入侵行为的异常性,将信息论中熵与聚类结合建立检测模型.
1 信息熵概念
信息熵是信息理论中一个非常重要的概念,它是信息论中用于度量信息量的,衡量一个随机变量取值的不确定性.就数据集合来说,信息熵可以作为数据集合的不规则程度的量度.从随机过程的角度介绍信息熵的概念,设X是一个随机变量,S(X)是X取值的集合,p(x)是X的概率函数,则信息熵E(X)公式如下:

(1)
E(X)是随机变量X的信息熵,用来衡量随机变量取值的不确定量度.
定义1:设定数据集合X它的每一个数据项属于一个类x,x∈Cx,那么相对于|Cx|种分类,X的熵定义为:
(2)
其中p(x)表示属于类x的数据项在集合中的概率,而Cx为类的集合.
对于含有多个属性的记录X={X1,X2,……,Xn}的信息熵计算如下:
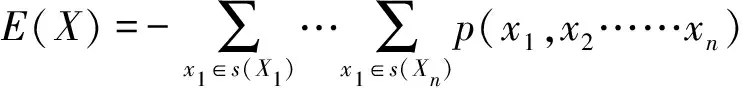
(3)
如果记录的属性之间互相独立,则每个属性概率的乘积正好等于属性值的联合概率,因此总的信息熵就等于每个属性的信息熵的和:
E(X)=E(X1)+E(X2)+…+E(Xn)
(4)
信息熵较适合处理具有分类属性记录的聚类问题.对数据集合而言,熵是确定一个数据项属于哪一类所必须用到的编码位数.根据聚类分类判断准则,同一聚类中的数据越相似越好,说明数据越有序,越纯净.由此推出,“熵值越小,聚类越好”.
定义2:设p(x)和q(x)是定义在x∈Cx之上的两个不同的概率分布,则p(x)和q(x)之间的相对熵为:
(5)
相对熵其主要的性质如下:

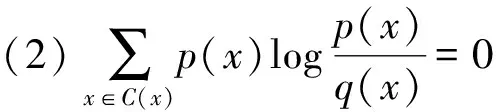
由上述性质,当p(x)和q(x)为两个离散分布时,相对熵可以作为二者符合程度的一个度量.在此应用相对熵来衡量两个数据集规律性的相近程度,相对熵越小,说明两个数据集合的规律性越相近,如果相对熵为0,则意味着两个数据集具有一样的规律性.
2 入侵检测聚类形式化概述
采用信息熵对分类属性的入侵记录进行聚类处理与使用相似性系数对具有分类属性的入侵检测记录进行聚类处理具有相同的结果.利用上述描述的信息论的知识对入侵检测聚类进行形式化描述.
首先要定义一个连接记录R,R的定义模型如下:
R(R1,R2,……,Rn)

算法采用信息熵和相对熵的组合熵的值进行重新分类.在此需明确定义函数模型,使期望信息组合熵值最小,期望组合熵的表达式可以定义为:
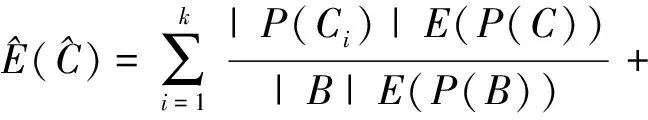
(6)
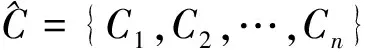
3 基于聚类入侵检测算法
算法实现如下:
(1)初始化聚类过程是随机的在数据库B(大小为N)中取出m个记录(m≤N)作为样本空间M,并从样本空间M中筛选出k个最不相似的记录完成初始化聚类.
具体实现策略为:首先对M中每一对连接记录用公式(1)计算信息熵E({Ri,Rj}),i,j≤m,根据熵值,将每个记录与M中的任意其它连接记录的信息熵进行比较,找出熵值最小的hi=min(E({Ri,Rj}))与之相对应的那个记录Ri,该最小信息熵值被定义为基准信息熵,通过基准信息熵体现Ri与M中其它记录之间的最大相似性.将这些记录分配给不同的聚类,实现了对随机取出的m个记录(m≤N)筛选出k个最不相似的记录作为初始聚类的中心O={O1,O2,…,Ok}.
(2)计算未被作为聚类中心的剩下的其它全部记录,按记录在数据库B中的先后顺序逐个对记录进行聚类处理.
具体实现策略为:将一个记录预分配给初始聚类中的一个聚类,并计算增加了这个记录的聚类的信息熵,再根据公式(6)计算这种预分配方案情况下相对组合熵的值.然后,将这个记录预分配到其它聚类进行同样的计算,在所有的相对组合信息熵中找出熵值最小的那种预分配方案为最佳方案,为每一个数据记录找到一个最合适的聚类分组.
(3)阀值α的确定,在对聚类进行重新分类时我们设定一个阀值α作为我们建立新类的判断点,这个阀值α定义的精确程度将直接影响入侵检测误报率的高低.


(7)
在这里定义∑E({Oi,Oj})为所分聚类中任意两个聚类的信息熵的总和,通过求平均值的方法确定阀值α.这样阀值α的定义可以更加准确的定义聚类的重分类标准.当我们判断完一个数据记录时,需要更新阀值α,也就是对任意两个聚类重新进行求和,然后再确定阀值α.
(5)如果有新的聚类生成,则对聚类进行重新调整.否则转到步骤(2)对下一个记录进行判断,直到所有记录判断完成.
整个算法的实现过程可以用图1描述:
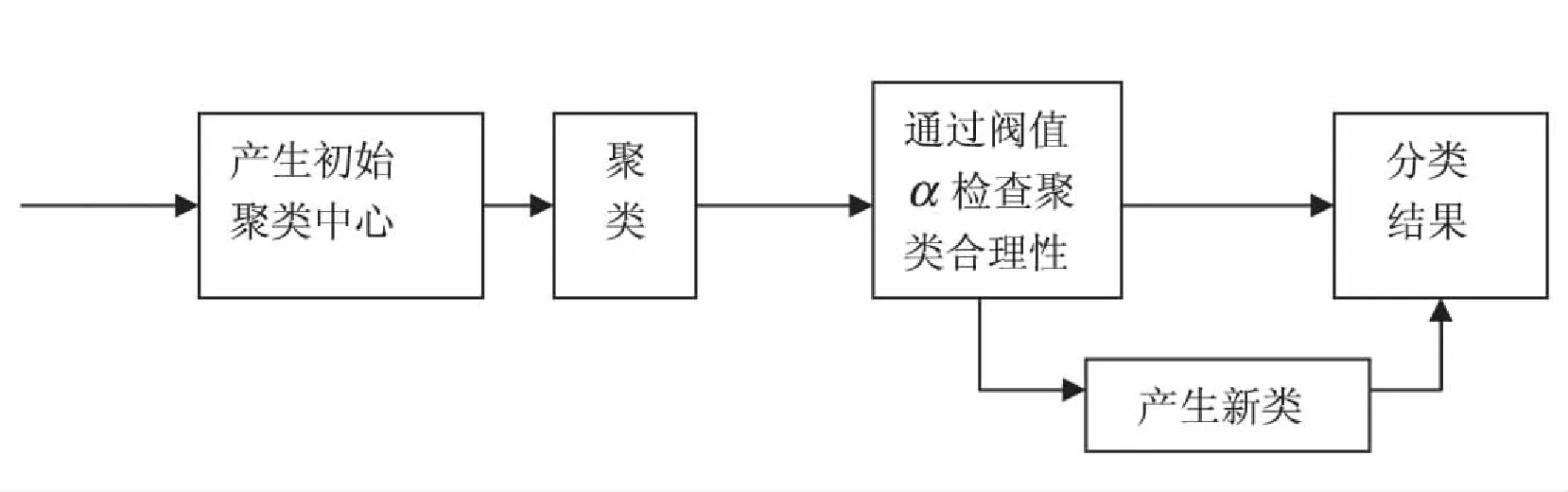
图1 聚类流程图
4 总结
本文将信息熵理论引入到聚类的解决方案中.建立的数据模型通过求聚类内信息熵与聚类间相对熵和的方法来解决入侵检测聚类问题.提出了一种面向信息组合相对熵的聚类算法,把信息熵的概念引入聚类算法中,并论述了算法定义与实现过程,对聚类结果进行了标类,并定义了阀值来解决聚类的顺序相关性对聚类质量带来的不良影响,使得对聚类有一个精确的描述,使入侵检测系统检测率有所提高.本文是以网络入侵检测为主,针对算法的实现并没有应用于现实.接下来研究重点是如何将聚类分析运用到基于主机的入侵检测中去,最好研究出统一的算法集成这两类检测方法,使算法在检测率提高的同时,误警率有所降低.
参考文献:
[1]Lunt T F,Jagannathan R,Lee R et al.IDES:The enhanced prototype-a real time intrusion detection expert system[J].Computers & Security,1993,12(4):405~418.
[2]D.E.Denning.An Intrusion-Detection Model[J].IEEE Transaction on Software Engineering,1987,13(2):222-232.
[3]Denning D E.An Intrusion-Detection Model [J].IEEE Symp on Security & Privacy,1986:118-131.
[4]Guha S,Rastogi R,Shim K.ROCK:A Robust Clustering Algorithm for Categorical Attributes[J].Information Systems,2000,25(5):345~366.
[5]X.Li,N.Ye.A Supervised Clustering Algorithm for Computer Intrusion Detection[J].Knowledge and Information Systems,2005,8(4):498-509.
[6]Lee Wenke,Xiang Dong.Information-Theoretic Measures for Anomaly Detection[C]//Proceedings of the IEEE Symposium on Security and Privacy,2001:130~143.
[7]E.Leon,O.Nasraouli,J.Gomez.Anomaly Detection Based on Unsupervised Niche Clustering with Application to Network Intrusion Detection[C]//Proceedings of the Congress of Evolutionary Computation,IEEE press,2004:502-508.
[8]熊家军,李庆华.信息熵理论与入侵检测聚类问题研究[J].小型微型计算机系统,2005(7):1163-1166.
[9]王军,李敏,肖德宝.基于信息熵的入侵事件依赖性研究[J].计算机工程,2004(9):108-109.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
铁道通信信号(2019年6期)2019-10-08
北京航空航天大学学报(2017年5期)2017-11-23
雷达学报(2017年6期)2017-03-26
雷达学报(2017年6期)2017-03-26
商情(2017年1期)2017-03-22
建材发展导向(2016年2期)2016-05-19
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
电脑知识与技术(2015年24期)2015-11-17
