
PostgreSQL的SSD优化方案*
2012-12-30 09:48:06张振龙
电子器件 2012年4期
张振龙
(厦门大学计算机与信息学院,福建厦门360000)
近几年,越来越多的非关键性业务开始尝试使用开源数据库以节省成本,在开源数据库中PostgreSQL是功能最为完善的关系型数据库。本文选取PostgreSQL作为原型数据库。
SSD(固态硬盘)是摒弃传统磁介质,其存储优势是高速的顺序读取和顺序写入,高速的随机读取性能;劣势是价格偏高,寿命较短,以及写入放大,本文将结合SSD的特点,将其使用在数据库系统中,以提升数据库系统的整体效率。
1 相关工作
目前许多知名数据库厂商也针对SSD提出了自己产品的改进方案,许多学术研究也把SSD中使用数据库优化作为研究方向。研究点大概集中在以下几点:
(1)将整个数据库放置在SSD上,提出一种新的数据库存储概念,为闪存数据库,并围绕闪存数据库对数据存储方式提出各种改进算法。但是,由于SSD本身的寿命问题,以及成本问题,该数据库只能应用于小型的非关键性应用。
(2)在关系型数据库中,将日志,索引,临时表空间,回滚段这些信息放置到SSD中,以提高数据库整体执行效率。日志的特点是大量的顺序写操作,而索引,临时表空间,回滚段的特点是顺序写,随机读。而且这些数据都属于是非关键性数据,可重建,因此,如果一时的SSD损坏并不影响数据的一致性。因此完全符合SSD的特点,可以在一定程度上提升数据库的存储效率。
(3)使用SSD作为二级缓存,也就是我们熟知的Oracle的 flashcache,这点 Oracle已经成功地商用,并为其数据库带来了可观的性能提升。利用SSD的特性,把从一级缓存中置换出来的数据存储到SSD中,将SSD其作为二级缓存,由于缓存中的数据也不是关键数据,且在使用时制定SSD读写策略,使其符合随机读顺序写的原则。但是,由于Oracle是商业软件,其对SSD的使用的具体策略并没有公开,本文将使用SSD作为PostgreSQL的二级缓存。
2 PostgreSQL使用SSD优化
数据库对磁盘数据进行访问时,如果是首次,首先将数据从磁盘中取出,然后放置到共享缓存,再从共享缓存中获取数据进行处理。如果要取的数据在共享缓存中已经存在,则直接从共享缓存中获取该数据进行处理。因此,有共享缓存的存在,大大提升了数据库的执行效率,减少了数据库的IO瓶颈。而且,只要是数据库需要的数据,都必须经过共享缓存。
本文先分析了目前PostgreSQL的共享缓存管理方法,然后设计一套策略,并对其进行实现。
2.1 PostgreSQL的共享缓存管理方法
PostgreSQL对共享缓存的管理方式采用哈希表以及描述符的方式进行管理。首先在初始化阶段,PostgreSQL开辟出一块空间,缓冲区描述符合缓冲区块的存储空间是连续分配的,而哈希表则分配在另一个空间中。
在分配完空间后,描述符与共享缓存空间块是一个一一对应的关系,其使用关系则通过哈希表保存,一个缓存块的大小在 PostgreSQL中默认为8 kbyte。而描述符是以一个数据结构的方式存在,具体的数据结构名称叫BufferDesc,在Buf_internals.h中定义,主要的字段有
refcount:用于下文提到的时钟算法轮寻;
bufid:表示所指向的缓冲的块号,默认为4096个块,以整形方式标识;
freenext:下一个空闲块的地址,用于下文中提到的Freelist的管理;
缓冲区管理的核心就是其对缓冲块的分配方式,上层接口请求数据时,发送一个BufferTag的数据结构,该数据结构包含三个字段;
RelFileNode rnode:物理文件的编号;
ForkNumber forkNum:当前的文件分支,PG文件有三种,在这不详细描述;
BlockNumber blockNum:当前请求的文件块号有了这三个值,我们就可以找到对应文件的内容。这个时候,PostgreSQL并不是马上去磁盘读取数据。而是将这三个值作为上文中提到的哈希表的Key,看是否能在哈希表中找到,而哈希表的Value正是bufid。如果能找到,则表示将要请求的这个数据正在缓冲区中,直接返回该缓冲区的内容即可;如果不能找到,再分配一个新的bufid,并维护哈希表记录下这次磁盘读取。
在共享缓冲区满的时候,又有新的请求需要分配共享缓冲区块时,触发缓冲区分配算法,而经典的也是最简单的缓冲区管理算法就是FIFO,但是一般在实际应用中会采用改进的 FIFO算法,例如在PostgreSQL中所采用的算法就是时钟扫描算法。该算法在BufferAlloc.c中调用,时钟扫描算法的基本原理就是,依次扫描所有的共享缓存描述符,在描述符中记录了一个refcount的值,如果该值为0,这将这个共享缓存返回,并使用这个共享缓存块;如果这个值不为0,则把这个值减1,继续找寻下一个。而refcount这个计数器是当这个共享缓存中的数据被访问时累加1,但是最大值为5。
时钟扫描算法的弊端就是要遍历所有的共享缓存块,这样带来了较大的开销。特别是当数据库进行大规模读写,或者数据库进行VACUUM的时候就会对缓存造成频繁的换入换出。因此,在Post greSQL中,对以上场景采用了一种称为环的策略在上层接口中,可以指定共享缓存的分配方式,如果需要进行环的方式分配,则在分配过程中记录事先设定好的环大小,将分配过程中涉及的缓存块形成一个环,之后如果再需要分配,只在环中进行分配而不会动用环之外的缓存块,从而避免整个共享缓冲区被大量换入换出。
在对共享缓存的操作过程中,必然要涉及到锁PostgreSQL中控制共享缓冲区访问有两种锁。
(1)自旋锁:又称为pin锁,利用互斥量实现的底层锁,用于内存块访问。
(2)内容锁:分为共享锁和排他锁,利用pin锁实现的上层锁,用于进程间并发的排他和共享操作
2.2 使用SSD作为PostgreSQL二级读缓存
将SSD作为PostgreSQL的二级缓存一般有三种方式。一种是作为读数据时的缓存(缓存非脏数据),也可以作为写数据时的缓存(只缓存脏数据)最后可以作为读写共存的缓存。而本文对SSD作为读数据的缓存进行详细描述,作为写或者读写缓存的场景在这里不考虑,有兴趣的读者可以自己研究实现。
作为二级缓存的基本思想就是将一级缓存中存放不下的数据转移到二级缓冲中进行存放,而这里的一级缓存指的就是共享缓存。当发生置换时,就是共享缓存满的时候,数据在共享缓存中已经无法存放,这个时候,我们就可以对置换出来的数据进行数据转移,转移到二级缓存中,也就是SSD中,当下次请求这个数据时,我们不需要再从磁盘中读取,而直接从SSD中读取即可。但是,并不是所有从共享缓存中置换的数据都是值得缓存的数据,本文定义了一种筛选规则,如果该数据是随机读磁盘的操作,索引数据或者是新写入的数据则缓存;如果是一个顺序读写磁盘的操作,或者数据库正处在大量读写,镜像,备份等操作时则不缓存。二级缓存基本思想如图1所示。
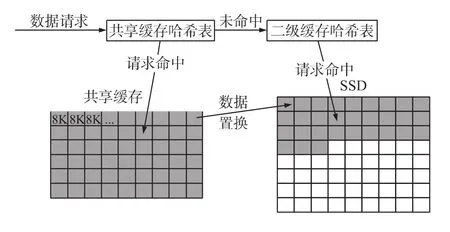
图1 二级缓存基本思想
将SSD作为二级缓存时,首先模仿共享缓存的管理方式,设置一个二级缓存描述符,以及用于保存使用情况的哈希表。当共享缓存发生置换时,具体就是在BufferAlloc这个函数的末尾,也就是已经成功分配了一个bufid作为即将使用的共享缓存块的时候。在原本的逻辑中,数据库将对这个缓存块进行写入覆盖的操作,但是本文在写入覆盖前,对这个共享缓存块的数据进行判断,如果符合进入二级缓存的条件,则将其放置到二级缓存中,等待下次读取。在这里,由于一个PostgreSQL的缓存块只有8K,为了避免对SSD的频繁操作造成写入放大,因此可以在这里做个处理,将多个置换出的数据拼成大块,一下写入到SSD中。
当下次数据请求到来时,具体就是在ReadBuffer_common这个函数中,从函数逻辑中明显可以看出其读磁盘的操作,具体就是smgrread的函数调用之前在这里我们可以添加代码逻辑,使其先到SSD中去寻找想要的数据,而不用直接读取磁盘。
3 结束语
本文详细表述了SSD缓存PostgreSQL中非脏数据的方法,并自己利用TPC-C进行测试,性能约有10%左右的提升。本文中所使用的方法,还有很大的改进空间,如果将脏数据考虑在内,则缓存情况更加复杂,这个可以作为下一步的研究方向。
SSD的特性随着技术的发展,其优势将越来越明显,最终可能取代磁盘作为主要的存储介质。但是,本文的意义不仅在于针对SSD的优化,未来的硬件存储的发展必然是多层次的,例如IBM目前已经推出PCM存储设备。而本文所描述的方法,只要存在多层次存储,便可以借鉴。
[1]Gray J.Tape is Dead,Disk is Tape,Flash is Disk,RAM Locality is King[EB/OL].[2009-07-19].http://research.microsoft.com/en-us/um/people/gray/talks/flash_is_good.ppt.
[2]Mtron.Solid State Drive Msd-Sata 3035 Product Specification[EB/OL].[2009-07-19].http://mtron.net/Upload_Data/Spec/ASiC/MOBI/SATA/MSD-SATA3035_rev0.4.pdf.
[3]Shah M A,Harizopoulos S,Wiener J L,et al.Fast Scans and Joins Using Flash Drives[C]//Luo Q,Ross K A.Proceedings of 4th Workshop on Data Management on New Hardware.New York ACM Press,2008:17-24.
[4]钱学忠.SQL在数据库应用系统中的运用[J].电子器件2000,23(3):185-190.
[5]姜承尧,陈庆奎.基于固态硬盘数据库在OLTP应用中的优化研究[J].计算机时代,2010(8):42-44.
[6]汤显,孟小峰.FClock:一种面向SSD的自适应缓冲区管理算法[C]//NDBC2010第27届中国数据库学术会议论文集A辑一,2010:148-159.
[7]李峰,刘晓洁,林翰翮.基于Oracle数据库的容灾系统[J].计算机工程与设计,2011(11):9-12.
[8]徐得智.Oracle海量数据库系统的优化策略[J].企业技术开发,2009(8):44-45.
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
数字通信世界(2018年1期)2018-04-18 11:05:22
测绘科学与工程(2017年5期)2017-05-07 06:30:44
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
