
基于TMS320DM6446的X264编码器的移植和优化
2012-12-30 09:48:04苏寒松
电子器件 2012年4期
郭 昕,苏寒松
(天津大学电子信息工程学院,天津300072)
H.264是ITU-T的视频编码专家组(VCEG)和ISO/IEC的活动图像专家组(MPEG)联合制定的视频压缩标准,引入了更多的新的高效的编码技术,在相同图像质量下,编码效率提高了50%,但同时带来了巨大的编码运算复杂度,影响了实时的要求。DSP的运行速度已经可以满足H.264对图像进行实时处理的要求。本文采用合众达公司基于TI达芬奇(DaVinci)DSP TMS320DM6446视频处理模板Seed-DVS6446[1]来进行移植工作,由于 H.264 直接移植到DSP平台上编码效率很低,需对其进行优化才能达到实时编码的要求。
1 编码硬件平台简介
德州仪器(TI)推出的TMS320DM6446采用Da-Vinci技术。TMS320DM6446采用双核架构集成了一个时钟频率为594 MHz的C64x+DSP内核和一个297 MHz的ARM926EJ-S内核。TMS320DM6446是定点DSP,便于进行视频处理的任务。由于其内部有一个ARM内核采用精简指令集,所以可以对DSP进行精确的控制,实现DSP的高速处理。并且集成了丰富的外设接口,如DDR2存储器接口、视频处理前端模块VPFE和视频显示设备连接的视频处理后端模块VPBE等,方便进行视频处理[2]。
其中,TMS320C64x+DSP是 TMS320C6000系列里最高性能的定点DSP平台,基于第二代高性能超长指令字结构,使其更适合数字多媒体的应用TMS320C64x+DSP处理器集成了64个32 bit通用寄存器、8个高性能独立功能单元—2个乘法器和6个算术逻辑单元。TMS320DM6446采用二级Cache结构,L1程序Cache为256 kbit直接映射Cache、L1数据Cache为640 kbit的双向配置Cache、L2存储/Cache包含一个512 kbit的存储器空间由程序和数据共享[3]。
2 编码器的算法流程
H264的实现版本主要有3种:JM、X264、T264,相比较而言,作为官方测试源码,JM更偏重于学术研究,编码复杂度高,不宜实用;T264是国内组织自行编写的代码,速度远高于JM,但目前还不甚完善;而X264结合了JM和T264的各自优点,所以本文选用 X264 作为算法原型[4]。X264 编码流程[5-6]如图1所示。
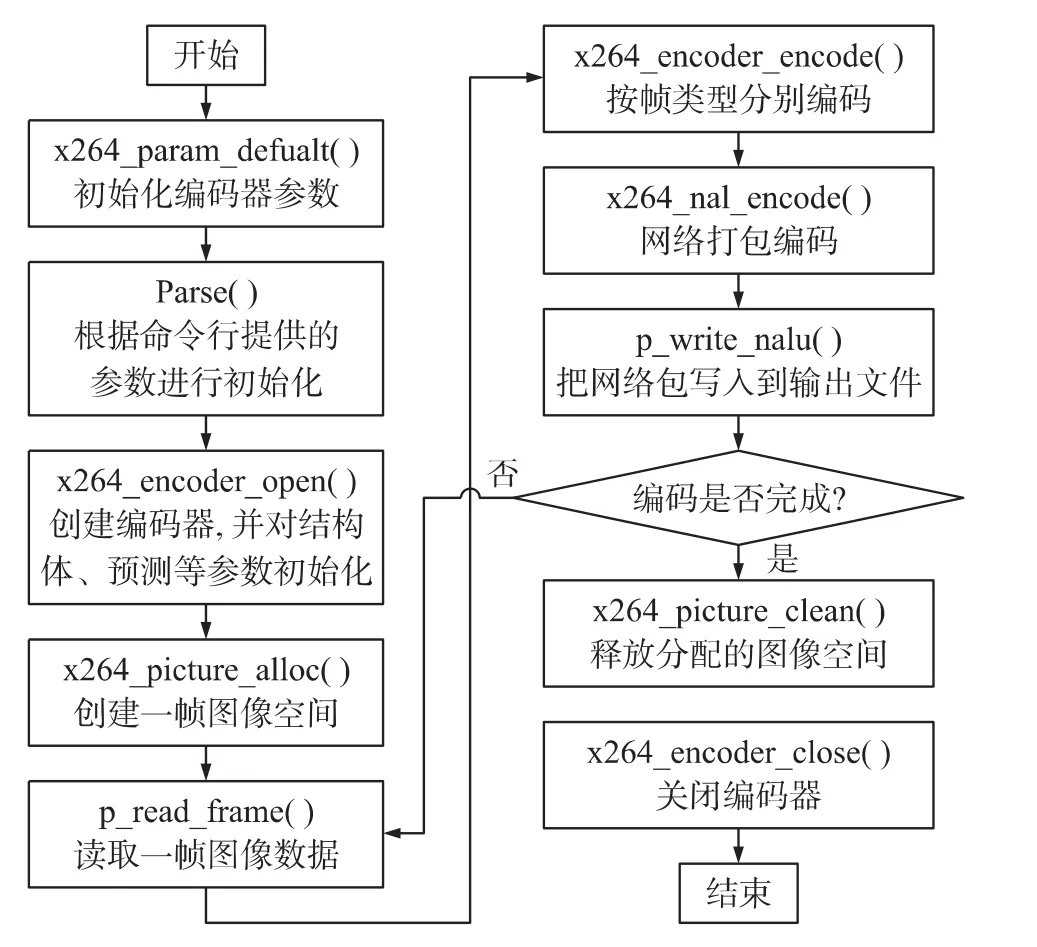
图1 X264编码流程
3 X264编码器的移植
3.1 代码裁剪
Baseline档次已经具备所需要的功能[7],所以删除程序中Baseline档次以外的功能模块(包括cabac.c和eval.c等),以及源程序中的解码部分;因为实时编码应用的环境要求低缓存延迟,而B帧预测需要较大缓存,决定去除B帧;采用帧方式,而去除和场方式有关的代码和数据;muxers.c文件的一些函数主要是定义了对 yuv、mp4、y4m、mkv文件格式的输入输出支持,将yuv部分单独提出来在X264.c中重写,这样重写的代码就只针对yuv视频;由于主处理器TMS320DM6446是定点DSP,然而在X264中存在一定比例的浮点运算,浮点运算是很费时的,因此保留计算 Y、U、V三种分量的PSNR值浮点运算外,其它的都需要删除;在源程序中,使用了大量的语句进行调试和测试,用于观察编译器的状态并防止一些异常情况,如assert函数printf函数、exit函数以及用于help提示信息、文件操作、用户界面操作和Debug信息等,在能够确保程序正确执行的前提上,基本上可以去除;此外很多函数和数据在整个系统中,虽然被定义和声明了,却从来没有被真正使用过,对于这一点,CCS的编译器给出了警告,把这一部分也删除。
3.2 编译器的差异
(1)X264程序是在VC环境下开发的,包含大量适用于VC环境下的头文件,由于TMS320C6000实时支持库包括ISO标准库以及与DSP硬件相关的特殊指令库,与VC的实时支持库不尽相同,一些VC支持的库不被C6000系统所支持,例如VC中支持的malloc、calloc等动态存储分布函数,在CCS中都包含在stdlib库中,因此必须对原来的include文件进行修改;CCS中没有timeb.h只能用DSP/BIOS中的CSL库函数CLK_getltime实现原有的计时系统。需要根据TMS320C6000的优化编译器用户手册在CCS库中匹配到与之功能相类似的文件和函数。
(2)CCS只兼容ANSIC代码,所以需要对非标准C部分的代码进行修改,使之能在CCS环境下运行的C代码。
(3)在VC中,编译器对所有的未初始化的变量默认统一赋上了初值0。而CCS同样会对未初始化的变量进行系统赋值,但赋的值决定于相应存储器位置的原有数据,会造成程序的重大错误。因此,必须在移植时对所有变量进行初始化。
(4)CCS和VC环境下的数据类型并不完全相同,两者数据类型对比见表1。在CCS中,长整型变量long在存储器中被分配了40 bit。从节约CPU处理时间角度考虑应对其进行相应的数据类型调整。
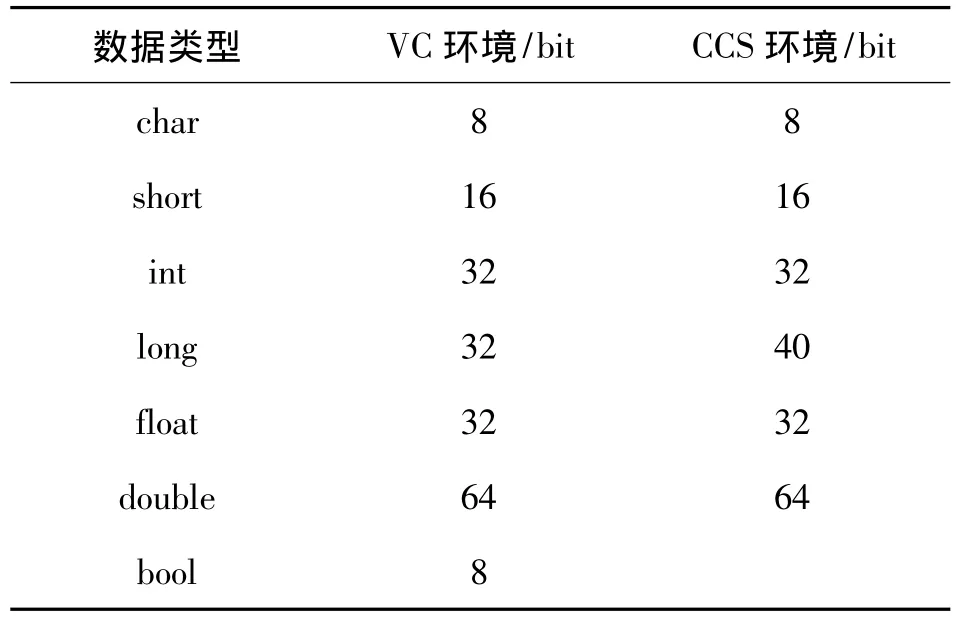
表1 数据类型对比
C语言定义了bool数据类型,而CCS中并未定义数据类型bool,所以如果在CCS中用到bool数据类型时,需要预定义。
(5)原始的X264代码是基于PC平台的,程序通过采用MMX和SSE语言编写SAD、DCT等函数使X264具有很高的编码速度,然而DSP和微处理的体系结构不同使得这些技术不能应用在DSP中,在X264代码中将HAVE_MMX编译选项屏蔽,同时将代码中与该编译选项相关的代码注释掉,只保留用标准C函数编写的部分。
3.3 存储空间的分配
在CCS中,设置程序和数据在寄存器中的存放是由编写.cmd文件来完成的,也可以通过MEM配置工具将每一个段指定到某个逻辑存储器空间中去。除了这种按段整体的分配之外,CCS还提供了一些类似预编译的宏指令如#PRAGMA CODE_SECTION()#PRAGMA DATA_SECTION,可以在代码中把某个函数或者数据指定到某个虚拟存储器空间中去。把进行编码计算中可能被调用频繁的程序段(如DCT变换、SAD)放在片内程序存储区中,把频繁用到的数据段分配到片内数据存储器中,把其他程序和数据段放在片外存储器中,另外,考虑到一帧图像的数据量很大,故将参考帧和当前帧的数据放到片外,在需要用到当前块和参考帧数据时,再将它们从外存读入到内存中,提高效率。
堆(heap)和栈(stack)的默认值为1 kB(kbyte)。可以在编译选项中修改其默认值,也可以用.cmd文件来对系统中的-heap和-stack进行配置。由于X264编码器中存在大量的动态存储空间的分配和函数的频繁嵌套调用,在代码移植初期,应尽量将heap和stack设置的足够大,以防止分配的存储空间不够,优化时再根据具体情况做相应的调整。
4 X264 编码器的优化[8]
4.1 编译器优化[9]:
在代码调试过程中编译器选项设置为-g-kpm-op0-o3-fr"$(Proj_dir)"-d"_DEBUG"-mt-mw-mh-ms0-mv6400+
-g选项使能符号调试和汇编源语句调试。no debug:生成的程序较精简,但不能对其进行调试。对程序调试完成后可以选择此项。
-o3选项使编译器执行各种优化循环的方法,比如软件流水、循环展开和SIMD(单指令多数据流)等技术,使编码时间大概减少到未优化之前的1/2左右,并且和-g选项一起使用时,程序优化不会出现错误。
-k选项选择后,编译器将保留编译过程产生的asm文件,在asm文件中,编译器的缺省的反馈信息也同时保留下来。-mw选项也可以生成详细的消息反馈,反馈信息基本上集中于循环的分析以及如何对循环进行流水编排从而提高性能。用户可以依照其对程序进行修改。
-pm选项表示程序级优化,编译器在编译时可以从整个程序的角度来优化程序。-op(n):通常和-pm一起联合使用,控制程序级的优化。-op0选项说明有外部变量引用和函数调用。
-mt选项向编译器说明代码中没有使用混迭技术,打开-pm和-mt选项后可以提高编码一帧的时间3 ms~4 ms。
-mh:-mh[n]:去掉流水线 epilog(排空),减小程序的大小。
-ms0选项不使用冗余进行优化,减少程序的大小。一般推荐-o与-ms0和-ms1联合使用,表示性能优化最重要,同时要考虑代码尺寸。
4.2 运动估计算法优化
X264编码器提供了4种整像素运动估计搜索算法:X264_ME_DIA(钻石搜索算法);X264_ME_HEX(六边形搜索算法);X264_ME_UMH(非对称十字型多层次六边形格点搜索算法);X264_ME_ESA(全搜索算法)。X264_ME_ESA算法的PSNR(峰值信噪比)最高,X264_ME_UMH,X264_ME_HEX算法依次降低,X264_ME_DIA算法最低,但相互之间的质量差别并不大,码率差别也很小,但编码速度上X264_ME_DIA算法最快,为了满足实时的要求,选用X264_ME_DIA算法并对其改进[10]。
(1)匹配准则
运动估计一般的匹配准则是采用率失真最优化,准则匹配误差函数为:

其中SAD(绝对差值和)计算公式如下:
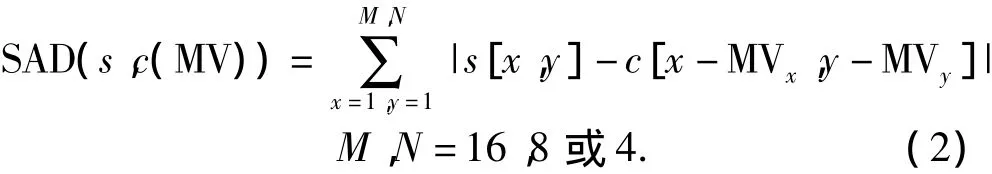
式中:M、N分别表示当前编码宏块的长宽尺寸R(MV-PMV)代表了对运动矢量差编码所需比特数;λmotion为拉格朗日常数[11]。文中将J(MV λmotion)最小的点记为最小误差点MBD(Minimum Block Distortion)。
(2)搜索起点
候选的 MV包括:当前块的预测运动矢量PMV;当前块左、左上、上、右上块的运动矢量MV参考帧(本文只采用一个参考帧)中的当前位置块、右边块、下边块运动矢量乘以时间差权重之后的MV;还有(0,0)。在候选 MV中选择使得J(MV,λmotion)最小的为最佳MV,该MV对应的点为运动估计的搜索起点.
(3)搜索方法的改进:以(2)中所得的搜索起点为中心点,对搜索区域内的点以如图2(a)所示的小菱形模板(模板半径为1),进行搜索,即对中心和菱形四个顶点计算匹配误差,得到MBD点,并记最小代价为bcost。若MBD点在菱形的中心,则这个点就是整个搜索域内的最优匹配点,若不是,则以现在的MBD点为中心进行小菱形搜索,直到MBD点落在中心点[12]。
在搜索过程中会出现某些点的重复搜索,例如,从图2(b)中可以看出 a、b、c、d、e为搜索过程中重复搜索的点,重复搜索必然造成运动估计效率低下。采用无重复搜索的小钻石搜索法时,第1次搜索5点,第2次搜索3点(△表示),第3次搜索2点(□表示),第4次搜索2点(◆表示),只需12次搜索,可以省去不少计算量。

图2 钻石搜索模板及搜索路径举例
(4)提前终止:当计算16×16模块时,由计算SAD的代码可知每个块需要计算pixl[x]-pix2[x]减法16×16次,在程序中添加if(i_sum>=bcost)条件判定,若满足提前终止循环计算,即在i_sum的值大于或等于最优的代价时跳出循环,节省多余的计算量,具体程序十分简单不在此赘述。
4.3 EDMA 优化[13]
视频编码需要处理较大的数据量,如一帧CIF格式的YUV数据约有150 kB,而X264除了原始数据输入外,处理完图像数据的传出图像、插值数据输出、图像上下边界扩展、运动估计时参考帧图像的传入等都涉及到大量的数据搬移,但DSP对不同的存储器的访问速度相差数倍。为了提高编码器的运行效率,节省DSP核对各个模块访问所消耗的时钟周期,需要启用DSP的DMA作为数据在两个存储器之间的传输通路。C64x+在外部存储器与内部存储器之间的数据传递可以通过增强型DMA(EDMA)实现。在片内存储器L2中开辟两个大小相同的缓冲区Pingbuffer和Pongbuffer,两个缓冲区轮流交替工作。当EDMA传输数据到Pingbuffer时,CPU处理Pongbuffer中的数据;当CPU和EDMA操作完毕后,Pingbuffer和Pongbuffer缓冲区互换,EDMA继续传输数据覆盖 Pongbuffer中的数据,CPU处理Pingbuffer中的数据。由于传输时间小于编码运算的时间,则EDMA完全独立于CPU在后台运行,不耗费一个时钟周期,实现了数据传输和CPU并行提高了代码的运行效率。
4.4 进一步优化
(1)内联函数优化:C6000编译器提供了许多内联函数intrinsics,可迅速优化C代码,使用时与普通函数一样调用,它们与C6000汇编指令一一对应,直接使用内联函数可以快速实现SIMD[14],如未使用内联函数优化前X264程序计算16×16模块的SAD的函数每次只能计算一个像素点的绝对值差,而使用内联函数_mem4()、_subabs4()等进行优化后,一次可以计算4个像素点的绝对值差,大大提高了运算速度。
(2)循环优化:C语言中使用伪指令#pragma MUST_ITERATE(min,max,multiple)可以明确告诉编译器循环次数或最小循环次数,从而防止冗余循环产生,也便于编译器将循环展开,此外,由于在编译器进行优化时只会在最内层循环中形成一个pipeline,尽量将多重循环拆开形成一个单层循环不要使用多重循环,这样循环语句才能充分利用编译器的软件流水线。
5 实验结果
TMS320DM6446的时钟频率为594 MHz,选取100帧、CIF格式(352×288)的测试序列container foreman、mobile,量化步长取 27,视频为 Y:U:V 4:2 0格式,采用IPPP…编码模式。表2为优化前后各视频序列的结果比较,从表中可以看出,优化后的编码器帧率比优化前有了较大幅度的提高,基本能够实现CIF格式实时编码,PSNR值在优化前后并没有明显变化,说明优化后编码质量未受到大的影响
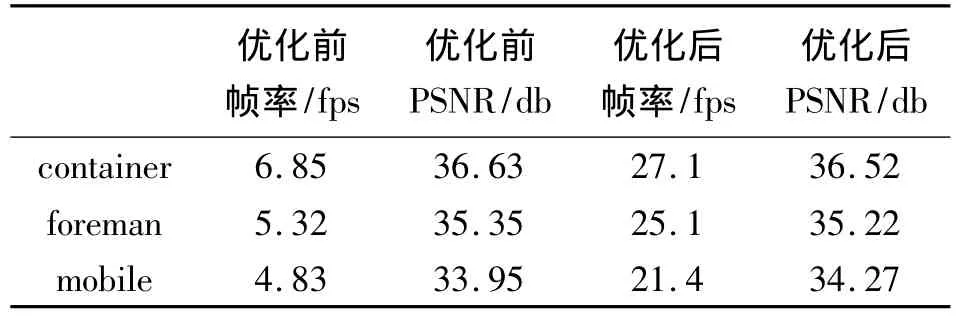
表2 优化前后对比
6 结论
本文结合DM6446的硬件结构特点,将X264编码器在DM6446上成功地进行了移植,并对编译器选项、运动估计、内联函数及DSP在编码时的数据搬移等方面进行了优化,基本可达到CIF格式序列的实时编码要求。
[1]SEED-DVS6446 用户指南[S].Texas Instruments,2008.10.
[2]TMS320DM644x DMSoC VPBE User’s Guide[S].Texas Instruments,2007.04.
[3]李方慧,王飞,何佩琨.TMS320C6000系列DSPs原理及应用[M].电子工业出版社,2003.
[4]李博丞,严胜刚,曲鹏.基于TMS320DM6446的H.264编码器实现与优化[J].电子设计工程,2009,17(05):122-123.
[5]毕厚杰.新一代视频压缩编码标准——H.264/AVC[M].北京:人民邮电出版社,2005.
[6]刘仕翔.基于DM642 DSP的x264编码器研究及实现[D].西南交通大学,2010.17-18.
[7]王鹤,H.264视频编码算法在DM6446上的研究与实现[D].内蒙古大学,2011.40-41.
[8]Video Encoding Optimization on TMS320DM64x/C64x[S].Texas Instruments,2004.10
[9]TMS320C6000 Optimizing Compiler User’s Guide[S].Texas In struments,2002
[10]王宏志,苏令华,王晓红.基于达芬奇平台的视频编码器实现[J].计算机测量与控制,2011,19(05):1159-1160
[11]石迎波,吴成柯.基于H264的多参考帧运动估计快速算法[J].计算机工程,2008,34(10):218-220
[12]钱瑛.基于X264的运动估计算法研究[J].硅谷,2008,24
[13]TMS320C6000 DSP Enhanced Direct Memory Access(EDMA Controller Reference Guide(SPRU234A)[S].Texas Instrument.
[14]刘定佳.H.264视频编码算法研究及DSP实现[D].西安电子科技大学,2010.49-50.
猜你喜欢
铁道通信信号(2020年7期)2020-02-06 09:04:50
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
组合机床与自动化加工技术(2014年10期)2014-03-01 02:22:05
