
一种基于农业领域本体的语义检索模型
2012-12-27 06:54陈叶旺李海波余金山
华侨大学学报(自然科学版) 2012年1期
陈叶旺,李海波,余金山
(华侨大学 计算机科学与技术学院,福建 厦门 361021)
一种基于农业领域本体的语义检索模型
陈叶旺,李海波,余金山
(华侨大学 计算机科学与技术学院,福建 厦门 361021)
基于农业领域本体和词汇,给出一个针对农业领域的语义检索改进模型.该模型接受用户自然语言输入,通过计算词语与本体知识之间的相关度和相似度,来实现词汇到知识的映射.针对农业领域本体特点,给出相应的语义扩展规则,把检索结果从本体知识扩展到与之相关的资源文档,并对检索结果进行排序.
本体;语义扩展;语义检索模型;农业领域
语义检索是提供信息服务的重要组成部分,是当前的一个研究热点[1-9].然而,目前大部分的基于本体的语检索方法只是用本体来提供一些表达能力较浅的信息空间,或者只是在本体表达的知识中做是非判断,存在着很大的局限性.在过去的一段时期内,在语义检索这个方面上取得的成果,仅仅是在基于本体的知识系统中使用部分本体的表达能力[10],或是采用基于布尔检索模型[9].这使得被检索的对象要么符合条件,要么不符合条件.对于第1种模型而言,它使用部分本体的表达能力,而本体只是用来提供一些表达能力较浅的信息空间,本质上等同于词汇分类和词汇表.对于第2种模型而言,它存在一个很大的局限性,即很难把目前存在的海量非结构化知识完全用本体形式化地表示[8].在自然语言词汇到本体知识映射方面,这两种模型多是以字符串匹配方式简单而直接地完成映射,使得映射成功率相对较低.另外,这两个模型都没有提供一个有效的检索结果排序,使得最终用户很难区分结果好坏.对于用户来说,能否方便地实现检索语句的构造,准确地表达出自己的检索需求,关系到能否检索到相关的结果.采用自然语言问句的形式,是目前表达检索意图的最好形式.本文给出一个基于农业领域本体与词汇的改进检索模型,并进行相应的实验.
1 用户输入自然语言处理
系统的自然语言处理,包括用户查询预处理、问题分类、去除无意义字和词、中文分词等主要功能.
1)预处理.去除需求文本中不能被识别的成分,包括空白字符、空格、TAB和特殊字符.
2)问题分类.系统对每个领域知识的查询都定义了一系列查询关键词,根据这些关键词,可以从用户的输入中辨别出查询领域.
3)去除无意义字和词.属于经验处理,主要是去除平凡词,如“是”、“应该”、“可以”,以及“的”、“地”、“得”等.平凡词所在的语义表达的正确性和重要性较小,可以去除.平凡词列表是根据经验知识得到的,可以不断提炼修改.
4)中文分词.这一步主要基于两个词库,一个是中文基本词库,其词汇数量有119 850个;另一个是联合国粮食及农业组织(Food and Agriculture Organization,简称FAO)提供的中文农业词库,其词汇数量有37 060个.在分词过程中,FAO提供中文农业词库优先级比中文基本词库高,即先以FAO中文农业词库为准.
2 词汇-本体知识映射
在经过自然语言分词之后,得到的是词汇集合,须把这些词汇转化为本体知识库中对应的知识点上,这就需要所谓的映射工作.映射结果通常有如下3种情况:1)所有关键词是领域本体知识库中的元素;2)部分关键词是领域本体知识库中的元素;3)没有关键词是领域本体知识库中的元素.
对于本体知识库中不存在的词汇,可以通过词汇的相似度计算,匹配相关的词汇形成映射关系.文中采用的映射方法,是从两个角度来考查自然词汇-本体知识之间映射的关系,即一方面从词汇-标注文档-本体知识相关程度来看词汇-本体知识的联系紧密程度;另一方面基于知识关系词典考查词汇-本体知识两者之间的相似程度.
2.1 基于词汇-标注文档-本体知识的相关关系
在词汇-标注文档-本体知识的相关关系中,一个词汇可能被包含在多个文档中,而每个文档又可被一个或多个本体知识标注.通过统计包含词汇的文档所属的本体知识,可以统计出这个词汇对不同本体知识的相关程度.这种相关程度说明了词语-本体知识间的联系紧密程度.为计算这种相关关系,通过以下几个假设来说明一个自然语言词汇对一个本体知识的相关关系.
假设1 一个词汇w通过文档映射到的本体知识个数越多,它对单个本体知识的相关度越低.
假设2 一个词汇w在一个受本体知识e标注过的文档中的词频越高,w与e的相关程度越高.
假设3 若一个词汇w与文档d相关,则标注文档d的本体知识e与文档d的相关度越高,w与e之间的相关程度也就越高.
假设4 一个词汇w在越多的受本体知识e标注过的文档中存在,w与e之间的相关程度越高.
假设5 出现过词汇w的文档与受本体知识e标注过的文档交集越大,w与e的相关程度越高.
假设1从词汇在知识空间的分布情况来分析,一个词语与越多的知识关联,它对概念的区分性就越不明显,与单个知识的相关程度也就越低.假设2在与某个本体知识相关的文档空间中,对词汇进行词频统计.这样统计粒度细,区分性强,则可以更准确地刻画这个词对概念的所属程度.假设5与假设2的细粒度角度不同,假设3与假设4考虑的角度是粗粒度的相关文档数目.这样从粗细不同的角度能更全面地考查词汇与本体知识之间的相关度.据以上假设给出词汇w和本体知识e的相关程度计算方法.
设DS={d1,d2,…,dm}表示一个文档库;≻ed表示知识e标注了文档d,NPRO(e,d)表示知识e标注文档d的相关度,则有

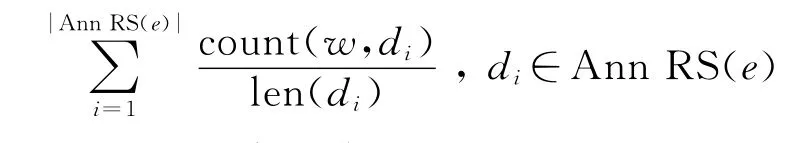
算法1的词汇-文档-本体知识相关度计算伪代码,如表1所示.
2.2 基于知识关系词典的词汇-本体知识相似度
在语义信息缺乏的情况下,知识词典只能实现词汇到本体知识的多对一映射,从而解决自然语言中的多词同义现象.例如,将电脑和计算机都映射到本体概念“computer”上,再比如“叶子”和“叶片”都映射到本体知识的“leaf”上.然而,自然语义的一词多义问题就比较难解决了,如苹果一词可以同时表示苹果计算机和一种植物.概念映射的另一个困难是概念词典常常无法覆盖所有的用户词汇,用户可能会使用生僻的词汇来表示心目中的概念,由此可能产生无法被概念词典识别的“孤儿词汇”.
因此,基于知识关系词典的映射应该取决于如下两点:1)字符串匹配,若词汇与领域本体中的某个实体的标签及扩展表示字符串相似,则将这个本体实体作为候选映射元素;2)自然语言上下文与本体语义上下文之间的关系.如果候选映射元素集合之间存在着领域本体中所定义的语义关系,那么可以认为映射成功可信度高;而如果它们之间相互孤立,则认为成功可信度低.
定义1 知识关系词典.一个本体实体e的知识关系词典Le是由一个词汇集合Te和一个语义环境Contexte组成,即Le=Te∪Contexte.一个词汇t出现Contexte中,则记为t∠Contexte.
定义2 词汇-知识相似度.词汇-知识相似度函数SIM∶w→e,计算词汇集合Γ中一个词汇w∈Γ与本体实体e相似度,有

其中:MAXSTRSIM(w,e)=Max(SrtSim(w,w′1),SrtSim(w,w′2),…,SrtSim(w,w′|Te|));w′,…,w′|Te|∈Te;λ=|Φ|/|Γ|,而Φ={w′|w′∠Contexte,w′≠w}.
依据以上工作,得出算法2的词汇-本体知识相似度计算伪代码,如表1所示.

表1 算法的词汇-文档-本体知识相关度计算伪代码Tab.1 Pseudocode of algorithm of calculating word-document-ontoloy relation
2.3 词汇-本体知识映射相关度
词汇-标注文档-本体知识相关关系体现的是词汇与本体知识之间的联系紧密程度,而基于知识关系词典的词汇-本体知识相似度体现的是两者之间的相似程度.二者分别从不同的角度考查两者之间的关系.在这里,可以认为两者对词语-本体知识映射相关度具有相同的影响力,两种因素相互作用的结果更能有效说明词汇映射相关度的强弱.因此,采用两种因素直接相乘的方式来定义词语-本体知识映射相关度,即
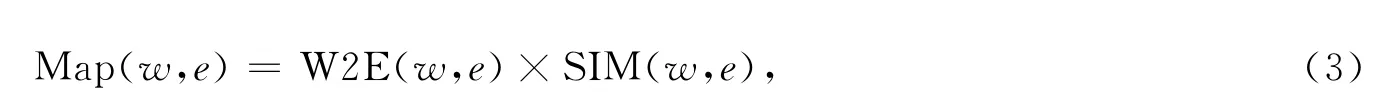
3 基于领域本体的语义扩展
根据疑问对象和疑问焦点在本体知识库中映射的距离,可分为直接关系检索和间接关系检索.在检索处理中,两种关系检索方式的难度和实现策略不同.直接检索的实现较为简单,可通过相似度计算将疑问对象和疑问焦点映射为三元组的主体和谓词结构进而生成检索表达式.有时直接检索结果不能满足用户需求,就需要根据领域本体中知识关系进行语义扩展,然后提交给检索表达式生成模块,组成SPARQL表达式进行检索,即扩展检索.文中的工作是把两者合并在一块,通过相关度体现出不同.
本体实体分为类、属性、实例3种,其扩展方式和扩展假设有所不同.
1)类(概念)扩展.对一个概念实体e,可以从知识库中选取与之相关的概念作为e的扩展,如上下位概念、等同概念(包括owl:sameAs和owl:equivalentTo)、参照概念(owl:seeAlso)等.
2)属性扩展.与类的扩展类似,对一个属性实体e,可以从知识库中选取与之相关的属性作为e的扩展,如上下位属性、等同属性(包括owl:sameAs和owl:equivalentTo)、参照属性(owl:seeAlso)等.
3)实例扩展.除了可以通过等同关系、参照关系实现扩展外,还可以通过一些特殊属性关系推导出与其有等同关系的实体.
在农业领域本体中常用到这些特殊属性,主要有FunctionalObjectProperty,SymmetricObject-Property和Transtivity Property.
1)FunctionalObjectProperty(功能性属性):对于一个owl:FunctionalObjectProperty P而言,如果P(X,Y)与P(X,Z)都成立,Y=Z.那么,根据这种逻辑关系,可以把使用owl:FunctionalObjecproperty关系可以推导出与实体e等同的其他实体作为e的扩展集.
2)SymmetricObjectProperty(对称性属性):与FunctionalObjectProperty类似,可以把使用owl:SymmetricObjectProperty关系可以推导出与实体e等同的其他实体作为e的扩展集.
3)Transtivity Property(传播性属性):对于一个owl:TranstivityProperty ObjectProperty P而言,如果P(X,Y)与P(Y,Z)都成立,则P(Y,Z)成立.根据这种逻辑关系,可以把使用owl:TranstivityProperty关系可以推导出与实体e相关的其他实体作为e的扩展集.
4 生成SPARQL形式化查询语句
SPARQL现在已成为W3C的推荐标准,文中方法的查询最终都转化成SPARQL.因为用户的提问方式多种多样,不同的问题也会有不同的检索策略.问句中的关键词可能是本体中类、属性、实例中任何一种.问句(关键词)提交后,将启动问句解析模块分析问句,过滤无意义词汇,分解成词汇集合,进行词汇-本体知识映射,确定知识关系;然后,根据问句的疑问词及句法和语法特征对问题进行分类,确定问题检索策略和答案的组织方式.最后,系统访问领域本体库,判定哪些关键词是本体库中包含的类、属性、个体,进而对用户提问概念进行规范化.
标准的中文问句结构有一定的规则,而本体中三元组〈Subject,Predicate,Object〉的形式化表示正好符合问句的表达顺序.这就为问句成分映射成本体知识库的词汇提供了条件.在SPARQL的检索表达式中,三元组处在后方顺次排列,其中的未知变量就是问题所在的位置.
疑问对象是问题的主体,一般问句的提问针对的是主体的某个属性.尽管用户提问的方式多种多样,但归纳起来主要有两种排列句型:一种是疑问对象位于句子的前部,疑问焦点排列在疑问对象的后面,句子的尾部是疑问词,问题的答案就是疑问词所指代的信息,如白斑病怎么治;另外一种问句的提问方式与此相反,疑问词位于句子的前部充当疑问对象,疑问焦点位于疑问词的后方,句子的尾部为疑问对象的相关信息,如什么药能治白斑病.虽然两种句型的排列顺序不同,但其疑问的意向是相同的,句中的疑问成分也一致,经过问句解析后形成的结果,如表2所示.

表2 解析示例Tab.2 Examples
在进行三元组元素的映射时,疑问对象放置在三元组主体的位置,中间的谓词由疑问焦点充当,客体的位置是未知变量,也就是问题的所在之处.当用户从接口输入检索关键词时,可以直接将输入的关键词与本体中的词汇进行相似度计算.
如果依据用户输入的内容找不到结果,则按前述的方式进行语义扩展,对每一个实体扩展的集合取笛卡尔乘积,即M1×M2×…×Mn.其中Mi为第i个实体的扩展集合.对乘积结果中的每组元素,重新按上述方法创建查询语句,并根据扩展实体与原实体的相似度计算新生成的查询语句与原始查询语句相似度.
5 扩展查询结果
如前所述,过去的一段时期内语义检索方法的检索结果缺乏合适的排序,不存在那种可以用百分比来表示检索结果可信度的答案.文中的检索模型与布尔语义检索系统不同之处在于,返回排序的结果不仅仅是知识库中用本体所描述的相关知识,还有与知识相关信息资源,排序过程以每条结果项的综合相关度为基准.每个结果项的综合相关度包含两部分,即

式(4)中:resultind,d表示结果项,包含知识ind与文档d;SIMSPARQLind为生成的SPARQL的查询语句与原始查询的相似度,该查询语句的执行结果中包含实例ind;NPROR(ind,d)为文档d与实例ind之间的相关度;W 为权重.
6 实测评价
根据前面的工作,实现一个现向农业领域的语义检索系统.开发工具是MyEclipse 6.0,本体知识用OWL表达,资源标结果存储于MySQL数据库中.目前,在语义搜索领域还没有一个公认的测设数据集和评价方法,而文中的工作也只是针对特定的农业领域.因而,测试时使用的数据都是自己建立的农业相关领域本体知识及农业相关的资源,而这些资源都经过语义标注工具或手工方式标注过.
本体知识使用的农业病虫害本体,#Concept和#Individual的数量分别为274,3 730;而资源是相对应的农作物病虫害知识文档,其数量为1 119.使用Precision@(n,k)和Recall@(n,t)作为主要的评价方法和指标,其计算式为

其中:Precision@(n,k)表示前n个结果中相似度大于k的查准率,Recall@(n,t)表示前n个结果中相似度大于k的查全率;α为语义检索的前n个结果中相似度大于k的集合;β为人工判断的检索结果中前n个结果.
表3为查询实验数据.由表3可以看出,检索方法取得了一定的效果,当查询语句比较简单且能按查询示例结构输入时,查询结果比较准确.

表3 查询实验数据Tab.3 Query data
7 结论
目前,大部分的基于本体的语检索方法很难把存在的海量非结构化知识完全用本体形式化地表示.同时,在自然语言词汇到本体知识映射方面,现有的方法多是以字符串匹配方式简单而直接地完成映射,使得映射成功率相对较低.此外,对于检索结果也都没有提供一个有效的排序,使得最终用户很难区分结果好坏.针对这些问题,文中给出一个基于农业领域本体和词汇的改进检索模型.
该模型接受用户自然语言输入,通过计算词语与本体知识之间的相关度和相似度,来实现词汇到知识的映射;针对农业领域本体特点,给出相应的语义扩展规则;把检索结果从本体知识扩展到与之相关的资源文档,并对检索结果进行了排序.基于这个模型,实现一个针对农业领域的检索系统,并进行一些小规模的实验,取得了良好的效果.
[1]HEFLIN J,HENDLER J.Searching the web with SHOE[C]∥Proc of AAAI 2000Workshop on AI for Web Search.Austin:AAAI Press,2000:35-40.
[2]SHAH U,FININ T,JOSHI A,et al.Information retrievalon the semantic web[C]∥Proc of the 11th International Conference on Information and Knowledge Management.New York:ACM Press,2000:461-468.
[3]GUHA R,Mc COOL R,MILLER E.Semantic search[C]∥Proc of the 12th international conference on World Wide Web.New York:ACM Press,2003:700-709.
[4]PICARD J,SAVOY J.Enhancing retrieval with hyperlinks:A general model based on propositional argumentation systems[J].Journal of the American Society for Information Science and Technology,2003,54(4):347-355.
[5]LOSADA D E,BARREIRO A.A logical model for information retrieval based on propositional logic and belief revision[J].The Computer Journal,2001,44(5):410-424.
[6]POPOV B,KIRYAKOV A,OGNYANOFF D,et al.KIM:A semantic platform for information extaction and retrieval[J].Journal of Natural Language Engineering,2004,10(3/4):375-392.
[7]BERNERS-LEE T,HENDLER J,LASSILA O.The semantic web[J].Scientific American,2001,284(5):34-43.
[8]VALLET D,FERNÁNDEZ M,CASTELLS P.An ontology-based in-formation retrieval model[J].ESWC,2005,3532:455-470.
[9]DAVIES J,FENSEL D,BUSSLER C,et al.The semantic web:Research and applications[M].Berlin:Springer-Verlag,2004:473-487.
[10]CHRISTOPHIDES V,KARVOUNARAKIS G,PLEXOUSAKIS D,et al.Optimizing taxonomic semantic web queries using labeling schemes[J].Journal of Web Sematics,2004,1(2):207-228.
A Semantic Retrieval Model Based on Agricultural Field Ontology
CHEN Ye-wang,LI Hai-bo,YU Jin-shan
(College of Computer Science and Technology,Huaqiao University,Xiamen 361021,China)
A semantic retrieval model is proposed based on the ontology and vocabulary of agriculture domain.This model provides an interface for user to input natural language,then it maps identified keywords to ontology entities by calculating the correlation and similarity between them;furthermore,we give a set of rules for semantic extension based on the features of agricultural ontology;and we extend and order the result got from the ontology to the annotated documents.
ontology;semantic extension;semantic retrieval model;agricultural domain
陈志贤 英文审校:吴逢铁)
TP 391.3
A
1000-5013(2012)01-0027-06
2011-07-03
陈叶旺(1978-),男,讲师,主要从事语义检索与数据挖掘的研究.E-mail:ywchen@hqu.edu.cn.
福建省自然科学基金资助项目(A0810013);福建省农业科技重大项目(2010N5008);华侨大学高层次人才科研启动项目(09BS619)
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
制造业自动化(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
专利代理(2016年1期)2016-05-17
文学教育(2016年27期)2016-02-28
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
质量与标准化(2010年5期)2010-05-03
