
关系数据库中的范式定义问题研究
2012-12-27 06:01:02李志洁王存睿
大连民族大学学报 2012年5期
李志洁,王存睿
(大连民族学院计算机科学与工程学院,辽宁大连 116605)
关系数据库中的范式定义问题研究
李志洁,王存睿
(大连民族学院计算机科学与工程学院,辽宁大连 116605)
对关系数据库的规范化理论和四种范式做了简要介绍,并对范式定义和函数依赖关系进行了探讨。针对第二范式和码的定义中存在的不严密性以及重复问题,提出了解决方案,进一步界定范式概念中函数依赖关系的范围。
数据库;关系;函数依赖;范式
关系数据库的规范化理论[1]最初是由E.F.Codd在1971年提出的。规范化理论可以降低数据库中的冗余,消除异常,因此成为关系数据库设计的重点和难点。在设计数据库之前,需要对数据进行规范化处理以确保数据库遵从适当的范式。范式是指符合某一种级别的关系模式的集合。规范化理论要求关系数据库中的关系必须满足一定的要求,即满足不同的范式。按照属性间的不同依赖程度,范式可以分为第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、Boyce-Codd范式(BCNF),后来又有人提出了第四范式、第五范式[2-4]。本文针对规范化理论中范式的概念不严谨以及建立在集合论上的范式定义与关系主码的定义相矛盾等问题进行展开分析,并提出了修正的范式定义。
1 规范化理论相关概念
各种范式其实就是一些确定关系模式的规则,而且这些规则是按层次递进分等级的,每一级都是在下一级的基础上制定的更严格的规则,即满足最低要求的范式是第一范式(1NF),在第一范式的基础上进一步满足更多要求的是第二范式(2NF),以此类推。规范化理论涉及函数依赖以及码的概念,现将本文涉及的概念阐述如下。
1.1 函数依赖
设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或Y函数依赖于X,记作X→Y。简单的说就是:某个属性决定另一个属性时,称另一属性依赖于该属性。例如在设计学生登记表时,一个学生的学号能决定学生的姓名,也可称姓名依赖于学号。如果知道一个学生的学号,就一定能知道学生的姓名,这种情况就是姓名依赖于学号。函数依赖又分为非平凡依赖,平凡依赖。从性质上还可以分为部分依赖,完全依赖两种。

1.2 码

1.3 范式
关系数据库中的关系必须满足不同的范式。目前关系数据库有以下几种常用的范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、鲍依斯-科得范式(BCNF)等等。
(1)第一范式(1NF)。二维表中的每一个分量必须是不可分的数据项,满足了这个条件的关系模式就属于第一范式。意指数据库表中的字段都是单一属性的,不可再分。第一范式是关系模式应具备的最起码的条件。很显然,如果数据库设计不能满足第一范式,就不能称为关系型数据库。
(2)第二范式(2NF)。若关系属于第一范式,并且每一个非主属性都完全函数依赖于码,则关系属于第二范式。第二范式是在第一范式的基础上增加了一个约束条件:关系模式中每一个非主属性都必须完全函数依赖于主属性。意思是,每个非主属性是由整个主键函数决定的,而不能由主键的一部分来决定。也就是说,数据库表中不存在非关键字段对任一候选关键字段的局部函数依赖。局部函数依赖是指存在组合关键字中的某些字段决定非关键字段的情况。所以二范式要求所有非关键字段都完全依赖于任意一组候选关键字。对于所有单关键字的数据库表,因为不可能存在组合关键字,所以都符合第二范式。
2 范式定义中存在的问题
在码的概念中,关系中的码能够完全函数确定其他属性,才能称之为码。根据这个定义,可得到如下两个推论:
(1)码中不能包含“无用”的属性,即码中的主属性必须都是决定因素。例如:在学生成绩表中,如果(学号,课程号)是关系的码,那么(学号,课程号,姓名)就不是码,因为姓名不是决定因素。
(2)关系中的属性必须完全函数依赖于码,即码不能部分函数确定其他属性。例如:在学生成绩表中,如果(学号,课程号)是码,那么学号可以确定姓名,姓名函数依赖于学号,即姓名部分函数依赖于码,因此(学号,课程号)不是码,不符合码的定义。
如果关系中的属性组不满足上述两个条件,那么就不能称为码。接下来的问题是,一个关系是否一定具有码呢?这要追溯到概念模型的内容,概念模型中阐述了信息世界的若干个基本概念,包括实体和码。实体是客观存在并可相互区分的事物,并具有若干属性。码是唯一标识实体的属性集。从实体和码的定义可以推导出实体一定具有码,才能够和其他实体相区分。同样,将概念模型转化为关系模型后,一个关系表通常对应现实世界的一个实体集。例如学生关系对应学生的集合。由于现实世界中的实体是可区分的,相应地,关系中的每个元组也是可以相互区分的,即关系具有唯一性标识——码。至此,我们已经得到一个重要的结论,即
“一个关系一定具有码,且关系的码必须完全函数确定其他属性,或者关系的属性必须完全函数依赖于码。”
然而,这个结论却与第二范式的定义相重复。从第二范式的判定概念里,我们可以看到,如果关系属于第二范式,那么关系中的每一个非主属性都完全函数依赖于码。根据前面的分析可知,码的定义本身就要求:关系的非主属性必须完全函数依赖于码。因此,在假设码的定义为正确的前提下,只要一张表是关系表,那么就一定具有码,且关系中的属性一定完全函数依赖于码。隐含的意思为:关系表只要具有码就一定满足第二范式。作者认为关于第二范式的概念和码的概念之间的关系不是非常严谨,于是提出了两种解决方案如下:
(1)修正第二范式的定义。新的第二范式(2NF):若二维表属于第一范式,并且具有码,则一定属于第二范式。但是新第二范式的概念打乱了原有范式体系的定义方式,不利于概念的连续性。为此,作者提出了另一种设想,即修正码的定义,同时保持原有第二范式定义不变。即下面的第二个方案。
(2)修正码的定义。新的码定义为:设K是关系模式R<U,F>中的属性或属性组,若K→U,则称K为R的候选码。若候选码多于一个,则选其中的一个为主码。这个定义和原有定义的区别在于,属性组K是函数确定U,这个函数确定可以是完全函数确定,也可以是部分函数确定。与之相对,原有定义要求属性组K必须完全函数确定U。这个新码的定义与第二范式的概念就不存在重复现象了。
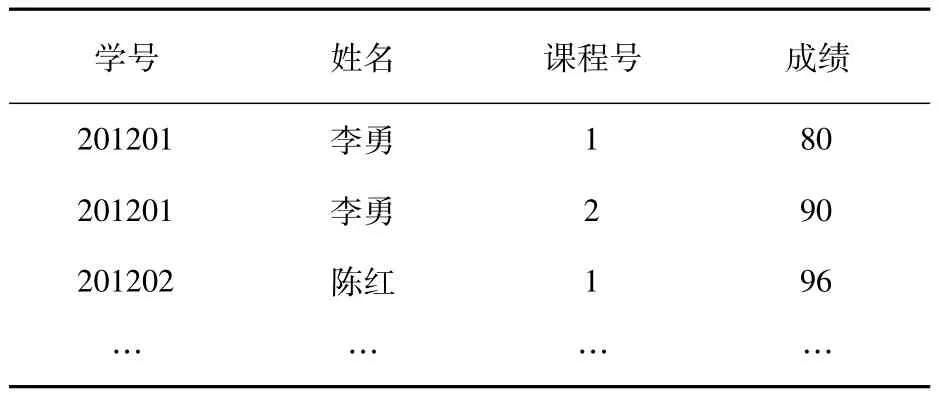
表1 学生成绩表
提出第二个解决方案主要是基于这样的考虑,原有码的定义在实际应用中并不符合人们的思维习惯。例如,在表1中,存在如下的函数依赖关系{学号→姓名,(学号,课程号)→成绩},所以学号和(学号,课程)都是决定因素。但是(学号,课程号)是否为码呢?根据码的定义,关系中的属性必须完全函数依赖于码。如果(学号,课程号)为码,那么成绩和姓名都应该完全函数依赖于码。事实上,姓名仅仅函数依赖于学号,这就产生了姓名对(学号,课程号)的部分函数依赖。因此,根据码的定义(参见1.2节),(学号,课程号)不能称之为码。但是实际上,我们知道(学号,课程号)能够唯一确定一个元组,具有码的功能。这就导致了属性组(学号,课程号)的称谓和功能之间“名不副实”的现象。当然,如果去掉了第二个属性姓名,则学生成绩表就具有码(学号,课程),因为成绩属性完全函数依赖于码,同时,这个关系即属于第一范式,也属于第二范式。
3 结语
范式是改善关系模式的一种方法,是衡量数据库中关系模式设计是否合理的标准之一。满足高级别范式的数据库结构清晰,可以避免插入、删除和修改操作的异常,大幅降低数据库的冗余度,提高数据库的通用性和安全性。当然,数据库的逻辑设计并不仅仅只依赖于范式,在实际应用中,有很多灵活运用四大范式而不拘泥于四大范式的例子。在一定制约条件下,数据库的设计若能符合第二范式,就已经达到数据库设计的要求了。因此,本文着重讨论了低一级的范式(第二范式)的概念和定义问题。关系数据库的理论是建立在集合论的基础之上的,集合中一个重要的概念就是函数依赖,关于各种范式的要求也是针对函数依赖所展开的。在详细分析了函数依赖理论之后,根据主码的定义推论导出了第二范式的定义与主码定义的相左之处。鉴于定义并无本质错误,只是在概念范围上界定不清,本文仅仅提出了修正的第二范式定义以及修正的码的定义,以帮助读者在规范化过程中快速理清各种关系属性及函数依赖关系。
[1]CODD E F.A Relational Model of Data for Large Shared Data Banks[J].Communications of the ACM,1970,13(6):377-387.
[2]CARLO Z.A New Normal Form for the Design of Relational Database Schemata[J].ACM Transactions on Database Systems,1982,7(3):489-499.
[3]RONALD F.A Normal Form for Relational Databases That Is Based on Domains and Keys[J].Communications of the ACM,1981,6(3):387-415.
[4]WIJSER J.Temporal FDs on complex objects[J].ACM Transactions on Database Systems,1999,24(1):127 -176.
Research on Normal Form of Relational Database
LI Zhi-jie,WANG Cun-rui
(School of Computer Science& Engineering,Dalian Nationalities University,Dalian Liaoning 116605,China)
This paper makes a brief introduction to normalization theory and four kinds of Normal forms.Also the definitions of Normal forms and functional dependency are discussed.For the problem of imprecision in the second Normal form definition,a revised definition of second Normal form is proposed.Thus,the scope of functional dependency in the Normal form concept is further defined.
database;relation;functional dependency;normal form
TP 393
A
1009-315X(2012)05-0492-03
2012-03-17;最后
2012-07-19
大连民族学院人才启动基金项目(20086205)。
李志洁(1978-),女,黑龙江鸡西人,副教授,主要从事人工智能研究。
(责任编辑 刘敏)
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:51:30
甘肃教育(2021年10期)2021-11-02 06:14:08
福建江夏学院学报(2021年6期)2021-08-10 08:22:08
艺术品鉴(2020年11期)2020-12-28 01:36:56
大连民族大学学报(2020年2期)2020-06-16 03:12:56
英美文学研究论丛(2018年1期)2018-08-16 03:01:00
下一代英才(酷炫少年)(2018年4期)2018-04-28 08:29:31
河北大学学报(自然科学版)(2015年1期)2015-02-27 13:06:13
海外英语(2013年1期)2013-08-27 09:36:04
江西理工大学学报(2013年1期)2013-03-20 14:57:13
