
Word/Excel 辅助快速提取方正书版.fbd文件中文摘数据的方法研究
2012-11-21 02:54黄鹂
长江大学学报(自科版) 2012年34期
黄 鹂
(长江大学期刊社,湖北 荆州 434023)
Word/Excel 辅助快速提取方正书版.fbd文件中文摘数据的方法研究
黄 鹂
(长江大学期刊社,湖北 荆州 434023)
针对《中国石油文摘》稿件提交系统需要逐条输入分类号、篇名、作者、作者单位、摘要、关键词、起止页码等信息,操作起来比较机械、烦琐的问题,提出了一种利用Word中的宏和Excel中的宏、自动筛选、分列、自动计算等功能来快速提取上述信息的方法。以《石油天然气学报(江汉石油学院学报)》数据为例,通过宏按钮可以直接提取出“分类号、摘要、关键词”,其他数据通过分列、自动计算再经过一定的加工均可快速提取出来。这种方法使文摘数据的提取效率大大提高。
文摘;数据提取;Word;Excel
石油类期刊很多都向《中国石油文摘》提供文摘数据,采用《中国石油文摘》稿件提交系统(以下简称“提交系统”)需要逐个从正文中将篇名、作者、作者单位、摘要、关键词、中图分类号等复制并粘贴到提交系统中。操作虽然简单,但比较机械、烦琐。为了改变这种方式,笔者提出利用Word中的宏[1]和Excel中的宏、自动筛选、分列、自动计算等功能[2]来快速提取期刊论文中的这些数据项。下面以《石油天然气学报(江汉石油学院学报)》为例,说明如何提取方正书版系统的.fbd文件中的文摘数据。
1 数据提取过程
1.1目次页文件中的数据——Word宏
在Word中打开欲提取文摘数据的《石油天然气学报》目次页文件(文件名为:石油天然气学报目次.fbd)(见图1),选择“工具-宏-录制新宏”,在打开的“录制宏”的对话框中输入宏的名称,如输入“目次页分列”,将其指定到工具栏上并保存在所有文档中,关闭对话框(见图2)。以下的操作将被记录在这个宏中:选择“编辑-替换”,打开“查找和替换”对话框,选择目次页文件中的方正排版命令“汉体五号楷体居右排”将其换为“|”(见图3);按同样的方法,将“(”换成“|”,将“汉体五号书宋”删除,然后全选数据,点击“表格-转换-文本转换成表格”,在打开的对话框中选择“其他字符”,在其后的输入框中输入 “|”(见图4), 按提示要求完成后,停止录制宏。此时目次页文件已被转换为一个具有篇名、作者及页码这3列的一个表格了(见图5)。

图1 目次页节选

图2 Word中录制宏对话框 图3 查换和替换对话框 图4 文本转换成表格对话框
1.2正文文件中的数据——Excel宏

图5 文本转换结果
在Word中打开欲提取文摘数据的《石油天然气学报》正文文件(文件名为:石油天然气学报正文.fbd),全部选中后复制、粘贴到新建的Excel工作簿中的Sheet1中,先录制一个提取数据的宏,以后只需执行这个宏,就可以完成数据提取。Excel中宏的录制过程如下:“工具-宏-录制新宏”,在对话框中给新宏取名为“筛选文摘数据”,将其保存在“新工作簿”中,关闭对话框(见图6),接下来的按键操作和快捷键操作的过程都将被记录下来:
1)选择“数据-筛选-自动筛选”,此时在单元格(如A1单元格)右下角出现一个向下的三角形筛选按钮,点击该按钮,选择“自定义…”,打开“自定义自动筛选方式”对话框,点击左框的下拉箭头,选择“始于”,在右框中输入“[摘要]”,按“确定”后(见图7),即把始于“[摘要]”的数据筛选出来,选中该数据列,用快捷键Ctrl+C,将选中数据列复制到剪贴板中,再点击“Sheet2”工作表标签,光标定位在A1单元格,按“Ctrl+V”,将筛选出的“[摘要]”粘贴到A列。

图6 Excel中的录制新宏 图7 定义自动筛选对话框

图8 筛选结果
2)点击“Sheet1”,点击筛选按钮,选择“全部”之后,全部数据显示出来,此时再点击筛选按钮,选择“自定义”,打开“自定义自动筛选方式”对话框,点击左框的下拉箭头,选择“始于”,在右边的输入框中输入“[关键词]”,按“确定”后,把始于“[关键词]”的数据筛选出来,选中该数据列,用快捷键Ctrl+C,将选中数据列复制到剪贴板中,再点击“Sheet2”工作表标签,光标定位在B1单元格,按“Ctrl+V”,将筛选出的“[关键词]”粘贴到B列。
3)重复步骤2),此时可将筛选内容换为“[中图分类号]”“汉体小五号细圆”,就会分别将“中图分类号”和“作者单位”筛选出来,将其分别粘贴到Sheet2中C列和D列(见图8)。此时停止宏的录制,“筛选文摘数据”的宏就录制完成了。下次进行文摘数据提取时,只需执行“筛选文摘数据”这个宏即可。
1.3提取数据的加工
提取出来的数据还带有许多不需要的内容,仍然可以通过录制宏的方式将这些词删除。图8中D列数据为“作者单位”,其中还有单位所在城市及邮编,这2项内容是文摘数据库中不需要的信息,需要删除。因为《石油天然气学报》作者单位与城市名称和邮编是用“逗号”分开的,可以利用这一点,选择Excel中的“数据-分列”,根据对话框的提示,选择分隔符为“逗号”,按提示信息即可将作者单位与城市、邮编分为2列,此时直接选取作者单位数据即可。
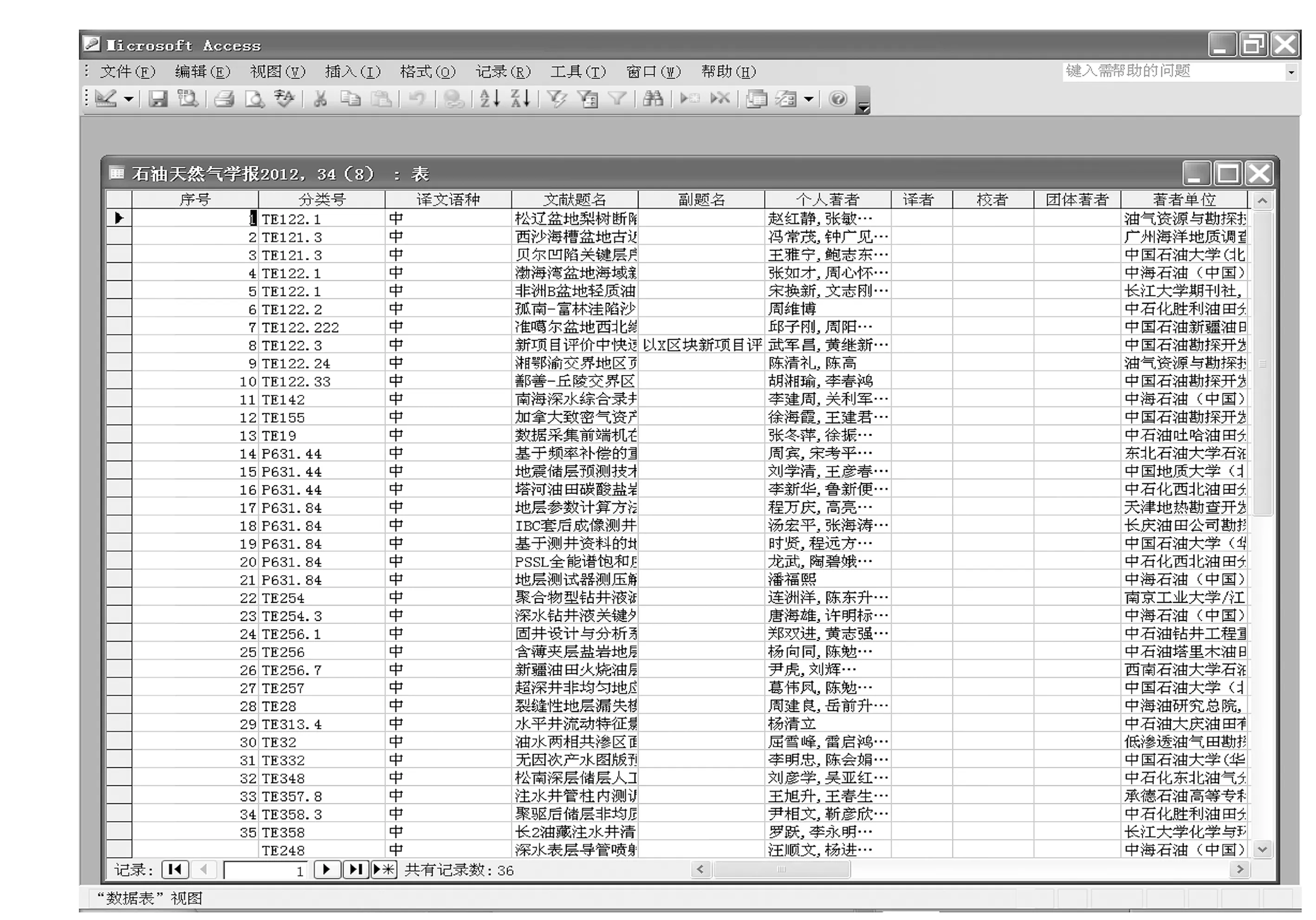
图9 加工完成的文摘数据
“文章起始页码”可手工输入,之后的“止页码”是下一篇文章的“‘起始页码’-1”,可通过Excel中的公式快速生成。
2 数据提交
按照《中国石油文摘》提交系统的要求,将前文经过加工的提取数据逐一复制、粘贴到包含所有字段的Excel文件中相应的字段下,对其中的“图、表、参”的具体数据,需要逐个录入,之后的“图、表、参”可以利用Excel中的字符连接运算自动生成。加工好以后,将Excel文件导入Access数据库中(见图9),将数据库文件压缩后即可发送给《中国石油文摘》编辑部,完成数据的提交。
3 结 语
通过Word和Excel中的“目次页分列”“筛选文摘数据”这2个宏按钮,可轻松提取“篇名、作者、起始页码、摘要、关键词、中图分类号”,再配合使用Excel数据分行、自动计算等功能就可将“作者单位、起止页码”提取或计算出来。这种方法将机械、枯燥的数据提取过程变为了轻松、有趣的过程,同时还提高了数据提取的效率。
[1]人力资源和社会保障部人事考试中心.Word2003中文字处理[M].北京:中国人事出版社,中国劳动社会保障出版社,2010.
[2]人力资源和社会保障部人事考试中心.Excel2003中文电子表格[M].北京:中国人事出版社,中国劳动社会保障出版社,2010.
[编辑] 洪云飞
10.3969/j.issn.1673-1409(N).2012.12.032
TP391.13
A
1673-1409(2012)12-N099-03
猜你喜欢
环境影响评价(2020年2期)2020-12-02
网络安全和信息化(2020年1期)2020-01-15
中学科技(2018年12期)2018-12-19
中学科技(2018年10期)2018-12-18
课程教育研究·新教师教学(2016年1期)2017-04-10
宝藏(2017年2期)2017-03-20
电脑知识与技术(2016年5期)2016-04-14
祝您健康(1985年3期)1985-12-30
祝您健康(1985年1期)1985-12-29
