
一种改进的FSVM语音情感识别算法
2012-10-30 05:22:24邢玉娟李恒杰张成文
重庆科技学院学报(自然科学版) 2012年5期
邢玉娟 李恒杰 张成文
(甘肃联合大学,兰州 730000)
一种改进的FSVM语音情感识别算法
邢玉娟 李恒杰 张成文
(甘肃联合大学,兰州 730000)
针对语音特征参数对某类情感具有不确定性的问题,提出一种基于典型相关性分析的改进模糊支持向量机算法,应用于语音情感识别。采用典型相关性分析方法对特征向量进行降维,得到样本的约简向量集,在此约简向量集上建立模糊支持向量机模型判定情感类型。仿真实验结果表明,该方法相比于传统支持向量机法和模糊支持向量机法具有较高的识别准确率。
典型相关性分析;模糊支持向量机;语音情感识别;支持向量机
语音是人类的重要交流方式,在人类的语音信号中不仅包含了语义信息,同时也包含了人类丰富的情感信息(如喜悦、悲伤、愤怒、惊讶等)[1]。如何让智能计算机具有语音情感识别和表达能力,是当前智能化人机交互领域研究的热点,在自然人机交互、多媒体分段与检索、安全系统自动监管等方面有着广泛的应用前景。
传统的支持向量机法,以其出色的分类性能在语音情感识别领域获得了成功的应用。然而,SVM是基于二元分类的,当将其应用于语音情感识别中时,需要构造多元分类器,常用一对多组合分类和一对一组合分类的方法。然而在构造多元分类器的过程中,存在一些不可分区域。为了解决这个问题,文献 [2]中提出了模糊支持向量机的方法(Fuzzy Support Vector Machine,FSVM),通过对每一类样本设置隶属度解决不可分数据,实验结果表明FSVM的分类性能优于SVM。而文献[3]中指出FSVM在大规模训练样本情况下,并不能很好的解决受限优化问题。在语音情感识别中,语音特征参数主要包括语音的基音频率、短时能量、共振峰、MFCC参数以及它们的派生参数,这些语音参数的维数很高,并且包含大量的对情感识别没有贡献的噪音信息,采用这样的高维特征向量训练FSVM,势必会导致FSVM训练速度慢。因此本文提出一种基于典型相关性分析(canonical correlation analysis,CCA)的改进的FSVM算法。通过CCA对样本进行降维,减小样本的规模,进而降低后续阶段的计算复杂度,有助于FSVM模型的建立。
1 典型相关性分析
典型相关性分析的核心思想是通过研究两组随机向量之间相关关系,根据判别准则寻找向量的典型投影方向,使得在该投影方向上两组向量间的相关性最大[4]。
假设x∈Rp和y∈Rq是两组语音特征向量,根据CCA的思想,寻找投影方向a1和b1,使得x和y在这两个投影方向上的投影μ1=aT1x和ν1=bT1y具有最大的相关度,称μ1,ν1是第一对典型相关特征。紧接着再依次计算第二对投影方向a2和b2,求得第二对典型相关特征μ2和ν2,以此类推直到求得第s对投影方向和典型相关特征。通过最大化典型相关特征μ和ν之间的相关系数 ρ(μ,ν),来求解投影方向 a 和 b。
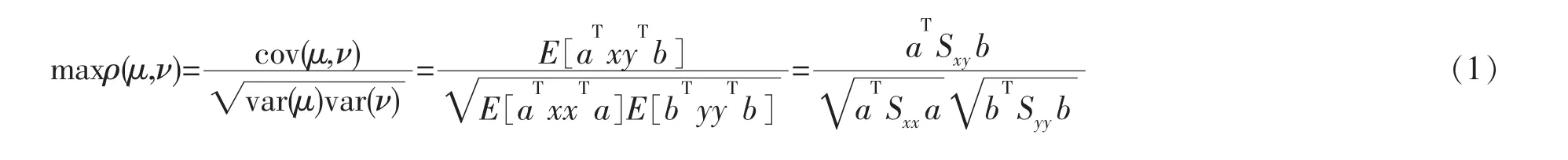
这样,通过对x和y之间的相关分析,得到少数几对典型相关特征向量作为有效的判别信息,达到降维和消除特征之间信息冗余的目的。
2 基于CCA和FSVM的语音识别
本文提出的语音情感识别系统框图如图1所示,输入语音经过预处理过程(端点检测、预加重、分帧加窗等)得到情感特征向量,采用CCA对情感特征向量降维,在得到的约简向量集上建立FSVM分类模型,最终得到识别结果。
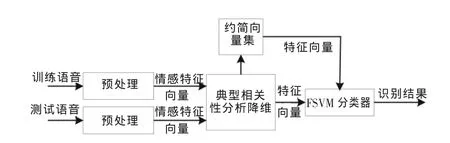
图1 基于CCA的改进FSVM语音情感识别系统框图
模糊支持向量机和常规支持向量机的区别是,训练样本中除了样本的特征与类属性表示之外,FSVM 的每个训练样本增加了隶属度 μ (xi)∈(0,1][5]。设训练样本集为(yi,xi,μ(xi)),(i=1,2,…,n)。其中 xi∈RN表示样本特征,yi∈{-1,1}表示类标识。假设映射f=φ(x)将训练样本从原始空间RN映射到高维空间H。
由于隶属度μ(xi)表示该样本属于某类的可靠程度,ρ是支持向量机目标函数中的分类误差项,则μ(xi)ρ为带权的误差项,FSVM的最优分类面为下面目标函数的最优解。
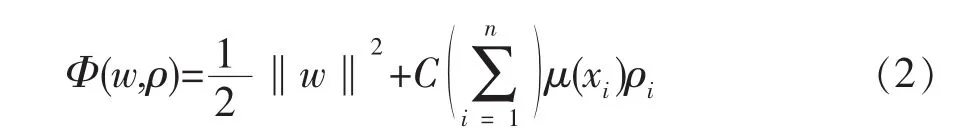
约束条件为:yi[(wT·f)+b]-1+ρi≥0, i=1,2,…,n

其中,惩罚因子C为常数,w表示线性分类函数yi的权系数。由式(2)可知,当 μ(xi)很小时,减小了 ρi的影响,以至于将相应的xi看作不重要的样本。相应地最优分类面的判别函数为:

其中 0≤αi≤μ(xi)C,i=1,…,n,K(xi,x)为核函数。
输入向量x和最优分类超平面fij(x)的距离可定义为。这样当fij(x)≥1或者fij(x)≤-1时,x完全属于类别 i或类别 j;当-1<fij(x)<1 时 fij(x)可以认为是类别i或类别j的隶属度。因此μ(xi)的计算公式如下:
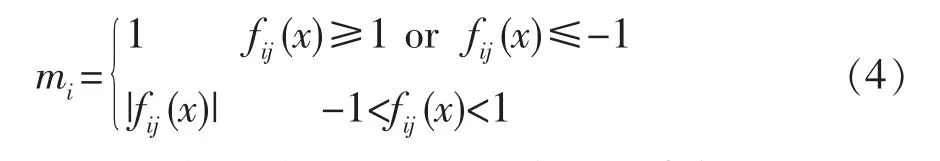
由于语音情感识别是一个多元分类问题,本文采用一对一的FSVM分类器。因此,对于一个n类问题,需要构造 n(n-1)/2 个二元 FSVM[6]。
具体的FSVM分类器算法如下:
Step1:对于输入向量 x,如果 fi(x)>0满足某一类,则将x划分到该类。否则转到Step2;
Step2:如果fi(x)>0满足不止一个类别i(i=i1,…,il,l>1),将其划分到 fi(x)(i∈{il,…,il})取最大值的那一类,否则转到Step3;
Step3:如果fi(x)≤0满足所有的类,则将数据划分到fi(x)的绝对值取最小的那个类。
3 仿真实验结果与分析
3.1 实验环境及语音情感数据库
仿真实验平台为PC2.6G/1G,Windows XP2003操作系统/Matlab7.0,结合语音工具箱Voicebox以及SVM Toolbox 1.0验证语音情感识别的性能。采用自己录制的语音数据,录音软件采用Cool Edit pro 2.0,录音时采用单声道、11.025kHz采样频率、16位采样精度。录制26位说话人(男性13名,女性13名)的6种情感状态语音:愤怒,喜悦,惊讶,悲伤,害怕,厌恶。每人每种情感录制10条语句,其中5句用于训练,剩余5句用于测试。利用Cool Edit中的降噪器工具,清除各种背景杂音。对语音库中每条语句进行端点检测、预加重,以帧长30ms、帧移15ms为语音信号加汉明窗,窗长N=200。提取基音频率、第一共振峰、短时能量、MFCC(Mel-frequency Cepstral Coefficients)4 类基本情感声学特征及其派生特征参数共40维作为语音情感特征向量。
3.2 实验结果分析
在该实验中,我们将本文提出的方法和传统的支持向量机法、模糊支持向量机法进行了比较分析,核函数采用分类性能较好的RBF核函数(σ=1.3)。实验结果如表1所示。
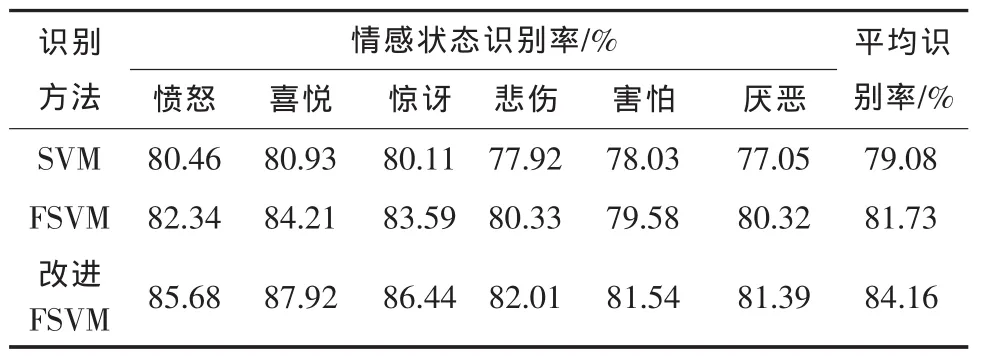
表1 情感识别率
由表1可知:
(1)在3种方法中,本文提出的方法的平均识别准确率是最高的,比SVM高出五个百分点,而比FSVM高出2.43%。在愤怒、喜悦和惊讶三种情感状态,改进FSVM的识别率相比于FSVM和SVM都有显著地提高,在愤怒状态比SVM提高了5.22%,比FSVM提高了3.34%;在喜悦状态比SVM提高了6.99%,比FSVM提高了3.71%;在惊讶状态比SVM提高了6.33%,比FSVM方法提高了2.85%。
(2)3种方法在悲伤、害怕和厌恶情感状态下的识别率都普遍不高,主要是由于这三种情感在发音时,许多生理特征相似,较易混淆。
图2给出了3种算法的情感识别率曲线图。
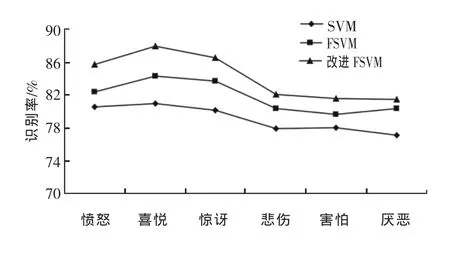
图2 3种算法情感识别率曲线图
4 结 语
为了克服传统FSVM在大规模训练样本情况下,不能很好的解决受限优化问题,导致训练速度慢的缺陷,本文提出一种基于CCA的改进FSVM算法,应用于语音情感识别。借助于CCA对输入样本进行降维约简,降低了FSVM的建模计算复杂度,同时FSVM在训练时引入了样本的模糊隶属度,从而可以很好地解决不可分数据问题。仿真实验结果表明本文提出的方法具有良好的识别性能。
[1]Moataz ElAyadi,Mohamed S,Kamel,et al.Surveyon Speech Emotion Recognition:Features,Classification Schemes,and Databases[J].Pattern Recognition,2011,44:572-587.
[2]Takuya Inoue,Shigeo Abe.Fuzzy Support Vector Machines for Pattern Classification[J].IJCNN'01,Volume 2,15-19 July 2001:1449-1454.
[3]Alistair Shilton,Daniel T H Lai.Iterative Fuzzy Support Vector Machine Classification[J]. Fuzzy Systems Conference,2007:1-6.
[4]徐晓娜,穆志纯.基于CCA的人耳和侧面人脸特征融合的身份识别[J].计算机应用研究,2007,24(11):312-314.
[5]Yongguo Liu,Gang Chen,Jiwen Lu,et al.Face Recognition Based on Independent Component Analysis and Fuzzy Support Vector Machine[J].Intelligent Control and Automation,WCICA2006,21-23:9889-9892.
[6]Tai-Yue Wang,Huei-Min Chiang.Fuzzy Support Vector Machine for Multi-class Text Categorization[J].Information Processing&Management,Volume 43,Issue 4,July 2007:914-929.
Speech Emotion Recognition Based on Improved Fuzzy Support Vector Machine
XING Yujuan LI Hengjie ZHANG Chengwen
(Gansu Lianhe University,Lanzhou 730000)
An improved fuzzy support vector machine algorithm is proposed in this paper in order to solve the non-determinacy of speech feature parameter.Firstly,canonical correlation analysis is utilized to reduce the dimension of feature vectors.And then,fuzzy support machine is trained on the reduced set to make final decision.The experiment results show that,our method has superior classification performance compared with SVM and FSVM.
canonical correlation analysis;fuzzy support vector machine;speech emotion recognition;support vector machine
TP391 文献标示码:A
1673-1980(2012)05-0140-03
2012-05-12
甘肃省教育厅基金项目(1113-01)
邢玉娟(1981-),女,甘肃天水人,硕士,讲师,研究方向为生物特征识别。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
数学物理学报(2021年1期)2021-03-29 03:14:42
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25 01:40:34
科技创新与应用(2020年6期)2020-02-29 10:39:27
学生天地·小学低年级版(2019年5期)2019-06-05 01:15:11
学生天地(2019年15期)2019-05-05 06:28:28
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
北京理工大学学报(2016年6期)2016-11-22 11:17:22
