
基于SVM的以词性和依存关系为特征的句子倾向性判断分析
2012-10-23 10:00吴明芬陈涛
五邑大学学报(自然科学版) 2012年4期
吴明芬 ,陈涛
(1. 中国科学院 计算技术研究所,北京 100190;2. 五邑大学 计算机学院,广东 江门 529020)
基于SVM的以词性和依存关系为特征的句子倾向性判断分析
吴明芬1,2,陈涛1,2
(1. 中国科学院 计算技术研究所,北京 100190;2. 五邑大学 计算机学院,广东 江门 529020)
将句法平面词的词性特征、依存关系、依存关系中的词性特征、邻接依存关系、邻接依存关系中的词性特征与倾向性词汇和倾向性搭配作为支持向量机(SVM)分类器的特征集,以句子为单位对多个领域的文本进行倾向性判断. 通过交叉验证的方式,估计出分类器的精度为95.6%,据此提出句子倾向性分析可不以句子倾向性判断为前提.
倾向性判断;依存关系;词性特征;支持向量机
支持向量机(Support Vector Machine,简称SVM)是一种得到广泛应用的有监督的二元分类方法,由Cortes和Vapnik于1995年首先提出[1],对解决小样本、非线性及高维模式识别具有独特的优势.
句子倾向性判断是将文本以句子为单位对其是否包含主观意见和情感进行判断,它可以作为按倾向性对文本分类系统的预处理模块,用来过滤无倾向性的文本;也可以与搜索引擎结合,用以搜索客户对某件商品的评论等倾向性文本.
基于SVM对文本进行句子倾向性判断,首先需要选取特征集. 目前特征集选取主要采用词级特征,有以下 2种方法:1)利用情感/倾向性词典、语料库等识别文本中具有明显倾向性的词(即评价词语)来判断文本倾向性[2-5]. 这种方法对分析显式的倾向性(即含有情感词的文本的倾向性)比较有效. 2)利用词语搭配来判断文本倾向性[6-9]. 这种方法具有一定的分析隐含倾向性和领域相关倾向性的能力. 本文将对语料库中文本的倾向性与句法平面词的词性特征(POS)、依存关系(DEP),依存关系中词的词性特征、邻接依存关系,邻接依存关系中词的词性特征进行分析和统计,并将统计结果结合倾向性词汇与倾向性搭配一起作为SVM分类器的特征集进行训练和测试.
1 准备知识
词性是指划分词类根据的词的特点,如名词(N)、动词(V)、形容词(ADJ)等. 依存关系的概念由依存语法衍生而来,法国语言学家Tesnière[10]提出“两个平面”理论,即用“结构平面”和“语义平面”来区分句法和语义. 鲁川[11]将句子剖析成跟显性、有序、省略、一维表层结构一致的“句法平面”,和跟隐性、无序、完整、多维里层结构一致的“语义平面”. 词性属于句法平面而依存关系属于语义平面. 周国光[12]将依存(配价)语法定义为一种结构语法,主要研究以谓词为中心、而构句时由深层语义结构映现为表层句法结构的状况及条件、谓词与体词之间的同现关系,并据此划分谓词的词类. 常见的依存关系有:句子核心动词(HED)、主谓关系(SBV)、动宾关系(VOB)、状中结构(ADV)、定中关系(ATT)等.
依存关系中词的词性特征、邻接依存关系以及邻接依存关系词的词性特征是将依存关系与词性结合在一起考虑. 邻接依存关系是指两个存在共用的词且跨度没有包含关系的依存关系. 特殊的核心结构不与任何依存关系包含. 如图1所示,存在4个邻接依存关系组合:HED_SBV,HED_VOB,SBV_VOB、ATT_ATT. 不包括VOB_ATT,因为动宾关系VOB(喜欢、处理)的跨度包含了定中关系ATT(处理、语言).
邻接依存关系中词的词性特征是两个邻接依存关系句法平面对应的词的词性组合,如图1中的邻接依存关系HED_SDV,HED_VOB,SDV_VOB,ATT_ATT对应的邻接依存关系中词的词性特征分别为:h_v_r,h_v_v,r_v_v和n_n_v.
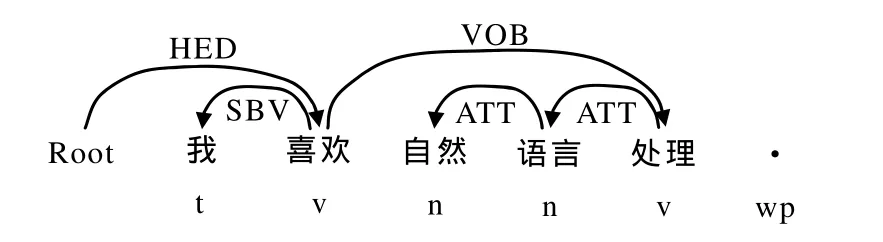
图1 依存关系可视化示例
2 实验过程
实验使用的语料库包括谭松波提供的中文情感挖掘语料—ChnSentiCorp[13]、搜狗分类语料库(精简版)[14]、哈尔滨工业大学 LTP源代码中提供的测试语料(test_gb.txt)[15]. SVM 工具采用Weka[16]平台提供的 LibSVM软件包[17],用哈工大 LTP[18]处理生成对应的 xml文件,使用 Python语言编写程序.
2.1 特征集选取
分别统计倾向性语料和普通语料中的词性特征(POS)、依存关系特征(DEP)、依存关系中的词性特征(2-POS)、邻接依存关系特征(2-DEP)、邻接依存关系中词性特征(3-POS),得出了以下结论. 由于篇幅所限,统计分析得到的统计图表见http://www.yourscom.com/v/.
1)词性中,名词、副词、地理名、拟声词、叹词、专有名词、缩写和机构名在有倾向性文本与普通文本中占有率差异明显. 其中名词、副词、拟声词在有倾向性文本中占有率明显高于普通文本,地理名、专有名词、缩写和机构名则明显低于普通文本.
2)依存关系中,状中结构、语态结构、定中关系、并列关系、前附加关系在有倾向性文本与普通文本中占有率差异明显. 其中状中结构、语态结构在有倾向性文本中占有率明显高于普通文本,定中关系、并列关系、前附加关系则明显低于普通文本.
3)2-POS中,副词动词序列、助词动词序列、名词形容词序列、形容词动词序列、副词形容词序列在有倾向性文本中比例较高,名词名词序列、地理名名词序列在有倾向性文本中比例较低.
4)2-DEP中,VOB_MT、SBV_MT、H_IC、ADV_CMP、SBV_IC、ADV_IC、IC_VOB、ADV_ADV、ADV_MT在倾向性文本中比例高于普通文本,ATT_ATT、ATT_DE、VOB_COO、QUN_ATT、ATT_COO、IC_IC在倾向性文本中比例低于普通文本.
5)3-POS中,d_v_v、d_v_u、v_v_u、v_v_a在倾向性文本中比例高于普通文本,p_v_n、v_n_n、h_v_a、h_v_p、p_v_v、n_v_n、n_n_n、n_n_v在倾向性文本中比例低于普通文本.
以上结论中及文中其他地方出现的关于依存关系和词性的缩写含义请参考文献[19].
倾向性词汇通过统计倾向性语料和普通文本语料中使用频率最高的 3 000个词汇并去除二者的交集再手工整理添加常用的形容词得到.
倾向性搭配严格地讲只是使用频率较高的两个词的组合,通过2种方法获得:1)二次遍历倾向性语料中所有句子,找出使用频率最高的10 000个两个词的组合. 2)统计依存关系箭头两端词的组合,找出使用频率最高的10 000个两个词的组合.
2.2 SVM分类
使用LibSVM的SVM分类器,根据2.1节的结论总结出特征列表见表1. 按照表1编写程序分别统计倾向性语料和非倾向性语料中每个句子的值,输出为Weka平台数据文件格式.

表1 特征列表
例如:句子“我爱自然语言处理”通过哈工大LTP平台处理生成xml文件的主要内容如下:

采用表1的特征集生成Weka平台数据文件如下:

2.3 实证结果
将数据文件导入Weka平台,选择LibSVM分类器,参数选择-S 0-K 2-D 3-G 0.0-R 0.0-N 0.5-M 40.0-C 18.0-E 0.0010-P 0.1,通过10次交叉验证的方式得到实验结果. 表2是倾向性句子和非倾向性句子的混淆矩阵,表3是精度、召回率和F-值的实验结果数据.

表2 倾向和非倾向性句子混淆矩阵
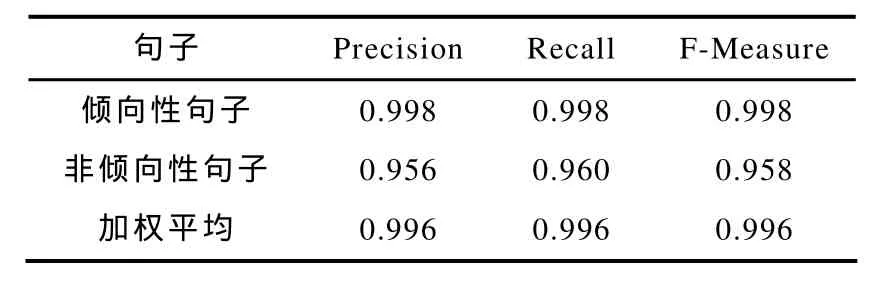
表3 精度、召回率和F-值数据
实验结果表明:本文设计的倾向性句子分类器的精度在 95.6%以上,召回率在 96%以上,F度量值在 95.8%以上. 也就是说,此分类器用于判断倾向性句子效果比较好,同时也表明词性特征和依存关系特征可以作为句子倾向性判断的特征集使用.
3 结论与展望
本文设计了一个采用 SVM分类器进行句子倾向性判断的系统,该系统除了采用倾向性词汇和倾向性搭配为特征外,还采用词性特征、依存关系特征,依存关系中的词性特征(2-POS)、邻接依存关系特征(2-DEP),邻接依存关系中词性特征(3-POS)等作为依据,实验结果表明该系统对句子倾向性的判断效果良好.
在手工从普通语料中抽取非倾向性语料的过程中,完全没有陈述人观点、也没有上下文主体的观点的句子数量非常少,比例在5%以下. 因此认为:在进行句子倾向性分析即对句子的倾向性进行分类之前,没有必要对句子的倾向性进行判断. 也就是说:句子倾向性判断可以不是句子倾向性分析的前提. 下一步的工作是通过实验及相关语料从多方面来验证此构想.
[1] CORTES C, VAPNIK V. Support Vector Networks[J]. Machime learning, 1995, 20: 273–297.
[2] 赵妍妍,秦兵,刘挺. 文本情感分析[J]. 软件学报,2010, 21: 3-10.
[3] TUMEY P. Thumbs up or thumbs down? semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th Annual Meeting I ACL, [S. I.]: Philadelphia, 2002: 417-424.
[4] TUMEY P, LITTMAN M. Measuring praise and criticism: Inference of semantic orientation from association[J]. ACM Transactions on Information Systems, 2003, 21(4): 315-346.
[5] KAMPS J, MARX M, MOKKEN R J, et al. Using WordNet to measure semantic orientation of adjectives [C]//Proceedings of LREC-04, 4th International Conference on Language Resources and Evaluation, Lisbon, LREC, 2004: 1115-1118.
[6] CHOI Yoonjung, KIM Youngho, MYAENG Sunghyon. Domain-specific sentiment analysis using contextual feature generation[C]//Proceedings of the 1st international CIKM workshop on Topic-sentiment analysis for mass opinion, New york: ACM, 2009: 37-44.
[7] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报,2005, 20(1): 14-20.
[8] 熊德兰,程菊明,田胜利. 基于 HowNet的句子褒贬倾向性研究[J]. 计算机工程与应用. 2008, 44(22): 143-145.
[9] 潘宁,林鸿飞. 基于语义极性分析的餐馆评论挖掘[J]. 计算机工程,2008, 34(17): 208-210.
[10] TESNIERE L. Éléments de syntaxe structurale[M]. Paris: Klincksieck, 1959.
[11] 鲁川. 知识工程语言学[M]. 北京:清华大学出版社,2010: 8.
[12] 周国光. 现代汉语配价语法研究[M]. 北京:高等教育出版社,2011.
[13] 谭松波. 中文情感挖掘语料:ChnSentiCorp[EB/OL]. 北京:谭松波,2010-06-29[2012-03-21]. http://www.searchforum.org.cn/tansongbo/corpus-senti.htm
[14] 搜狐研发中心. 文本分类语料库[EB/OL]. 北京:搜狐研发中心,2008-09[2012-03-23]. http://www.sogou. com/labs/dl/c.html
[15] CHE Wanxiang, LI Zhenghua, LIU Ting. LTP: A chinese language technology platform[C]//Proceedings of the Coling 2010 Demonstrations, Beijing: [s.n.]. 2010: 13-16.
[16] HALL M, FRANK E, HOLMES G, et al. The weka data mining software: an update[J]. SIGKDD Explorations, 2009, 11(1): 10-18.
[17] CHANG Chihchung, LIN Chihjen, LIBSVM: a library for support vector machines[EB/OL]. [s.l.]: ACM Transactions on Intelligent Systems and Technology, 2011[2012-04-05]. http://www.csie.ntu.edu.tw/~cjlin/ libsvm.
[18] 哈工大社会计算与信息检索研究中心. 语言技术平台[EB/OL]. 哈尔滨:哈工大社会计算与信息检索研究中心,2011[2012-04-08]. http://ir.hit.edu.cn/demo/ltp/.
[19] 李正华. LTP使用文档V2.1[EB/OL]. 哈尔滨:哈尔滨工业大学信息检索研究室,2009[2012-04-11]:13-14. http://ir.hit.edu.cn/ demo/ltp/LTP-manual-v2.0.1.pdf.
Sentences Tendency Judgement by POS and Dependency Based on SVM
WU Ming-fen1,2, CHEN Tao1,2
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. School of Information Science, Wuyi University, Jiangmen 529020, China)
The objective sentences of multi-domain from views is distinguished by using part of speech, dependency relationship, the part of speech combinations of the two words under one dependency, two adjacent dependencies, the part of speech combinations of the three words under two adjacent dependencies, sentiment words and sentiment collocations as features of SVM classifier. The precision is about 95.6% with 10-fold cross-validation. It is assumed that the sentence tendency judgement is not the premise of the document sentiment analysis.
tendency judgement; dependency; part-of-speech characteristics; support vector machine
1006-7302(2012)04-0066-06
TP391.1
A
2012-06-27
中国科学院计算技术研究所智能信息处理重点实验室开放课题基金资助项目(LIP2010-5);广东省科技计划资助项目(2010B010600039);广东省自然科学基金资助项目(S2011010003681);江门市科技计划资助项目(2012003009398)
吴明芬(1964—),女,江苏常熟人,教授,硕士,硕士生导师,CCF高级会员,研究方向为模糊集、粗糙集理论及其在智能信息处理中的应用.
韦 韬]
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30
计算机应用(2017年4期)2017-06-27
海外华文教育(2016年1期)2017-01-20
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新闻研究导刊(2015年17期)2015-12-25
语言与翻译(2015年4期)2015-07-18
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中央民族大学学报(自然科学版)(2014年3期)2014-06-09
