
条件函数依赖及其在领域无关数据清洗中的应用
2012-10-20 08:35周健昌卜媛媛
微型电脑应用 2012年9期
周健昌,卜媛媛
0 引言
随着信息技术的进一步推广,人们在获得大量信息,享受信息化带来便捷的同时,数据质量引起的问题—garbage in,garbage out,也日益突现。质量存在问题的数据,常误导决策者做出错误决定,轻则造成经济损失,重则带来毁灭性打击。
经研究指出,在美国,因为数据质量的问题,每年造成经济损失达 6000亿美元以上[1]。普化永道会计事务所调查表明,75%被调查公司存在因数据质量问题而致经济损失现象;在数据库挖掘项目中,近90%的研究者花在数据清洗和数据准备上的时间,超过项目时间40%,25%研究者甚至超过80%[2]。以上数据明证:数据质量问题普遍存在,也已造成严重威胁,且随信息技术进一步推广,形势必将更加严峻。
提高数据质量的一个重要技术,是将“脏”的数据进行清洗以使其变“干净”,这实际上就是数据清洗。脏数据是指含错误的、冗余的、不一致的数据,它的来源是多样的:数据来源繁多、时效性不一致或录入错误等主客观原因。
目前,对数据清洗的研究大多是领域相关的,不同的应用领域对其有不同的解释,因而对数据清洗还没有统一的定义。然而,数据清洗的目的是基本一致的[3]:检测数据中存在的错误和不一致,剔除或改正它们,以提高数据的质量。数据清洗可按数据清洗对象、来源领域、产生原因、实现方式与范围等不同指标有各种划分,但数据清洗的基本任务是相同的,都是过滤或修改那些不符合要求的数据,其基本流程都是相同的[4]:数据分析与定义,识别错误记录,修正错误。
本文首先介绍条件函数依赖CFD的相关定义和性质,主要研究了利用CFD进行数据清洗的基本流程,并对其核心步骤提出了优化方案,通过实验对比了FD、CFD用于数据清洗的差别,以及CFD受相关度量的影响,得出了与以往用于数据清洗的FD相比,CFD更优胜的结论。
1 条件函数依赖
函数依赖(Functional Dependency,FD)在数据库及知识发现领域,都是一个重要的的概念,然而它对规则的挖掘而言却不太充分,因为现实中的规则往往是带有条件的,如[邮编]→[街道名]在整个世界范围内是不成立的,但若前提是在英国,则它是成立的。
文献[5]正是考虑到这种情况,最初出于数据清洗的目的而提出了条件函数依赖(Conditional Funcitonal Dependencies,CFD)。CFD是在FD的基础上加入语义约束扩展而来的,比FD表达更具体的约束,从而更适合于大量数据中数据特征的描述。定义1 CFD[5]:
设存在一个关系模式R,attr(R) 表示定义在其上的属性集,对每个属性A ,有A⊆attr(R),A 的值域可以表示成dom(A),定义在R 上的一个条件函数依赖φ可以表示成φ:(X→Y,Tp)。其中:
(1)X⊆attr(R)、Y⊆attr(R);
(2){X→Y}是一个标准函数依赖;
(3)Tp是与X和Y相关的模板,定义了相关属性在取值上的约束条件,取值可以是定值常量也可以是"_"("_"为变量,表示对应属性可取域中的任何值,但应符合存在的蕴涵及约束关系)。
可把ψ记为:ψ= (X→Y,Tp[X]|| Tp[Y]),则称ψ中X相关的一方模板Tp[X]称为LHS,将Y相关的一方模板Tp[Y]称为RHS,则从FD、CFD语义可推知一成立的CFDψ有如下特点:
1) LHS、RHS要么两方都含变量,这称全变量CFD,要么两方都不含变量,这称常量CFD,除以上两种情况外的仅LHS或RHS一方含变量是不可能出现CFD的.
2) 类似FD的Armstrong公理的合并律,设Y=A1∪A2∪…∪An,则任何(X→Y,Tp[X]|| Tp[Y])型CFD都可由(X→A1,Tp[X]||Tp[A1])、(X→A2,Tp[X]||Tp[A2]) … ( X→An,Tp[X]|| Tp[An])合成。
3) FD与CFD的关系:若将模板中关于LHS的部分Tp[X]看作约束条件,关于RHS的部分看作结果,符合Tp[X]这个条件的记录组成的一个关系实例 r′(r的一个子集),则CFD就是r′上标准的FD(此即上述CFD定义中“标准 FD”的含义)。
本文将通过下述表1来说明CFD及其特性和示例,说明如何将CFD应用于数据清洗,如表1所示:
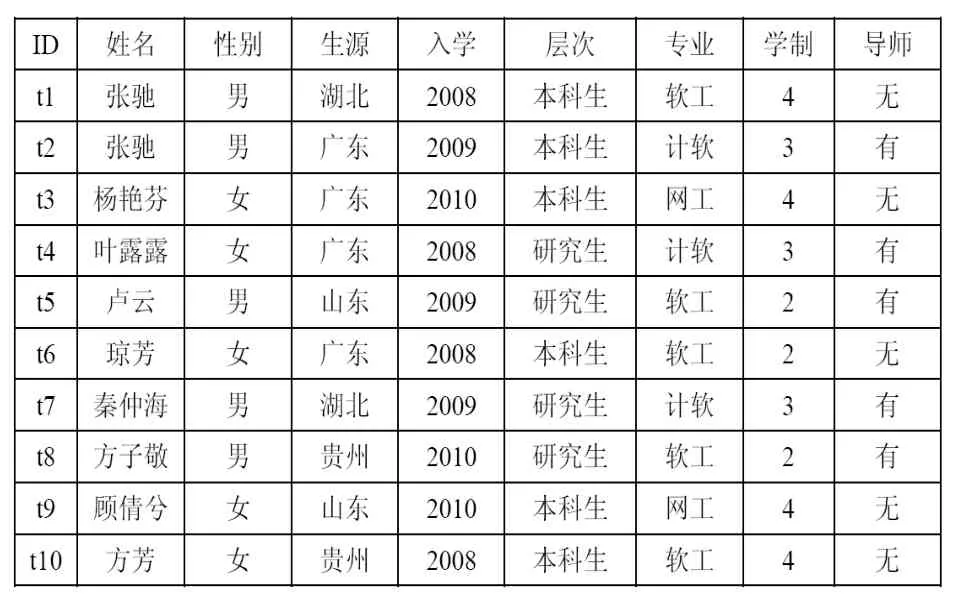
表1 信息学院学生信息表
据CFD的定义,我们可从表1中得到以下CFD:
ψ1:{(生源)→(性别),(湖北) || (男)},意为:信息学院中,所有湖北籍学生均男性。
ψ2:{(层次)→(导师),(-) || (-)},意为:“层次→导师”导师是一个FD关系.
ψ3:{(层次,专业)→(生源),(研究生,-) || (-)},意为:研究生中,不同专业的学生都来源于不同地方。
定义2:模板间的泛化关系[5]
为给CFD赋予语义,我们为模板的变量值与常量值定义出一个关系符“≤”,称泛化。
首先,对模板的同一属性分量取值n1、n2的泛化关系定义如下[5]:
n1≤n2,则n1==n2或n1是常量而n2是变量。
这种泛化关系很容易扩展到有相同属性集的模板Tp1[x],Tp2[x]上:
当且仅当∀ B∈X,都有 Tp1[B]≤Tp2[B]时,则有Tp1[X]≤Tp2[X],称 Tp2[X]泛化 Tp1[X]或 Tp1[X]具化 Tp2[X]。
为方便后文表达,我们引入“!≤”符号,其含义为:n1!≤n2,则 n1≤n2不成立。
例如:ψ4:{(层次)→(导师),(-)||(-)}就是对ψ2:{(层次)→(导师),(本科生) || (无)}的泛化。
2 基于CFD的数据清洗步骤
基于CFD的数据清洗是一种基于规则的数据清洗方案,它的基本处理流程可归纳为:
1) 数据分析与定义:为检测“脏数据”的类型,首先要对其进行详细的数据分析,除人工检查数据属性外,还应通过分析程序自动取得关于数据质量的元数据。
2) 获得描述数据集特征的CFD集:取得足以描述数据特征的规则集,是任何基于规则的数据清洗技术的核心步骤之一。对基于CFD的数据清洗,取得CFD集的方法主要是依赖数据挖掘的方法,从数据集中取得CFD集,再根据业务领域知识或元数据约束等增删CFD,以来进一步充实CFD集。
3) 利用CFD规则检测并标识错误:为从数据集中消除重复记录,首要的问题就是如何判断两条记录是否相似重复。
4) 冲突处理:根据一定的清洗规则合并或删除检测出的错误、相似重复记录,只保留其中正确的那些记录。
5) 重复2~4项,直至数据质量达标为止。
3 基于CFD数据清洗的核心步骤
3.1 挖掘描述数据集的CFD集:
对不同的规则类型,各有不同的规则集获得方法,而对于CFD,学者们已提出几种有效CFD挖掘算法,如CTANE、CFDMiner、FastCFD等[6]。不同挖掘算法适用领域可能不同,但它们的最终结果应一致—得出给定数据集中满足的所有非冗余CFD集。我们的实验采用的是CTANE算法,它的基本原理利用了CFD的以下性质:
对于ψ:{ X→A,Tp[X]|| Tp[A]}有Count(X,Tp[X])-Class(X,Tp[X]) = Count(X∪A,Tp[X∪A]) -Class(X∪A,Tp[X∪A]),则ψ成立,则其中
1) Count(X,Tp[X])是指在整个关系实例r中,在X上取值符合Tp[X]的记录的频数,
2) X∪A是属性集合的并(准确应写作X∪{A},本文中以此作简写)
3) Class(X,Tp[X])是指Tp[X]包含的等价类个数,即Tp[X]所蕴含的不含变量的不同取值的种类数。
从示例表来看,除ψ1、ψ2、ψ3因满足上述性质而被定为CFD外,{(生源)→(专业),(贵州) || (软工)}也是CFD,因为Count(生源,贵州)-Class(生源,贵州)=2-1,Count([生源,专业],[贵州,软工])- Class([生源,专业],[贵州,软工])=2-1。而{(姓名) || (生源),(-) || (-)}则不成立,因为Count(姓名,-)-Class(姓名,-)=10-9,而Count([姓名,-])- Class(姓名,-)=10-10。
3.2 利用CFD检测相似重复记录
相似重复记录的清洗,是数据清洗过程中最为关键的问题之一,也是研究最多的领域。解决相似重复记录的问题,就是要对数据集合中的记录进行对象识别,即根据记录所含的各种描述信息来确定与之相应的现实实体。
文献[7]与文献[8]中提出了利用SQL查询语句来实现检测相似重复,其基本原理是:
若有ψ':{X→A,Tp[X]|| Tp[A]}、ψ'':{X→A,Tp[X]||Tp[A]},若Tp'[X]= Tp''[X]≤Tp[X],但Tp'[A]≠Tp''[A],则X取值为Tp'[X]、Tp''[X]的记录中存在错误,用类SQL语句来描述如下:

一般地,检测分两个步骤进行[9]:
例如,我们得出如下的CFD:
ψ5:{(导师)→(层次),(-) || (-)}
ψ6:{(导师)→(层次),(有) || (本科生)},则我们可构造如下Tp,如表2所示:

表2 θ1:{(导师)→(层次),Tp1}
显然,表2所表过的θ1融合了ψ5、ψ6,而对于θ1,我们只要用就可以检测出t2、t4、t5、t7、t8间存在违例记录。
ψ7:{(层次,专业)→(学制),(-,软工)→(-)},如表3所示:
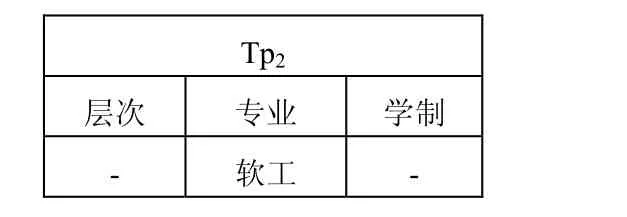
表3 θ2:{(层次,专业)→(学制),Tp1}
从表3知,θ2包含了ψ7,而对θ2,我们仅通过是无法检测出违例记录的,只有使用时才能确定t1、t5、t6、t8是违例记录。
实际应用中,每个数据库可能有多个CFDs作为约束条件。直观地来说,可以针对每个CFD按上述的查询进行检测操作,即每个CFD对应一组查询语句对,显然随着CFDs 数量的增加,检索会显得愈加繁杂。因此,文献[8]提出,对多CFDs条件进行整合,形成形式上新的约束条件和查询语句对,实质就是对相似CFD抽象它们的共性,引入了更泛化的CFD,以构造一个更通用的SQL查询对,从而将查询的次数大大降低,我们并不深入探讨此方法。
4 我们的改进
4.1 为规则的挖掘引入支持度
现实数据中常受到噪声的干扰,从而产生不一致的数据记录。尽量消除噪声也正是本文的目标,然而,现实情况是,有时候我们只对记录数达到一定限度的错误才作出修正,也就是说,允许存在一定的错误容忍度,这或许是对经常进行数据增删的数据集对错误检测效率的折衷,或者是实际应用的需要,如网络入侵检测中,不能稍微一点错误都认为是入侵的发生,因此,我们提出在规则检测时,使用支持度阈值,只有达到一阈值的错误规则才予以考虑并修正。这样做还有一个好处,正如Apriori算法中使用支持度剪枝,利用支持度的反单调性,我们可提前将不可能出现CFD规则的分枝剪去,从而大大速了规则挖掘的效率。
当然,必需说明的是由于引入了支持度使得一些规则可能会被忽视,需根据应用的情况来决定是否决定使得支持度。
4.2 为规则的挖掘与保存引入近似CFD概念
由前面的叙述知,对于无错的数据,挖掘得的CFD其置信度总是100%的,而对于含错的数据基本上是在大量的正确数据之余,含有零星的错误数据。这些少量的错误数据中其置信度总是较小的,而相应受到干扰的大量数据,其CFD置信度总是接近1而又小于1。
于是提出使用两个置信度阈值,conf_lo与conf_hi(conf_lo<conf_hi),按挖掘得出的置信度conf,将CFD放在不同的集合:
1) 0<conf ≤conf_lo,则将CFD放到可能含错的CFD集,记为∑e。
2) conf_hi≤conf ≤1, 将受到干扰CFD放入到∑n。
3) conf=1, 是正确CFD,将它放入到∑中。
4) conf_lo<conf <conf_hi,因为它出现的频度足够多,故不认为是错误的CFD。
这样的分类的好处是在使用基于SQL检测违例时,我们只需要∑e与∑n构建相应的更泛化的模板表,而无须理会∑,而∑e与∑n的规模较于∑一般而言是十分小的,从而加快了违例检测的效率。
插入记录时,我们先检测∑的规则,看是否符合其中的CFD,符合则直接加入数据集中,否则,检测∑e、∑n,若在其中发现有相应的CFD规则,则更改相应规则的置信度,再将记录插入数据集中,若插入记录使得∑e、∑n中相应规则的置信度conf有conf_lo<con<conf_hi,则将相应的CFD规则从∑e、∑n中除去,因为达到相应置信度后的规则极可能不是“错误”,只是可能相应记录顺序问题,才使前面检测出现“错误”的假象。删除记录时可以采取类似策略。
通过这种方法不仅可以高效地检测违例记录,而且在插入删除记录时,避免重新检测带来的时间空间的浪费。
5 实验分析
为分析基于 CFD的数据清洗方案的性能,使用 UCI中的adult[10]实验数据集进行FD与CFD对规则挖掘的比较,实验数据集的基本信息,如表4所示:

表4 实验数据集的基本信息
在实验中,涉及到数据的记录数目N是只取数据集的前N个记录,涉及到M个属性时,是只取它的前M个属性。实验平台:
处理器:Intel Pentium E21802.0GHz×2
操作系统:Windows XP SP3
内存:1.0 GB 实现语言:Java
5.1 FD与CFD的比较:
对FD挖掘使用的是TANE算法,对CFD挖掘使用的是CTANE,后者是前者的扩展,从挖掘原理与基本优化策略来说都有一定的相似性,因而在一定程度上它们的性能差异可以反映出FD与CFD之间的某些差异性,故而是可比的。
实验得出结果,如图1~图4所示:
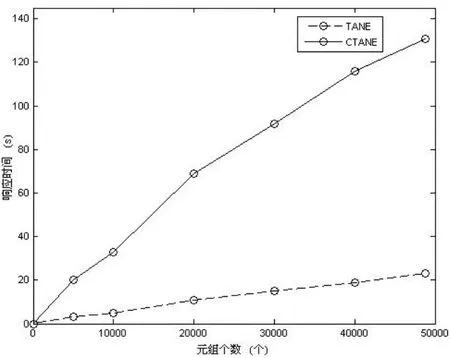
图1 Tane与CTane对记录数目(|r|)的敏感程度
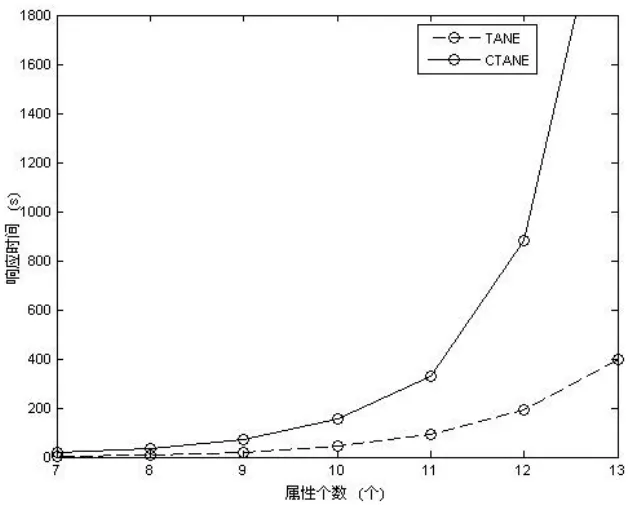
图2 Tane与CTane 对属性数目(|R|)的敏感程度
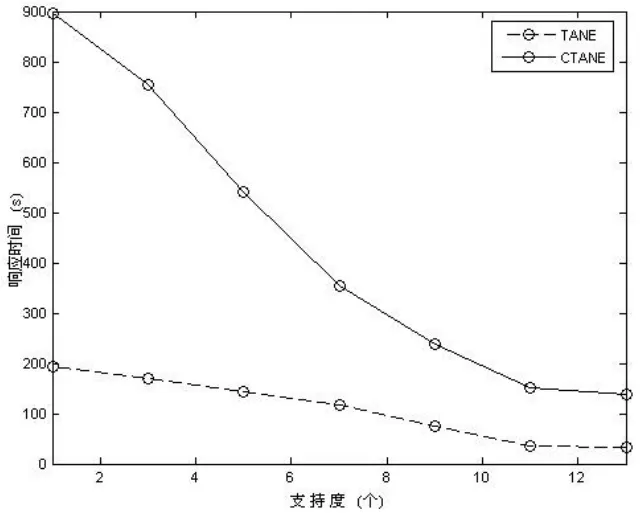
图3 Tane与CTane对支持度的敏感程度(1)
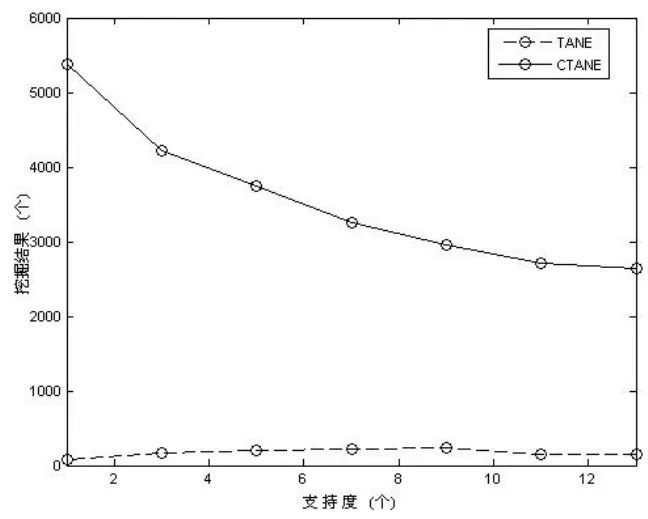
图4 Tane与CTane对支持度的敏感程度(2)
从图1、图2 可看出,CTANE、TANE的时间复杂度大致均随|R|呈指数级增长,随|r|呈线性增长,但CTANE的增长系数明显比TANE大,这是因为CTANE在TANE的基础上还要进行语义分析工作,它处理的对象粒度比 TANE细。因而,相同的|R|、|r|的情况下,CTANE的时空代价肯定比TANE大。
从图3、图4 可看出,CTANE比TANE对支持度更敏感一些。利用支持度,一般对CFD挖掘的提速幅度比TANE大,但相对来说,精度的损失也较严重,因而使用支持度应针对相应的领域知识,谨慎选择支持度阈值。
由图4还可知,对相同的数据集,相同的实验实例情况下,CTANE挖掘得的CFD远较TANE得出的FD要多,故而也间接说明了CFD对数据集的描述远较FD要具体,从而更适合于数据清洗。
5.2 改进前后的数据清洗方案进行了对比。
如图5所示:
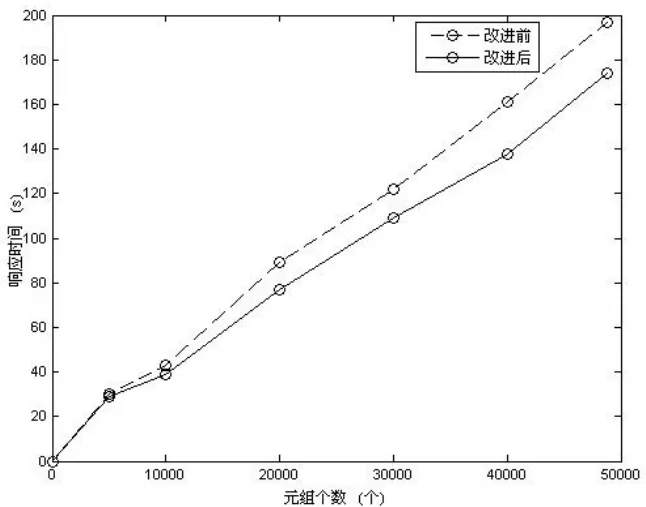
图5 改进前后的基于SQL数据清洗方案对比
对引入支持度的改进可以从上面的图中已得出结论,在此不再重复。
对引入近似CFD的改进,可从图5得出结论,改进后的清洗方案确实比原有的清洗方案,有了较大的性能上的改善。
6 总结
本文介绍了CFD的定义及其基本性质,并说明了应用CFD进行数据清洗的基本步骤,同时还对已提出的基于CFD数据清洗方案的改进,实验也表明,提出的改进,基本可以达到一定程度的优化。
[1]Eckerson, W.“Data quality and the bottom line,” [M]TDWI Report Series,Tech.Rep., 2002.
[2]曹建军,刁兴春,汪挺,王芳潇.领域无关数据清洗研究综述[J].计算机科学, 2010,(05) .
[3]Erhard Rahm, Hong Hai Do.Data cleaning: problems and current approaches .[M]IEEE Data Engineering Bulletin,2000,23(4):3-13.
[4]王曰芬,章成志,张蓓蓓,吴婷婷.数据清洗研究综述[J].现代图书情报技术, 2007,(12) .
[5]Bohannon P, Fan W, Geerts F, et al, Conditional functional dependencies for data cleaning[C]IEEE 23rd International Conference on Data Enginering, 2007: 746-755.
[6]Fan W,Geerts F,Li J,et al.Discovering conditional functional dependencies[C].IEEE25th International Conference on Data En-gineering.2009, :683-698 .
[7]Fan W,Geerts F,Jia X,et al.Conditional functional dependencies for capturing data inconsistencies[J].ACM Transactions on Data-base Systems, 2008, 33(2) :1-44 .
[8]Bohannon P, Fan W, Geerts F, et al, Conditional functional dependencies for data cleaning[C]IEEE 23rd International Conference on Data Enginering,2007:746-755.
[9]耿寅融,刘波.基于条件函数依赖的数据库一致性检测研究[J].计算机工程与应用,2012.
[10]实验数据源:http://archive.ics.uci.edu/ml/datasets/Adult
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
文教资料(2022年1期)2022-04-08
核科学与工程(2021年4期)2022-01-12
今日农业(2020年15期)2020-12-15
计算机应用(2018年5期)2018-07-25
中国民政(2016年12期)2016-09-16
山东青年(2016年1期)2016-02-28
中国老区建设(2016年2期)2016-02-28
轴承(2015年2期)2015-07-25
当代修辞学(2014年3期)2014-01-21
