
动态自适应加权的多分类器融合词义消歧模型
2012-10-15 01:51张仰森
中文信息学报 2012年1期
张仰森,郭 江
(北京信息科技大学 智能信息处理研究所,北京100192)
许多与自然语言处理相关的应用系统,如机器翻译、文本校对、信息检索、文本分类等,其性能的优劣与词义消歧的效果密切相关。因此,长期以来,汉语词义消歧一直是中文信息处理领域的难点和热点。由于词义消歧本身可以看作分类问题,因此,词义消歧模型的构建其实就是分类器的构建。由于不同分类器在不同领域的表现效果不同,因此,近年来集成学习方法成为机器学习领域的发展趋势[1],采用多分类器融合方法建立词义消歧模型的技术越来越受到研究者的关注,并在实际中得到应用[2-3]。多分类器融合就是通过某种规则将多个基分类器的判定结果融合起来,使得各基分类器之间相互弥补,得到系统最终的决策结果。构建多分类器融合词义消歧模型的工作一般由四步构成[4],包括模型参数输入、基分类器的设计与选择、模型体系结构、融合规则。模型参数输入是指用于确定语句中某个词词义的特征表示方式;基分类器设计与选择是指选择哪些分类器来进行集成融合;模型体系结构是指对各基分类器进行融合的体系结构;融合规则是指将各基分类器判定结果进行组合获取最终判定结果的规则与算法。关于多义词词义消歧的特征选择,已有很多的相关研究,我们在实验部分再进行讨论,下面主要就模型的体系结构、基分类器集合的设计与选择、多分类器的融合规则进行讨论。
1 多分类器融合的体系结构
多分类器融合的体系结构有级联方式和并联方式两种。采用级联方式时,将多个基分类器串联起来,前一级分类器为后一级分类器提供分类信息,指导下一级分类器的判断;而采用并联方式时,各基分类器的设计是独立的,各基分类器给出词义消歧的判定结果,按照某种融合规则将各单分类器的结果进行融合得到最终的词义判定结果。
由于并联方式可以使各基分类器并行工作,因此在分类速度上有较大优势。近几年,多分类器融合的研究主要集中在并联方式,特别是融合规则或算法的研究。分类器融合的目标是对各基分类器提供的信息进行融合,各基分类器提供的信息可以分为结果级、排序级和度量级三个层次[4]。(1)结果级是指基分类器给出的某个确定的词义,即最终分类的结果;(2)排序级是指基分类器按照多义词的上下文特征给出多义词词义类别的一个排序列表,排在最前面的是第一选择;(3)度量级是指基分类器给出选择每个词义类别的概率值。在这三个层次中,度量层所含的信息最丰富,结果层最少。从分类器工作过程来看,排序层是使用度量层的结果来排序,结果层是使用排序层的结果。从度量层到结果层是一个信息量递减的过程。所以适用于信息量少的层级融合的方法同样适用于含信息量多的层。
采用并联方式的分类器融合,可根据基分类器的信息层次分为三类:基于结果层的融合方法、基于排序层的融合方法、基于度量层的融合方法。这三类融合方法利用的信息是一个逐步具体的过程。对于第一类方法,其利用的信息最为简单,其规则的设计也相对简单;对于第三类方法,由于提供的信息量增多,规则或算法的设计相对繁琐,如果设计得当,多分类器融合模型的分类效果会比较好,若设计得不好,融合分类器的分类效果可能还不如单个分类器的分类效果。
2 基分类器的分析与选择
要想在多分类器的融合上取得好的效果,除了融合算法的设计,对于每个分类器而言,一般需要满足以下原则:
(1)基分类器的精确度要高,否则构造的融合分类器精确度也不会很高。
(2)基分类器应该具有多样性。基分类器之间应该产生互补信息,如果不同的分类器产生相同的错误,则融合就变得没有意义了,整体性能也不会有任何提高。
基于上述基分类器的选择原则,我们考察了最大熵分类器、朴素贝叶斯分类器、向量空间分类器和决策树分类器。这几种方法很具有代表性,且原理和方法互补性很强。我们分别利用这几种模型进行了词义消歧实验,相关的分析实验结果已在另一篇论文[5]中给出。其中朴素贝叶斯是传统的概率统计方法,简单快速,准确率高,稳定性强,对不同的特征对象进行实验,其最低准确率达到了78.12%;决策树是以实例为基础的归纳学习算法,易于理解,但对不同特征对象进行实验的效果不是太好,最好为67.3%。最大熵模型由于是一种使用多种类型特征的模型,在实验中表现不俗,其最低达到了83.35%。向量空间方法,是信息检索领域的基础,能够克服数据稀疏的问题,当特征选择恰当的时候,比如整句特征时,其最低准确率为68.52%以上。鉴于以上分析,在后面的融合实验中选择最大熵分类器、朴素贝叶斯分类器、向量空间分类器作为融合算法的基分类器。
3 分类器融合的主要方法
近年来已经有人将多分类器融合技术应用到词义消歧领域。融合方法主要有两种:(1)采用不同种类的分类器作为基分类器进行融合;(2)对同一种分类器选择不同词义消歧特征进行计算,将计算结果进行融合。融合计算常用的方法有乘法规则、均值、最大值Max、最小值Min、最大投票、序列投票、加权投票、概率加权等[2]。2000年 Kilgarriff和Rosenzweig采用简单投票策略集成SenSeval-1多个参赛系统的输出结果进行词义消歧[6];2008年吴云芳等[2]采用支持向量机、朴素贝叶斯、决策树,综合运用乘法规则、均值等9种集成方法,在两个不同数据集上进行了实验。它们都属于前述的第一种融合方法。2004年Wang和Matsumoto提出了一种堆栈集成法[7],单分类器选用朴素贝叶斯分类器,使用特征模板提取特征;2006年全昌勤等应用AdaBoost思想[3],选择贝叶斯分类器,通过学习少量带有词义标注的语料构造多个消歧分量分类器,并利用未标语料动态地对这些分类器进行更新,根据最终分量分类器进行集成确定多义词义项。它们都是采用了一种分类器对多种特征或分量进行叠加融合,属于前述的第二种融合方法。
(1)最大投票(Majority Voting,MV)方法
最大投票法是一种简单的分类器融合方法,由基分类器先对样本进行判断得出自己的分类结果,对自己所预测的类投一票,最后得票最多的类就是融合学习算法最终的预测结果。假设词有n个词义,有m个分类器参与投票,则其融合模型如公式(1)所示:

其中,sk表示词W 的第k个词义,fi表示第i个分类器,sj表示第i个分类器确定的词义,Δji是第i个分类器对第j个词义的投票结果,是m个分类器融合后得到的词义消歧结果。
(2)改进的投票(Improved Voting,IV)方法
简单的投票融合过程是结果级的融合,基分类器只输出单纯的分类决策,没有其他附加信息。对简单投票做以下改进,使其融合在度量级上进行,计算式如下:

其中,sj表示词W 的第j个词义,fi表示第i个分类器,P(sj)表示所有单分类器对词义sj输出概率的均值,是m个分类器融合后得到的词义消歧结果。这种方法属于上述的第二种融合方法。
(3)性能加权投票 (Performance Weighted Voting,PWV)方法
最大投票方法在确定最后结果时,没有考虑不同基分类器的分类性能及所采用的不同分类特征。所以,该方法无法体现性能高的分类器的优势,于是,人们就想到对上述两类方法进行改进,给性能高的分类器赋一个高的权值,这就是基于性能的加权投票方法。基于性能的加权投票方法可在结果级和度量级进行,结果级性能加权是对MV方法中式(1)和(2)的改进,结果如式(5)和(6);度量级性能加权是对IV方法中式(3)和(4)的改进,结果如式(7)和式(8)。

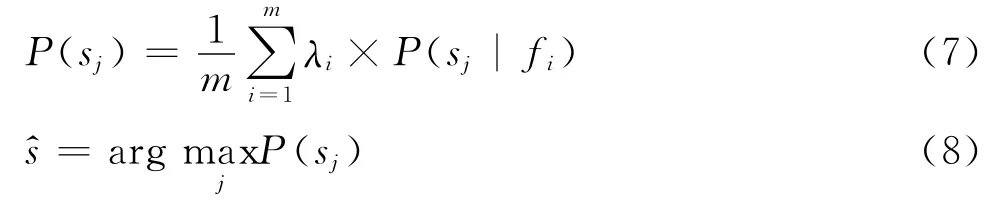
其中,sk表示词W 的第k个词义,fi表示第i个分类器,sj表示第i个分类器确定的词义,Δji是第i个分类器对第j个词义的投票结果,是m个分类器融合后得到的词义消歧结果,λi为分类器fi的加权系数。
4 动态自适应加权分类器融合模型
我们已在文献[5]中对四种分类器在词义消歧方面的应用情况进行了分析比较,目的是希望通过融合技术来提高词义消歧模型的性能。前面介绍的性能加权投票方法就考虑了各种分类器的性能,但其权值λi的确定缺乏依据,不能根据各基分类器在相应样本特征情况下动态自适应确定。本文在前述分析的基础上提出了一种动态自适应加权投票融合方法(Auto Weight Adjust,AWA),它充分考虑了各分类器在不同样本环境下的性能表现,计算出确定分类器fi加权系数的阈值θi,再根据θi计算该分类器的加权系数βi。动态自适应加权投票融合模型如式(9)所示。
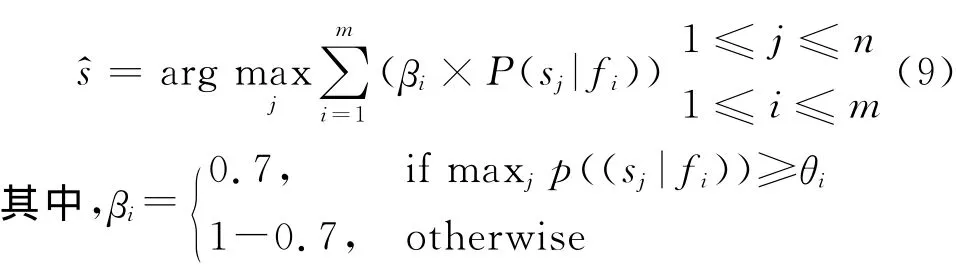
βi是我们设计的加权系数函数,用来表示基分类器fi对类别sj的权值;θi为确定分类器fi加权分量的阈值,阈值θi根据单分类器fi在决策时的“自信”值确定,“自信”值为分类器fi对每个类别sj(j=1,2,…,n)给出的度量层结果的概率平均值。用数学公式表示如式(10)所示。

与上述性能加权投票(PWV)不同,PWV通常将加权系数λi设置为基分类器的概率p(fi)[2],而这是很难求得的。本文设计的加权系数根据分类器fi的自信程度来确定它的权值,θi反映了分类器fi对所有类别sj(j=1,2,…,n)计算出的度量层的分类概率的平均值,如果P(sj|fi)大于或等于平均值θi,则说明fi对分类结果更倾向于类别sj,也就是说,它自信自己对确定最终类别sj的贡献要大,因此,给P(sj|fi)的权重系数为0.7,而如果P(sj|fi)<θi,则说明分类器fi对选择类别sj并不自信,因此在最终确定sj时只对自己计算出的概率值P(sj|fi)要30%的加权值。
这样设计的性能加权系数,能够保证每个分类器fi(i=1,2,…,m)对最后类别的确定具有发言权,只是每个分类器根据其自信度(是否大于阈值θi)发言权的大小不同。克服了只考虑那些对类别确定具有最大概率的分类器的缺陷,让所有分类器都能发挥作用,计算的结果更合理。在词义消歧应用中,分类的类别就是多义词的义项,这里所设计的模型,考虑了更多的上下文特征,不同的上下文特征集对应于不同的分类器,每个分类器都能对当前多义词的义项确定发挥作用,只是每个分类器对多义词的每个义项的贡献权重不同。综合计算出它的每个义项的概率值之后,排序选择概率最大的那个义项作为多义词的义项。通过大量实验,我们发现使用0.7确定“自信”特征的加权系数效果比较好。具体算法步骤如下:
Step1.对数据集(人民日报2000年11、12月中的50天语料)按不同的特征提取方法(所设计的7种特征模板)进行特征提取,形成7个特征集。
Step2.对每个基分类器fi(i=1,2,…,m),利用Step1得到的7种特征集,对多义词进行消歧分类实验,将消歧效果好的特征集作为与自己相适应的特征集。
Step3.对基分类器fi(i=1,2,…,m)确定在其相应的特征集下,在度量层计算出每个类别sj的概率值,并按式(10)计算相应的“自信”阈值θi。
Step4.For Each sjin S
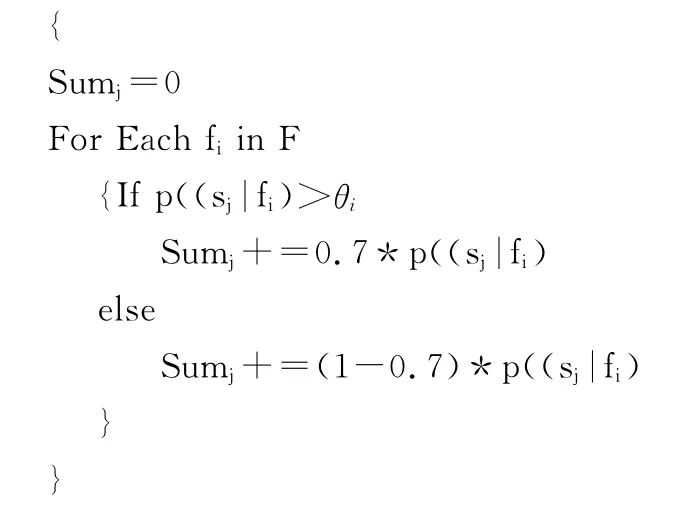
Step5.对度量层的sj(j=1,2,…,n)进行排序,选出sumj最大的那个sj作为分类结果。
5 实验设计与实现
选取的实验语料为北京大学计算语言学研究所标注的《人民日报》词义标注语料库,实验选取了2000年11月和12月两个月的标注语料共20M,其中80%(50天)作为训练语料,20%作为测试语料。同样从语料中统计出现频率大于500的动词,选取如表1所示的15个作为实验对象,其中CSD表示《现代汉语语义词典》。

表1 15个实验用的多义词
(1)特征模板设计与特征提取。上下文知识选择了“整句范围词性”、“整句范围词”、“整句范围词性+词”、“(-2,+2)范围词性”、“(-2,+2)范围词”、“(-2,+2)范围词性+词”、“依存句法”等七种特征,作为备选特征。
融合实验结果比较的主要技术指标是:准确率=正确标注数/标注总数。
(2)实验过程。实验过程遵循多分类器系统构建的三个步骤:数据预处理,基分类器训练,融合基分类器。
数据预处理:包括特征提取和数据规范化,这些操作在模型训练和测试中都会用得到。
基分类器训练:针对贝叶斯、向量空间、最大熵等三种消歧模型,在备选样本集中进行模型的训练,取得效果理想的基分类器。
分类器融合:用上述提出的动态自适应加权投票分类器融合方法将生成的基分类器组合在一起。
(3)实验设计。通过分析,我们设计了以下四种实验,对本文所提的分类器融合模型进行验证。
实验一:成员分类器选择贝叶斯、向量空间、最大熵三种模型,舍弃决策树分类算法,因为决策树算法性能不高,会影响集成分类器的效果。多分类器集成方法采用了最大投票(MV),改进的投票(IV),性能加权投票(PWV)和动态自适应加权投票(AWA)
实验二:只选取平均结果在85%以上的单分类器作为基分类器,即贝叶斯、最大熵进行实验。由于只有两种基分类器无法使用简单投票法进行集成,实验选择改进的投票(IV)和动态自适应加权投票(AWA)的融合算法。
实验三:选择最大熵分类器,在七种备选特征集上分别进行训练,得到不同的模型,然后使用最大投票(MV)、改进的投票(IV)、性能加权投票(PWV)和动态自适应加权投票(AWA)的融合算法进行计算。
实验四:选择贝叶斯分类器,在七种备选特征集上进行分别训练,得到不同的模型,然后使用最大投票(MV)、改进的投票(IV)、性能加权投票(PWV)和动态自适应加权投票(AWA)的融合算法进行计算。
6 实验结果分析比较
实验一结果如表2所示。

表2 实验一结果

续表
由实验一的结果可以看出,融合分类器的平均准确率从高到低依次为AWA、IV、PWV、MV。其中,IV、PWV、AWA结果优于最佳单分类器最大熵(91.08%)[5],效果最好的 AWA 比之高出0.53%。进一步分析,可以得出以下结论:
(1)最大投票方法表现较差的原因是它只利用了单分类器结果层的信息。虽然性能最佳的单分类器超出其他成员分类器许多,但在最大投票中却不占优势,因为规则是“一人一票”。就像真理掌握在少数人手中,却不被大多数人接受。
(2)改进的投票方法成功的原因在于结果的融合是在度量层。该方法充分考虑了单分类器给出的义项概率估计值会提供潜在的有用信息,体现出了性能好的单分类器的优势。
(3)性能加权投票略逊于改进的投票方法。虽然其结果的融合也是在度量层,但它在融合结果时加了一个权值,这样就引入了人为的噪声。
(4)动态自适应加权投票结果融合也是在度量层。其之所以获得最终的成功,在于权值的设定去掉了人为的因素,而是根据各基分类器自身情况自动决定的。
实验二的结果如表3所示。
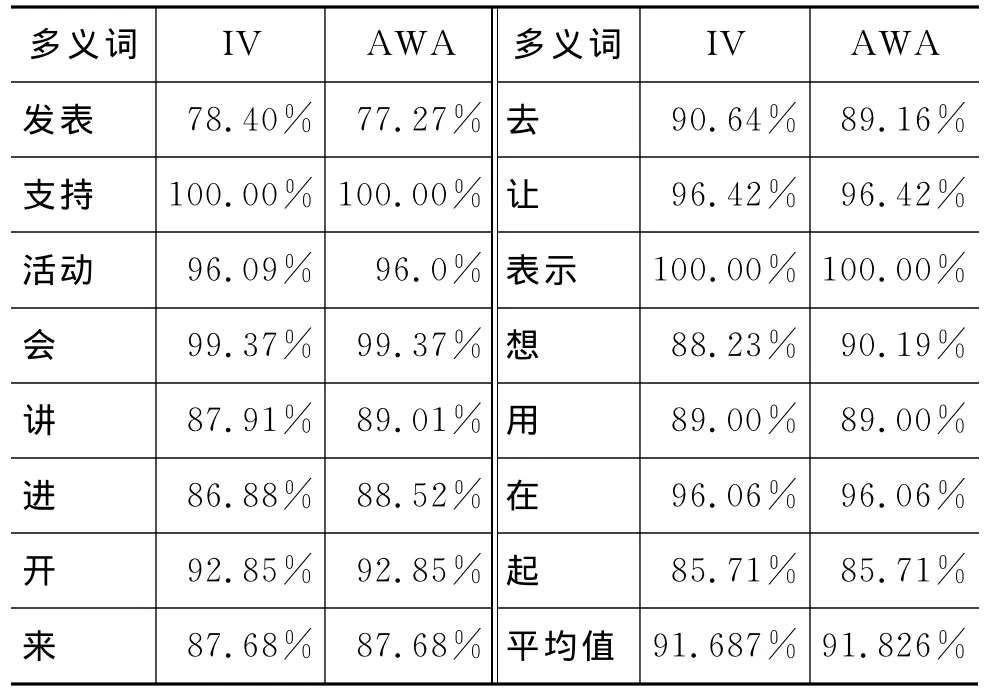
表3 实验二结果
在去掉了性能较差的向量空间模型之后,改进的投票方法和动态自适应加权投票的正确率都获得了提升。究其原因,在于性能不好的单分类器扯了“大家”的后腿,其提供的互补信息,不足以弥补性能低下带来的损失。而且动态自适应加权投票仍然领先于改进投票方法,充分说明了本文所提算法的有效性。深入分析原因,得到如下观点:AWA之所以有效可以从它的模型算法看出来,它克服了性能好的单分类器“过度自信”的缺点,同时又照顾了性能好的单分类器的权重,但如果单分类器表现出“不自信”就进行惩罚,降低其权重。算法关键就在自调节性上。
本实验结果,为下一步的深入研究指明了方向,成员分类器一定要选择性能好的单分类器,否则构造的集成分类器精确度也不会很高。
实验三的结果如表4所示。

表4 实验三结果
由实验三的结果可以看出,集成分类器的平均准确率从高到底依次为 MV、PWV、IV、AWA。所有集成分类器的结果均优于单分类器最大熵的最佳性能(91.08%)[5]。这说明特征之间的互补信息,帮助提高了最终融合结果的准确率。在一种特征空间中难以识别的模式,可能在另一种特征空间中很容易识别。
实验四结果如表5所示。
由实验四的结果可以看出融合分类器的平均准确率从高到底依次为AWA、PWV、IV、MV。除了AWA超出了贝叶斯最佳性能(87.66%),其他集成分类器均略低于最佳性能。
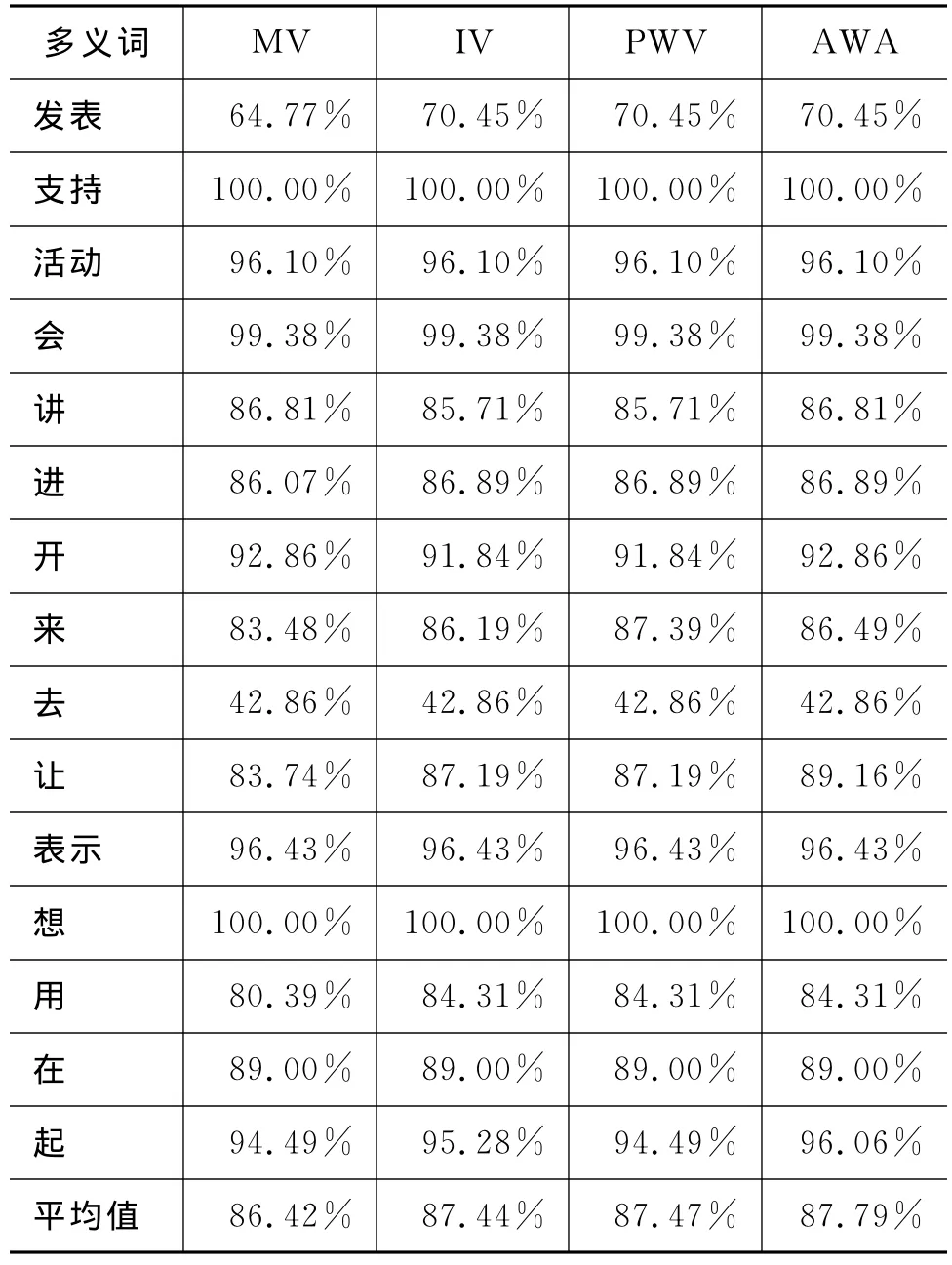
表5 实验四结果
综合实验三的结果和实验四的结果可以看出,一种规则并不是放之四海而皆准的,在一种模型上适用的融合方法,并不一定在另一种模型上适用。但通过这两个实验也可以看出,多分类器融合方法能够提高单分类器的效果。
本文在分析了前人分类器融合算法的基础上,结合词义消歧的任务提出了一种动态自适应加权投票的多分类器融合算法。通过实验检测表明,所提出的分类器融合模型充分利用了各基分类器输出的义项概率值,提高了词义消歧的准确率,分析其原因主要在于模型本身的自调节性上。另外,实验也表明,一种融合规则并不是适合任意的多分类器进行融合。
[1]Thomas G.Dietterich.Machine learning research:Four current directions[J].AI Magazine,1997,18(4):97-136.
[2]吴云芳,王淼,金澎,等.多分类器集成的汉语词义消歧研究[J].计算机研究与发展,2008,45(8):1354-1361.
[3]全昌勤,何婷婷,姬东鸿,等.基于多分类器决策的词义消歧方法[J].计算机研究与发展,2006,43(5):933-939.
[4]Latinne P,Debeir O,Decaestecker C.Combining Different Methods and Numbers of Weak Decision Trees[J].Pattern Analysis & Applications,2002,5(2):201-209.
[5]张仰森,郭江.四种统计词义消歧模型的分析与比较.北京信息科技大学学报,2011,26(2):13-18.
[6]Kilgarriff A,Rosenzweig J.Framework and results for English SenSeval [J]. Computers and the Humanities 34:15-48,2000.
[7]Xiaojie Wang, Yuji Matsumoto.Trajectory based word sense disambiguation [C/OL]//COLING 2004:Proceedings of the 20th International Conference on Computational Linguistics. http://aclweb. org/anthology/C/C04/C04-1130.pdf.
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24
纺织科技进展(2021年5期)2021-07-22
西夏研究(2020年1期)2020-04-01
新世纪智能(英语备考)(2019年11期)2020-01-18
电子技术与软件工程(2019年18期)2019-11-18
家庭影院技术(2019年8期)2019-08-27
中国惯性技术学报(2018年4期)2018-11-08
新高考(英语进阶)(2018年3期)2018-05-14
电子技术与软件工程(2017年14期)2017-09-08
燕山大学学报(2015年4期)2015-12-25
