
无结构P2P网络中一种高效的资源搜索机制*
2012-10-08 01:58赵佩章张同光
电信科学 2012年3期
赵佩章,张同光
(新乡学院计算机与信息工程学院 新乡 453003)
1 引言
近来P2P网络飞速发展,已成为互联网中最流行的应用之一。作为一个分布式的网络,其效率在很大程度上依赖于资源搜索的机制。尽管近年来关于P2P资源搜索的研究很多,但是在资源搜索方面一直存在很多需要解决的问题[1]。通常情况下,结构化P2P网络更倾向于采用DHT(distributed hash table,分布式散列表)的搜索方式;对于无结构P2P网络来说,例如Gnutella[2],资源搜索主要是使用洪泛(flooding)或者有一定控制的洪泛来进行,如随机走(random walk)[3],由于这样会在资源搜索过程中访问大量不相关的节点,因此造成较低的搜索效率。为了提高无结构P2P网络资源搜索效率,研究人员提出了许多搜索机制[4~7],但是这些搜索机制都没有考虑到节点之间语义的相关性,因此这些搜索机制仍然具有较高的搜索开销。
在语义相关的P2P网络中,相关的节点连接在一起,形成一个语义组。GES[8]和CSS[9]两种搜索机制都使用VSM(vector space mode,向量空间模型)[10]来计算节点的语义相关度。GES首先会对每一个节点进行矢量抽取,然后借助于VSM来计算节点间语义相关度,并依据计算出来的语义相关度数值生成网络拓扑,最后采用语义目标节点定位和洪泛相结合的搜索方式。CSS在GES的基础上,将每个节点按照所含内容的不同种类再细分为更小的虚拟节点,此法虽然可以提高资源查询的精准度,但是虚拟节点的引入却极大地增加了网络的开销。
在本文中,提出了一种新颖高效的资源搜索机制SKIP。在GES和CSS中,当通过biased walk(偏好查找)方法找到一个语义目标节点后,使用洪泛的方式在语义组中进行查询。本文提出的SKIP搜索机制将使用K-层迭代优先选择的方法来取代GES和CSS中的洪泛方式,同时,在整个拓扑结构的维护中,SKIP与GES所产生的开销相同,SKIP在查准率和查询开销上的表现要优于GES,而CSS却要产生更大的虚拟节点开销。
2 相关研究
一般来说,P2P网络分为结构化P2P网络和无结构P2P网络两种。对于结构化P2P网络来说,通常使用DHT技术,例如CAN[11]、Pastry[12]和Chord[13]都是使用DHT对资源进行搜索。DHT方法尽管有着较高的搜索效率,但是它只能对关键字进行精确匹配,无法进行语义相关的查询。无结构P2P网络,例如Gnutella,能够使用语义相关信息来进行资源搜索,但是其搜索的效率却比较低。
当前无结构P2P网络被广泛应用,对于无结构P2P网络的搜索来说,主要有盲目搜索和非盲目搜索。盲目搜索算法,是不依靠任何提示信息而对其所有邻居节点或者部分邻居节点进行盲目的消息转发,直到满足停止的条件,如洪泛、random walk、BFS(breadth first search,宽度优先搜索)[14]等。非盲目搜索算法主要是路由索引[15]的方式。
为了减少洪泛的使用和提高搜索效率,一些搜索算法引入了历史查询信息。参考文献[16,17]所述算法是基于兴趣定位的搜索算法,假设节点A中有节点B需要的某一类内容,那么节点A中的另外一些类的内容也是节点B所感兴趣的,在节点B发起搜索查询时,首先会将查询请求消息发送到节点A中。参考文献[18]提出了一种SON(semantic overlay network,语义覆盖网络)的搜索机制,对网络中的每个节点所包含的内容进行分类,并向全网络广播。每一个新加入的节点都需要广播,这样极大地增加了网络开销。
还有一些P2P搜索机制,如SETS(search enhanced by topic segmentation,话题分割搜索)[9],它是采用超级节点方式,每个超级节点负责一类的内容,同时根据普通节点所含不同的内容连接到不同的超级节点上。SETS的搜索路由分为全局路由和本地路由。全局路由就是在不同的超级节点之间进行路由,寻找不同类的内容;本地路由就是主要在某一个超级节点的范围内进行洪泛查询。由于采用超级节点的方式,因此单点失效是SETS机制的一个致命问题。GES[5]采用分布式的方法,并且通过语义相关性建立连接,形成语义组。在进行资源搜索时,GES使用biased walk算法找到目标语义节点,通过目标语义节点在语义组中进行洪泛查询。在GES的基础上,有研究人员提出了CSS[15],CSS把每一个节点里面不同种类的内容再分成不同的虚拟节点,这样提高了查询的效率,但是却忽略了分割虚拟节点的开销。
3 VSM的背景介绍
VSM[10]是一种使用节点所包含的关键词来表示节点内容的方法。在VSM方法中,使用关键词的矢量来表示每一个文档或者查询消息,通过余弦内积和的计算方法来判断是否语义相关,对于一个文档D和查询消息Q来说,其计算方法为:

在式(1)中,t是在文档D和查询消息 Q中同时出现的关键词,fD,t是关键词t在文档 D中的权重,fQ,t是关键词t在查询消息Q中的权重。
4 SKIP设计
在这一部分中,将详细阐述SKIP,分为节点矢量、拓扑构建和搜索协议3个子部分。
4.1 节点矢量
对于每一个节点来说,把它的关键词按照权重抽取出来,形成节点矢量,使用节点矢量来表示这个节点的内容。使用VSM来计算节点矢量间的语义相关度。首先,对于一个节点中的每一个文档按权重抽取出关键词,每一个关键词的权重根据该关键词在文档中出现的频率来确定;其次,对于一个节点来说,将节点中每个文档的带权重关键词加起来,便得到该节点的权重关键词,其计算方法为在这里,n是该节点中文档数目,t是各个文档相同的关键词。最后,把所有按照上述方法计算出来的带权重关键词组合在一起,便形成了该节点的节点矢量。
以节点X和节点Y为例,它们的节点间语义相关度用节点矢量的计算方式如下:

在式(2)中,t是在节点X的节点矢量和节点Y的节点矢量中共同拥有的关键词。fX,t是关键词t在节点X中的权重,fY,t是关键词t在节点Y中的权重。如果通过式(2)计算出来的相关度数值大于或等于某一个门限值,那么这两个节点被认为是语义相关,反之,则不相关。
同样,可以用如下的式子来计算节点X和查询消息Q之间的相关度:
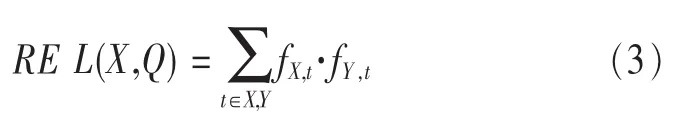
4.2 拓扑构建
每一个节点有两类邻居:一类是随机邻居,即是通过式(2)计算出来的语义相关度数值小于设定的相关度门限值REL_THRESHOLD;一类是语义邻居,即通过式(2)计算出来的语义相关度数值大于或等于设定的相关度门限值REL_THRESHOLD。拓扑构建的目标有两个,一是把语义相关的节点通过语义连接组成语义组,二是每个节点保持一定数目的随机连接以便于发现新的语义连接。拓扑构建算法包含两个部分,一个是邻居发现部分,另一个是邻居维持部分。
在邻居发现部分,起始节点会发起一个消息,该消息包含有本节点的节点矢量信息、语义相关度门限值REL_THRESHOLD、TTL(time-to-live,生命周期)等,该消息将随机地发送给其他节点。当消息到达一个节点后,该节点将会用式 (2)计算与起始节点的语义相关度,然后把TTL的数值减去1,再随机地发送出去,直到TTL的数值等于0,这条消息将会被丢弃。
MAX_SEM_LINKS是每个节点允许的最大语义邻居连接数,MAX_RND_LINKS是每个节点允许的最大随机邻居连接数。同时,每个节点有2个邻居候选cache:一个是随机邻居cache;一个是语义邻居cache。根据式(2)计算出来的语义相关度数值,该节点将会被起始节点按照是否语义相关分别放入随机邻居cache和语义邻居cache中,起始节点将会从语义邻居cache中选择语义相关度最高的前MAX_SEM_LINKS个语义相关节点作为它的语义邻居;同时从随机邻居cache中随机选择MAX_RND_LINKS个节点作为随机邻居。对于语义邻居,起始节点会将它们按照语义相关度的数值从高到低进行排序。
在邻居维持部分,其任务就是从邻居候选cache中选择新的邻居以及保持现有符合要求的邻居。每个节点会周期性地从它的语义邻居cache中选择新的语义邻居来更新它的语义邻居连接,其算法为adapt_sem_neighbors(),需要注意的是,当语义相关度数值大于或等于门限值REL_THRESHOLD的节点数大于最大语义邻居连接数MAX_SEM_LINKS时,起始节点将选择相关度最高的前MAX_SEM_LINKS作为新的语义邻居。同理,节点的随机邻居数也不能超过MAX_RND_LINKS。节点的邻居重新连接后,每个节点根据语义相关度的数值从高到低对语义邻居进行排序。在图1中,给出了邻居拓扑调整与维持的伪代码。

图1 邻居调整与维持的伪代码
4.3 搜索协议
SKIP资源搜索定位查询算法的主要思想简言之就是:优先搜索查询语义相关度最高的那部分节点。
当一个节点发起查询请求时,首先使用biased_walk()函数找到语义目标节点,然后再发起SKIP查询,具体如下。
用M(M≤MAX_SEM_LINKS)来表示某一个节点的语义邻居个数,然后将该节点的所有语义邻居按照之前网络拓扑构建时计算出来的节点之间的语义相关度数值进行排序,排序的规则是按节点之间语义相关度数值从高到低进行排序。排完序之后,将这些语义邻居按照语义相关度数值由高到低平均分成m个子组。当查询消息找到语义目标节点后,就是从目标节点语义相关度最高的一个子组,即语义相关度数值最高的[M/m]个语义邻居(在这里[]表示高斯取整函数)开始继续进行资源搜索定位查询。
资源搜索定位查询消息每转发一次,其生命周期TTL的数值将被减去1,当TTL=0时,资源搜索定位查询消息将不再转发,而被直接丢弃。如果通过第一个子组的语义最相关的[M/m]个语义邻居的查询后,仍然没有满足要求,那么目标节点将会从第二个语义子组开始转发资源搜索定位查询消息,直到搜索查询到的满足要求;若仍然无法满足源节点的资源搜索查询请求,将从第3个子组继续往下搜索查询;以此类推。
值得注意的是,资源搜索定位查询消息每往下转发一次,相当于往下一层迭代了一次,因为在下一层的每一个节点,同样地将会把自己的语义邻居节点按照语义邻居节点之间的语义相关度数值进行排序,排序的规则是从高到低。在对该节点的所有语义邻居按照之前网络拓扑构建时计算出来的节点之间的语义相关度数值排完序之后,将这些语义邻居按语义相关度数值由高到低平均分成m个子组。资源搜索定位查询消息将会按照语义相关度数值最高的[M/m]个语义邻居优先选择的机制,在下一层语义邻居节点中继续查找,一旦找到满足源节点要求数量的语义相关资源时,查询立即终止。图2是biased_walk()和SKIP资源搜索定位查询算法的伪代码。
如图3所示,以语义子组数m=2,最大语义邻居链接数MAX_SEM_LINKS=4为例,介绍一下搜索路径。圆形节点为语义相关的语义邻居,方形节点为语义不相关的随机邻居。当查询消息找到语义相关的目标节点X后,该资源搜索定位查询消息将会用式(3)、(4)计算节点X中的每一个资源文档与这个资源搜索定位查询消息的语义相关度。虚线是语义相关度最高的子组,黑体实线是语义相关度次高的子组,首先会从虚线子组开始查询,若查询到的结果满足要求,查询终止;若不满足,则从黑体实线子组继续查询。

图2 搜索协议伪代码
5 仿真结果
在测试数据的选取上,使用TREC[19]作为仿真实验中的测试数据。TREC是一个在信息资源检索领域广泛使用的标准数据集。在仿真实验中,主要采用查准率(即最大相关资源数/获取总的相关资源数)和查询开销(即访问节点数)作为实验的性能指标来衡量SKIP搜索算法的优势。
表1中列出了相关实验参数的设置。
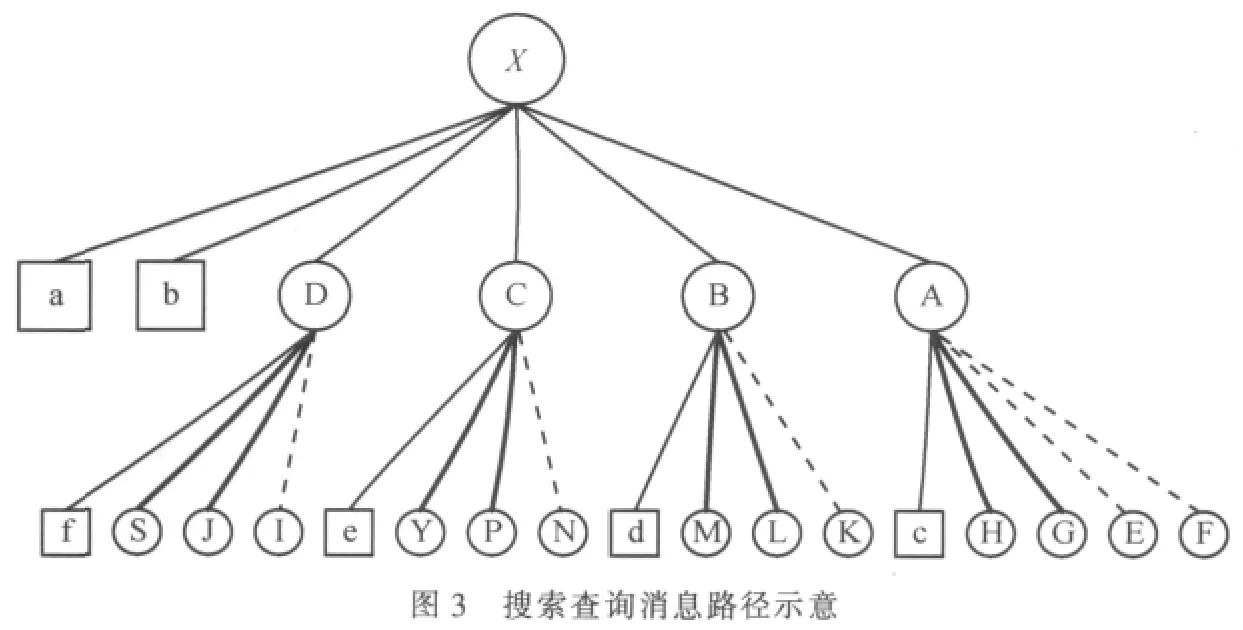
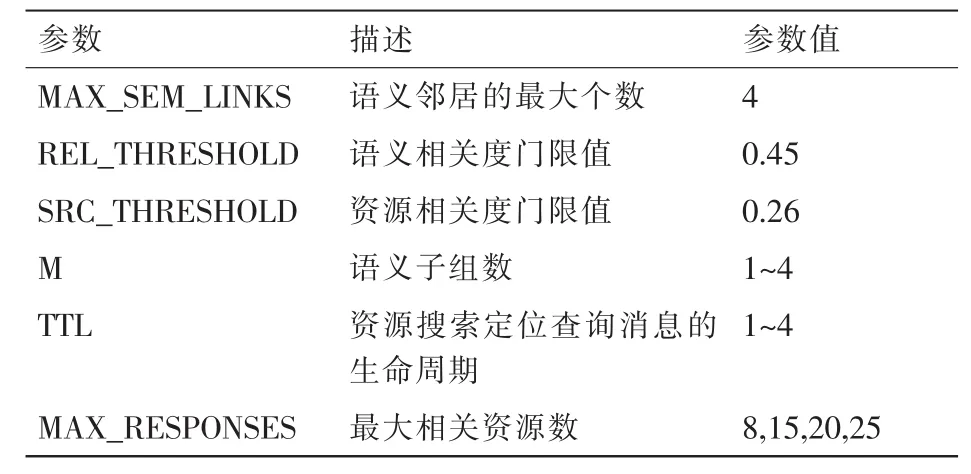
表1 搜索策略仿真实验参数
仿真实验结果如图4、图5所示。GES方式只对应m=1时情况。SKIP搜索方式对应m=1,2,3,4时的情况

从图4中可以清楚地看到,对于同样的资源搜索定位查询消息生命周期TTL值,当语义子组参数m的值从1递增到4时,GES搜索查询算法的查准率是最低的。而对于SKIP资源搜索定位查询算法来说,m的值越大,查准率越高。换句话说,随着语义子组数的增加,也就是m值的增加,SKIP资源搜索定位查询算法将使用更小的粒度来进行优先选择搜索,因此,其资源的查准率也将越高。
从图5中可以清楚地看到,当TTL的值较小(TTL=1以及TTL=2)时,SKIP算法与GES算法的查询开销的差别不是太大。但是,当TTL的值增加时,GES的开销迅速上升,而SKIP算法的查询开销却仍然保持在一个较低的状态。换句话说,GES查询消息在资源搜索时,访问了大量的节点,造成了巨大的开销;反观SKIP查询算法,在完成相同的查询任务的情况下,极大地减少了查询消息对于节点的访问量,减小了搜索查询的开销。
综上所述,SKIP查询算法与GES查询算法相比,优先选择语义相关度更高的部分语义邻居节点进行搜索定位查询,具有更好的资源查准率和更低的查询开销。
6 结束语
在本文中,提出了SKIP资源搜索算法,由于其采用优先选择与层层迭代的方式,具有很高的查询效率和较低的查询开销。仿真实验也显示了SKIP在查准率和查询开销方面优于GES。将来,笔者还要考虑异构环境下的拓扑构建和搜索策略。
1 Risson J,Moors T. Survey of research towards robust peer-to-peernetworks:search methods.ComputerNetworks,2006,50(17):3 485~3 521
2 Gnutella 0.6.http://rfc-gnutella.sourceforge.net/src/rfc-06-draft.html
3 Yang B,Garcia-Molina H.Improving search in peer-to-peer networks.Proceedings of the ICDCS 2002,Vienna,Austria,2002:5~14
4 Lv Q,Cao P,Cohen E.Search and replication in unstructured peer-to-peer networks.Proceedings of 16th ACM Ann Int’l Conf Supercomputing(ICS),New York,USA,2002:84~95
5 Cohen E,Kaplan H,Fiat A.Associative search in peer-to-peer networks:harnessing latent semantics.Proceedings of IEEE INFOCOM,2003,2(4):1 261~1 271
6 SpripanidkulchaiK,MaggsB,Zhang H.Efficientcontent location using interest-based locality in peer-to-peer systems.Proceedings of IEEE INFOCOM,2003,3(3):2 166~2 176
7 Bawa M,Manku G,Raghavan P.SETS:search enhanced by topic segmentation.Proceedings of26th Ann Int’l ACM SIGIR Conf,Toronto,Canada,2003:306~313
8 Zhu Y,Hu Y.Enhancing search performance on gnutella-like P2P systems.IEEE Transactions on Parallel and Distributed Systems,2006,17(12):1 482~1 495
9 Guo L,Jiang S,Xiao L,et al.Exploiting content localities for efficient search in P2P systems.Proceedings of 18th Ann Conf Distributed Computing (DISC’04),Amsterdam,Netherlands,2004
10 Berry M W,Drmac Z,Jessup E R.Matrices,vector spaces,and information retrieval.SIAM Review,1999,41(2):335~362
11 Ratnasamy S,Francis P,Handley M,et al.A scalable content addressablenetwork.ProceedingsofACM SIGCOMM,San Diego,CA,USA,2001:161~172
12 Rowstron A,Druschel P.Pastry:scalable,distributed object location and routing for large-scale peer-to-peer systems.Proceedings of the 18th IFIP/ACM International Conference on Distributed System Platforms (Middleware), Heidelberg,Germany,2001:329~350
13 Stoica I,MorrisR,KargerD,etal.Chord:a scalable peer-to-peer lookup protocol for internet applications.IEEE/ACM Transactions on Networking,2003,11(1):17~32
14 Crespo A,Garcia-Molina H.Routing indices for peer-to-peer systems.Proceedings of the 22nd International Conference on Distributed Computing(IEEE ICDCS’02),Vienna,Austria,2002
15 Crespo A,Garcia-Molina H.Semantic Overlay Networks for P2P Systems.Technical Report,University of Stanford,May 2004
16 Risson J, Moors T.Survey of research towards robust peer-to-peernetworks:search methods.ComputerNetworks,2006,50(17):3 485~3 521
17 HuangJ,LiX,Wu J.A class-based search system in unstructured P2P networks.Proceedingsofthe IEEE 21st International Conference on Advanced Information Networking and Applications,2007:76~83
18 Guo L,Jiang S,Xiao L,et al.Fast and low cost search schemes by exploiting localities in P2P networks.Parallel and Distributed Computing,2005,65(6):729~742
19 Text REtrieval Conference(TREC).http://trec.nist.gov
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·高一版(2021年11期)2021-09-05
开放教育研究(2020年2期)2020-03-31
通信产业报(2020年43期)2020-01-15
现代防御技术(2016年1期)2016-06-01
现代语文(2016年21期)2016-05-25
新高考·高一物理(2016年1期)2016-03-05
大连民族大学学报(2015年2期)2015-02-27
中国卫生(2014年12期)2014-11-12
中国卫生(2014年8期)2014-11-12
