
一种改进的LPCC参数提取方法研究
2012-09-27 01:42:20王彪
电子设计工程 2012年6期
王彪
(宝鸡文理学院 数学系,陕西 宝鸡 721013)
一种改进的LPCC参数提取方法研究
王彪
(宝鸡文理学院 数学系,陕西 宝鸡 721013)
为了提高语音信号的识别率,提出了一种改进的LPCC参数提取方法。该方法先对语音信号进行预加重、分帧加窗处理,然后进行小波分解,在此基础上提取LPCC参数,从而构成新向量作为每帧信号的特征参数。最后采用高斯混合模型(GMM)进行说话人语音识别,实验表明新特征参数取得了较好的识别率。
特征提取;小波变换;分解;LPCC参数;语音信号
语音识别技术是新世纪一门十分热门的技术,涉及多个领域,在社会生活中具有举足轻重的重要意义。而语音信号特征参数又是语言识别领域的重中之重,选取良好的特征参数有助于提高语音识别率。
语音信号是一种短时平稳信号,即时变的,十分复杂,携带很多有用的信息,这些信息包括语义、个人特征等等,其特征参数的准确性和唯一性将直接影响语音识别率的高低,并且这也是语音识别的基础。
小波分析具有多分辨率分析的特点,在时频两域都具有表征信号局部特征的能力,很适合探测正常信号中夹带的突变和噪声,成为信号处理的重要工具之一。
为提高语音识别率,本文应用小波分析的特点,提出了一种改进的语音信号LPCC参数提取方法。本文方法先对语音信号进行预加重、分帧加窗处理,然后进行小波分解,在此基础上求取LPCC参数,以此作为列向量,构成一个新向量作为语音信号的特征向量,以此表征每帧信号。本文方法提取的特征参数具有唯一性,且是数字化的,在一定程度上提高了语音信号的识别率。
1 LPCC参数
线性预测倒谱参数[1](LPCC)是线性预测系数(LPC)在倒谱域中的表示。该特征是基于语音信号为自回归信号的值时,利用线性预测分析获得倒谱系数。该特征是基于语音信号为自回归信号的值时,利用线性预测分析获得倒谱系数。LPCC参数的优点是计算量小,易于实现,对元音有较好的描述能力,其缺点在于对辅音的描述能力差,抗噪声性能较差。
由于通过自相关法求得的LPC系数保证了系统的稳定性,使得下面式(1)所对应的声道模型传输函数具有最小相位。

利用这一特点,可以推导出语音信号的倒谱c(n)和LPC系数之间的递推关系:
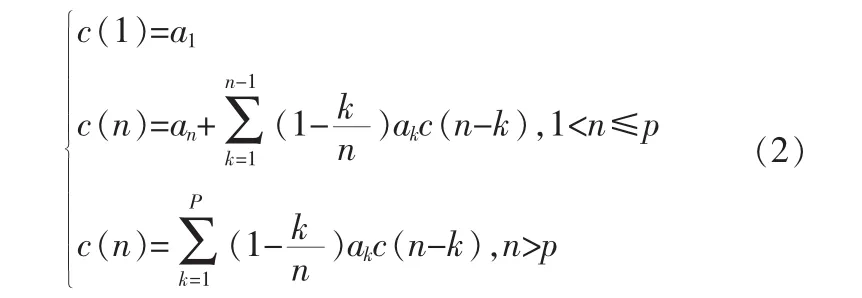
或是由LPC得到:

根据同态处理的概念和语音信号产生的模型,语音信号的倒谱c(n)等于激励信号的倒谱(n)与声道传输函数的倒谱(n)之和。通过分析激励信号的语音特点以及声道传输函数的零极点分布情况,可知(n)的分布范围很宽,c(n)从低时域延伸到高时域,而(n)主要分布于低时域中。语音信号所携带的语义信息主要体现在声道传输函数上,因而在语言识别中通常取语音信号倒谱的低时域构成LPC倒谱特征c,即:
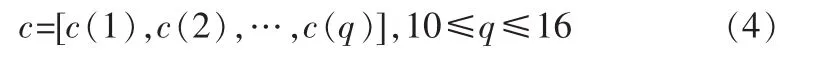
式中,q为LPC倒谱特征的阶数。
2 小波分析
小波分析是一种将窗口大小固定不变,而其形状可变,且时间窗和频率窗都可以改变的时频局部化分析方法。小波分析对非平稳信号具有很好的自适应性,这是因为其具有在高频部分有较高的时间分辨率及较低的频率分辨率,而在低频部分有较高的频率分辨率及较低的时间分辨率的特性。小波分析发展了传统的傅立叶变换思想,对非平稳信号具有更好的分析能力。
设ψ(t)∈L2(R),(L2(R)为平方可积的实数空间),其傅里叶变换为(ω)。 当(ω)满足允许条件(Admissible Condition):
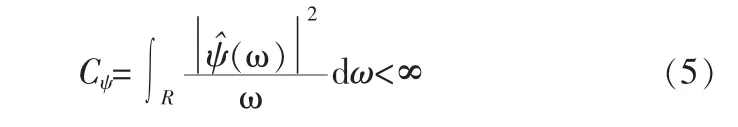
时,称ψ(t)为一个母小波(Mother Wavelet)。将母函数ψ(t)经伸缩和平移后,可得到一个小波序列。
对于连续的情况,小波序列为:
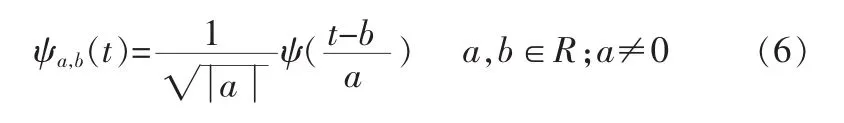
其中,a为伸缩因子,b为平移因子。
对于离散的情况,小波序列为:
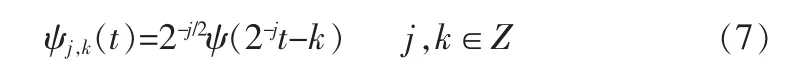
3 改进的LPCC参数提取
改进的LPCC参数[3]提取过程如下:
1)对语音信号进行预加重、分帧加窗处理。
预加重:为便于对语音信号进行频谱分析或声道参数分析,需要对其进行预加重处理。一般地,通过一个一阶的预加重数字滤波器来实现预加重处理,其传递函数为:

其中,u为预加重滤波器的系数,其取值范围是0.94~0.97。
分帧加窗:由于语音信号是一种典型的非平稳信号,其特性是随时间变化的。为便于对其进行分析,要将其分成一段一段的,每段信号称为一帧,每帧长度一般为10~30 ms,认为在这个小时间段内语音信号是平稳的。我们用加窗函数来将语音信号进行分帧处理。
2)对每帧信号进行3层小波分解,提取第3层各结点的小波系数,依次记为:s1、s2、s3、s4、s5、s6、s7、s8。
3)对 s1、s2、s3、s4、s5、s6、s7、s8 分别求取 8 阶 LPCC 参数,参数向量记为 d1、d2、d3、d4、d5、d6、d7、d8。
4)将 d1、d2、d3、d4、d5、d6、d7、d8 作为列向量,构成一个新向量T,即:

将T作为语音信号的特征向量,以此表征每帧信号。
改进的LPCC参数提取过程如图1所示。

图1 改进的LPCC参数提取过程图Fig.1 Improved LPCC parameter extraction process Graph
4 仿真实验
采用高斯混合模型(GMM)进行说话人语音识别,以验证新特征参数的效果。将GMM应用于说话人识别的直观解释是[4]:每个说话人的语音声学特征空间可以用一些声学特征类来表示,这些声学特征类代表一些广义上的音素,如元音、清辅音、摩擦音等,并且能够反映说话人的声带形状。
录制5个人的语音,每人录制3句话:“今天”、“我是大学生”。语句逐渐复杂,从而能够更好验证新特征参数的效果。分别提取语音信号的传统LPCC参数和本文提出的新特征参数,并分别建立GMM模型进行测试。测试时,对语音信号进行染噪处理,分别对每个语音以信噪比0 dB、5 dB加入噪声,在计算相似度之后,进行规范化,最后得出每个语音的识别率结果。下表是语音信号在不同信噪比下的识别率。

表1 语音信号在不同信噪比下的识别率Tab.1 Speech signal in different signal to noise ratio of recognition rate
从上表可以看出:在不同噪声环境下,如给语音分别以信噪比0 dB、5 dB加噪时,采用本文方法进行语音识别得到了比传统LPCC参数方法更高的识别率。这说明本文方法能在一定程度上提高说话人的语音识别率,基本能够达到预期的目的。
5 结束语
首先介绍了语音信号的传统LPCC参数[5];其次叙述了小波分析;再次以此为基础,提出了一种新特征参数的提取方法;最后通过GMM模型进行说话人识别,在不同噪声环境下,分别对语音信号按传统LPCC参数[6]方法和本文方法进行实验,实验表明新特征参数取得了较好的识别率。
当然,本文还有一定的不足之处,如:能否更加精细、更加准确的特征参数T。这是今后工作中亟待解决的问题。
[1]王炳锡,屈丹,彭煊,等.实用语音识别基础[M].北京:国防工业出版社,2005.
[2]胡昌华,李国华,刘涛,等.基于MATLAB 6.X的系统分析与设计——小波分析[M].2版.西安:西安电子科技大学出版社,2004.
[3]陈杰,张玲华,吴玺宏.基于小波包一LPCC的说话人识别
特征参数 [J].南京邮电大学学报:自然科学版,2007,27(6):54-56.
CHEN Jie,ZHANG Ling-hua,WU Xi-hong. Feature extraction based on waveletPacket-LPCC in speaker recognition[J].Journal of Nanjing University of Post and Telecommunications:Natrtal Science,2007,27(6):54-56.
[4]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[5]荣薇,陶智,顾济华,等.基于改进LPCC和MFCC的汉语耳语音识别[J].计算机工程与应用, 2007,43(30):213-216.
RONG Wei,TAO Zhi,GU Ji-hua,et al.Identification of Chinese whispered speech based on modified LPCC and MFCC[J].Computer Engineering and Applicafiom,2007,43(30):213-216.
[6]余建潮,张瑞林.基于MFCC和LPCC的说话人识别[J].计算机工程与设计,2009,30(5):1189-1191.
YU Jian-chao,ZHANG Rui-1in.Speaker recognition method using MFCC and LPCC features[J].Computer Engineering and Design,2009,30(5):1189-1191.
An emproved LPCC parameter extraction method research
WANG Biao
(Mathematics Department,Baoji University of Arts and Sciences,Baoji721013,China)
In order to improve the speech recognition rate,an improved LPCC parameter extraction method is proposed.First the pre-emphasis, frames and windows processing is conducted to speech signal in the method,then wavelet decomposition is used, the LPCC parameter is extracted on the basis,thus a new vector is formed as each frame signal characteristic parameter.Finally, the Gauss mixed model (GMM) is used for speaker speech recognition, and experiment shows that the new characteristic parameters obtaines better recognition rate.
feature extraction;wavelet transform;decomposition;LPCC parameter;speech signals
TP311
A
1674-6236(2012)06-0029-02
2012-01-02稿件编号:201201004
宝鸡文理学院院级重点项目(ZK11127)
王 彪(1982—),男,天津人,硕士,助教。研究方向:信号处理。
book=33,ebook=357
猜你喜欢
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
计算机工程(2020年3期)2020-03-19 12:24:50
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
中国交通信息化(2018年3期)2018-06-13 03:27:58
制造技术与机床(2017年11期)2017-12-18 06:46:39
