
基于网页正文逻辑段落和长句提取的网页去重算法
2012-09-25 10:09:34张小娣宋余庆
图书情报研究 2012年2期
张小娣 宋余庆
(江苏大学科技信息研究所 镇江 212013)
·信息检索·
基于网页正文逻辑段落和长句提取的网页去重算法
张小娣 宋余庆
(江苏大学科技信息研究所 镇江 212013)
网页去重是提高网络检索效果的有效途径。针对现有网页去重算法的不足和网页正文的结构特征,提出一个基于网页正文逻辑段落和长句提取的网页去重算法。该方法通过用户检索关键词将网页正文物理段落结构表示成逻辑段落,在此基础上提取逻辑段落中的长句作为网页特征码实现相似网页判断。实验证明,该方法提高了篇幅短小的镜像网页和近似镜像网页的去重效果。
网页去重 逻辑段落 长句提取 句子相似度
1 引言
近年来,由于网络和信息技术的快速发展,网络资源日益丰富,互联网上的信息快速增长。根据中国互联网络信息中心2011年1月的统计报告[1],自2003年开始,中国的网页规模基本保持翻番增长,2010年网页数量达到600亿个,年增长率78.6%。网页的规模说明了互联网内容的丰富程度,用户面对如此海量的信息,利用搜索引擎进行信息检索已经成为一个重要途径。报告显示“2010年,搜索引擎用户规模3.75亿,……搜索引擎在网民中的使用率增长了8.6个百分点,达81.9%,跃居网民各种网络应用使用率的第一位”[1]。搜索引擎已经成为网民上网的主要入口,国内各大搜索引擎运营厂商不断提高其服务能力和水平。但用户在搜索信息的时候常常会发现,返回结果中存在大量重复信息。为提高搜索引擎的检索效率,减轻用户获取有效信息的时间和成本,甄别和去除重复网页是一个有效途径。
目前我国对于相似网页检测算法的研究有:基于全文分段匹配的去重算法[2];基于网页关键词的去重算法[3,4];基于网页特征码的去重算法[5-7];基于链接的去重算法[8,9];基于网页结构的去重算法[10];基于长句提取的网页去重算法[11];基于语义的网页去重算法[12]等。现有的技术从不同角度解决网页重复问题,按照网页特征码提取的粒度可以分为三类:①基于词级别的粒度进行特征提取[3];②基于多个词组成的特征串和基于长句进行特征提取[7];③基于段落或整篇网页内容进行特征提取[2]。由于互联网上存在海量信息,重复网页的辨别不仅需要考虑精度也需要考虑速度。网页特征码的粒度越小计算速度越慢,粒度越大计算速度越快。基于词级别的粒度比较小,对于大规模信息检索实用性不强;基于整篇网页内容的粒度最大,虽然速度快,但是对正文细微的区别无法辨别,精度不高。近年来提出的网页去重算法采用一种折中的方法,如基于网页正文结构的网页去重算法和长句提取的去重算法。基于网页正文结构去重算法的基本原理是将网页文本的自然段编号,使用该编号代替自然段本身生成一棵目录结构树,并通过目录结构的相似程度来判断网页的重复程度。该方法在很大程度上节省了时空开销,适用于大规模的相似度计算;但是对于无小标题式文本,该算法就演变为按自然段进行分段签名;对于自然段中有丢字、加字但是主题内容相同的重复网页则无法检测出来。长句提取去重算法的思想是:首先提取网页正文中所有长句中字数最多的m个句子。不足m个句子的网页,保留所有的长句。然后对每个句子进行摘要,将得到的摘要值组成向量集合作为网页指纹进行相似度判断。该算法缺点是:当网页正文内容较少时,该算法则演变为基于整篇网页内容进行去重,因此该算法对于篇幅短小的网页内容去重无能为力。基于上述分析,本文提出了一种基于网页正文逻辑段落和长句提取的网页去重算法。
2 网页正文逻辑段落划分
目前基于网页正文结构的网页去重算法针对的是传统的物理段落,即依照自然段作为划分依据,给各个段落按照在正文中层次的不同赋予不同的权值,进而使用这些段落进行相似匹配,这种方法带有一定的机械性。如果物理段落中包含的信息过少,容易导致特征词数较少,则无法表征该网页内容,容易出现匹配率较低的现象。因此,本文以用户查询关键词为基础,建立了一种以用户查询关键词为中心的逻辑段落结构,在此基础上提取逻辑段落中的长句作为网页特征码实现相似网页判断,提高网页去重效果。
2.1 涉及到的中文分词策略
本文采用基于多层隐马模型的汉语词法分析系统ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System ),该系统由中国科学院计算技术研究所研制,具有中文分词、未登录词识别等功能。分词策略为:首先将专有名词切出,剩下的部分采取双向分词策略。如果两种分词策略结果相同,则直接输出结果;如果结果不一致,则输出最短路径的那个结果。将用户输入的关键词保存在集合K中,把K中的关键词进行分词,将结果存放在集合T中,T={t1,t2,…,tn}。
2.2 逻辑段落划分
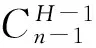
逻辑段划分算法描述:
定义1:网页正文内容预处理即经过分词后过滤掉没有实际意义的虚词和停用词。
定义2:V表示网页正文内容经过分词、预处理后剩下的实词集合;Vt表示检索关键词。
定义3:P表示网页正文第i个自然段经过分词后实词集合的个数。
定义4:假设网页正文有m个自然段,则Vim表示从第i个自然段到第m个自然段之间经过分词后的实词集合。
定义5:定义V和Vi的笛卡尔乘积如下:
V·Vi+1=∑wiwk(0≤i≤P-1,0≤k≤Pi)
输入:经过去噪后的网页正文。
输出:包含了逻辑段划分信息的text。
处理过程:
(1)去噪后的网页正文处理成原始自然段集合Natual(),假设共有m个自然段;
(2)每个自然段经过分词处理后得到一个包含实词的二维集合PreNatual();
(3)统计包含查询关键词的词段i;
(4)初始化index,提取逻辑段边界。
分析:①若i=0,则把Natual(i)加入text中,并提取该逻辑段的查询关键词,index=i;否则,i=i+1。
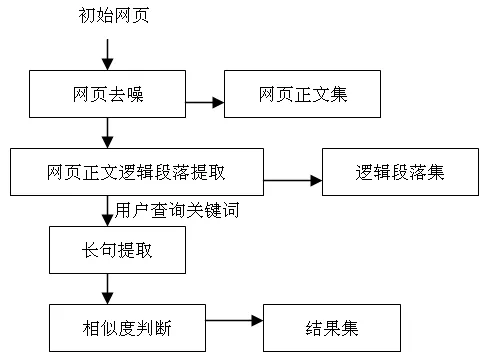
②若0 ③若i=m-1,提取该逻辑段的查询关键,并把Natual(i)加入text中;否则,把Natual(index+1)至Natual(i)加入text中。 句子是话语的最小单位,却是语言的最大单位,若干句子组成段落。句子既有组篇功能也有表意功能。长句能够很好地表征网页。首先,长句作为网页特征可以保证不容易重复。中文常用字有6700多个,任意两个句子重复的概率约为1/(6700k),当k的值较大时,重复的概率非常低。另外,相对于完整的段落,句子要短很多,被干扰的概率也较低。本文的长句有别于语法上定义的用句号分隔的句子,将长句定义为长度不少于k个字的句子。如果网页正文较长,能提取的长句可能很多。为了减小存储特征空间,仅保留所有长句中最长(字数最多)的m个句子;对于不足m个句子的网页,保留所有的长句。然后使用MD5算法计算这些长句的摘要,将这些摘要作为网页的特征。MD5算法可以把任意长度的数据作为输入,然后产生一个128比特(16字节)的摘要作为输出。根据多次试验设定长句k值取9,即每个句子至少9个汉字(16个字节),如果字数太多的话,特征易受干扰;字数太少,网页特征表征性不高。根据MD5算法,即使超出8个汉字的长句也能用16个字节来表示,因此可以节省存储空间。如上所述,一张网页的特征可以定义为: 其中,S为该网页的长句集合,|S|表示集合中长句的数量。 4.1 系统设计 本系统由四个模块组成。网页去噪模块使用参考文献13的算法[13]实现,即将HTML文档看作字符和标签组成的序列,通过对HTML标记进行统计,最后生成只含有主题内容的HTML文档;网页正文逻辑段落提取模块使用前文介绍的算法实现;长句提取模块使用前文介绍的长句提取算法实现;相似度判断模块使用下面介绍的双层相似度计算方法。 图1 网页去重系统图 4.2 相似度判断 本文将网页相似度的计算划分为2个层次,包括句子与句子的相似度计算、段落与段落之间的相似度计算。 (1)句子相似度计算如下: 两个句子的相似度由词形相似度和词序相似度决定,词形相似度起主要作用,词序相似度起次要作用。因此句子A、B相似度表示为: Sim(A,B)=λ1·WordSim(A,B)+λ2·OrdSim(A,B) 其中,λ1,λ2为常数,且λ1+λ2= 1,相似度的数值在0~1之间,数值越接近1则相似度越低。相似句子查找算法描述如下: 输入:Input, InTab, LenTab, corpora; 输出:相似句S; for each word in Input; 计算非零的SameWC(Input, S); 根据LenTab计算SameWC(Input,S)排在前K1句子的WordSim(Input, S); 根据corpora计算WordSim(Input, S)的OrdSim(Input, S); 输出最相似句。 (2)段落相似度的计算过程如下: 段落相似度是由句子相似度计算出的,设两个段落分别为t1、t2,sm、sn为段落中的句子,则段落表示如下: t1= {s11,s12,…, s1m} t2= {s21,s22,…, s2n} 实验网页集来源于人工收集的1500篇网页,其中包括1000篇不相同网页,完全重复的网页和部分重复的网页数目分别是205篇和295篇,调用本文去重算法对网页测试集进行实验,算法的评价指标使用查全率(Recall)、查准率(Precision)和响应时间。 通过与现有的一些去重算法进行比较,实验结果如表1所示。 表1 同现有去重算法比较 图2 响应时间 从实验结果可以看出: (1)基于正文逻辑段落和长句去重算法去重的精确率和查全率都能达到99%以上,去重效果较好,表明该算法采用的特征码能有效的代表网页信息。基于正文结构树算法提取的网页特征是自然段,提取粒度大,干扰信息多,因此查全率相对较低;基于长句提取算法提取的特征粒度是长句,对于篇幅短小的网页正文则变为基于整篇网页内容的特征提取,查全率较低;基于正文结构和长句提取算法提取网页正文的物理段落,对于没有段落标识符的网页则无法提取段落结构,因此查准率相对较低。 (2)从响应时间图可以看出,特征码数目越多,算法所需时间就越多。在特征码一定时,特征码的长度越长,所需比较时间越长。从空间效率上来讲本算法能够满足大规模网页去重的要求,具有实用价值。 本文提出并设计了一种以用户查询关键词为中心,基于网页正文逻辑段落算法和长句提取算法的一种新的网页去重算法。该算法不仅解决了正文中添加信息的近似镜像网页的去重,还增强了篇幅短小网页的去重效果。试验表明,该方法相对于基于正文结构树算法[10]和长句提取算法有更高的查全率和查准率,可以很好地辅助搜索引擎对搜索结果进行过滤。 [1] 中国互联网络信息中心. 中国互联网络发展状况统计报告:2011年1月[R/OL]. [2011-04-12]. http://www.cnnic.net.cn/dtygg/dtgg/201101/P0201101193289 60192287.pdf. [2] 彭曙蓉. MD5算法在消除重复网页算法中的应用[J]. 电脑知识与技术,2005(29):15-16. [3] 谢 蕙. 基于用户查询关键词的网页去重方法研究[J]. 现代图书情报技术,2008(7):43-46. [4] 樊 勇. 基于主题的网页去重[J]. 电脑开发与应用,2008(4):4-6. [5] 姚新波. 基于特征串的网页去重算法[J]. 科技信息,2008(28):411. [6] 王 哲. 基于特征码的网页去重算法研究[J]. 山东电大学报,2009(1):14-16. [7] 吴平博. 基于特征串的大规模中文网页快速去重算法研究[J]. 中文信息报,2003(2):28-35. [8] 龚秋艳. 简单高效的URL消重的方法[J]. 计算机应用,2010(1):49-50. [9] 高 凯. 网页去重策略[J]. 上海交通大学学报,2006(5):775-777. [10] 魏丽霞. 基于网页文本结构的网页去重[J]. 计算机应用, 2007(11):2854-2856. [11] 黄 仁. 基于正文结构和长句提取的网页去重算法[J]. 计算机应用研究,2010(7): 2489-2491. [12] 樊 勇,郑家恒. 网页去重方法研究[J]. 计算机工程与应用,2009(12):141-143. [13] 刘艳敏. Web页面主题信息抽取研究与实现[J]. 计算机工程与应用,2006(12):146-148. DetectionandEliminationofSimilarWebPagesBasedonLogicalParagraphsandExtractionofLongSentences Zhang Xiaodi, Song Yuqing Institute of Science and Technology Information of Jiangsu University, Zhenjiang 212013, China The technology of detection and elimination of similar web pages is an effective way to improve the effect of network retrieval. Because of the inadequacy of algorithm and the structural features of webpage texts, an algorithm, based on logical paragraphs and extraction of long sentences to detect and delete similar web pages, is proposed in this paper. Through retrieval keywords, this method expresses webpage’s physical paragraph structures as logical paragraphs. Based on that, long sentences are extracted from logical paragraphs as similar characteristics code of webpages. The experiment results show that this method can improve the effectiveness of short webpages and eliminating similar webpages in retrieval. detection and elimination of similar web pages; logical paragraphs; extraction of long sentences; sentence similarity TP391 张小娣,女,1979年生,硕士研究生,研究方向:搜索引擎,发表论文1篇;宋余庆,男,1959年生,教授,博导,主要研究方向:信息安全、医学图像处理,发表论文数篇。3 长句提取算法
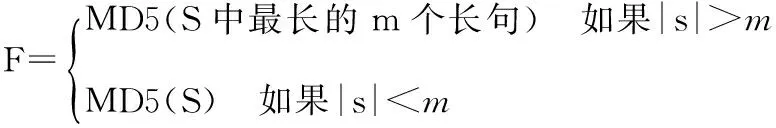
4 基于网页正文逻辑段落和长句提取的网页去重算法
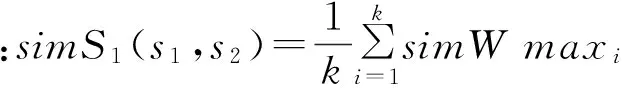
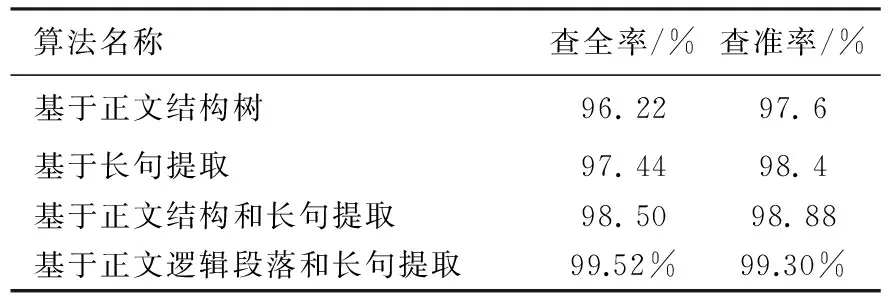
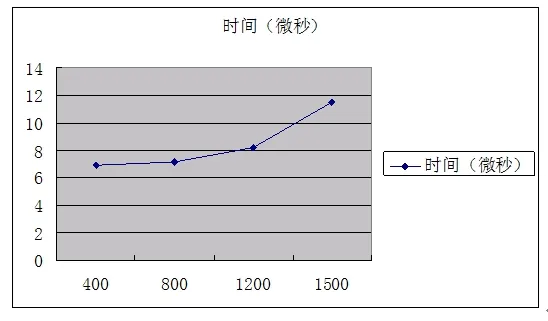
5 实验结果和分析
6 结论
猜你喜欢
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
智富时代(2019年6期)2019-07-24 10:33:16
散文诗(2017年17期)2018-01-31 02:34:11
高中生·天天向上(2016年9期)2016-11-22 09:10:34
高中生·天天向上(2016年5期)2016-11-21 05:44:58
现代语文(2016年21期)2016-05-25 13:13:46
读写算(下)(2016年11期)2016-05-04 03:44:07
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
——意群—动态对等法
长春大学学报(2012年9期)2012-09-19 08:00:00
