
一种先进运动估计算法的硬件实现
2012-09-19 01:31江飞,杨奕,杨兵
电子与封装 2012年6期
江 飞,杨 奕,杨 兵
(中国电子科技集团公司第58研究所,江苏 无锡 214035)
1 引言
视频压缩是数字视频信号传输和储存的必要手段,一般我们采用基于预测和变换的混合编码技术,它们在H.261、H.262、H.263和MPEG-1、MPEG-2、MPEG-4标准中已经被采纳。在这种编码技术中运动估计占有很重要的地位,也耗费了视频编码中大部分的计算时间。通常能够得到精确和平滑的运动场矢量的运动估计方法都比较复杂,如光流场运动估计、贝叶斯运动估计、基于小波的分层估计,甚至基于全搜索的块匹配法等,需要大量的计算时间,并不适合实际的软件和硬件实现。而一些在实际中经常采用的快速运动估计方法如快速块匹配法(三步法、四步法、菱形搜索法)基本可以满足实际视频显示的效果,并且在硬件方面也较容易实现。本文介绍的就是一种基于快速块匹配法的硬件实现。
2 MEP设计目标
六种工作模式如表1所示。
RW支持掩模:即在有掩模的区域不作运算。
在最大的模式(64×64 →128×128)下,运算时间不超过5ms(工作频率为33MHz)。
输出全部的运算结果及其最小的三个值和相应的坐标。
设计定义如下:
PW:Peak Window(顶点窗,顶点区域);RW:Reference Window(参考窗);SW:Search Window(搜索窗);PE:Processor Element(处理单元)。
SW及RW中坐标的定义如图1。

表1 工作模式

图1 RW和SW坐标定义
Error(i,j):对应(i,j)顶点的运算结果(本文的结果、运算结果都是Error)。
3 MEP算法原理
为了使256个PE能全部高效运作,并行算法的设计成了本项目目标能否实现及芯片性能的关键。用户的要求是遍历整个搜索窗口,并且找出3个最优值及其坐标,这决定了我们对每个顶点都要作运算,运算的数学表达式为:ΣΣ|SW(i,j)-RW(i,j)|。
3.1 RW(16×16)→SW(32×32)的并行运算
SW顶点区域为X(0~5),Y(0~15),即在SW的左上角区域内。每个PE计算一个顶点,各个PE并行运算,使用流水线技术实现数据的复用以确保各PE的独立运行。
如图2所示,RW的数据按先X方向后Y方向的顺序滚入PE;同时SW中的数据按先X方向后Y方向的顺序滚入PE。在PE同时收到RW与SW后进行已定义好的运算操作,并在下一个时钟周期将RW的数据向下一个PE进行传播。而SW的数据是在数据总线上按一定的顺序进行传播,也就是有多个PE同时接收一个SW的数据。RW的数据全部滚入PE1起的下一个周期开始输出误差结果Error并进行冒泡排序,在RW(15,15)到达PE256时,全部数据输入完成,并且除去最后一个数外,其他255个顶点计算完毕;再过一个周期,排序完毕。总共需256+256+1=513个周期来完成全部的顶点运算及结果排序。

图2 PE排列结构
3.2 冒泡排序算法
如图3所示,首先将三个排序结果寄存器全部置1,将对应的坐标寄存器清零;然后将Error传播到三个比较器与各自先前的值比较,若Error小则将Error送入自身的寄存器,并将对应的Error的坐标送入坐标寄存器;再指定优先级,若优先级为1,则将Error送入自身的寄存器,并将对应的Error的坐标送入坐标寄存器;最后返回2,直到排序结束。

图3 排序结构
3.3 PE结构
如图4所示。只要将SW'中的数据按upper、lower组织好,即可实现对SW'中数据的复用。在第二次加载RW(0,0)时,SW'正在读入SW'(0,16),它也正是PE需要的数据。Counter为12bit,其余的reg为8bit。
4 MEP的RW掩模
掩模位单独载入,每位掩模位对应唯一的PE,它不随时钟传播,它只随时钟每次对一个PE进行载入。

图4 内在结构
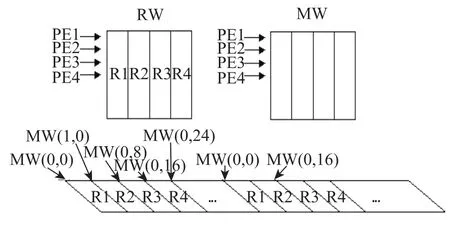
图5 RW掩模
如果RW为16×16,则MW(掩模窗口)也为16×16,并且MW只需载入一次。
如果RW为32×32,对应的MW为32×32,如图5,MW要随时钟循环载入对应的PE中。
掩模位控制对应的PE在以后的255个周期是否需要作运算,如果不要作运算,则将自身的SE置为全1(在作SE比较时才不会出错)。
掩模位若在芯片内部缓冲,则需要64 bit×64 bit(512B)的缓冲区。
5 硬件实现
具体电路图如图6。
PE阵列的功能就是接收DSP提供的搜索窗(Searching Window ,简称SW)数据、参考窗(Referencing Window,简称RW)数据,以及搜索模式(Searching Pattern,简称SP)数据,计算出运动向量,并将处理结果返回给DSP。
外挂DSP处理器的主要功能是完成对视频信号的编码,产生相应的搜索窗数据、参考窗数据以及搜索模式数据,并接受PE处理结果以完成整个信号的编码功能。
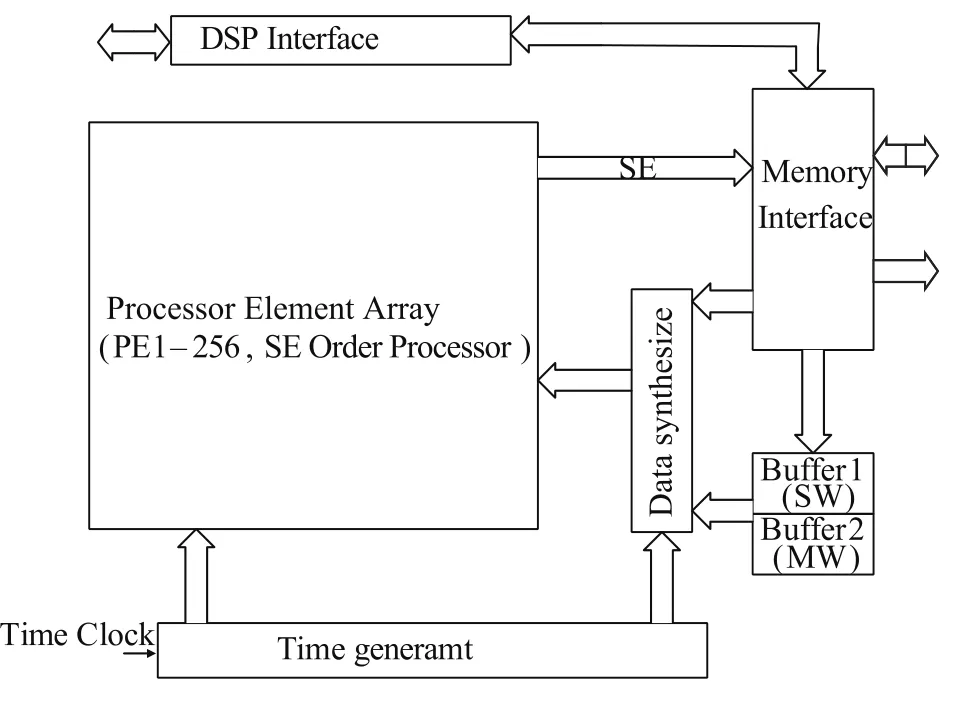
图6 电路结构
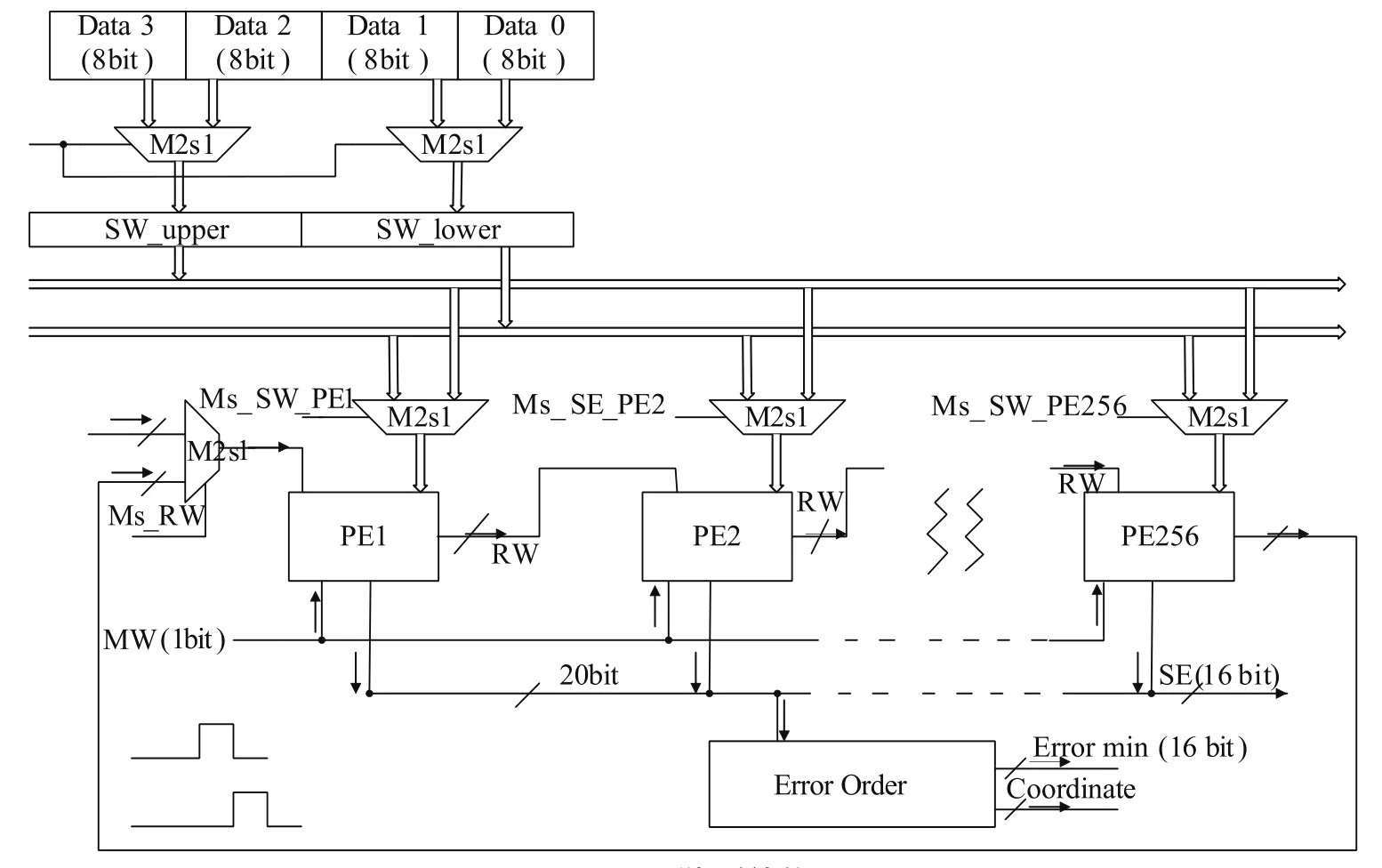
图7 PE阵列结构
外置SRAM接收MEP的数据,并按照MEP的要求存储起来,当MEP需要SRAM中的数据时,可以从SRAM中顺序读出来。
6 结论
本文详细分析了基于块的快速匹配的算法原理,对于不同窗口操作方式时的硬件实现速度以及所耗资源都进行了分类比较,并根据硬件实现的处理速度和面积规划的要求,详细地设计了该系统的构架以及各部分的硬件电路。
[1]T Koga,K Iinuma,A Hirano,Y Iijima,and T Ishiguro.Motion compensated interframe coding for video conferencing[C].Proc.Nat.Telecommun.Conf.,New Orleans,LA,Dec.1981.G5.3.1-G5.3.5.
[2]M Po,C K Cheung,W C Ma.A novel fast block motion estimation algorithm using center-biased search pattern[J].Proc.IEEE Int.Conf.on Neural Net and Signal Proc,1995,2(12): 1 616-1 619.
[3]T Sikora.The MPEG-4 video standard verification model[J].IEEE Trans.Circuits Syst.Video Technol,1997,7(2): 19-31.
[4]J Y Tham,S Ranganath,M Ranganath,and A A Kassim.A Novel Unrestricted Center-Biased Diamond Search Algorithm for Block Motion Estimation[J].IEEE Trans.Circuits Syst.Video Technol,1998,8(8): 369-377.
[5]J R Jain,A K Jain.Displacement measurement and its application in interframe image coding[J].IEEE Trans.Commun,1981,COM-29(12) :1 799-1 808.
猜你喜欢
有色金属设计(2022年4期)2022-02-04
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
计算机应用(2020年5期)2020-06-07
传感器与微系统(2019年7期)2019-06-25
自然资源遥感(2017年2期)2017-04-27
光学精密工程(2016年3期)2016-11-07
吉林大学学报(理学版)(2013年5期)2013-12-03
网络安全与数据管理(2011年24期)2011-08-08
通信技术(2010年8期)2010-08-06
