
基于词语相关度的文档主题抽取算法
2012-09-18 02:25袁晓峰
成都大学学报(自然科学版) 2012年4期
袁晓峰
(盐城师范学院信息科学与技术学院,江苏盐城 224002)
基于词语相关度的文档主题抽取算法
袁晓峰
(盐城师范学院信息科学与技术学院,江苏盐城 224002)
考虑到文档中出现频率较高的词语能够体现文档的主题,设计了一种中文文档主题抽取算法.该算法首先对目标文档进行预处理,然后计算文档中每个词语的出现频率,用出现频率最高的几个词语作为文档的主题.其中,将词语间的相关度作为计算出现频率的参考因素.词语相关度的计算是基于中文知识库《知网》的方法.实验证明,本算法具有较高的准确性.
词语相关度;出现频率;知网;主题抽取
0 引 言
文档主题抽取的研究被广泛应用于搜索引擎、文本聚类等文本自动处理方面的工作.目前,国内相关研究集中于字同现频率、语言理解、匹配和统计等方面[1-4].本研究在《知网》概念描述方法[5]的基础上,着重研究《知网》中义原在纵向和横向上的关系结构,以此来计算词语之间的相关度.通过考虑词语之间相关度,提出一种计算词语出现频率的新算法:首先对文档进行预处理,剔除停用词;然后计算词语之间的相关度,将初始出现频率较低的词归于与之相关度较高的那些初始出现频率较高的词;最后用出现频率较高的词作为文档主题.
1 词语相关度计算
《知网》中的概念是对词汇语义的描述,是用知识表示语言来描述的,这种“知识表示语言”所用的词汇称为义原.词语相关度计算需要考虑2个方面:词语相似度与义原关联度[6].
1.1 词语相似度
对于2个汉语词语W1和W2,如果W1有n个义项(概念):S11,S12,……,S1n,W2有m个义项(概念):S21,S22,……,S2m,则W1和W2的相似度是各个概念的相似度之最大值,
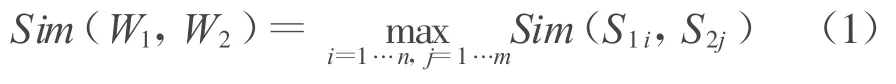
概念之间的相似度计算可分为4个部分[7].
①第一基本义原,直接计算2个义原的相似度,记为Sim1(S1,S2);
②其他基本义原,可以看成是一个集合,通过建立2个集合中元素的对应关系来计算2个集合的相似度,记为Sim2(S1,S2);
③关系义原,可以看成是一个特征结构,即“属性:值”对的集合,每个“属性:值”对为一个“特征”.2个特征之间一一对应关系的建立就转化为对相同“属性”对应“值”的相似度的计算,记为Sim3(S1,S2);
④关系符号描述,其值为一个特征结构,转换为2个特征结构的相似度计算,记为Sim4(S1,S2).
则,概念之间的相似度计算式为,
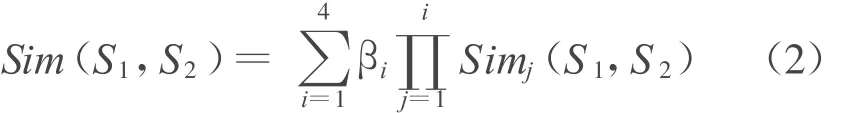
其中,βi(1 ≤i≤4)是可调节的参数,且有,β1+β2+β3+β4=1,β1 ≥β2 ≥β3 ≥β4.
这样,词语之间的相似度计算就完全转化为义原之间的相似度计算.
由于义原可根据上下位关系组织成树状结构的层次体系,因此通过计算义原之间的距离可计算出义原之间的相似度[8],
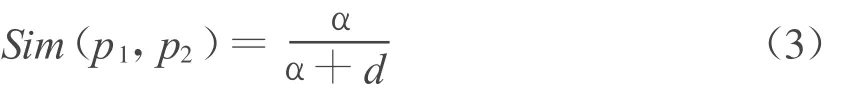
其中,p1、p2分别表示两个义原,d是p1和p2的距离,α是一个可调节的参数,通常 α表示相似度为0.5时的词语距离值.
1.2 义原关联度
两个义原的关联度记为A,其计算式为,
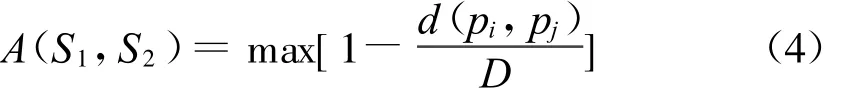
其中,pi和pj分别为义项Si和义项Sj的第一基本义原,D为横向关联影响深度,即某一义原向上第几层的解释义原会对其特征有影响.
1.3 词语相关度
词语相关用以描述两个词语的概念之间的关系,而相关度是概念之间相关程度的度量.因此,词语相关度是相似度和关联度的加权求平均,其计算式为,

式中 ,η1+η2=1.
2 主题抽取
主题抽取可分为:对给定文本d进行特征抽取和主题生成.特征抽取将文本用实词序列表示,主题生成通过计算实词序列中词的出现频率从而得到文本的主题.
2.1 特征抽取
通常,特征抽取需先对给定文本d进行预处理,如分词、去除停用词等.为了降低整个算法的复杂性,本研究仅考虑把实词作为特征词,即不考虑连词、代词、副词等虚词,分词是中文文本处理常用的步骤,本算法采用中科院中文分词系统(Institute of Computing Technology,Chinese Lexical Analysis System,ICTCLAS)进行分词,最后得到结果,
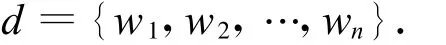
2.2 主题生成
主题生成的主要思想是:首先,从经过特征抽取的结果中选取出现频率最大的s个词语,并将其称为待定主题词,待定主题词初始权值设为1;其次,计算文档中其他词汇与s个待定主题词之间的相关度,并将相关度加到待定主题词的权值上;最后,选定t个权值最大的主题词作为文档的主题.
主题抽取算法的具体步骤如下:
①选出d中出现频率最高的s个词集,合记为hf={w1,w2,…,ws},剩余的词集合记为 ,left=d-hf={v1,v2,…,vn}.
②初始hf的权值,weight={g1=1,g2=1,…,gs=1}.
③计算left集合中的词与hf中每个词之间的相关度,rel=R(left,hf),并将hf中当前词权值加上rel.
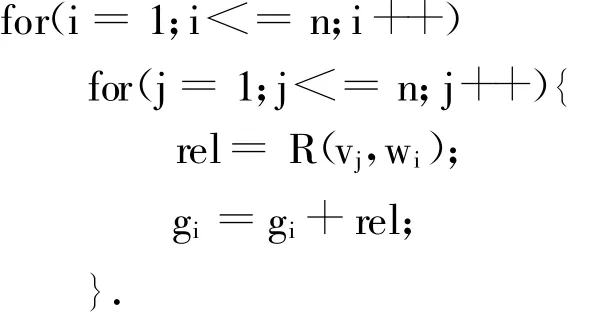
④选出weight集合中值最大的t个词,记为,subject={w1,w2,…,wt},此即为文档d的主题.
3 实 验
3.1 主题抽取实验
由于算法的参数无法给出标准值,对此,本研究通过反复实验并与其他文献比较,设置参数如下:
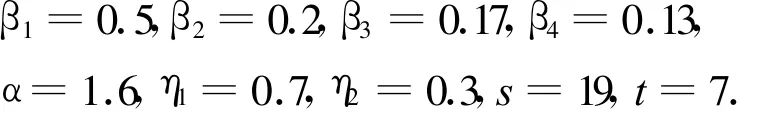
在实验中,本研究从复旦大学语料库中抽取200篇带有标题的短篇新闻,其中政治类46篇、经济类45篇、科技类39篇、娱乐类22篇,其他48篇.并将主题句抽取的质量好坏分为4个等级:与原标题基本一致、包含原标题内容、主题基本符合、主题不全面或主题偏离.若结果符合前3个等级则认为抽取正确,并将文本篇数占总测试语料篇数的比例称为主题句抽取正确率.实验结果如表1所示.

表1 主题抽取实验结果
3.2 实验结果分析
从表1中的数据可以看出,政治类的新闻文档主题抽取准确率极高,几乎为100%,与原标题基本一致比率达到了93.5%;经济类和科技类的新闻文档主题抽取准确率分别为97.8%、97.4%,略低于政治类;娱乐类的新闻文档主题抽取准确率为90.9%,较前3类文档偏低,这是因为娱乐类的新闻内容不紧凑、话题比较广所致;其他类文章的主题抽取准确率不足90%.准确率最高的新闻类的文档主题相对集中,文章的布局紧紧围绕主题,此也再次证明文章的主题分散对主题抽取有不利的影响.尽管如此,本算法对文档主题的抽取准确率都达到80%以上,证明了本算法的有效性.
4 结 语
出现频率高的词语能够体现文档的主题,不过频率不能仅仅由该词出现的次数决定,而必须考虑与该词相关度较高的词语的出现频率.本研究提出了一种通过词语相关度来统计词语在文档中出现的频率,进而通过词语出现的频率来抽取文档主题的算法.实验表明,本算法对文档主题的抽取准确率较高.需要说明的是,该算法的主题抽取质量与文档的布局也有着密切的关系,主题思想越集中,抽取的准确率越高;反之,主题思想越发散,抽取的准确率越低.
:
[1]马颖华,王永成,苏贵阳,等.一种基于字同现频率的汉语文本主题抽取方法[J].计算机研究与发展,2003,40(6):874-878.
[2]麻志毅,姚天顺.基于情境的文本主题求解[J].计算机研究与发展,1998 ,35(4):344-348.
[3]Yin Zhonghang,Wang Yongcheng.Extracting Subject from Internet Newsby String Match[J].Journal of Software,2002,13(2):159-167.
[4]韩客松,王永成,沈洲,等.三个层面的中文文本主题自动提取研究[J].中文信息学报,2001,12(4):20-27.
[5]董振东,董强.知网[EB/OL].http://www.keenage.com/html/c index .html,1999-2007.
[6]许云,樊孝忠,张锋.基于知网的语义相关度计算[J].北京理工大学学报,2005,25(5):411-414.
[7]刘群,李素建.基于《知网》的词汇语义相似度计算[J].计算语言学及中文信息处理,2007,31(7):59-76.
[8]Agirre E,Rigau G.A Proposal for Word Sense Disambiguation Using ConceptualDistance[C]//Porceeding of International Conference on Recent Advances in Natural Language Processing.Bulgaria:arXiv.org,1995.
Algorithm of Document Subject Extraction Based on Word Relevancy
YUAN Xiaofeng
(College of Information Science and Technology,Yancheng Teachers University,Yancheng 224002,China)
A kind of subject extraction algorithm was designed based on the consideration that words with high frequent occurrence could represent the theme of the document.Firstly,this algorithm pre-processed the sample document and calculated the occurrence frequency of eachword of the document.Some most frequent words were used to represent the subject.The relevancy between words was referred to calculate the frequency of each word and the calculation of relevancy was based on the ontology Hownet.At last,the high accuracy of the algorithm was testified by the experiment.
word relevancy ;occurrence frequency ;Hownet;subject extraction
TP391.1
A
1004-5422(2012)04-0367-03
2012-09-04.
袁晓峰(1978—),男,硕士,从事计算机信息检索与自然语言处理技术研究.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
老年医学与保健(2017年6期)2017-02-06
信息安全研究(2016年4期)2016-12-01
西北工业大学学报(2015年1期)2015-02-22
