
基于社会网络的Web服务选择算法的研究
2012-08-20 05:19苏佰川张国义许胤龙
网络安全与数据管理 2012年6期
苏佰川,张国义,许胤龙
(中国科学技术大学 计算机科学学院,安徽 合肥230026)
随着面向服务计算技术的深入发展,通过组合Web服务建立分布式应用系统逐渐成为基于Web应用开发的主流技术。在众多可获得的Web服务资源中,如何选择合适的服务实例进行组合,使之既能满足应用的功能需求,又能满足用户提出的QoS需求,是一个备受关注的问题,并已得到了广泛的研究。
QoS约束的Web服务选择与组合是一类组合优化问题。到目前为止,求解该问题比较典型的方法有线性规划算法[1-2]和遗传算法[3-6]。线性规划算法在候选服务集规模较小时是非常有效的,但是随着规模的加大,计算耗时增长速度明显加快,可扩展性变差。遗传算法被用于QoS的全局组合优化已有许多成功的案例,但是,由于在诸多的研究中一般采用随机交叉和变异操作,没有考虑候选服务实例之间实际存在的连接偏好,组合服务的可靠性难以得到有效的保证。连接频率反映了服务之间的连接偏好,频率越高,下一次连接的可能性就越大,在一定程度上可增强组合服务的可靠性。如何利用候选服务实例之间的连接偏好优化服务的随机选择,提高服务组合的效率与成功率是本文主要关注的问题。
根据软件工程的一般常识可知,一个复杂的组合服务包含平行、分支、选择、循环等结构,可以利用数据流聚合方法形成颗粒较大的结构块。而对于一个大规模的候选服务集合,应用社会网络社区形成机制[7],也可以形成与服务流程聚合块功能相一致的服务子集,即所谓的服务社区。这样,服务选择就演化成社区选择问题,运用遗传算法能较好地保证结构性选择,且依据连接权重形成的服务社区能充分体现服务之间的连接偏好。根据这一思想,本文提出了一个基于社区形成机制和遗传算法的服务选择方法,与传统遗传算法不同的是,设计了一个依据连接偏好的效用函数估算随机选择概率。初步的实验结果证明,该方法行之有效,且具有较高的计算效率。
1 问题描述
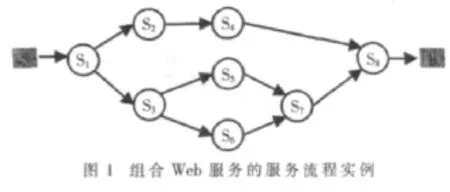
对于用户提出的服务需求首先建立组合服务流程,图 1所示为一个有 8个原子服务 S1,S2,…,S8的服务流程。
如图1所示,一般一个组合Web服务流程由多个Web原子服务组成,每个Web原子服务又对应有多个候选服务。这些候选服务可能由不同的服务提供者提供,具有相同的功能和不同的QoS度量值。

定义(服务流程,SP)1:对于任意一个组合Web服务流程 SP可表示为 SP=(S,≤s),其中其中 Si表示第 i个原子服务,≤s表示各个服务 Si、Sj之间的内部关系,可表示为:≤s=(Pre,Suc,R),其中 Pre 和Suc分别表示当前服务在服务流程中的前驱和后继。同时如果某个Si.Pre=∧,则此结点为开始结点,如果某个Si.Suc=∧,则此结点为结束结点。R(0<R≤1)表示当前原子服务在服务流程中的结构关系,R=1表示此服务在服务流程中是串行、并行或者循环结构,0<R<1则表示此服务属于服务流程选择结构的一个分支。
假定每个原子服务Si包含m个候选服务,即:

对于每个候选服务Sji都有不同的服务质量(QoS)[3,8],如响应时间(Response time)、代价(Cost)、可靠性(Reliability)、信誉度(Reputation)等,假定每个候选服务的服务质量(QoS)维度为 k,即:

其中T、C、R为某一服务选择实例(WS)完成组合服务要经历的总的响应时间、总代价及可靠性。而TQoS、CQoS及RQoS为用户提出的约束条件。组合Web服务流程[3]的4种基本结构——串行、并行、选择和循环中QoS度量值(T,C,R)计算公式在文中已给出,此处不再叙述[8]。
2 算法描述
2.1 服务社会网络
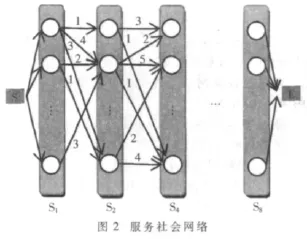
要应用社会网络[9-10],首先要将候选服务结点集合转换为以网络为主的服务社会网络,因此要在结点之间加入边及其边的权值的确定。
定义(服务结点,Node)3:对于组合Web服务选择问题中的每个候选服务,都称之为一个候选服务结点(Node),每个 Node除了候选服务本身的 QoS之外,另外加入边的权值 (Weight)属性,具体数据结构表示为Node(Name,Type,Weight,QoS)。 为描述方便,将 Node.Name 由之前的转化为 Nk(k=1,2,…,n×m),每个服务结点 Ni的服务类型 Ni.Type=Sj(j=1,2,…,n),同时 Ni.Weight是一个三元组,表示为(Name,Type,w)。
设 Edge(Si,Sj)为如果在服务流程 S中 Si到 Sj存在边相连,则 Edge(Si,Sj)为 1,否则为 0。
定义(服务社会网络,SSN)4:对于特定的服务流程S,用户每提出一个QoS需求,都会对应一个 WS满足用户的功能需求及QoS需求,对每个满足需求的WS作如下判断:

通过以上的定义,将之前的服务结点之间加入边及权值,形成服务社会网络,如图2所示。
2.2 服务社会网络选择算法
Web服务的部分QoS是负相关的,即取值越小越好(如响应时间、代价),而同时部分 QoS则是正相关的,即取值越大越好(如可靠性等)。因此对于负相关的QoS属性和服务结点之间的权值归一化:
定义(归一化,Normalized)5:
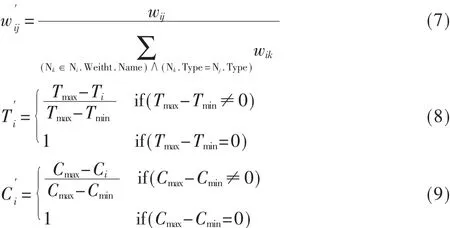
结点的效用函数Fi的定义由QoS参数组成,其中的QoS参数是与用户提出的目标函数中的QoS参数相对应的,由式(4)可知目标函数使整个组合Web服务的执行时间最小,故效用函数的定义如定义6所示。
定义(效用函数,Fi)6:Fi=T′i
服务结点之间的权值归一化后,结点 Ni与 Nj之间的归一化权值w′ij与 w′ji值不相同,因此结点间的选择概率定义如下:
定义(选择概率,Pij)7:
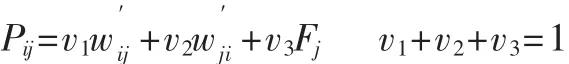
Pij越大,表明结点 Ni与 Nj被选择在一起用于解决问题的概率越大。
给出Pij之后,同时结合Web服务选择问题和遗传算法,提出了如下的服务社会网络算法(SSN Algorithm):

某一结点Ni在某一服务实例WS中关于前驱后继的平均选择概率P的计算公式如下(前驱后继可能不止一个,Num函数用于计算某一原子服务Si在某一服务流程中前驱与后继的个数):

3 实验分析
实验环境为100 Mb/s的局域网,微机的配置为Intel Pentium Dual 2.0 GHz CPU,2 GB内存,操作系统为Windows XP,算法编译环境为VC++6.0。实验分为 4组,每组的服务类型个数及候选服务个数如表1(其中n表示原子服务个数,m表示每种原子服务对应的候选服务个数)所示,分别从以下几个方面进行实验。
(1)服务结点规模不同时对选择算法执行时间的影响。

表1 各组原子服务类型规模及候选服务规模
选择算法中的外层循环设置为1 000次,内层循环条件为当TBest有连续50次不发生变化或者循环满3 000次时结束。算法在4个group下的执行时间如图3所示,由图可知,当整个社会网络中总结点个数为3 000时,所用的时间刚刚1 s,而且随着网络规模的增加,执行时间的增长速率要缓慢得多。因此说网络规模越大,SSN算法的执行效率越高。

(2)随着社会网络权值的不同找到最优解的概率

分析在不同权值下各个group运行SSN算法100次,能找到的目标函数的较优值与最优解之间的比值,通过图4可以看到随着网络中权值的增大,4个group找到的较优解与最优解之间的差距越来越小。当网络中结点的规模不是很大(group1,group2)时,即使权值不是很大,找到最优解概率也非常高。随着权值的增加,能找到最优解的次数也不断增多,当用户提出次数到达40次左右时,group1与group2基本每次都可以找到最优解。当网络规模较大(group3,group4)的情况下,虽然权值很小时找到最优解的概率不是很高,大概85%,但随着权值的增加,能找到最优解的概率迅速加大,当权值为30时,概率达到了96%左右,权值为 50时,概率达到了98%,因此随着用户QoS需求的增加,能找到最优解的概率能够迅速加大,同时对于结点规模很大的社会网络来说,效果更佳。
随着服务计算的迅速发展,可利用的Web服务资源越来越多,候选服务结点的规模也越来越大。本文总结了近期相关的工作,提出了一种基于社会网络社区形成机制的Web服务选择方法。将Web服务选择问题转换到社会网络中,利用社会网络特有的性质结点联系强度等来解决服务选择问题。提出了一种服务社会网络概率选择方法,此方法与遗传算法的不同之处在于变异结点的选择不是随机的,而是根据结点之间的连接频率,它反映了服务之间的连接偏好,频率越高,下一次连接的可能性就越大。
虽然最终算法给出了很好的性能,但还有待进一步改进,如本文算法是基于单目标优化的,希望今后在多目标优化方面有所进展。同时本文算法是基于历史信息(服务实例)的,因此当历史信息较少或刚开始没有历史信息时性能方面可能会很差,希望今后在这方面也有所研究。
[1]Zeng Liangzhao,BENATALLAH B,DUMAS M,et al.Quality driven Web services composition[C].Proceedings of the 12th International Conference on World Wide,2003.
[2]ARDAGNA D,PERNICI B.Adaptive service composition in flexible processes[J].IEEE Trans.Software Eng,2007,33(6):369-384.
[3]HWANG S Y,WANG H,TANG J,et al.A probabilistic approach to modeling and estimating the QoS of Web-Services-based Workflows[J].Information Sciences,2007,23(177):5484-5503.
[4]KLEIN A,ISHIKAWA F,BAUER B.A probabilistic approach to service selection with conditional contracts and usage patterns[C].ICSOC-ServiceWave2009,2009:253-268.
[5]Tang Maolin,Ai Lifeng.A hybrid genetic algorithm for the optimal constrained Web service selection problem in Web Service composition[C].WCCI 2010 IEEE World Congress on Computational Intelligence,2010.
[6]Liu Shulei,Liu Yunxiang,Jing Ning,et al.A dynamic Web service selection strategy with QoS global optimization based on multi-objective genetic algorithm[C].GCC2005,2005:84-89.
[7]KUMPULA J M,ONNELA J P,SARAMAKI J,et al.Model of community emergence in weighted social networks[J].Computer Physics Communication,2009(180):517.
[8]YU T,ZHANG Y,LIN K J.Efficient algorithms for Web services selection with end-to-end qos constraints[J].ACM Transactions on the Web,2007,1(1):1-26.
[9]NEWMAN M E J.Analysis of weighted networks[J].Physical review,2004,70(05):1-9.
[10]WASSERMAN S,FAUST K.Introduction to social network analysis[M].Cambridge Cambridge Univ.Press,1994.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
自动化学报(2017年7期)2017-04-18
统计与决策(2017年2期)2017-03-20
现代电子技术(2016年15期)2016-12-01
现代计算机(2016年34期)2016-02-28
智能系统学报(2015年4期)2015-12-27
