
基于形状上下文的公共场所行人检测系统
2012-08-10 03:39丁辰瑜葛万成陈康力
通信技术 2012年4期
丁辰瑜,葛万成,陈康力
(同济大学 电子与信息工程学院,上海 200092)
0 引言
近年来,在交通运输及公共设施规划等方面,对于慢行交通对象,比如行人及非机动车的研究越来越多,对于其流量等数据的研究方面,其精度要求也越来越高。而在建立行人模型供公共设施建设参考时,实际数据是非常重要的,尤其是微观数据,目前,在交通运输方面,国外针对行人以及人流的建模研究,主要集中于行人的步频和长度,行人安全,行人数目,行人跟踪,公共服务设施服务时间等参数进行研究[1]。由于以往的主要研究主要集中在对于机动车的研究,在对于行人和非机动车的研究方面,虽然近年来有一些算法表现良好,但是在实际应用用上仍然存在一些问题。此外,行人在公共场合存在其特殊性,一方面独立的个体表现的行为具有随机性,另一方面在高峰时期,大量的行人会汇聚成人流。因此,通过一系列自动化手段取得公共设施中行人行为与人流总体趋势相关的模型,对于公共行人设施的规划和建设,公共交通服务的加强,以及对高强度客流的预测,有着非常重要的意义。
而基于视觉的行人检测目前仍旧是计算机视觉领域的一个公认的难题。其中一个关键的问题就是如何将人和车辆、树木等其他物体区分开来。如果仅用基于运动特性的提取方法是很难做到的,原因在于他们缺少了本地描述特征。而基于特征学习的方法近年来被证明在行人检测上有着比较好的性能。比如 Paul Viola等人提出的基于 AdaBoost Cascade的 Haar特征目标检测算法[2],在正面无旋转的人脸的识别上取得了比较高的识别率。2002年,Lienhart对该方法进行了扩展[3],增加了45°特性。使该方法适用于全旋转缩放的目标检测。2005年Dalal提出了基于HoG特征的算法,在MIT数据库上取得了非常高的识别率[4]。Bo Wu最先提出了edgelet特性[5],这些小边描述了人体的某个部位的轮廓,然后再用boosting算法筛选出最有效的一组edgelet来描述人的整体。该方案不需要人工标注,而且避免了相似模板之间的重复的计算。
然而这些方法在识别行人时,都是用背景分割-目标识别的顺序对场景中的行人进行识别。在这些方法中,分割被视为一种小块到整体的过程,并且仅能基于已有数据进行图像分割。而人在对场景识别时,目标识别和背景分割被认为是交替进行的。因此Bastian Leibe和Bernt Schiele提出了基于广义Hough变换,分割和识别交替进行的目标识别方法[6]。其核心思想是找出图像中所有匹配的小块,并且每个小块进行广义Hough变换,并用mean-shift方法找出物体最有可能的中心。在得出物体中心后,再利用中心和小块的信息对背景和目标进行分割。另外Bastian Leibe于2005年针对不同的本地特征和分类器进行了比较[7]。
这里采用了Bastian等人提出的方法,并使用形状上下文作为本地局部特征,并通过广义Hough变换算法对特征进行匹配,以此对行人和背景进行分割,建立了一个基于视觉传感器的行人检测系统。
1 形状上下文特征
形状上下文是Serge Belongie,Iitendra Malik和Jan Puzicha 2002年提出的用于匹配相似图像的本地描述符[8]。他在匹配的时候起到了关键的作用。在这里将其用于行人特征的提取。
形状上下文是一个向量集合,其中包含了从形状轮廓中的一点到其他点的向量。因此这个描述符描述了整个形状相对那一点的轮廓。图1(a)、图1(b)表示了对于行人轮廓上的一点到其他点的向量。
对于一个由n点组成的轮廓,可以得到一个n-1维向量对轮廓进行描述。但是如果将整个向量集作为形状描述符会过于庞大,会导致训练时间过长,识别无法做到实时性,鲁棒性差等问题。并且每个实例的形状和采样的点都各有差别。因此这里在对应点上引入一个直方图作为描述符使其鲁棒性更高同时也更加简洁。对于每一个轮廓中的点 pi,定义如下直方图来表示它在目标中的形状特征:
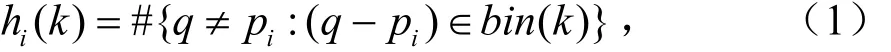
式中,k表示直方图的量化阶数,q为除了 pi之外的n-1个点的集合,q - pi为从点q到点 pi的向量。如图1 (b)所示。Serge等人采用直方图对所有向量分类是为了简化计算量并且统一特征向量的维度,并且采用对数极坐标的表示方式以提高旋转及缩放后目标的匹配能力,即:
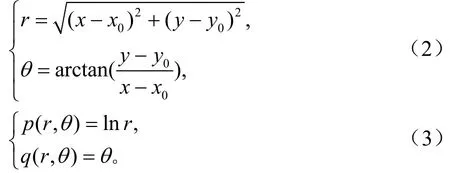
具体实现中将lgr分为5段,将θ分为12段,这样k等于 60。如图 1(c)所示。这里对每个轮廓取300个点,实际形成的直方图如图 1(f)、图 1(g)、图 1(h)所示,可以看到,对于同样是行人轮廓上的点,点A和点A’有着类似的直方图,而点B’的直方图则与点A与点A’的直方图差异较大。
以上定义比较直观的显示了形状上下文描述符,然而为了计算它们之间的相似度,需要定义一个量描述其互相之间差异的变量。若ip,jq分别表示两个目标中的两个点,则基于2χ统计,它们的形状上下文描述符的差异度表示为:
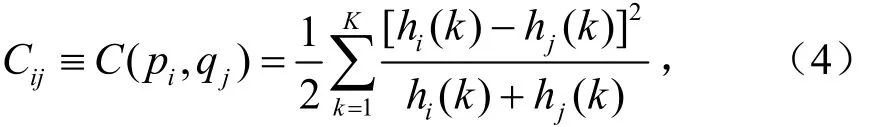
这样可以计算出两个形状上下文描述符之间的差异度。如图 1(d)、图 1(e)中,点 A 与点 A’的差异度C(A,A′) = 3 9.9,而点 A与点 B的差异度C(A,B) = 2 16.4。因此可以通过求得两个目标A与B之间的差异度矩阵 Cn×m,并通过取最小值完成匹配,即使式(5)取最小值即可完成匹配:

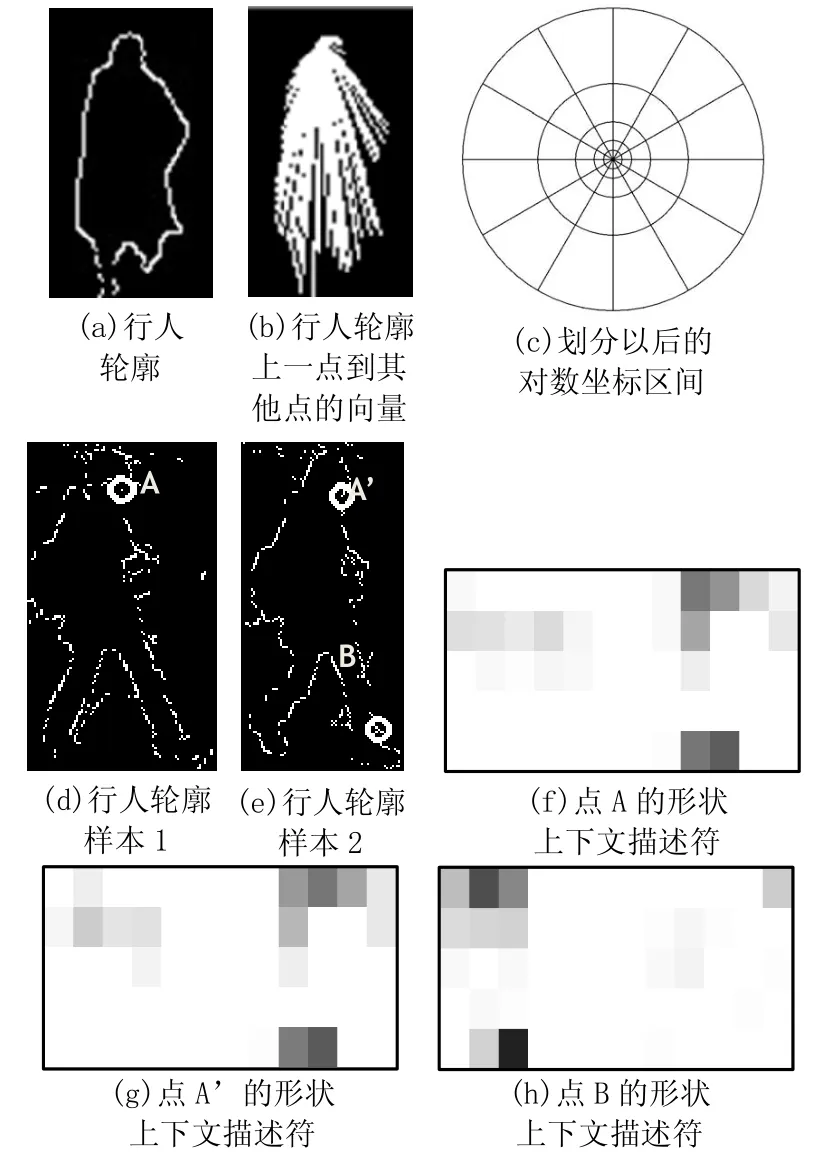
图1 形状上下文及其直方图表示
仅有形状上下文特征并不能直接对复杂场景中的行人进行识别和分割,原因在于行人外观以及动作的多样性。如果仅用形状上下文可能对与训练样本相似的行人具有比较高的检出率,而对一些与训练样本整体上有一些差异的行人的检出率比较低。
2 基于广义Hough变换的检测算法
Bastian Leibe和Bernt Schiele提出了基于广义Hough变换的目标识别和分割[6]。比起其他方法该方法的优势在于能够识别与之前样本有一定差异的目标。在系统的实现中,首先使用形状上下文对移动边缘采样,并且利用形状上下文对已学习的包含空间概率分布的码书实例进行匹配。如果找到一个匹配,则利用码书实例对假设中心进行投票。
2.1 目标假设中心产生
用SC表示一个在位置l处的采样点的形状上下文描述符。通过匹配描述符和码书从训练好的码书中获得一组有效的实例iI。因此,观察到一个以c为中心的目标nO的概率可以表示为:
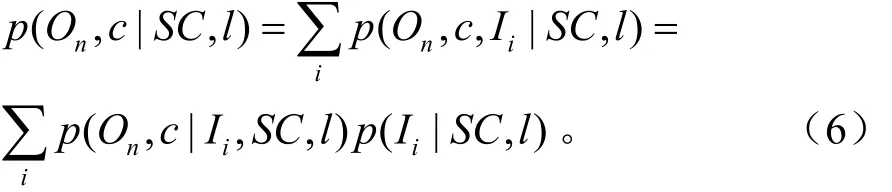
由于SC可以被有效的实例 Ii替代,则p(On, c|Ii,S C,l)可简化为 p (On, c|Ii,l)。且描述符与实例之间的匹配和坐标l不相关。则上式可简化为:
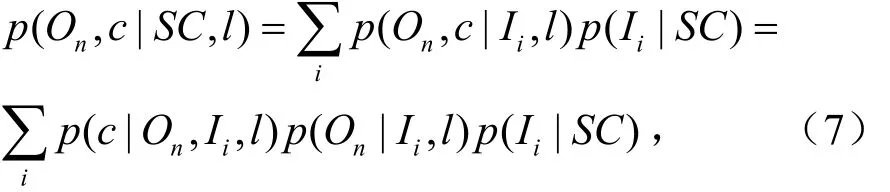
式中,p (c|On, Ii,l)表示码书实例在位置l处观测到目标 On在c处的投票,p (On|Ii,l)和 p (Ii|S C)分别表示码书实例和目标以及形状上下文与码书之间的相似度。由此,可以通过累计所有边缘对目标 On的中心c进行投票。
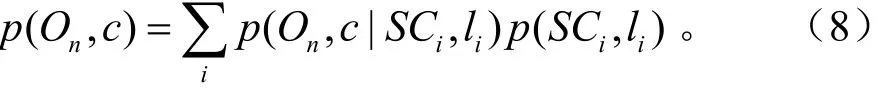
在计算了目标所有的假设后,采用Mean-shift算法在投票区域内寻找局部最大值以确定目标的中心。
2.2 目标分割
在计算出目标的中心假设后,可以在概率框架下,通过对投出正确中心的本地小块进行反向查找,也就是说,通过以下边缘化公式估计图像中像素作为前景的概率。
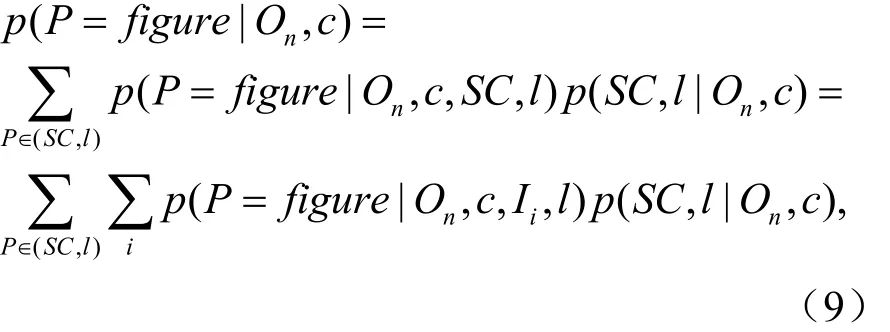
式中:
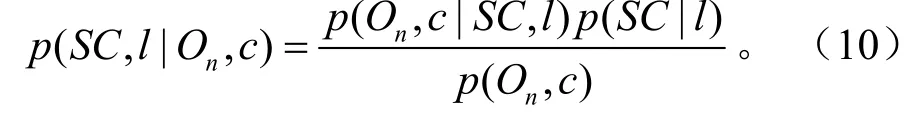
本系统中图形-背景分割通过跟踪匹配结果来实现。即根据码本匹配的本地小块在空间概率分布中的大小,通过目标中心反向映射到相应的位置。这样就实现了目标与背景的分割。每个假设目标的边界框是包含所有反向映射小块的最小边界框。如图2所示。

图2 行人中心假设与背景分割过程
3 系统实现与测试
3.1 系统工作流程
针对行人检测与计数的目的,提出了一种基于形状上下文特征和广义Hough变换的形状上下文行人检测系统。系统的步骤如图3所示,在训练时,首先使用Canny算子对帧间差进行移动边缘提取,并对每个边缘采样300个点并计算它们的形状上下文特征,并对其进行K值聚类并且计算它们的空间概率,形成码本。检测时,对使用已经训练好的码本对提取的边缘点的上下文进行比较,并且根据码本在投票空间进行Hough投票,用Mean-Shift找到局部最大值,反向映射到小块。最后找出重叠程度高于70%的两个目标,将其认为是一个目标,即假设排除。
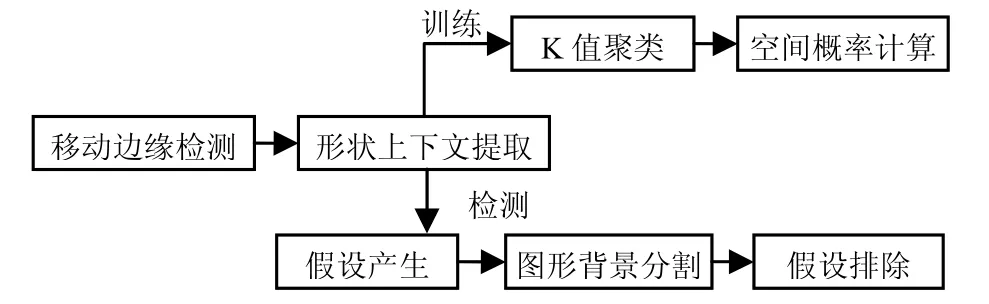
图3 系统工作流程
3.2 系统测试结果
此处从PETS2006视频中手动截取了30个训练样本,其中包含了正面和侧面的人体,样本的平均像素为55×95。然后按照上述步骤进行训练,原图像和提取的边缘图像如图4所示。
检测测试中,所有视频均来自于PETS2006数据集。该数据集包含了公共场所中监控摄像头在车站捕捉的若干组视频。其中选取了6段视频,侧视角和正视角的视频各3段,正视角帧数分别为700和1 000以及150帧,行人人次分别为461和695以及633人次;侧视角视频长度分别为643和257以及1 154帧,行人人次为1 412和667以及1 154人次。视频尺寸为360×288,其中行人的平均大小为45×78。
测试结果如图5所示,这里对实验室先前研究的基于SIFT的行人检测系统进行了对比。该系统采用 128维的SIFT特征作为特征向量。测试平台为Pentium M 1.60 GHz,代码为c++实现,此算法每帧的平均处理时间为150 ms。在行人密集的场景中速度降为215 ms左右。

图4 训练样本及其提取的边缘
从图5中可以得出基于形状上下文描述符的检测算法比基于SIFT特征的算法更加精确。在侧面视角和正面视角的大部分情况下检出率都高于85%。但是可以看出,由于视频3中行人较为密集,这种算法的检出率仍然有待改善。
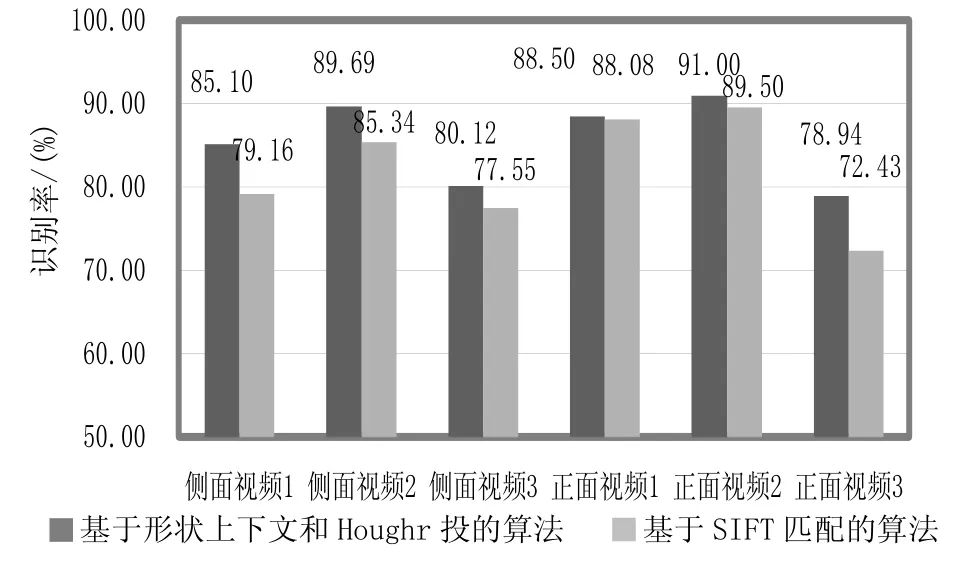
图5 系统性能及比较
4 结语
针对现有算法中所存在的识别率低,训练时间长等缺陷[9-12],提出了一种基于形状上下文和广义Hough变换的检测算法,并进行了系统实现与测试。测试结果显示,在测试平台为Pentium M 1.60 GHz的环境中,经过与SIFT特征匹配的比较,该系统有着较高的识别率,平均检出率达到85%,能应付中、低人流密度的场景。另外,训练样本的选取方面,此方法只需要30个正样本,不需要负样本,因此只需比较短的训练时间。另外此算法的速度在测试平台上能达到5~10帧/秒,可以基本符合实时监测的需求。
[1] SAUNIER N, HUSSEINI A E, ISMAIL K, et al. Pedestrian Stride Frequency and Length Estimation in Outdoor Urban Environments using Video Sensors[C]// TRB 90th Annual Meeting Compendium of Papers.Washington DC: Transportation Research Board,2011:11-21.
[2] VIOLA P,JONES M J. Rapid Object Detection Using a Boosted Cascade of Simple Features[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Kauai, HI, USA: IEEE Computer Society 2001, 2001: 511-518.
[3] LIENHART R,MAYDT J. An Extended Set of Haar-like Features for Rapid Object Detection[C]// IEEE ICIP 2002. Rochester, New York, USA: IEEE ICIP Society,2002: 900-903.
[4] DALAL N,TRIGGS B. Histograms of Oriented Gradients for Human Detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE Computer Society, 2005:886-893.
[5] WU B,NEVATIA R. Detection of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors[C]//IEEE International Conference on Computer Vision. San Diego, CA, USA: IEEE Computer Society, 2005:886-893.
[6] LEIBE B,SCHIELE B. Interleaved Object Categorization and Segmentation[C]//British Machine Vision Conference (BMVC’03). British: BMVC 2003 Society, 2003: 759-768.
[7] LEIBE B, LEONARDIS A, SCHIELE B. Robust Object Detection with Interleaved Categorization and Segmentation[J]. International Journal of Computer Vision Special Issue on Learning for Recognition and Recognition for Learning, 2008, 77(01):259-289.
[8] BELONGIE S, MALIK J,PUZICHA J. Shape Matching and Object Recognition Using Shape Contexts[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002,24(04):509-522.
[9] 高智芳,张新家.基于小波变换的除噪方法及其应用研究[J].信息安全与通信保密,2007(06):102-104.
[10] 王忠, 陈海清.基于LAB色彩空间的自适应数字水印算法[J].信息安全与通信保密,2006(04):70-72.
[11] 戴海港,宫宁生,张德金.基于二值图像连通域的车牌定位方法[J].通信技术,2011,44(08):116-117.
[12] 余萍,崔少飞,赵振兵,等. 图像配准中的边缘提取方法的研究[J].通信技术,2008,41(06):161-163.
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28
测绘学报(2022年12期)2022-02-13
意林(2021年5期)2021-04-18
安徽电子信息职业技术学院学报(2020年5期)2020-11-13
计算机应用与软件(2020年6期)2020-06-16
扬子江(2019年1期)2019-03-08
电子制作(2019年2期)2019-02-14
摄影之友(影像视觉)(2018年12期)2019-01-28
小天使·一年级语数英综合(2017年6期)2017-06-07
初中生世界·八年级(2017年3期)2017-03-24
