
交通事故案例检索优化方法
2012-07-30 11:33董宪元方守恩王俊骅
同济大学学报(自然科学版) 2012年5期
董宪元,方守恩,王俊骅
(同济大学 道路与交通工程教育部重点实验室,上海201804)
交通事故决策管理涉及交通管制、交通救援、道路清障等不同作业需求,涉及部门广,影响因素复杂,实际仍处于半结构化管理阶段.案例推理(casebased reasoning,CBR)是一种人们利用积累的知识和经验解决当前问题的类比学习方法,适用于解决非结构化或半结构化问题,具有良好的可扩充性、可移植性以及自学习能力[1].案例检索是案例推理过程的核心,当前研究较多的案例检索算法有K-NN(k nearest neighbor)算法、决策树法、神经网络算法、支持向量机等[2].其中,作为最广泛使用的案例检索算法,K-NN算法应用简便灵活,且随着计算机技术的提高,响应迅速,保证了检索效率,尤其适用于基于属性表示的交通事故案例检索.美国佛蒙特大学Sadek等[3]将案例推理方法引入到交通诱导领域,案例各属性权重值均界定为1,采用K-NN算法检索交通流路径分流方案;荷兰代尔夫特科技大学Hoogendoorn等[4]采用案例属性数据平均模糊隶属度作为权重值计算案例相似度,实现实时路网交通安全辅助管理;加拿大不列颠哥伦比亚大学Lin等[5]提出了基于案例推理的道路安全改善方法效益评估系统.国内,华南理工大学翁小雄等[6]采用基于案例推理的动态参数匹配和协调冲突检验方法,寻求建立交叉口信号控制优化方案;西南交通大学戢晓峰[7]采用层次分析法确定案例属性权重,应用KNN算法检索相似的决策案例进行交通拥挤管理;东南大学杨顺新[8]根据专家赋值法确定案例属性权重,应用K-NN案例检索算法查询制定高速公路交通事件应急管理措施.但是,应用K-NN算法进行交通事故案例检索仍存在以下问题:① 交通事故案例数据由数值型和枚举型数据组成,案例属性权重一般采用主观方法定性确定,检索精度及稳定性较差;②以往仅仅以案例最高相似度为指标评价检索精度的方法过于片面.
本文基于道路交通事故由数值型和枚举型数据构成的特点,分析道路交通事故数据频率分布特征,采用信息熵方法评价数据离散程度,客观确定交通事故案例属性权重,并应用二阶聚类算法建立案例检索库,提高案例检索精度;以Matlab R2008a为仿真工具开发交通事故案例检索系统,以沪杭高速公路交通事故数据为例,采用K-NN案例检索算法进行案例检索试验,结合案例最高相似度和案例集匹配度综合评价案例检索精度,验证该案例检索优化方法的有效性.
1 案例属性权重设定
1.1 基于数据离散程度的案例属性权重计算
案例属性权重准确设置是实现案例检索目标的关键.本文基于交通事故案例属性数据频率分布特征,通过数据信息熵分析案例各属性数据离散程度,客观确定案例属性权重值.
假设系统可能处于多种不同的状态,而每种状态出现的概率为Pi(i=1,2,…,m),则系统的信息熵定义为[9]
式中,取k=1/lnm.
交通事故案例属性j的信息熵为

信息熵确定的值域为[0,1],可直接用于随机变量离散程度的对比分析,信息熵的值越接近于0,离散程度越小,检索所需权重值越小;信息熵越接近于1,离散程度越大,检索所需权重值越大.交通事故案例属性j的权重定义为

1.2 沪杭高速公路交通事故案例属性权重
以沪杭高速公路2005年~2008年3542条交通事故案例数据为分析对象,对交通事故的发生位置、发生日期、发生时段、事故形态、严重程度和天气状况数据的频率分布进行分析,通过式(2)计算数据信息熵,评价案例各属性数据离散程度.基于式(3)计算案例各属性权重值见表1.

表1 交通事故案例属性权重Tab.1 Attributes weights of the traffic accident case
2 交通事故案例检索库
基于K-NN算法进行案例检索时,因事故形态、事故严重程度及天气状况三种属性数据权重值过小,检索精度相对较低.现采用二阶聚类算法在原沪杭高速公路交通事故案例库的基础上建立案例检索库,综合提高案例各属性数据检索准确度.为兼顾检索效率与检索精度,有效进行二阶聚类,需同时对数值型事故位置数据以及权重值偏小的以上三类属性数据进行归类化处理,建立案例检索库,提高案例检索精度和效率.
2.1 数据归类化处理
基于数据频率分布特征,采用累计频率法将事故发生位置划分为事故多发位置和事故偶发位置[10],同时,以数据频率分布均衡化为目标,对交通事故形态、交通事故严重程度、天气状况数据进行归类化处理,数据归类化处理结果分别见表2~表5.

表2 交通事故位置数据归类化处理Tab.2 Data classification of the traffic accident location

表3 交通事故形态数据归类化处理Tab.3 Data classification of the traffic accident form

表4 交通事故严重程度数据归类化处理Tab.4 Data classification of the traffic accident severity

表5 天气状况数据归类化处理Tab.5 Data classification of the weather condition
2.2 建立交通事故案例检索库
基于沪杭高速公路交通事故案例库,采用二阶聚类算法建立案例检索库.现将原交通事故案例库聚为9类组成案例检索库,聚类效果良好,如图1~图2所示.图1,图2是根据数据分析软件SPSS的分析结果.

图1 交通事故案例检索库结构Fig.1 Structure of traffic accident case retrieval base

图2 交通事故案例聚类效果Fig.2 Clustering effect of traffic accidents case
3 案例检索
K-NN检索算法是对案例库中每个案例的属性相似度进行加权求和计算案例综合相似度,并检索形成具有一定数目案例的案例集.决策者需要从最高相似案例以及案例集整体匹配性两方面综合考虑,制定决策措施.
3.1 案例相似度计算
数值型属性相似度计算:设案例Ci与案例Cj的第m个属性为数值属性,其属性值分别记为Vim和Vjm.对属性值进行归一化处理,使得Vim,Vjm∈[0,1],则案例Ci与案例Cj第m个属性的相似度为

式中:sim(·)为相似函数;D(·)为属性值之间距离.
枚举型属性相似度计算:枚举型属性相似度的计算比较简单,只要两个案例的属性值相同,则两者的相似度值为1,否则为0

在计算出案例各属性的相似度之后,可以计算两个案例之间的综合相似度为[7]
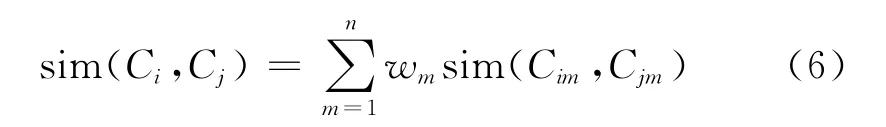
式中,wm为案例第m个属性的权重值.交通事故案例各属性权重值见表1,n表示案例属性数量,
根据式(4)~式(6)对案例检索库中每类案例分别进行案例相似度计算,依据案例相似度的大小及每类案例数量选取出不同的案例数,一般取]条案例[11],则共选取条案例形成案例集.其中,kl表示案例检索库第l类案例数量,k表示案例集所包含的案例数量.
3.2 案例集匹配度
当检索出的最高相似案例与目标案例并不完全相似(simmax(Ci,Cj)≠1)时,决策者需要对检索得到的案例集进行综合评估,以期制定完善的交通事故管理决策措施.本文提出案例集匹配度的概念,结合案例最高相似度综合评价案例检索效果.
“案例集匹配度”定义为“案例集中的案例数据能够与目标案例各属性值相匹配的程度”.由k条案例所组成的案例集中,若案例第m个属性为枚举型,此该属性匹配度为

若案例第m个属性为数值型,则此属性匹配度为

其中w′m=1/n,m=1,2,…,n,则案例集匹配度为

4 试验分析
以Matlab R2008a为仿真工具开发交通事故案例检索GUI(graphical user interface)系统(图3).计算机配置为 Geenuine Intel(R)处理器,0.99G 内存,分别从案例最高相似度和案例集匹配度两方面评价案例检索精度,制定案例决策措施.试验过程中记录了检索耗时,验证案例检索的时效性.
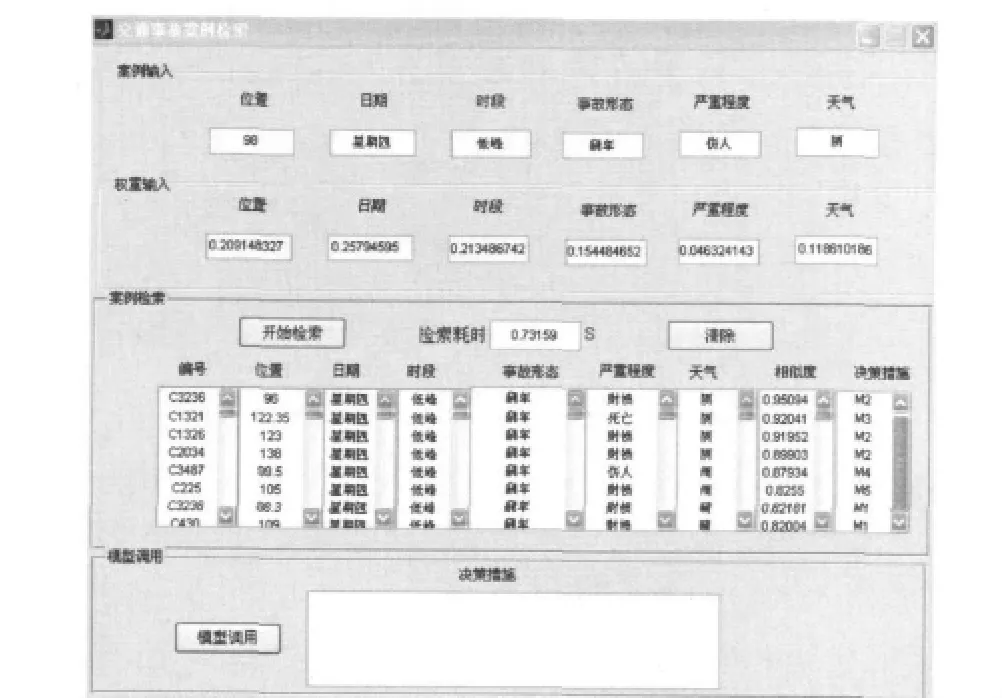
图3 交通事故案例检索系统Fig.3 Traffic accident case retrieval system
仿真系统随机产生40条试验案例,分别在原交通事故案例库和案例检索库上进行案例检索,检索效果如图4和图5所示.
定义参考案例相似度最小阈值为0.8.从图4可以看出,在40次随机案例检索试验中,共有37次检索案例最高相似度在0.8及其以上,检索精度为92.5%,案例属性权重设置基本合理.检索平均耗时0.39s,满足实时决策的需要.然而,案例T5,T24及T26最高相似度分别仅为 0.678 8、0.652 6 和0.788 7,且案例集匹配度较小,显然不能满足在目标案例条件下进行决策选择的需要.

从图5可知,通过对案例检索库的分类检索,案例集匹配度都有了不同程度的提高,尤其对案例T5,T24及T26进行检索时,案例集匹配度分别增长了67.1%,25.9%和53.6%,弥补了检索案例最高相似度值过小的问题.决策者可以通过对案例检索集的综合评估,制定更加科学、合理的管理措施,保证了案例推理的有效性.检索试验平均耗时0.40s,同样满足交通事故条件下实时决策管理的需要.
5 结论
本文基于交通事故案例数值型和枚举型数据并存的构成特征,提出采用信息熵方法评价数据离散程度,客观确定交通事故案例属性权重;在数据归类化处理的基础上,应用二阶聚类算法建立了案例检索库,并进行了K-NN案例检索试验;提出了从案例最高相似度和案例集匹配度两个方面进行案例检索精度评价的方法.试验分析证明,在客观确定交通事故案例属性权重并建立案例检索库的基础上进行K-NN案例检索,案例检索精度提高,弥补了以往仅仅以最高相似案例辅助决策的弊端,优化了案例检索效果,且检索试验平均耗时仅约0.4s,符合道路交通事故实时决策管理的需要,验证了该交通事故案例检索优化方法的有效性.
[1]Gronau G,Laskowski F.Using case-based reasoning to improve information retrieval in knowledge management systems[C]//AWIC’03 Proceedings of the 1st International Atlantic Web Intelligence Conference on Advances in Web Intelligence.Berlin:Springer-verlag,2003:94-102.
[2]孙岩清,尹树华,林初善.基于粗糙集的CBR系统案例检索策略[J].电讯技术,2010,50(5):23.SUN Yanqing,YIN Shuhua,LIN Chushan.A case retrieval strategy for CBR system based on rough set [J].Telecommunication Engineering,2010,50(5):23.
[3]Sadek A W,Smith B L,Demetsky M J.A prototype case-based reasoning system for real-time freeway traffic routing[J].Transportation Research Part C,2001,9(5):353.
[4]Hoogendoorn S P,De Schutter B,Schuurman H.Decision support in dynamic traffic management.Real-time scenario evaluation [J].European Journal of Transport and Infrastructure Research,2003,3(1):21.
[5]Lin F,Sayed T,Deleur P.Estimating safety benefits of road improvements:case-based approach [J ].Journal of Transportation Engineering.2003,129(4):385.
[6]翁小雄,姚树申,朱学峰.基于交通流颗粒化结构的交通控制模型[J].公路交通科技,2007,24(2):99.WENG Xiaoxiong,YAO Shushen,ZHU Xuefeng.Traffic control model based on granuIation configuration of traffic flow[J].Journal of Highway and Transportation Research and Development,2007,24(2):99.
[7]戢晓峰,刘澜.基于案例推理的交通拥挤管理方法[J].西南交通大学学报,2009,44(3):415.JI Xiaofeng,LIU Lan.Traffic congestion management method on case-based reasoning[J].Journal of Southwest Jiaotong University,2009,44(3):415.
[8]杨顺新.高速公路事件延时、延误和响应模型分析[D].南京:东南大学交通学院,2009.YANG Shunxin.Analysis of freeway incident duration,time delay and response model[D].Nanjing:Southeast University.School of Transportation.2009.
[9]朱兴琳.公路运营系统安全性综合评估[D].上海:同济大学交通运输工程学院,2010.ZHU Xinglin.Integrated assessment of highway operation system safety[D].Shanghai:Tongji University.College of Transportation Engineering,2010.
[10]方守恩,郭忠印,杨轸.公路交通事故多发位置鉴别新方法[J].交通运输工程学报,2001,1(1):90.FANG Shouen,GUO Zhongyin,YANG Zhen.A new identification method for accident prone location on highway[J].Journal of Traffic and Transportation Engineering.2001,1(1):90.
[11]张云涛,龚玲.数据挖掘原理与技术[M].北京:电子工业出版社,2004.ZHANG Yuntao,GONG Ling.Data mining principle and technology[M].Beijing:Publishing House of Electronics Industry,2004.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
中学生数理化(高中版.高考数学)(2021年10期)2021-12-02
四川劳动保障(2021年10期)2021-12-02
中学生数理化·中考版(2021年10期)2021-11-22
小雪花·成长指南(2020年2期)2020-10-12
疯狂英语·新读写(2018年2期)2018-11-29
雷达学报(2017年6期)2017-03-26
灾害医学与救援(电子版)(2016年4期)2016-03-11
振动工程学报(2015年1期)2015-03-01
郑州大学学报(理学版)(2014年2期)2014-03-01
