
基于遗传算法的列车自动驾驶过程优化研究
2012-07-27 11:23高凡
铁道运营技术 2012年3期
高凡
(兰州交通大学 自动化与电气工程学院,硕士研究生,甘肃 兰州 730070)
近年来,各国学者们运用了多种方法对高速列车速度控制器进行了不同的研究,取得了一定的成果[1],如日本研制的“预测型模糊控制”列车自动驾驶系统[2];新加坡学者把遗传算法用于列车自动驾驶仿真中,根据各种情况在出发前便产生惰行的最合适点,以实现能耗最低,之后又提出了基于模糊的多目标控制列车自动运行系统;中科院自动化所把一种新型的联想记忆神经网络,应用于列车的自动停车中,该技术以滚动优化的方式实现了基于联想记忆神经网络的长程预测控制;铁道科学研究院提出了基于直接模糊神经控制的方法[3],应用在列车自动运行控制上[4];同济大学用模糊控制的BP网络实现站间运行控制,用基于遗传算法的模糊神经网络实现列车的定位停车控制[5]。
由于列车自动驾驶系统(ATO)控制的目标复杂多样和环境变量不稳定等原因,要实现ATO控制,传统的控制理论己经不能满足需要,须利用先进的智能控制理论对控制算法进行设计。本文采用遗传算法对列车运行曲线进行优化,从而产生最优的决策策略以控制列车运行。
1 高速列车运行优化模型
1.1 列车运行质点模型 根据《牵引计算规程》,列车质点运动方程为
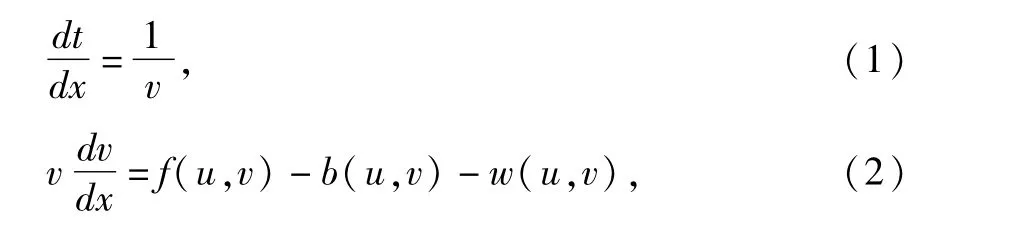
式中:x为列车在线路上的位置;
t为运行时间;
v为列车运行速度;
u为输入控制;
f为列车牵引力,由列车牵引特性曲线决定;
b为制动力;
w为列车阻力。
1.2 列车运行优化模型 单质点模型将列车看作一个整体,列车在当前位置的阻力由基本阻力和附加阻力叠加而来,但相邻2车体分别位于不同坡段时,会产生不同的附加阻力,此时,无论采用车体哪部分为计算基准,都会产生比较大的计算误差。
实际上列车是分步式质量系统,与单质点模型比较而言,主要表现为单位附加阻力不同,因而对单质点模型进行如下优化:
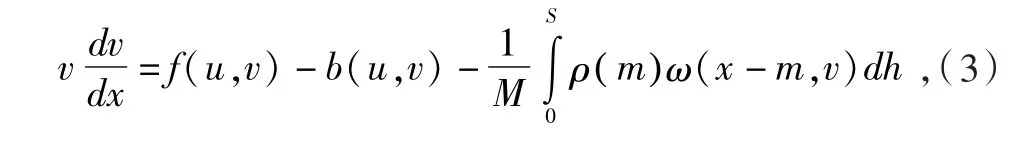
式中:M为列车质量;
ρ(m)为距离列车头部m位置处列车的单位长度质量;
S为列车全长。
对单质点模型进行优化后,列车单位点的阻力与列车所处的位置相关,当列车位于不同坡道时得到不同的阻力,从而提高了列车运行模型的准确性。
2 遗传算法优化运行曲线模型
2.1 遗传优化的优越性 遗传算法(Genetic A lgo⁃rithm-GA)是基于自然选择和基因遗传学原理的搜索算法,借助于复制、交叉、变异算子,引导个体逐渐向最优解移动,选择操作使优秀的个体能够尽可能保留下来。为了保持种群的多样性,通过交叉和变异操作获得优秀的个体,同时变异操作有利于维护种群的多样性,防止陷入局部最优,只须检测少量的结构就能反映搜索空间的大量领域。它在实时性要求不高的复杂控制系统的优化中是很有潜力的,对于列车自动驾驶这种多目标,多输入变量的控制系统来说,采用遗传算法可以很好地解决列车运行的准时性、停车精度、能耗及舒适性等多目标寻求最优控制策略的问题。
2.2 遗传优化过程 列车自动驾驶问题,实际上就是寻找列车行驶过程中,达到行车要求的最佳工况转换点及其控制策略。因此,可将列车控制序列进行遗传编码,用遗传算法寻优,对目标曲线进行优化。遗传算法优化高速列车目标曲线流程,见图1。
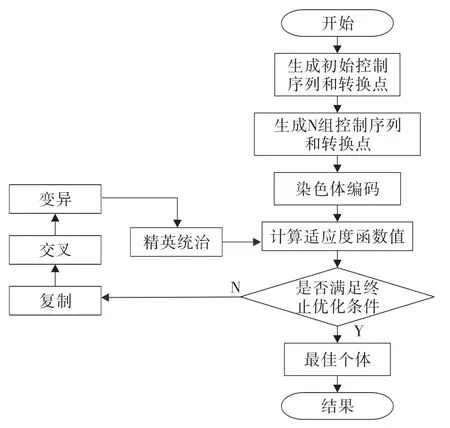
图1 遗传算法优化高速列目标曲线的流程图
2.2.1 生成列车控制序列和转换点 根据《牵引计算规程》,求得列车在整个区间输入控制序列及其转换点。合并运行距离很短的不合理输入控制,本文合并1 km以下输入控制,得到列车输入控制序列及其转换点。
将目标速度转化点与坡度转化点的加速度值求差,得到合成的加速度转换点,如图2所示。
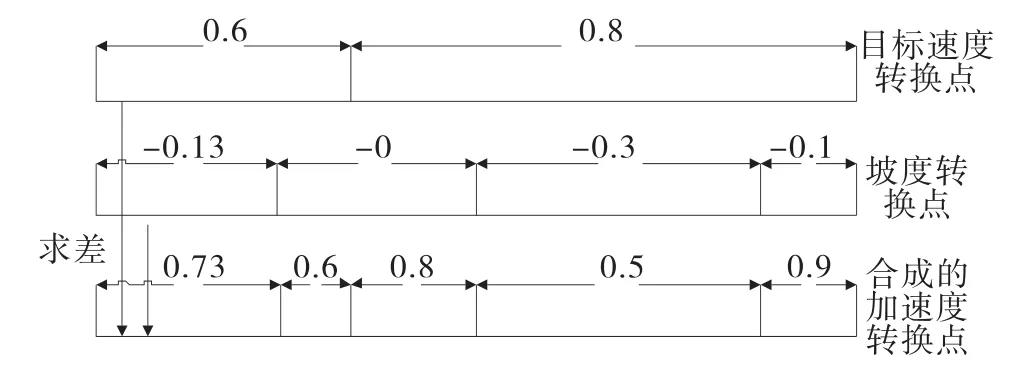
图2 合成加速度转换点
2.2.2染色体编码 将控制序列及其转换点转化为二进制串,每对工况和位置编码连接组成一个基因,整个区间形成k个基因,将其连接为一条染色体。转换编码如表1所示。
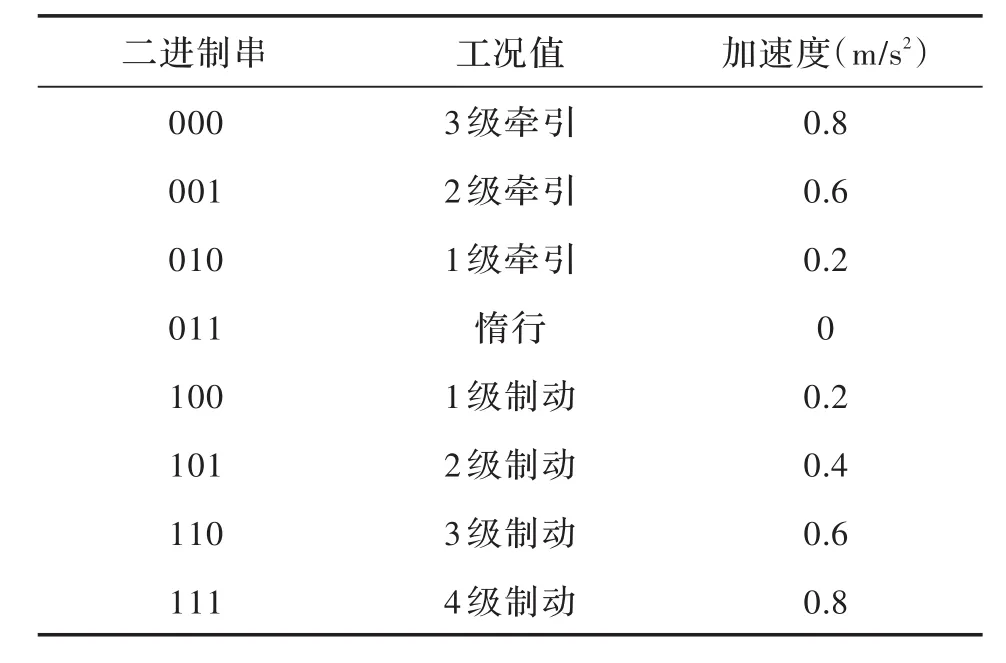
表1 编码转换表
选取位置86632(10101001001101000)cm处采取工况2级牵引(001)为例,编码如下。

2.2.3 适应度计算 适应度用来确定个体被遗传到下一代个体中的概率。适应度函数是衡量遗传算法优劣的关键。
1)列车运行时间:

式中:ft为列车运行时间;
X为列车运行距离。
2)列车停车地点:

式中:fd为列车实际停车地点指标。
3)列车全程能耗:

式中:θ为不同输入控制对应的能耗。
4)旅客舒适度:

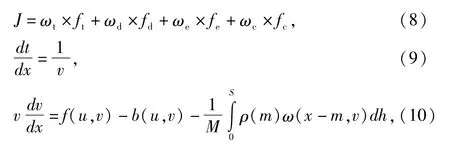
从上式可知,加速度变化率决定了旅客受到的冲击率,冲击率越小运行的舒适度就越高。
列车运行时间ft,停车精度fd,能耗fe,舒适度fc作为目标,应用线性加权,将多目标优化问题转化为单目标优化问题,建立模型如下:
式中,ωt,ωd,ωe,ωc分别为运行时间、停车精度、能耗、舒适度的权重。
2.2.4 遗传算法基本操作 遗传操作过程如图3所示。
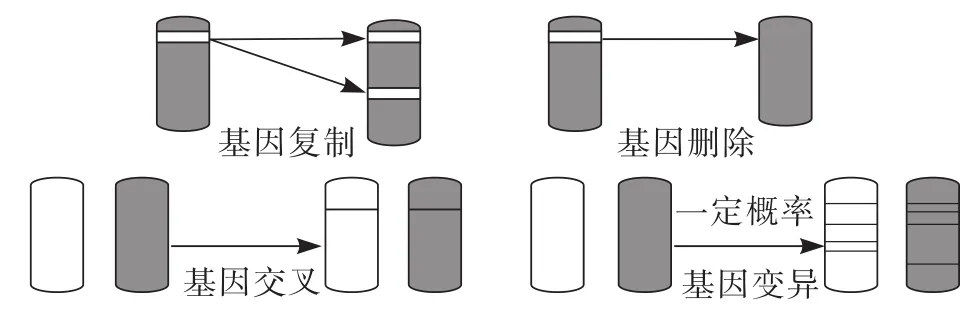
图3 遗传操作过程
1)复制;采用遗传算法轮盘选择策略。
2)交叉;采用遗传算法部分个体匹配交叉策略,由于交叉概率太小会造成搜索过程停滞不前,所以把交叉概率定在0.5~1.0之间,本文选取交叉概率为0.5。
3)变异;变异算子通过对所有个体随机地确定基因位,以变异概率改变该基因值。目的是增强遗传算法的局部搜索能力,同时增加群体的多样性。如果没有变异,就不会产生新的基因,但变异太大又会使遗传算法变成随机搜索,一般变异概率定在0.01~0.2之间,本文选取变异概率为0.01。
2.2.5 精英统治 精英统治就是使遗传算法过程中的最佳染色,体始终参与每一代的繁殖过程。
在染色体复制过程中,上一代最佳染色体有一定概率不能被选中。不被选中的概率由下式决定:

式中:n为父代染色体个数,设其中有1个最佳染色体;
2n为从基因池中随机独立选出的染色体数。
上式表明最佳染色体在复制过程中将有13%的概率不被选中,并且即使最佳染色体被选中,其后代适应度也很有可能不会比此最佳染色体的适应度高。因此,运用精英统治得到的后代,就能保持高适应度,且收敛的速度始加快。
3 仿真验证
3.1 仿真参数 选取京津城际线路中北京站至武清站之间88.206 km的线路为依据,线路规定运行时间为22.51 m in。以CRH 3型高速列车为研究对象,该型号高速列车的主要参数与特性见表2。
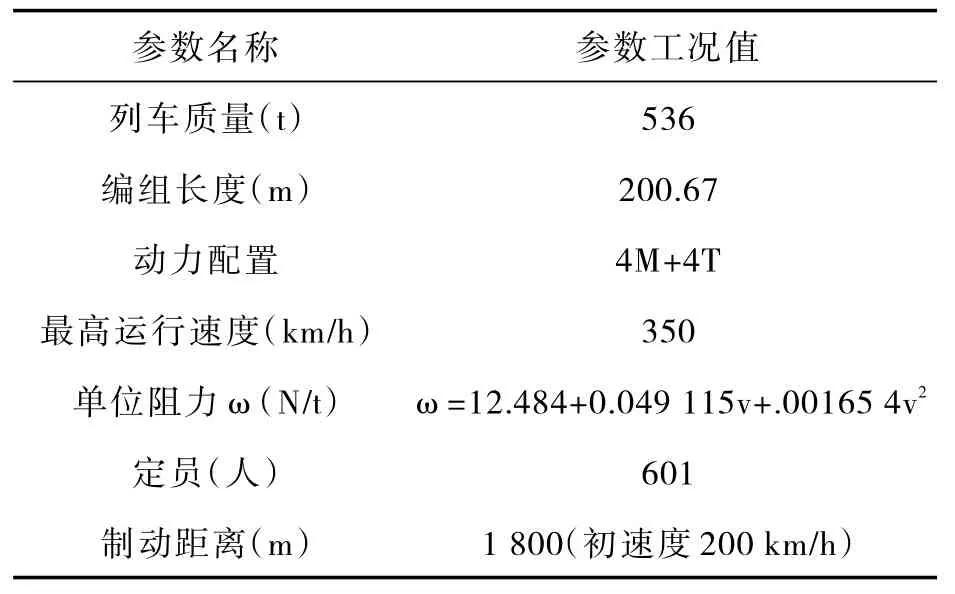
表2 高速列车主要参数
3.2 优化曲线 根据线路数据和优化模型进行仿真。高速列车自动驾驶优化曲线,如图4所示。
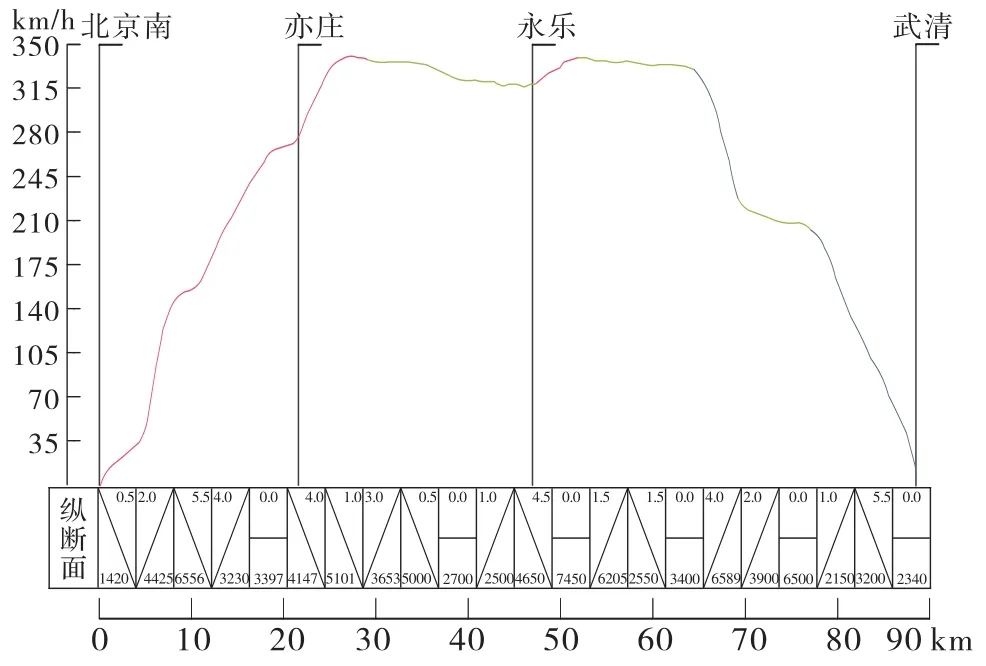
图4 高速列车优化运行曲线
从图4中列车启动加速过程较快;列车在338 km/h的目标速度附近运行,其优化曲线较为平稳,满足了舒适性的要求;列车运行的时间为21.19 m in,运行时间与规定时间的误差为19 s,列车的准时性满足要求;列车运行距离为88.205 3 km,距离停车点0.7 m;运行过程中3段采用惰行,减少了能量损失。从仿真结果可以看出,节能效果显著,其他各项指标也都在控制的范围内有较好效果。
4 结束语
本文在列车牵引计算系统的基础上,应用遗传算法对高速列车目标曲线进行优化,采用精英统治加快收敛速度,得到最优策略控制列车运行。该方法兼顾了列车运行的准时性、停车精度、能耗及舒适性等功能。该方法对于我国高速列车多目标运行过程的研究可具有较好的参考价值,为进一步研究列车自动驾驶系统提供了有价值的分析方法。
[1]唐涛,黄良冀.列车自动驾驶系统控制算法综述[J].铁道学报,2003,25(2):98-102.
[2]Oshima H,et al.Automatic train operation system basedon predictive fuzzy control[C]//Proceeding of Artificial In-telli⁃gence for Industrial App lications,1988.IEEE AI’ 88,Pro⁃ceedings of the International Workshop,1988:485-489.
[3]WANG Jing,CAI Zi-xing,JIA Li-m in.Direct Fuzzy Neu-ral Control with App lication to Automatic Train Oper⁃ation[J].Control Theory and App lication,1998,(15):391-398.
[4]何兵,万百五.用于高速列车自动化的多控制器递阶智能控制研究[J].西安交通大学学报,1997,31(9):39-45.
[5]赵海东,刘贺文,杨悌惠.高速列车运行控制系统的研究[J].中国铁道科学,2000,21(1):31-36.
猜你喜欢
铁道通信信号(2020年1期)2020-09-21
科学之谜(2019年3期)2019-03-28
电子制作(2019年24期)2019-02-23
铁道通信信号(2018年10期)2018-12-06
科学之谜(2018年8期)2018-09-29
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
铁道通信信号(2016年8期)2016-06-01
智能系统学报(2015年4期)2015-12-27
中国铁道科学(2015年6期)2015-06-21
